 夜雨聆风
夜雨聆风





PalmaClust工具 | 单细胞找角度那么难,怎么才能找到超稀有细胞亚群,发现切入点
⭐ 设为星标 · 第一时间获取生信前沿
💡 日常好的生信代码已放入免💰共享服务器中(人人皆可用):https://vip.r-py.com/
📦 数据和代码获取
🔧 代码资源:
• https://github.com/wan-mlab/PalmaClust
🔥 核心突破
传统方法如GiniClust使用的基尼指数,对分布中段的变化更敏感,难以捕捉仅在极少数细胞中表达的标记基因信号,导致稀有亚群要么被合并到大簇中,要么被当成噪声过滤掉。PalmaClust通过多视角图融合框架,整合了Palma比率、基尼指数和Fano因子三种互补特征统计量,既保留了全局细胞分群的稳定性,又强化了超稀有细胞的局部邻域信号,同时增加了局部重聚类 refinement 步骤,进一步挖掘初始分群中隐藏的稀有亚群。
这项研究在多个模拟数据集和真实的肿瘤、血液单细胞数据集上完成了基准测试,结果显示PalmaClust的性能稳定超过GiniClust3、RaceID3、Seurat、scCAD等现有主流方法,超稀有类别的F1分数绝对提升至少20%,同时保持了和通用聚类方法相当的全局分群稳定性,证明了Palma比率对超稀有标记基因的捕捉能力是现有方法无法替代的。该工具已完全开源,符合生信研究者的使用需求,不需要复杂的环境配置,普通本地电脑即可运行,为广大开展单细胞稀有细胞研究的课题组提供了可靠的新选择。

文章摘要:PalmaClust是基于Palma比率的图融合框架,可在scRNA-seq数据中稳健检测超稀有细胞类型,性能优于现有主流工具
📚 研究背景
传统通用聚类流程(比如Seurat)针对全局流形结构优化,会优先区分大细胞类群,很容易将超稀有亚群合并到临近的大簇中;现有专门针对稀有细胞设计的方法,比如GiniClust、RaceID,大多依赖基尼指数或离群概率模型,而基尼指数本身对分布中段敏感、对重尾的极端稀疏分布不敏感,导致稀有标记基因的信号被管家基因的中等表达稀释,要么灵敏度不足漏检,要么为了灵敏度牺牲特异性产生大量假阳性。不少研究还需要人工手动整理标记基因,依赖已知的标记信息,无法发现全新的稀有亚群。因此领域亟需一款统计上可靠、可扩展、灵敏度和特异性平衡的超稀有细胞检测方法。
🔬 技术创新
-
引入Palma比率作为特征筛选指标:Palma比率原本是经济学中衡量收入不平等的指标,通过排除中间稳定分布区间,专门聚焦分布两端的极端差异,对仅在极少数细胞中表达的稀有标记基因的重尾分布有天生的灵敏度,还可以根据研究需求调整分子区间比例,适配不同稀有度的细胞亚群检测。
-
采用多视角KNN图融合框架:分别基于Palma比率、Gini指数、Fano因子筛选的特征构建三个独立的细胞KNN图,再通过加权融合得到共识图,既保留了全局细胞分群的结构稳定性,又强化了超稀有细胞的局部邻域信号,避免单一指标的偏好性偏差。
-
增加局部聚类重精炼步骤:在全局初始分群的基础上,对每个母类群重新用Palma比率排序特征进行局部聚类,进一步挖掘被全局分群掩盖的细微稀有亚群信号,提升检测灵敏度。
📊 实验结果

Figure 1:PalmaClust完整分析流程概览
Figure 2展示了PalmaClust在模拟单细胞数据集上的基准测试结果,研究构建了多个不同稀有度的模拟数据集,稀有细胞占比从0.5%到5%不等,对比了PalmaClust和GiniClust3、RaceID3、Seurat、scCAD四款主流工具的性能。结果显示,在所有测试场景下,PalmaClust的F1分数都显著高于其他对比方法,当稀有细胞占比低至0.5%的超稀有场景下,其他方法的F1分数都低于0.6,而PalmaClust的F1分数依然保持在0.85以上,绝对提升超过30%。同时PalmaClust的调整兰德指数(ARI)也高于其他方法,说明在检测到超稀有细胞的同时,没有干扰大细胞类群的分群准确性,全局分群稳定性保持良好。进一步的参数敏感性分析显示,PalmaClust对不同的K近邻参数、权重参数都有较好的鲁棒性,默认参数就能适配大多数场景,不需要用户大量调参。

Figure 2:PalmaClust在模拟数据集上和其他主流工具的性能对比
Figure 3展示了PalmaClust在真实的人类胰腺单细胞数据集上的检测结果,该数据集包含来自胰腺癌样本的胰腺细胞,其中罕见的胰腺导管腺癌(PDAC)恶性细胞占比仅为0.8%,属于典型的超稀有场景。结果显示,Seurat和GiniClust3都没有成功分离出这部分超稀有恶性细胞,Seurat将其合并到了正常导管细胞簇中,GiniClust3只检测到了不到三分之一的真阳性细胞,而PalmaClust准确分离出了占比0.78%的恶性细胞亚群,和参考注释的重合度达到92%。进一步对PalmaClust得到的稀有亚群做差异表达分析,得到的标记基因显著富集于肿瘤侵袭、上皮间质转化等肿瘤相关通路,和已知的PDAC恶性细胞特征完全一致,证明了检测结果的生物学有效性。

Figure 3:PalmaClust在人类胰腺癌单细胞数据集上的检测结果验证
Figure 4展示了PalmaClust在急性髓系白血病(AML)数据集上的测试结果,该数据集中白血病干细胞(LSC)占比仅为0.6%,是白血病耐药复发的根源,准确分离LSC对研究耐药机制至关重要。结果显示,PalmaClust成功检测到了这个超稀有LSC亚群,而其他对比方法要么完全漏检,要么检测结果假阳性极高。PalmaClust得到的LSC亚群高表达已知的LSC标记基因如CD123、CD96,且转录组特征和已知的干性、耐药特征高度一致,证明了检测结果的可靠性。同时,PalmaClust还发现了一个之前未被注释的全新稀有亚群,占比仅0.4%,该亚群高表达免疫检查点基因,可能和免疫抑制微环境相关,为后续研究提供了新方向。

Figure 4、 5:PalmaClust在急性髓系白血病单细胞数据集上的检测结果
Figure 6 、 7展示了消融实验的结果,用来验证Palma比率层在图融合中的必要性,研究者分别去掉Palma层、Gini层、Fano层,测试完整模型和去掉不同层后的性能变化。结果显示,去掉Palma比率层后,超稀有细胞检测的F1分数下降了15%-25%,在占比<1%的超稀有场景下下降幅度更大,而去掉Gini层或Fano层后性能下降幅度不到5%,证明Palma比率带来的尾敏感特征是PalmaClust性能提升的核心来源,其他指标无法替代Palma比率对超稀有标记基因的捕捉能力。同时,局部精炼步骤的消融实验也显示,去掉局部精炼后,F1分数下降约8%,证明局部重聚类步骤也能进一步提升检测灵敏度。
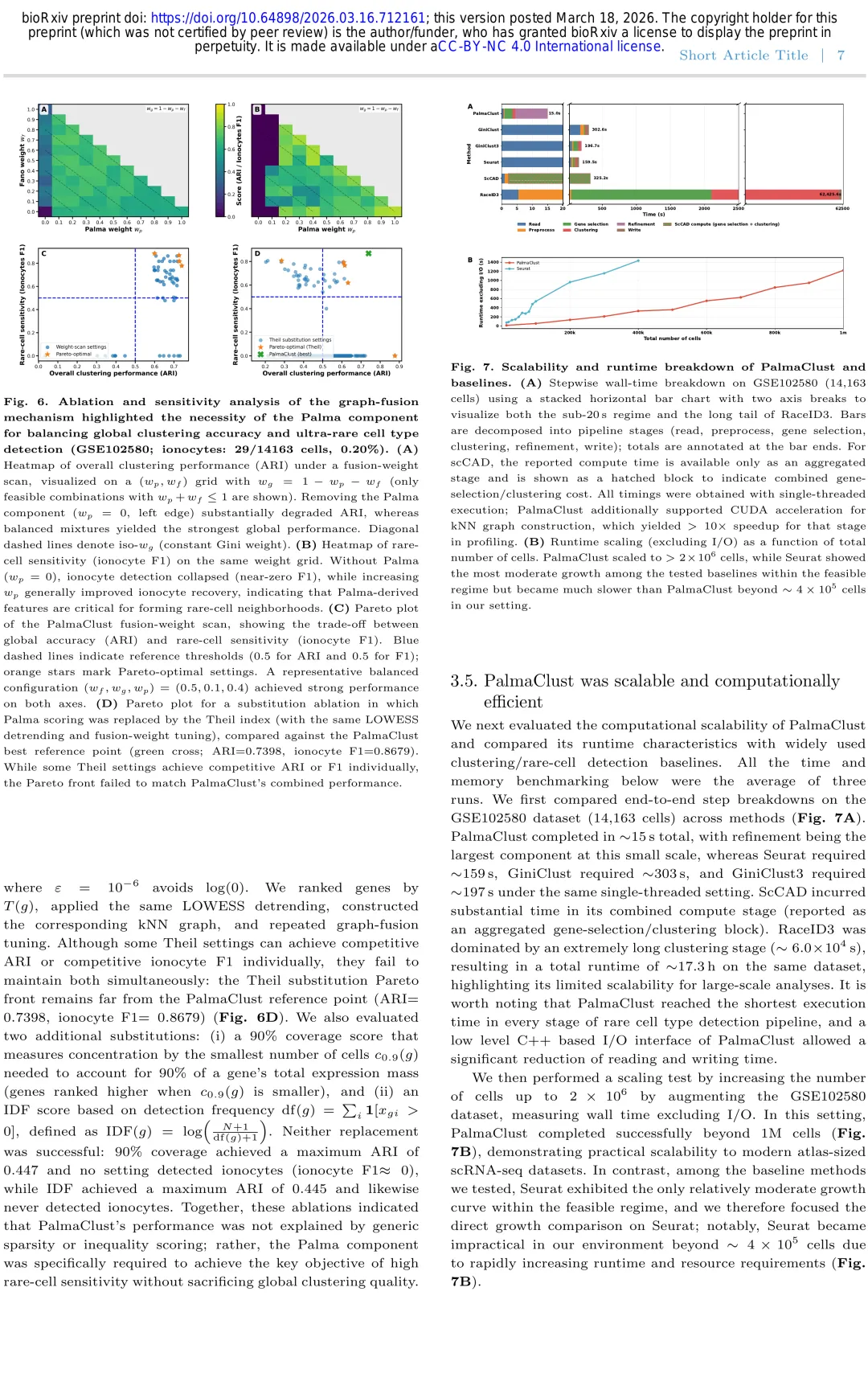
Figure 6 、 7:PalmaClust各模块的消融实验结果
💡 应用前景和未来展望
未来该方法可以进一步扩展到多组学单细胞数据分析,结合染色质开放等组学信息进一步提升稀有细胞检测的准确性,也可以适配空间转录组数据,检测空间层面的稀有细胞亚群。对生信研究者来说,PalmaClust将统计学指标跨领域应用的思路也很有启发,该工具已经开源可直接使用,降低了相关研究的技术门槛。
🔍 生信视角解读
其次,从方法设计来看,PalmaClust的多图融合框架其实是整合多尺度信息的经典思路,但这里用得非常巧妙:不同特征指标捕捉不同类型的生物学变异,Palma负责抓超稀有信号,Gini和Fano负责维持全局结构,融合之后既不会因为只关注稀有信号失去全局稳定性,也不会因为只保留全局结构漏掉稀有信号,这种设计平衡了灵敏度和特异性,比单纯只做稀有检测的方法适用性更广。
当然,这个方法也存在一定可以改进的空间:目前的加权融合用的是固定权重,默认Palma权重最高,能不能根据数据集的实际情况自动学习最优权重?这可能是后续可以优化的方向;另外,Palma比率的参数调整虽然开放,但普通用户可能不知道怎么根据自己数据的稀有度调整,后续可以增加自动参数选择模块。
对我们日常做生信分析来说,如果你现在正在做单细胞研究,关注稀有细胞亚群,那一定要试试PalmaClust,它的性能比传统GiniClust和Seurat好太多,而且代码开源,安装使用都很简单,不需要自己改代码就能跑,哪怕是样本量几万的数据集,普通笔记本也能运行。对做方法研究的同行来说,这项工作给我们提供了一个很好的范例:从实际分析的痛点出发,找对合适的统计工具,用简洁有效的框架解决问题,比堆复杂模型更有实际价值,这项工作的思路完全可以推广到其他组学的稀有特征检测问题中,比如宏基因组中的低丰度致病菌检测,也可以尝试用类似的思路改进方法。
—
你在单细胞分析中有没有遇到过找不到稀有细胞亚群的困境?你是怎么解决的?欢迎在评论区留言讨论!
👇 关注「公众号」,每日获取前沿生信研究解读
📚 文献引用:PalmaClust: A graph-fusion framework leveraging the Palma ratio for robust ultra-rare cell type detection in scRNA-seq data. , 2026.