 夜雨聆风
夜雨聆风





从文档孤岛到智能知识库:构建代码感知的四层知识管理体系

当技术文档遇上 AST 解析,如何让静态文档”活”起来,成为可检索、可引用、可验证的智能资产?
一、技术文档的困境:我们正在失去的知识
每个技术团队都面临同样的困境:
• 文档沉睡:需求文档、接口规范、数据字典静静地躺在文件夹里,版本迭代后无人问津
• 检索困难:PDF/DOCX 是二进制黑洞,全局搜索无能为力,关键词匹配如同大海捞针
• 代码脱节:文档描述了字段的业务含义,却不知道对应代码中的哪个类、哪个方法
• 影响盲区:修改某个字段或接口时,只能靠全局字符串搜索猜测影响范围,缺乏精确的引用分析
• 版本漂移:文档更新与代码重构各行其是,三个月后文档与实现已面目全非
传统的知识管理将文档视为静态资产,这是问题的根源。文档不应只是给人读的,更应该被代码引用、被工具理解、被系统验证。
二、破局之道:构建”文档-符号-代码”三位一体知识库
2.1 核心洞察:超越文本相似度搜索
传统的 RAG(检索增强生成)方案依赖文本向量相似度,这在代码生成场景下存在天然局限:
• 无法精确建立”数据库表字段”与”Java 实体类属性”的映射
• 无法追踪接口定义到 Controller 方法的调用链
• 无法评估修改某个字段的真实影响范围(引用计数、风险等级)
新的解决方案需要基于 AST(抽象语法树)的符号级理解能力,建立文档概念与代码符号之间的精确映射。
2.2 四层知识库架构
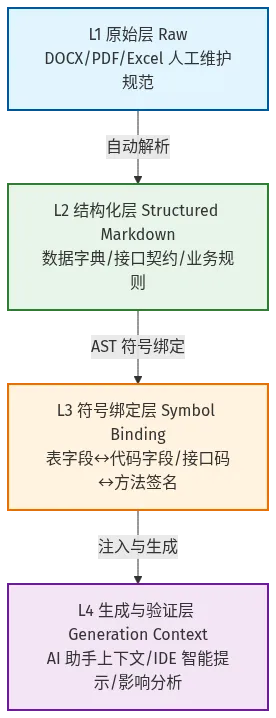
关键创新:引入 L3 符号绑定层,实现从”文本相似度”到”图遍历 + 符号影响分析”的跃升。
2.3 AST 解析工具选型
构建符号绑定层需要强大的 AST 解析能力,以下是目前主流的代码分析工具:
GitNexus:面向代码知识图谱的 AST 解析引擎
GitNexus 基于 tree-sitter 构建完整的代码抽象语法树(AST)和符号关系图,提供强大的代码理解能力:
• 符号级代码检索:精确到类、方法、字段的命名搜索
• 引用链追踪:自动发现符号间的调用、继承、实现关系
• 影响分析:评估修改某个符号的波及范围(直接/间接/传递依赖)
• 安全重构:基于 AST 的符号重命名,而非文本替换
典型应用场景:
# 查询 Order 类的所有引用点gitnexus impact --target "Order" --direction upstream# 获取 ResponseVo 的完整字段和方法签名gitnexus context --name "ResponseVo"
AI 编程工具的 LSP 支持
现代 AI 编程助手(如 OpenCode、Cursor、Claude Code)通过 Language Server Protocol(LSP)获得 IDE 级的代码理解能力:
• 实时代码分析:利用 LSP 获取当前文件的 AST、类型信息、引用关系
• 跨文件导航:通过 LSP 的 goToDefinition、findReferences 功能追踪符号
• 智能补全:基于 LSP 的代码补全建议,生成符合项目规范的代码
LSP 的核心优势:
• 与编辑器解耦,支持 VS Code、IntelliJ、Vim 等多种 IDE
• 实时增量更新,无需重新索引整个代码库
• 类型感知的代码分析,理解泛型、继承、多态等复杂语义
工具对比与选型建议
|
工具 |
适用场景 |
核心优势 |
集成方式 |
|
GitNexus |
批量代码分析、知识图谱构建、影响分析 |
完整的仓库级 AST 索引、强大的图查询能力 |
CLI + MCP 协议 |
|
LSP |
实时代码生成、IDE 内辅助编程 |
低延迟、与开发环境无缝集成 |
Language Server |
|
tree-sitter |
自定义解析需求、轻量级分析 |
解析速度快、支持 40+ 语言 |
原生 C 库/绑定 |
推荐组合:使用 GitNexus 进行仓库级知识图谱构建,结合 AI 工具的 LSP 支持实现实时代码生成辅助。
三、关键技术实现
3.1 文档结构化转换(L1 → L2)
将原始 DOCX 文档转换为带有版本追踪元数据的 Markdown:
---source_docx: "数据结构设计文档.docx"docx_modified_time: "2026-03-15T10:30:00Z"docx_checksum: "a1b2c3d4e5f6"converted_time: "2026-04-02T14:22:00Z"code_commit: "72da1d193"binding_version: "1.0.0"confidence: "verified"---# 订单主表 - 核心数据结构## 元数据- **主键**: order_id (BIGINT)- **存储引擎**: InnoDB- **对应实体类**: `com.example.domain.Order`- **对应 VO**: `OrderVo`, `OrderDetailVo`## 核心字段| 字段名(文档) | 数据库列 | 类型 | 必填 | 业务含义 | 实体类字段 ||-------------|---------|------|------|----------|------------|| orderId | order_id | BIGINT | Y | 订单唯一标识 | `Order.orderId` || userId | user_id | BIGINT | Y | 用户ID | `Order.userId` || status | status | TINYINT | Y | 订单状态 | `Order.status` || amount | amount | DECIMAL | Y | 订单金额 | `Order.amount` |
核心价值:
• 可追溯:通过 YAML frontmatter 记录文档-代码-索引的三向版本对齐
• 可检索:纯文本 Markdown 支持全局搜索、版本对比、差异分析
• 可引用:其他文档可以通过相对路径链接到具体字段定义
3.2 符号绑定层构建(L2 → L3)
利用 AST 解析工具(如 tree-sitter)扫描代码库,建立精确映射:
显式命名映射配置(naming-mappings.yaml):
schema_mappings:- table: "orders"class: "com.example.domain.Order"repository: "OrderRepository"service: "OrderService"confidence: "verified"interface_mappings:- code: "API_001"controller: "com.example.controller.OrderController"method: "createOrder"request_vo: "CreateOrderRequest"response_vo: "OrderResponse"confidence: "verified"
自动映射发现原理:
1. 表名 → 实体类:通过类名相似度 + 字段匹配度自动发现
2. 表字段 → Java 字段:通过注解(如 @Column)或命名约定匹配
3. 接口码 → 方法签名:通过 URL 路径、方法命名、参数类型综合匹配
3.3 符号绑定存储格式
数据字典绑定(schema-bindings.json):
{"table": "orders","version": "1.0.0","last_sync": "2026-04-02T14:30:00Z","entity_class": {"name": "Order","fq_name": "com.example.domain.Order","file_path": "src/main/java/com/example/domain/Order.java"},"fields": [{"doc_column": "orderId","db_column": "order_id","java_field": "orderId","java_type": "Long","getter": "getOrderId","setter": "setOrderId","references_count": 156,"impact_risk": "HIGH","validation": {"required": true,"min": 1}}],"repository": {"name": "OrderRepository","fq_name": "com.example.repository.OrderRepository"}}
接口契约绑定(interface-bindings.json):
{"interface_code": "API_001","doc_name": "创建订单接口","controller": {"class": "OrderController","fq_name": "com.example.controller.OrderController","entry_method": "createOrder"},"services": [{"name": "OrderService","fq_name": "com.example.service.OrderService"}],"vos": [{"name": "CreateOrderRequest","fq_name": "com.example.dto.CreateOrderRequest"}],"related_tables": ["orders", "order_items"]}
四、AST 增强的代码生成工作流
4.1 需求解析 + 符号路由
场景示例:用户要求”在创建订单接口的返回报文中增加 priority 字段”
智能助手执行流程:
1. 读取 L2 层文档:.knowledge/interface/API_001.md
2. 读取 L3 层绑定:.knowledge/bindings/interface-bindings.json,定位到 OrderResponse VO
3. AST 上下文获取:调用 context(OrderResponse) 获取当前 VO 的完整字段列表和方法签名
4. 影响分析:调用 impact(OrderResponse, upstream) 评估修改影响范围(哪些 Service、Controller 依赖此 VO)
5. 索引新鲜度检查:确认代码索引是否为最新版本
4.2 智能代码生成
基于文档定义 + AST 上下文生成代码:
生成规则:
• 字段命名严格遵循文档中的 JSON key(驼峰命名)
• 类型映射基于文档中的数据库类型 → Java 类型映射表
• 校验注解基于文档中的约束(如长度、必填、正则)
• Setter 签名与现有代码风格保持一致(参考 AST 解析结果)
4.3 双向一致性校验
|
校验类型 |
校验内容 |
工具/方法 |
|
Schema 一致性 |
VO 字段名是否与文档一致? |
规则脚本 |
|
类型一致性 |
Java 类型是否与数据库类型兼容? |
类型映射表 |
|
符号影响校验 |
修改是否引入编译错误? |
影响分析工具 |
|
引用完整性 |
新增字段的 getter/setter 是否被识别? |
引用计数 |
|
版本一致性 |
文档-代码-索引三者是否对齐? |
健康检查工具 |
五、风险管理与缓解策略
|
风险 |
等级 |
缓解措施 |
|
命名映射不准确 |
中 |
建立显式命名映射配置 + 人工 review 边界情况 + 置信度标记 |
|
索引过期 |
中 |
索引新鲜度检查 + 降级机制(使用历史映射 + TODO 标记)+ CI 自动更新 |
|
文档解析鲁棒性差 |
低 |
使用成熟库(python-docx)+ 异常处理和日志 + MVP 阶段人工校验 |
|
维护成本高 |
中 |
MVP 验证先证明价值 + 自动化工具减少人工操作 |
|
版本漂移 |
中 |
版本追踪元数据 + 定时对比文档/代码/bindings 三向差异 + 健康状态仪表板 |
六、预期收益:知识管理的范式转变
|
维度 |
传统方式 |
AST 增强知识库 |
|
字段扩展 |
翻文档 + 全局搜索 10-15 分钟 |
注入上下文直接生成,2-3 分钟 |
|
接口变更 |
容易遗漏字段或类型写错 |
精确绑定到 VO/Controller,错误率下降 90% |
|
影响分析 |
靠全局字符串搜索猜测 |
精确的引用链分析(直接/间接/传递依赖) |
|
重构安全性 |
手动 rename,容易遗漏引用 |
符号级安全重构,自动更新所有引用 |
|
新人上手 |
背诵大量规则 |
通过导航表 + AST 可视化快速理解代码结构 |
|
一致性维护 |
代码与文档经常不同步 |
自动检测三向差异,主动提示更新 |
|
知识沉淀 |
经验在专家脑海中 |
显式化为可查询、可验证的知识图谱 |
七、关键成功要素
1. 渐进式推进:从最小可行方案开始验证,证明价值后再全面投入
2. 显式映射:不依赖模糊的自动发现,建立可维护的命名映射配置
3. 版本对齐:文档、代码、索引三者版本必须可追溯、可校验
4. 工具链整合:将知识库检查纳入 CI/CD 流程,确保知识新鲜度
5. 降级机制:当 AST 索引不可用时,有历史映射信息作为备选
八、结语:让文档回归本质
技术文档的本质是知识载体,而非静态文件。
当文档能够与代码符号建立精确绑定,当文档修改能够自动触发影响分析,当文档定义能够直接指导代码生成——文档就从”负担”变成了”资产”。
这不仅是工具链的升级,更是知识管理思维的转变:从”写文档给人读”到”建知识库给系统用”。