 夜雨聆风
夜雨聆风





拒绝AI堆砌!腾讯音乐基于OpenClaw的智能运维生态建设
本文根据边雪冬老师在〖2026 XCOPS智能运维管理人年会-广州站〗的演讲内容整理而成。(文末有PPT获取方式,不要错过)

作者介绍
边雪冬,腾讯音乐运维开发负责人。2014年加入腾讯,负责立体化智能监控系统建设,机器学习算法去阈值,告警去噪80%,准确率100%。2016年加入腾讯音乐,建设适用于音乐场景下的DevOps体系、智能化运维体系、观云大数据平台、全面推进云原生。
目录
-
腾讯音乐智能运维体系建设演进脉络
-
海量业务数据架构支撑体系建设
-
AIOps能力升级:数据赋能与智能告警优化
-
AI浪潮下的全新探索:OpenClaw龙虾智能运维体系
-
落地理念与未来规划
自ChatGPT引爆全民AI浪潮以来,AI技术全面重构各行各业的生产模式,运维领域也迎来了从传统立体化运维、常规智能运维,向原生AIOps升级的关键转折点。在转型初期,我们核心思考两个核心问题:AIOps转型该从何处切入、如何落地落地。
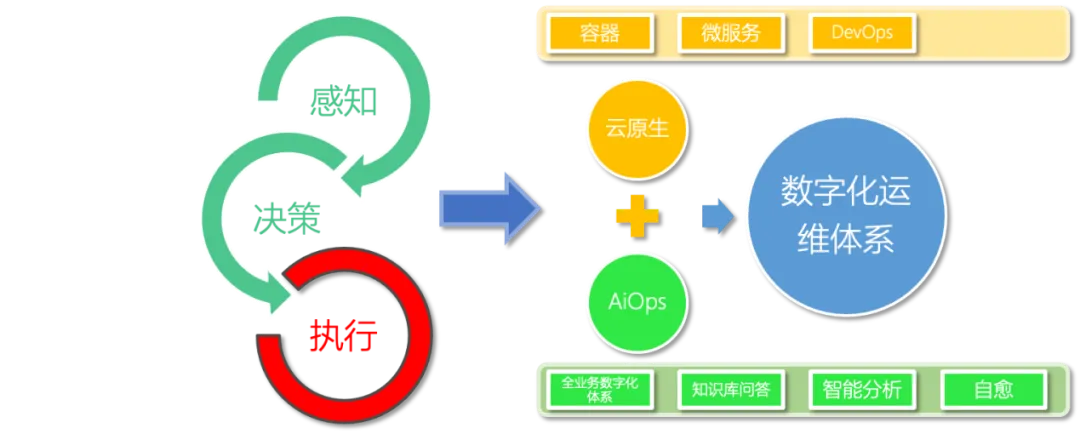
复盘运维与运维开发的核心工作,所有场景都可以抽象为质量、效率、成本三大核心维度,再进一步下沉拆解,整个运维体系的核心链路可归纳为:感知、决策、执行。我们所有的AIOps建设,均围绕这一套底层逻辑循序渐进落地。
一、腾讯音乐智能运维体系建设演进脉络
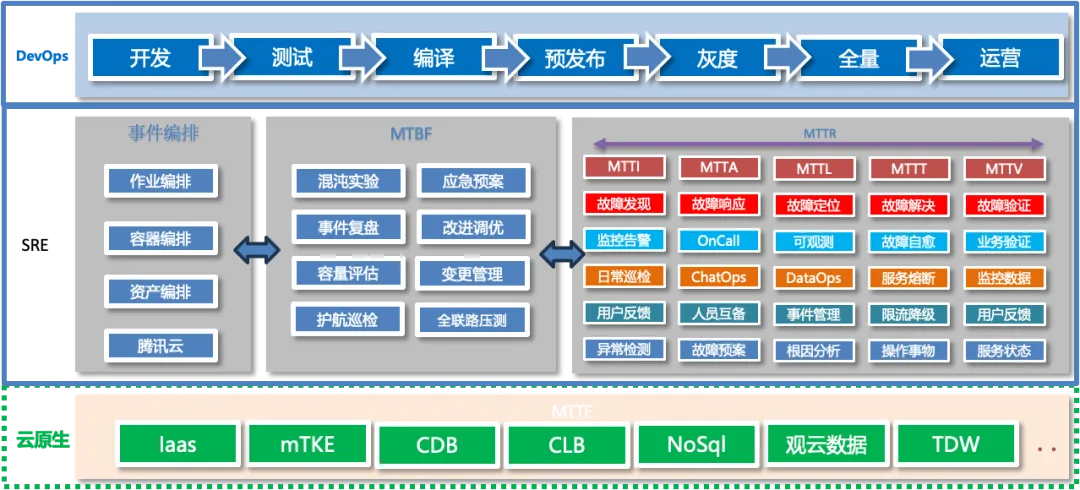
历经多年迭代,我们搭建了一套全覆盖、全闭环的数字化运维体系,整体架构分为三层,层层联动、协同赋能业务研发与运维:
-
上层研发交付层(DevOps):打通从代码提交、编译构建、测试验证到上线发布的完整CI/CD研发链路,实现研发全流程数据可追溯、可观测、可管控;
-
中层SRE运维层:聚焦故障治理核心场景,完成故障发现、响应、定位、修复、复盘的全流程闭环,持续优化故障响应时长与运维处置效率;
-
底层云原生基座层:基于K8s等云原生核心组件,结合腾讯音乐海量业务场景特性,搭建适配自身业务的云原生运维体系,为上层运维、研发能力提供稳定基座支撑。
在完善基础架构后,我们核心发力点转向:如何通过AI赋能,最大化释放现有体系的能力价值,解决传统运维的痛点难题。

回溯2014年前后的运维现状,我们面临着行业共性的运维困境。当时运维工作高度依赖人工值守,峰值阶段单人每月接听运维告警电话高达3000通,运维人员长期处于“被动救火”的状态,精力被大量重复性、基础性问题消耗。
从技术架构层面来看,早期系统存在海量监控节点,业务链路复杂、监控维度分散。一旦出现故障,会瞬间爆发大量碎片化告警,运维人员只能逐个排查、临时修复,缺乏统一的故障定位、关联分析能力,故障处置效率极低,业务稳定性保障压力巨大。
同时,传统阈值告警模式存在天然短板:不同业务的异常判定标准完全不同。部分业务80%运行负载即出现异常,部分稳定性敏感业务90%负载已是临界值,还有普通业务可承受60%负载波动。人工配置、维护各类业务告警阈值,不仅工作量巨大,还极易出现阈值不合理、漏告警、误告警等问题。
为解决阈值固化、告警泛滥的核心问题,我们在2014-2015年引入3sigma方差算法重构告警体系,彻底摒弃传统人工固定阈值配置模式。
这套算法的核心逻辑是:将各类监控指标的实时波动转化为动态波动值,通过累积波动幅度判定异常等级。指标波动幅度越大,累积异常分值越高,告警触发越及时、精准。同时,系统会基于昨日、上周同期及近30分钟的历史数据,实时迭代更新判定标准,实现全量指标动态阈值告警,无需人工维护。
该方案落地后,我们的告警量级实现断崖式下降:月度告警总量从3000+条精简至200余条,彻底解决了告警泛滥、人工运维压力过载的问题,为后续智能运维建设奠定了基础。
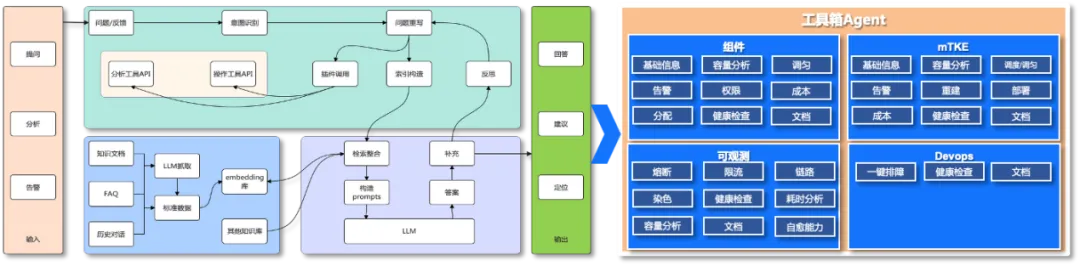
告警数量大幅压降后,新的核心痛点凸显:海量告警维度分散、相互独立,单一故障会触发多条无关告警,运维难以快速串联关联信息、定位故障根因,依旧无法摆脱“盲目救火”的困境。
针对这一问题,我们搭建了自研告警工作流体系,结合文档检索、语义提取能力,自动梳理告警之间的关联关系,实现碎片化告警的智能串联聚合。同时,我们配套搭建了完整的运维工具箱,整合可观测监控、组件异常检测、K8s集群监控、DevOps全链路数据等能力,为告警分析提供全方位数据支撑。
后续我们基于Dify重构标准化工作流,通过正则检索、大模型语义分析,进一步提升告警关联、异常识别的智能化能力,实现告警从“被动接收”到“主动关联分析”的升级。
在基础告警能力完善后,我们对整体可观测体系进行全盘升级:首先,汇聚单节点监控、IP节点探测、网络抖动监测等全维度基础监控数据,基于单点告警数据完成单维度故障根因初步定位;其次,依托全链路可观测能力,将单点告警串联为完整链路告警,最终关联映射至业务SLA核心指标,实现故障从单点到全链路的全覆盖分析。
同时,我们针对微服务上报体系做差异化优化:根据业务重要等级配置不同的数据计算窗口,普通业务采用1分钟统计窗口,核心重要业务压缩至20秒甚至更短,实现核心业务异常秒级感知、快速告警。通过全链路层级分析,可直观还原从上至下的异常传播过程,精准定位故障源头。例如服务成功率下降问题,系统可通过内存指标、链路数据联动分析,直接判定为内存异常导致的服务故障。
此外,我们打通了完整的DevOps全流程数据,留存代码提交、编译、测试、上线全链路记录。出现故障时,可追溯具体代码变更文件、变更函数,实现故障从“现象归因”到“代码级精准归因”的突破。
针对腾讯音乐数万级的复杂服务节点,我们升级WebCode可观测能力,梳理服务上下游血缘关系,彻底解决复杂微服务架构下链路梳理难、根因定位难的问题。
通过对海量历史告警与故障数据的梳理,我们将日常业务故障归纳为三大核心类型:业务逻辑错误、IP集群路由异常、熔断限流异常,三类故障覆盖绝大多数运维场景。
数据统计显示,IP集群路由异常占日常高级故障的20%,业务逻辑错误占比高达40%。基于该数据结论,我们制定了分层治理策略:优先攻克20%的IP集群故障,可直接实现20%的业务质量提升;针对占比最高的业务逻辑错误,搭建统一错误码知识库平台。
该平台会自动沉淀各类错误码的故障成因、处置方案、优化建议,告警触发后强制运维、研发人员补齐故障信息与解决方案。同时打通代码仓库,通过代码注释关联错误码释义与处置策略,实现故障经验的标准化沉淀、复用与迭代,从源头降低同类故障复现率。
二、海量业务数据架构支撑体系建设
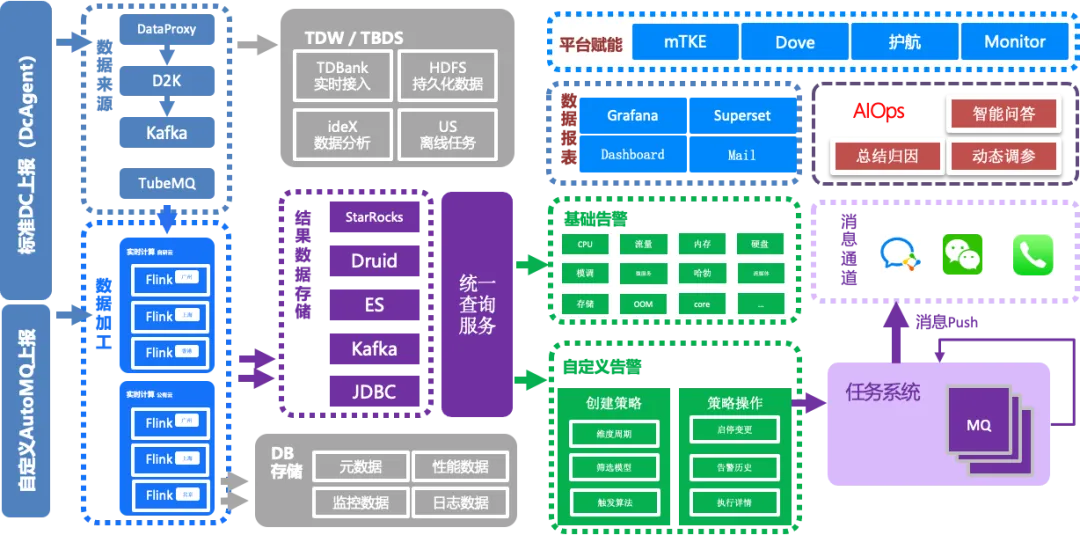
除通用运维故障外,音乐业务存在大量个性化、细维度的业务故障,如播放异常、音频加载失败等,这类故障依赖通用监控无法精准识别。为此,我们自研适配业务场景的DC Agent,兼容全维度业务、运维数据上报场景,实现细粒度业务指标的全覆盖采集。
面对海量数据处理压力,我们搭建了高可靠、高吞吐的数据处理架构。目前平台一分钟数据上报量高达40亿条,涵盖运维监控数据、音乐业务运营数据两大类核心数据。为保障数据稳定性与高效处理,我们完成多层架构优化:
-
数据上报层:在DC上报链路搭建全层级容错机制,避免链路中断导致的数据丢失、数据异常问题;
-
数据存储层:深度与StarRocks社区合作,采用存算分离架构,在保障数据查询、分析性能的同时,大幅降低存储成本;目前正逐步将ES能力迁移至StarRocks新版本,实现全量数据存储统一;
-
数据应用层:处理后的标准化数据可赋能Grafana、SuperSet等监控平台,支撑各类技术指标、业务指标的监控告警,告警渠道覆盖企业微信、电话等,实现普通告警精准触达、核心告警紧急兜底。
这套数据体系落地后,我们实现了故障的精细化定位。针对腾讯音乐国际化业务场景,可精准识别特定区域、特定运营商的网络异常,快速判定故障影响范围,支撑运维人员通过流量迁移、容错调度等方式,快速化解区域性故障,同时实现所有告警呈现逻辑、水位监控的统一标准化。
三、AIOps能力升级:数据赋能与智能告警优化
在基础运维体系成熟后,我们聚焦数据赋能与AI智能化升级,搭建了标准化的数据赋能架构。基于沉淀多年的全维度数据,封装统一数据Agent能力,并依托MCP架构完成统一抽象封装,赋能底层XOps平台,为各业务线提供标准化的数据观测、告警分析能力。
针对传统3sigma告警算法的局限性,我们引入AI告警预测方案完成全面升级。结合业务节假日效应、运营活动、波峰波谷等场景特征,为数据打上场景标签,实现差异化告警策略。例如周末、大促等流量波动场景,自动对告警做合理降频,大幅提升告警精准度,减少无效告警干扰。
我们将AIOps体系也定义为云原生基座+AI智能运维的一体两翼架构,以云原生为基础、以AI智能能力为驱动,搭建数字化、智能化运维体系。目前我们已重点落地故障自愈的执行能力,后续将持续深耕知识库建设,实现感知、决策、执行全链路的智能化升级。
四、AI浪潮下的全新探索:OpenClaw龙虾智能运维体系
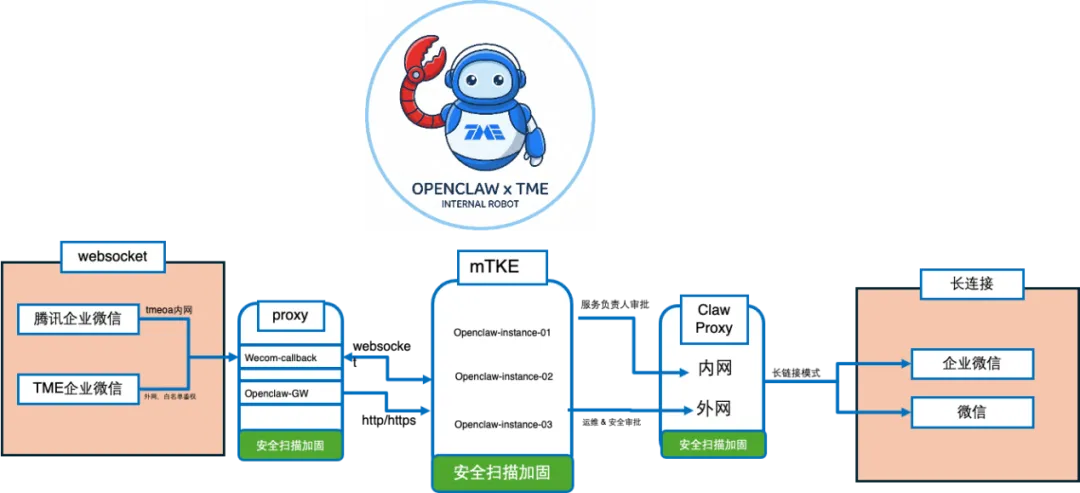
随着大模型技术爆发,我们启动了自研AI智能运维体系——OpenClaw(龙虾)的建设,核心聚焦安全可控、智能赋能、高效落地三大核心目标,适配腾讯音乐内部全场景运维需求。
企业内部AI落地的核心前提是安全可控。基于现有K8s云原生平台,我们为OpenClaw搭建了完全隔离的专属沙箱环境,从输入、输出两端构建全链路安全防护体系:
-
输入层安全:通过统一网关与Proxy组件完成全流量劫持、过滤与校验,保障输入指令、数据的合规性与安全性,拦截恶意、违规请求;
-
输出层安全:针对大模型请求、外网关联请求两类核心输出流量,联合腾讯朱雀实验室完成全流量加密加固,杜绝数据泄露、非法访问等安全风险。
同时,我们单独搭建高安全等级的OpenClaw专属集群,专门对接代码仓库场景,严格保障代码数据、研发数据的安全性,适配研发、运维核心敏感场景的AI赋能需求。整套沙箱环境本身具备完整的生产隔离能力,无需额外叠加沙箱降级机制,实现安全与效率的平衡。
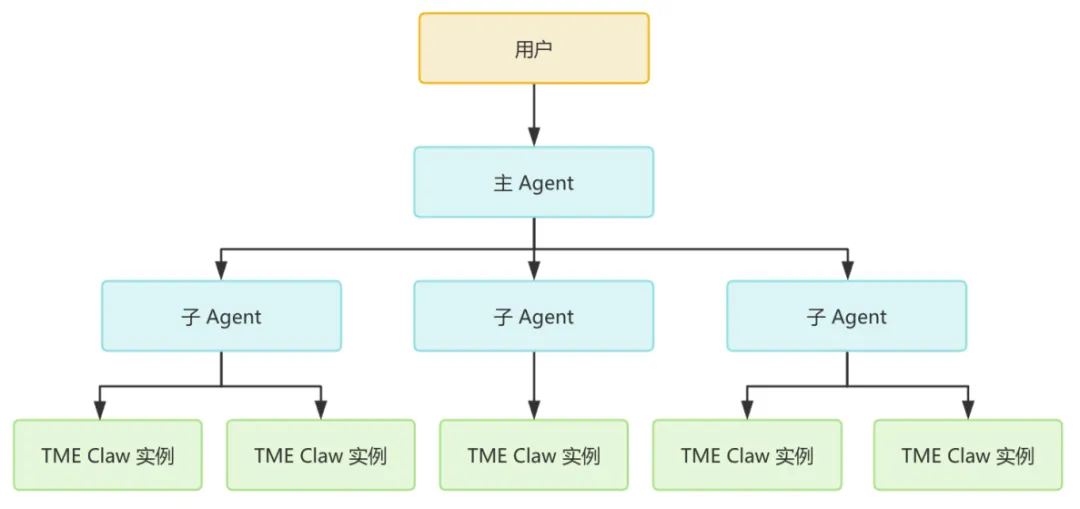
为突破单一智能体的能力局限,我们搭建了主Agent+子Agent的龙虾战队协同架构,实现多角色、多场景的智能化协同工作:
-
所有OpenClaw智能体均归属内部用户资产,具备独立用户属性与角色定位,可按需配置架构师、产品、运维、研发等专属角色,系统通过灵魂文件自动补齐角色能力与工作边界;
-
由主Agent作为核心调度中枢,统筹、协调多个子Agent分工协作,适配复杂运维场景的多维度分析、多步骤处置需求,解决单一智能体能力单一、场景适配性差的问题。
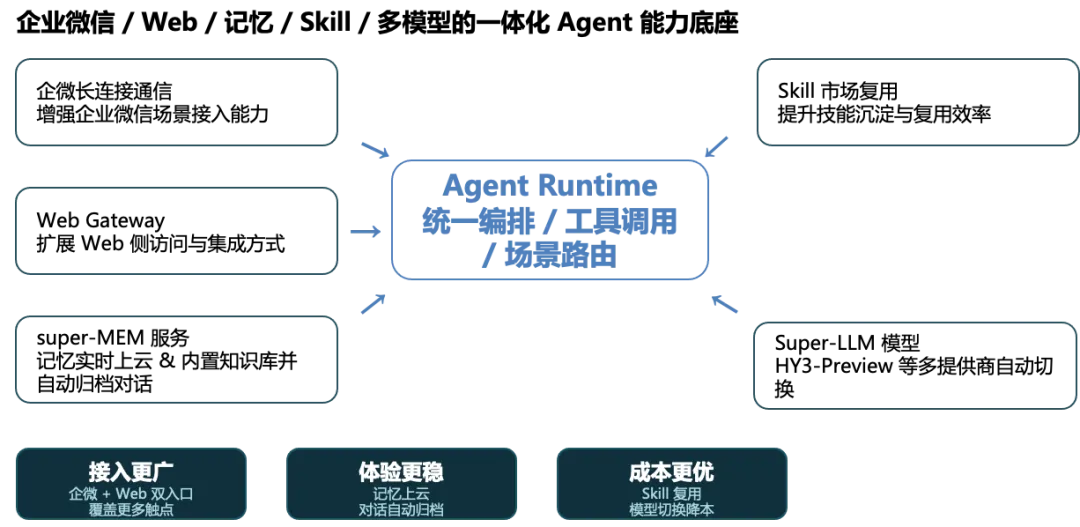
面对Hermes、各类大模型、新型智能体的快速迭代,为避免重复接入、重复开发的冗余成本,我们对智能体架构做了通用抽象,搭建统一的Agent Runtime运行时体系。通过统一网关、统一技能市场、统一插件服务,实现各类AI智能体的快速接入、统一管理,无需针对不同模型、不同智能体做定制化开发,大幅提升架构通用性与可扩展性。
在AI落地实践中,我们发现大模型普遍存在上下文爆炸、记忆混乱、Token消耗过高、模型适配不合理等痛点。为此,我们自研两大核心服务,彻底优化大模型使用体验与成本效率。
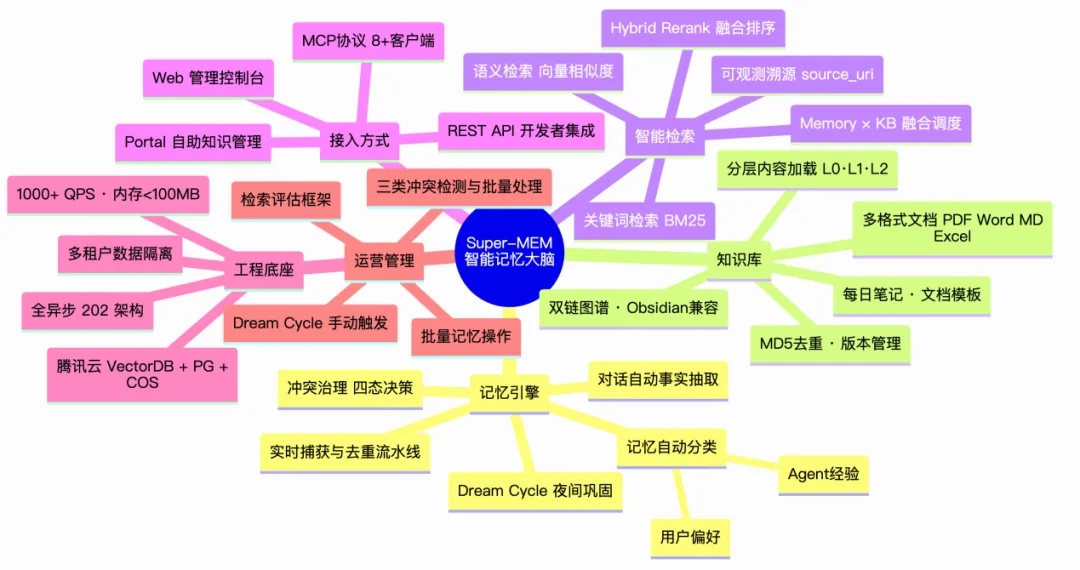
一是Super Memory超记忆服务。摒弃单纯的RAG检索模式,搭建融合知识图谱、结构化知识库、场景化记忆的完整记忆体系。系统可根据业务场景自动录入、召回对话与运维知识,同时设置知识激活周期,不活跃知识自动降冷归档,超长内容自动沉淀入库。这套能力落地后,大模型单次对话Token消耗从原本5-6万稳定降至1-2万,大幅降低使用成本,同时解决记忆混乱、上下文过载问题。
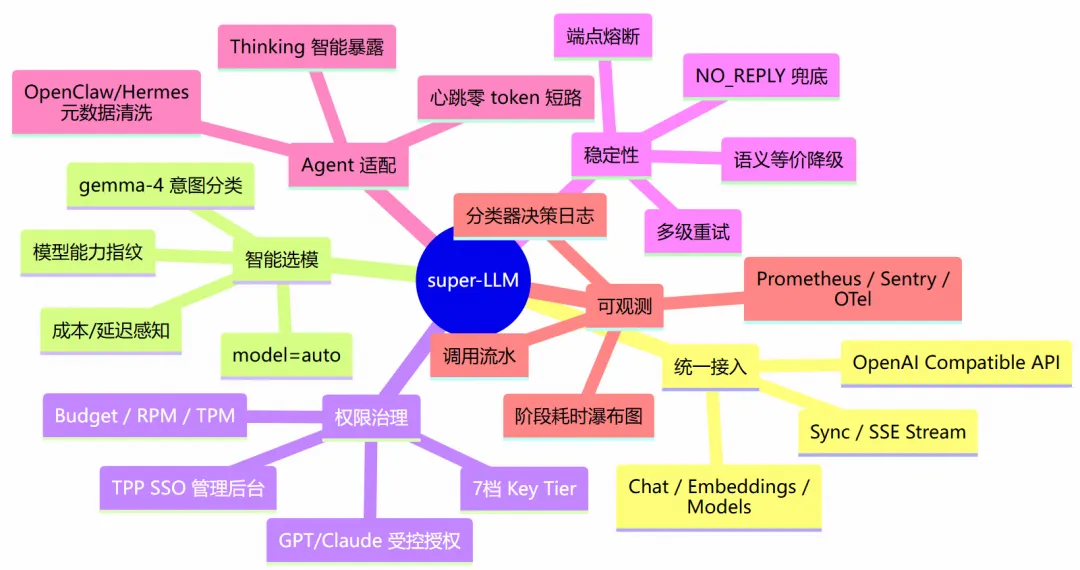
二是Super LLM智能路由服务。平台接入多模态、OCR、通用问答、代码生成等多类大模型,为实现场景化精准选型、成本可控,我们搭建模型智能分析器。针对用户请求自动识别场景类型:普通问答、业务咨询类请求调用低成本内部模型;代码开发、复杂分析类高精度需求,自动调度高性能模型。同时实现OpenClaw心跳请求的统一拦截处理,避免无效Token消耗,实现模型调用的精准、高效、低成本管控。
五、落地理念与未来规划
过去一年,行业普遍面临AI运维落地的焦虑,多数团队聚焦“堆砌AI能力”,而我们始终坚持场景落地优先、解决实际问题为核心的建设理念。现阶段我们保持稳健落地节奏,仅将大模型应用于故障分析、根因定位等确定性场景,严控AI直接操作生产环境的风险。
在故障自愈场景中,目前我们采用「AI分析建议+人工确认+自动化执行」的安全模式:AI完成故障根因分析、给出处置方案后,不会直接操控生产资源,由运维人员一键触发预设的安全脚本与工作流,完成故障自愈。针对K8s Pod重建、节点剔除等高危操作,全部依托传统稳定逻辑判定执行,保障大规模生产环境的绝对稳定。
未来,我们将依托多Agent协同架构,持续细化AI分析能力、完善运维知识库体系,深耕复杂场景的智能化落地,让AIOps真正扎根业务、赋能业务,实现从“辅助运维”向“自主运维”的进阶升级。
Q&A
Q1:OpenClaw输出层为何不额外配置受控沙箱?
A:OpenClaw整体运行在专属隔离沙箱环境中,底层K8S架构上已实现生产环境完全隔离,天然具备安全管控能力,无需额外叠加沙箱降级环节,兼顾安全性与运行效率。
Q2:故障自愈的执行逻辑是AI直接操作还是人工确认执行?
A:目前不支持AI直接操控生产环境。核心逻辑为AI完成故障智能分析、输出标准化处置方案,系统展示一键处置按钮,由运维/业务人员人工确认后,触发预设的安全自动化脚本完成自愈。核心生产场景优先保障稳定性,杜绝AI自主操作带来的不可控风险。
Q3:3sigma动态告警算法的核心原理与阈值生成逻辑?
A:该算法彻底取消人工固定阈值,核心通过指标波动累积值判定异常。系统基于近30分钟实时数据、昨日及上周同期历史数据,实时迭代生成动态判定标准。指标波动幅度越大,累积异常分值越高,告警触发越精准,适配所有业务场景的个性化波动规律,彻底解决传统阈值维护成本高、适配性差的问题。
Q4:目前平台的故障自愈率核心指标情况?
A:平台无统一自愈率统计指标,核心依托标准化自动化逻辑落地自愈。针对20%的IP集群路由类故障,系统可通过K8s Pod重建、节点剔除等预设逻辑自动判定、自动执行;其余故障以AI分析+人工一键处置为主,所有自愈动作均经过严格场景校验,优先保障业务稳定。
Q5:主Agent与子Agent的划分逻辑、核心价值是什么?
A:主、子Agent均为自研专属智能体,核心划分逻辑为调度中枢与场景执行分层。主Agent负责全局统筹、流程调度、任务分发;子Agent绑定专属用户、专属角色、专属场景,负责具体细分任务执行。核心价值是实现权限隔离、角色分工、场景细分,避免智能体越权操作,同时适配复杂运维场景的多任务协同处理,提升整体智能化效率。

