夜雨聆风
夜雨聆风





某笔记app深度混淆魔改md5逆向思路
前言
看标题大家都知道是哪个软件了,由于特殊原因,本文作为发布各平台的免费文章因为传播性会更广 所以不会去写那么直白的,而且本文也重点讲其中最核心的魔改md5算法的逆向思路,文中会附带我自己开发的逆向工具使用;会的朋友可以选择跳过本文了,当然你也可以看看我的分析方法,估计和你的会不太一样
这里的样本是9.24.0,是最新版;不过初步看和其他版本差不多,除非使用太老的版本的话好像说没有魔改md5,这个我不是很清楚了,没有验证。
我希望通过这个文章能够给大家讲明白魔改md5的一种通用打法吧,因为这个案例魔改点位非常的多,而且还经过了定制化的ollvm,以前的方法基本都失效了,基本上也别指望ida了,老老实实看trace了,但是看trace还不让你省心,因为存在一个hmac,这会导致交叉多轮md5。。。 这时候你跟trace一定要跟紧了。
参数逆向整体流程
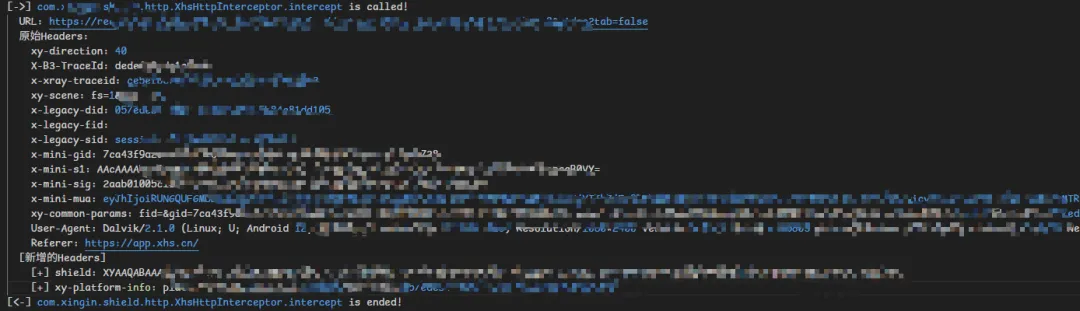
shie** 参数 在哪生成?怎么hook到的?
首先抓包看一下,看一下ua如果有什么okhttp那么大概率是okhttp框架,如果是http协议也可以默认大概率是;如果抓不到或者是其他情况就需要小心,其他协议或者其他框架了;
那okhttp又怎么hook呢?这里需要知道一些开发知识,首先,这个header参数是很多请求都有的,那么他大概了不会针对某一个请求来添加header参数,而是用一套可以复用的逻辑来添加header;
这在okhttp中就是典型的拦截器了,举一个生活化的案例,处理污水,污水流经某一个管道,你加了点试剂让他沉淀,这样流经的所有污水都会被处理;这在okhttp框架中就是拦截器机制,这个机制太常见了,常见到你在很多开源工具都能看见;
本质:统一处理链(Interceptor Pipeline)
那我们怎么定位他某一个拦截器添加了header呢?你得先 hook 到他添加了哪些拦截器,然后在去 hook 这些拦截器的实际拦截函数,然后进入和退出的时候打印一下header,也可以做个diff对比,这样你可以知道 拦截器1加了shie** ,拦截器2加了x-mini-sig;
效果图如下:
2. 怎么用unidbg来补?
在native层,这个可以用unidbg来补,主要难点就是okhttp框架的一堆东西,这个可以在unidbg的pom.xml中引入okhttp框架,往上文章太多了;
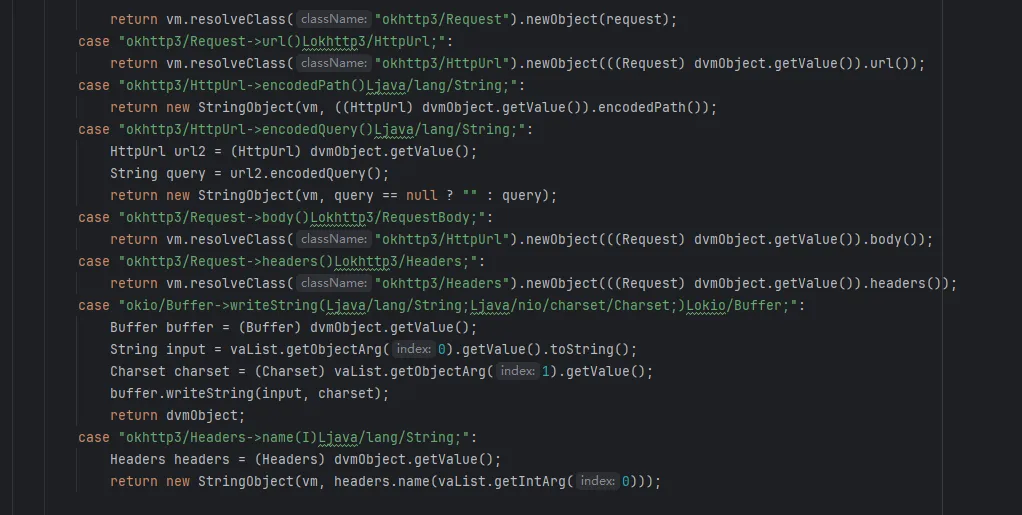
而这个案例呢,要用unidbg补的话你最好是利用jnitrace看日志然后补,不会补可以看网上文章,或者直接丢给ai来补;最后补出来会在某个jni日志看到shie** ;这个过程需要一定的耐心

3. 关键数据 切分多部份
这里我就省略了前期的部分字节的逆向过程了,主要就是16+83 字节,后面83字节是什么rc4得到的;然后83字节中又有好几部分,其中最后一部分是16字节,是魔改md5
4.魔改MD5特点
-
1. 初始变量改了, 不过只是部分交换;但是要怎么确保用的是对的?? 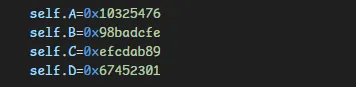
-
2. 64轮的函数由于恶心的ollvm导致完全展开,ida是真的基本看不了一点; 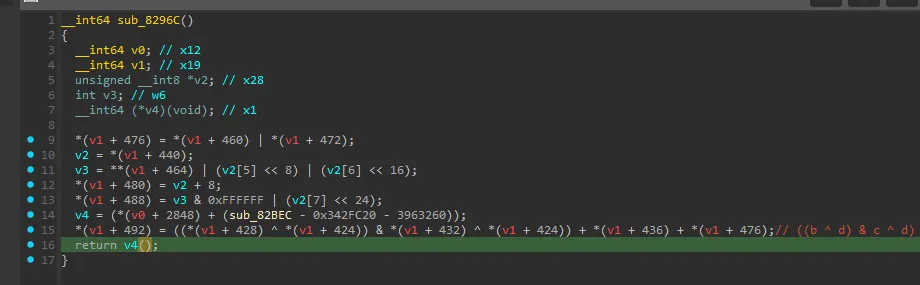
-
3. T表全换:可以从trace中定位偏移规律,然后找到存在ida中的位置,然后写ida脚本 dump出来,也可以找trace规律写正则脚本提取 -
4. T表轮间乱序:但T表dump出来的还不行,中间md5的64轮 某些轮次(比如39和40)之间还有交换,所以你会看到T表乱飞的情况,要同步改 
-
5. 这个乱飞的过程实际上是很恶心的;如果你只是简单交换T表是不行的,因为他的abcd也有不同, 所以有的时候要用展开的md5写法才行 -
6. 整个md5涉及的所有变量都是一个地址,不管是abcd还是f,还是中间变量,全是查表+偏移的,基本上用不了;类似什么v1+496 v+520这种,然后还不是所有的都是查表+偏移,而且偏移是在移动的,有点类似于滑动窗口的样子?? 具体看前面的图 -
7. 然后为了计算一次hash 会md5 多个64字节的情况,这一点你需要计算出80后面的长度位然后计算字节来判断;但是你还得知道多轮md5到底是怎么做的; -
8. 我们可以利用一些规律,比如第一次的md5和第二次的md5在 64轮的第一轮的T表都是一样的,然后作为锚点,借机找到明文加载的pc地址,然后写批量脚本提取每一轮md5的明文; 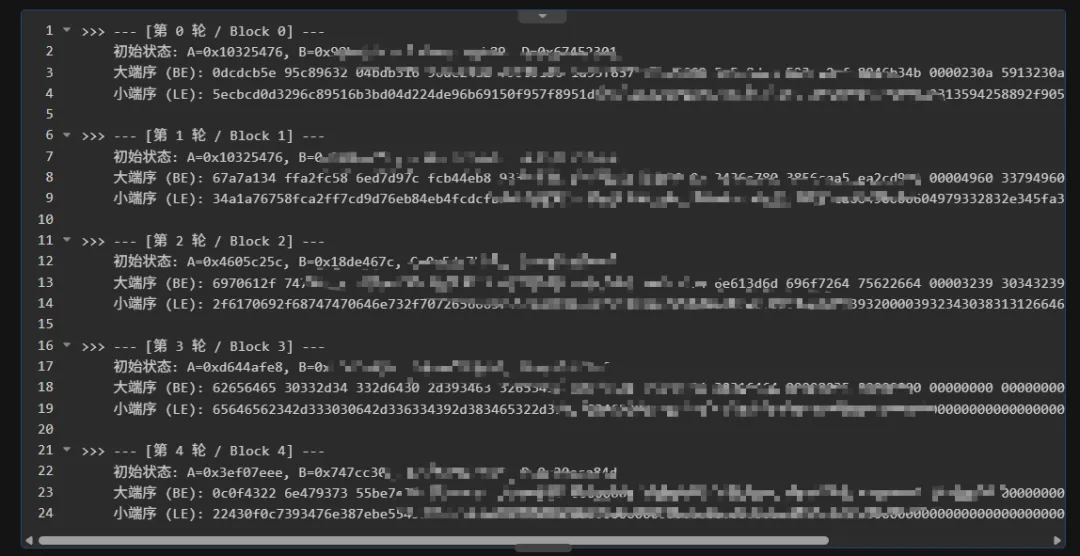
-
9. 但是这里还会出现某一轮特殊的情况;其实原因是因为他是多次md5交叉的情况,你在trace中会看见5次md5,那么哪几次是连续的??要怎么根据trace日志还原呢? -
10. 还有就是怎么识别出hmac吧。虽然其实你知不知道hmac都不影响算法还原,因为可以视作两轮hash和两个salt;但是如果知道的话,你在逆向的过程肯定是能省一定时间的,而且写还原算法会简洁一点 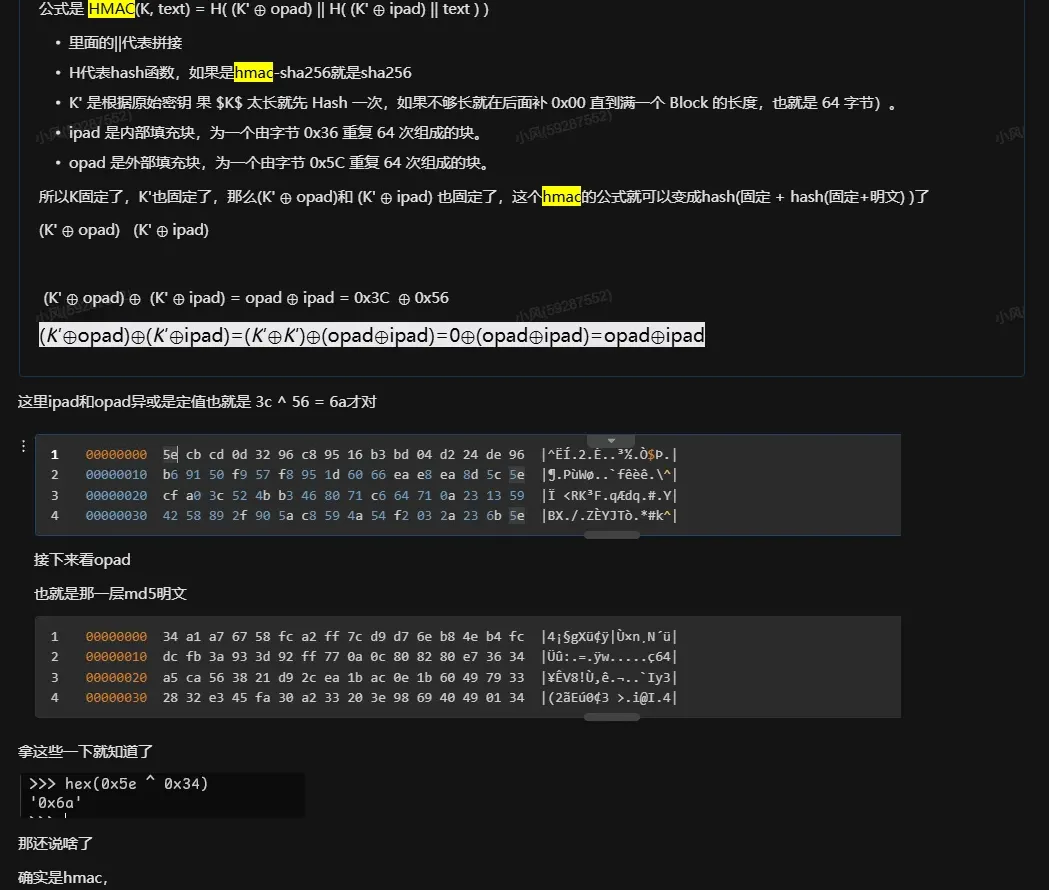
✔ 静态分析基本失效✔ 必须依赖 trace✔ 需自动化辅助
深度魔改+混淆的md5通杀打法
首先必须trace;
下面的讲解如果看不懂的话,建议关注我的同名b站账号,我今天会出一期进行讲解,会比文章详细得多,因为文字有的时候描述不清楚;
初始 abcd 定位
下面我画个图,圈一下涉及到的初始abcd
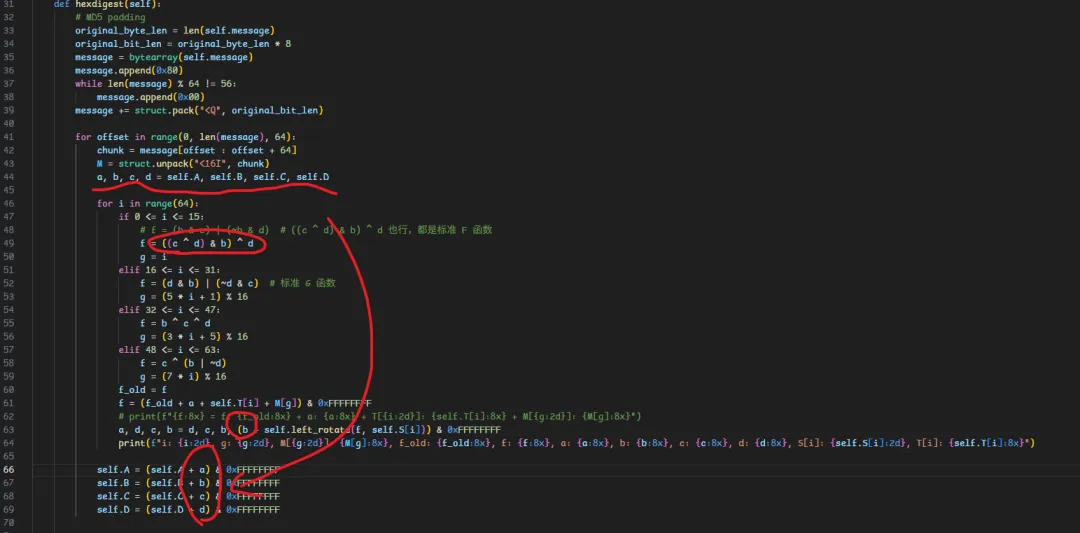
关键点与正则搜索规则
-
1. 第一轮参与: 第一处是参与64大轮的第一小轮,但是你怎么保证你的a不会看错d?b和c不会看错?如果是b的话都好说,应该还有其他特征 -
2. 最终累加:第二处是末尾的和算法出来的abcd相加,这一点是非常有用的,下面给两个trace日志比如我这里的是 ef29bddaca2a67b2dcff858ad588a2b6,那么根据端序还有md5特点,我知道 dabd29ef 是a,而且这个a应该是两个值加出来的,所以汇编中用正则来搜肯定是add.*=>.*=0xdabd29ef
接下来要进行候选判断 :搜出来了0x9bccab01和0x3ef07eee就可以思考谁是原始的a,谁是64轮的a了?这时候如果我们找到了4个初始的abcd,那么这两个中间肯定有一个是,哪个是,哪个就是初始a,另一个是64轮算出来的a;3. 那么这时候就取决于你知道的条件了,因为要根据这个算法的魔改程度来判断;
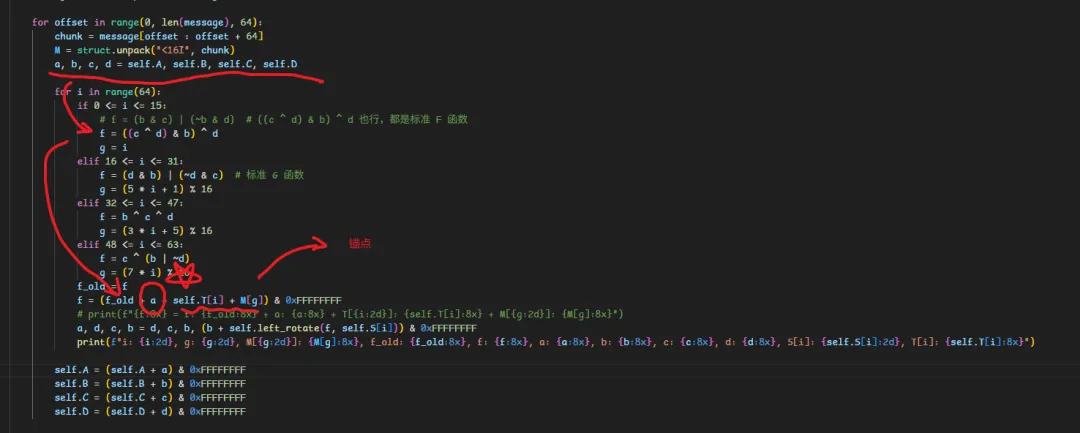
-
• 是否参与第一轮 -
• 是否参与累加 -
• 是否符合 T / f / M 关系 -
1. 首先要明确我们可以知道些什么东西? 首先密文的16字节你肯定是知道的,那么也就是说最后的abcd你是知道的 -
2. 那么最后的abcd是从64轮算出来的abcd再加上原始的abcd来的;这时候你就知道谁是a,谁是b了;
极端情况(啥都不知道)
突破点:
-
• f_old -
• T -
• 明文
接下来就可以重点突破这几个地方;这里假设他都魔改了,那么我们先突破一波明文
明文恢复
方法:
-
• 扫描 0x80 padding -
• 定位写入点 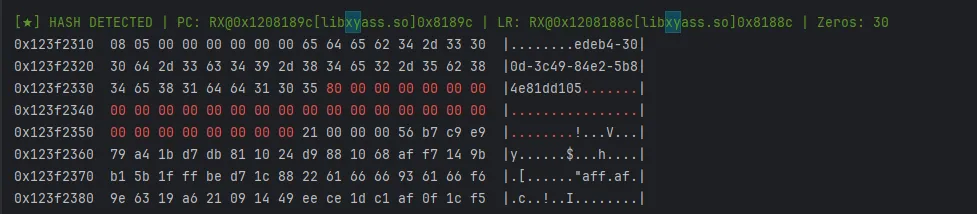
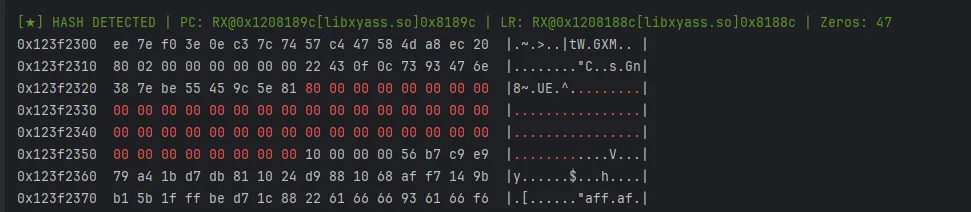
比如这个app的案例,这里就是hmac所以有两次hash,全被我逮到了;
换别的大厂看看; jd/ks
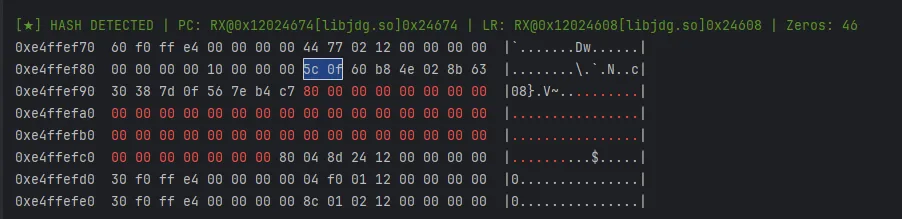
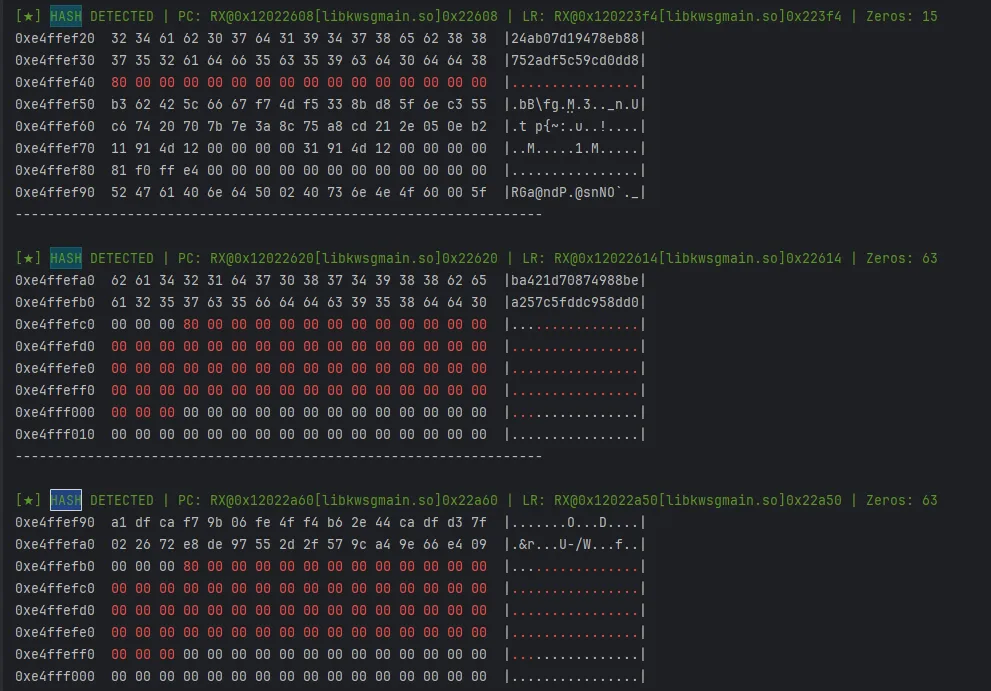
这里是适配使用了md结构的hash,包括md家族和sha家族的hash;还有别的扫描方案,其实我感觉大家都会写代码,直接让ai给你写一个就完事了,不过需要加过滤条件才能稳定,不然的话可能2000-3000条日志,这种就失去了意义了;所以如果需要的朋友进我星球自取吧,一是我能赚点米,二是我后面也还有更新,为了这东西单独发篇文章说明更新了什么没啥意义。
这样我们就可以知道他在哪写入0x80了,我们可以根据pc和lr地址跳过去分析了;这时候你就可以找到他魔改md5的函数入口,可以hook拿到输入和输出
MD5 特征:必有 0x80, 除非他魔改掉这个字节
T表恢复
通过前面的明文,还有a,那么我们就差f_old和T了,这时候你只需要知道谁是参与&、^、| 算出来的谁就是f_old,谁是固定ldr出来的,谁大概率是T;
比如我们前面不是搜到了 [libxyass.so 0x12000000+0x84010] 0x12084010: "add w8, w11, w8" ; w11=0x9bccab01 w8=0x3ef07eee => w8=0xdabd29ef 么
然后这里的0x9bccab01 和 0x3ef07eee 肯定有一个是b,然后我们直接往上翻这几个东西

结果在这里就翻到了第一个值是经过ror得到的,那不就是f么,所以0x3ef07eee 是b
所以0x9bccab01 是被0xb025f196左移得到的,那0xb025f196是f,f = f_old + a + T +M[g]
然后你的a,M都可以知道了,那么T不就确定了?
这时候你就知道T了,然后你如果知道了第二轮的T。第三轮的T,那你可以利用ldr的规律找到他们的加载偏移,从而找到最开始的点位,直接dump。64个T出来;
-
1. 如果64轮的每一轮的代码是通用的,你可以根据pc来搜到下一轮T的加载; -
2. 但是xhs这里是64轮完全展开的,每个pc都不一样,所以要找规律
这时候还能推出b来:你可以借助第一轮的abcd得到f_old,也可以通过&^|排查出来, 还知道T, M还知道左移,你可以算出第一轮新的b
64轮之间的关系
md5的64大轮本质就是生成了64个新b
把md5函数打开,然后每一轮输出下图这样的日志,那么你就可以根据这里的b去trace中搜,如果搜到了,大概率那一轮及以前算的没问题,这时候如果错了,可以利用二分法来定位哪个b算错了,这时候可以排查出到底是哪一轮及以前开始出问题了。这个过程中可以关注f函数是否魔改? 左移量是否魔改? T表是否魔改?明文块是否交叉?这个案例中,除了f函数没有魔改意外,其余全部都会出现。。。所以你一定要会这个逐步定位错误点的问题。
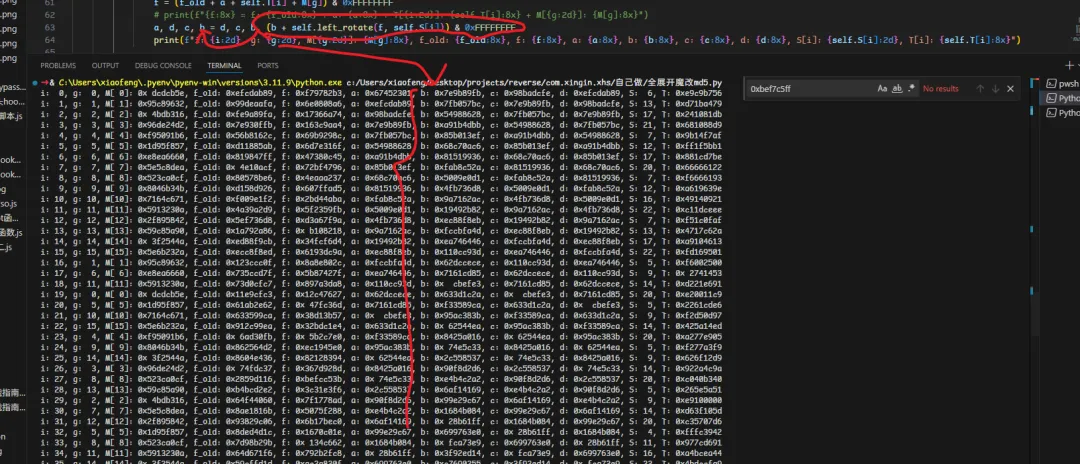
公式可以看上图
新b = 上一轮的旧b + f被左移后的值
这里是算出一个f然后和上一轮的b相加得到新的b,那么你如果知道了上一轮的b,你是不是可以根据add.*上一轮的b 然后搜到下一轮的b的生成点位?比如上一轮的b是0x7e9b89fb 那你就可以写正则:add.*0x7e9b89fb.*=>.*

这里为啥会有两个,因为abcd在64轮中 会有轮转,可能在某一轮就变成了a然后和某个值add了得到了f,这里简单排除一下就知道了,肯定是最早的。
然后你就知道下一轮的b是0x7fb057bc或者0x77ec1bb1; 这时候你可以排除一下,可以根据pc地址跳过去看看谁可疑? 还可以根据这两个值得生成,比如第一个值”add w8, w8, w6″ ; w8=0x114cdc1 w6=0x7e9b89fb => w8=0x7fb057bc那么我可以搜0x114cdc1是不是经过了左移得到的:

比如这个图,就很明显了对吧。那么你就从第一轮一直可疑延续到64轮结束,这个过程会很累,有没有什么办法批量?
正则 提取 左移量/T表
-
• 批量提取 f -
• 二分定位错误 -
• 批量验证 b
在这里实际上不是很好搞;但是还是值得的,因为我64轮主要逆向的是20轮左右,其他的都是写脚本dump出来的常量然后再改的;比如你发现左移的汇编大部分都是如下:

那么你就可以根据f要准备左移得到新的f,这个新的f会和上一轮的b相加,对吧,那你可以利用这个过程,写正则脚本,然后提取出相似的汇编块,注意这几句汇编可能中间是有其他汇编的,所以你写的模式最好是智能一点:
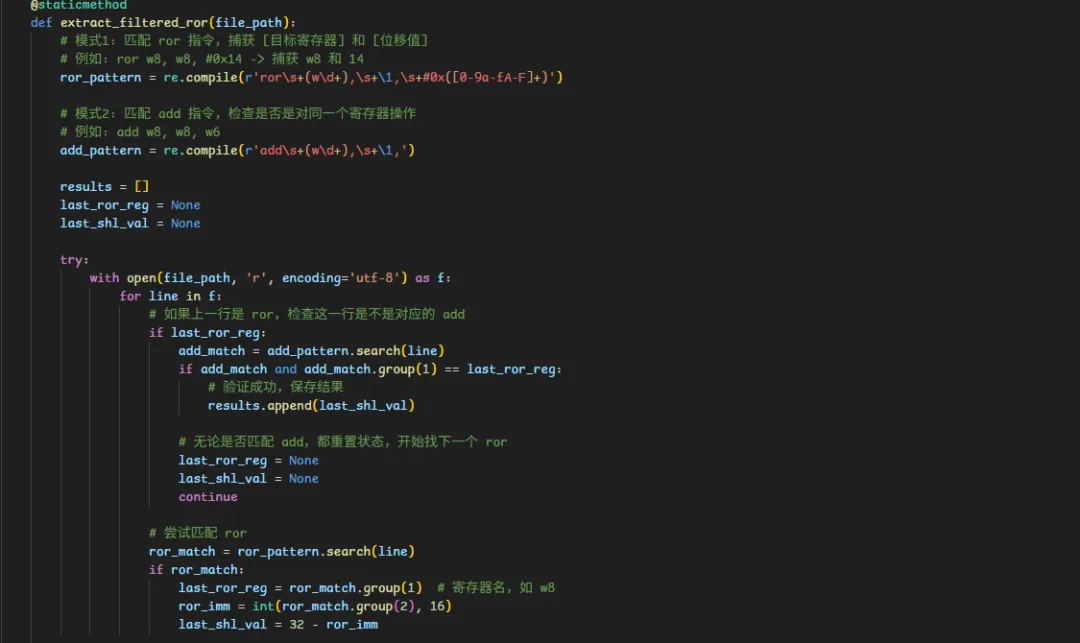
比如我在这里根据这个规律来进行匹配,然后筛选出了250多个左移量,那我就得根据我前面手动逆向的得到的6,11,23,然后在这个250候选里面找到,然后取连续的64个左移量,然后再尝试,如果不对的话,那么就是我的匹配算法没写好;当然会出现你匹配了前10个,但是后6个没和前10个连续,这时候也没事,再对后6个的前几个进行逆向就可以了,然后再去切片中找,这个样本因为存在多次交叉md5所以左移量是交叉的,这时候用我上面的打补丁的方案可以搞; 如果是普通案例,只需要匹配出来就直接薄纱了;甚至如果是没咋ollvm的,如果64轮的每一轮左移量的汇编pc都差不多,你都可以根据pc地址直接搜到那一行然后提取出左移量;
T表同样是可以的
不同次md5的明文正则提取
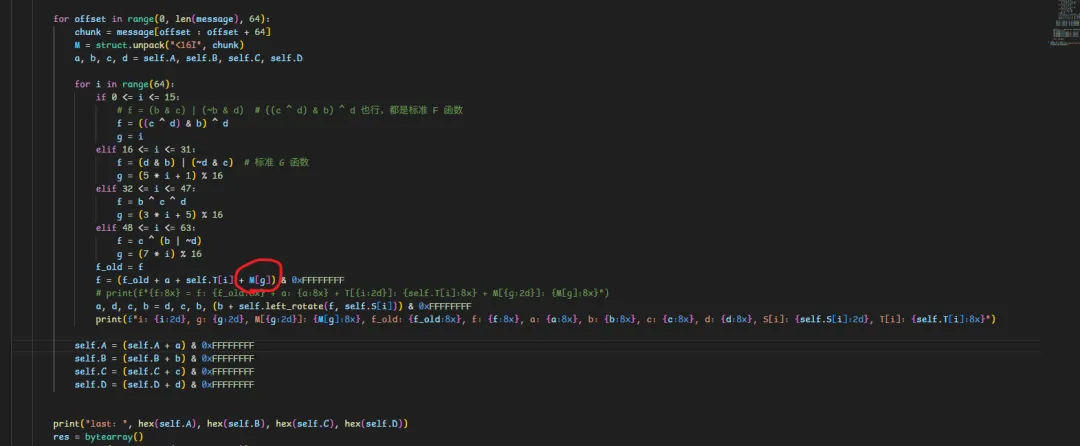
这里可以发现明文是每一轮都会用的,然后会算出一个g的index,从而切片出来,然后第一大轮的g就是循环的索引,那么我们第一大轮0-15,每次4字节,就可以提取出完整64字节了,这在后面写脚本提取出5次md5的明文非常有用;
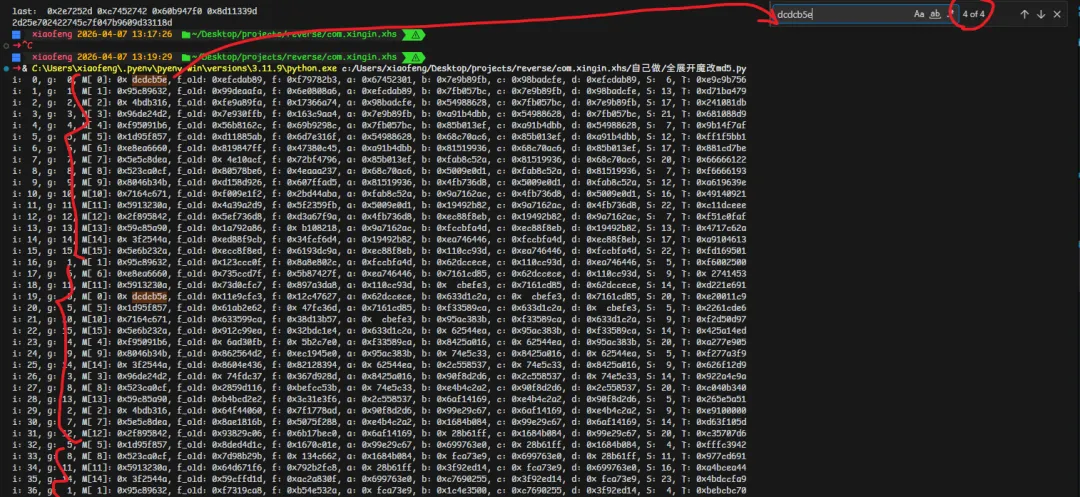
看日志会看的很清楚,这里面可以看到第一大轮明文是连续的,如果我们要提取每次md5的明文就可以利用这个规律,然后连续提取,组成64字节即可。还有就是64轮中每个明文块会被使用4次,对应4大轮, 这个和g的设计有关,详情请看md5理论设计论文或者其他理论博客;
然后每一次的64轮ldr明文的pc都是一样的,只需要根据这个pc搜,然后提取寄存器的值就行了;
分块 MD5的特点
首先看源码:每64字节是一组,然后每组都会生成更新一波self.A BCD然后下一次md5的第一轮内循环又把上一次md5的abcd作为初始值来进行运算,所以你如果是3次md5,那么前两次肯定都是64字节,然后第3次因为要留8字节长度位,还有0x80的填充位; 所以你可以根据长度位来判断出前面到底有几次,比如这个案例中发现后面的长度位是508,那么0x508/8=1288/8 =161=128+33,也就是两个64字节+一个33字节。
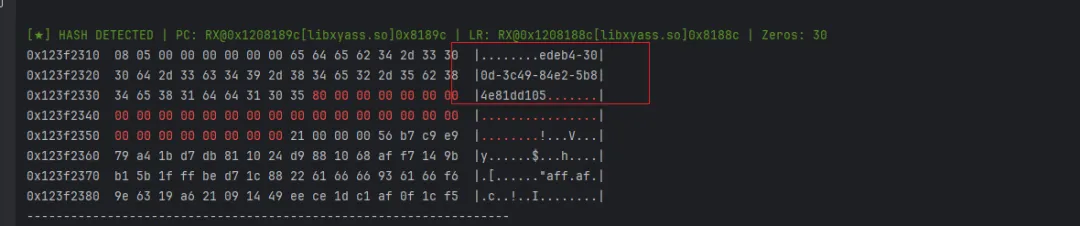
我们前面写的内存扫描插件因此不能捕获完整明文的原因就是因为这个,因为前两个64字节不填充md5啊,所以拿不到明文。。。。这时候可以根据实际内存中的明文块包含的长度位来判断;所以相当于也是一套闭环打法了。
那么逆向到底怎么打呢,这个可以看我日这个案例的详细文章还有视频,在这里讲不清楚;简单说就是把md5的填充给干掉,然后用填充好的64字节,并且把长度位改正确掉,如 65646562342d333030642d336334392d383465322d35623834653831646431303580000000000000000000000000000000000000000000000805000000000000 这在后面80后面最后还有什么8050的长度位。
然后去trace中找到初始abcd,然后直接开始还原这个魔改md5,然后呢,还原完毕后;再利用前面提到的明文提取脚本,提取出每一次的md5 64字节明文以及初始abcd,然后都跑一下,算出来第64轮的abcd,这时候会有一个衔接的过程。
总结一波就是 链式结构
明文1 → MD5 → abcd1abcd1 → 明文2 → MD5 → abcd2abcd2 → 明文3 → MD5如 标准abcd 明文1算出来 abcd。这个abcd是下一次md5的初始值,然后再算出来abcd这时候是第3次md5的初始值,那么你就可以把三个明文块连在一起,然后使用第一轮的初始abcd,来跑算法了。
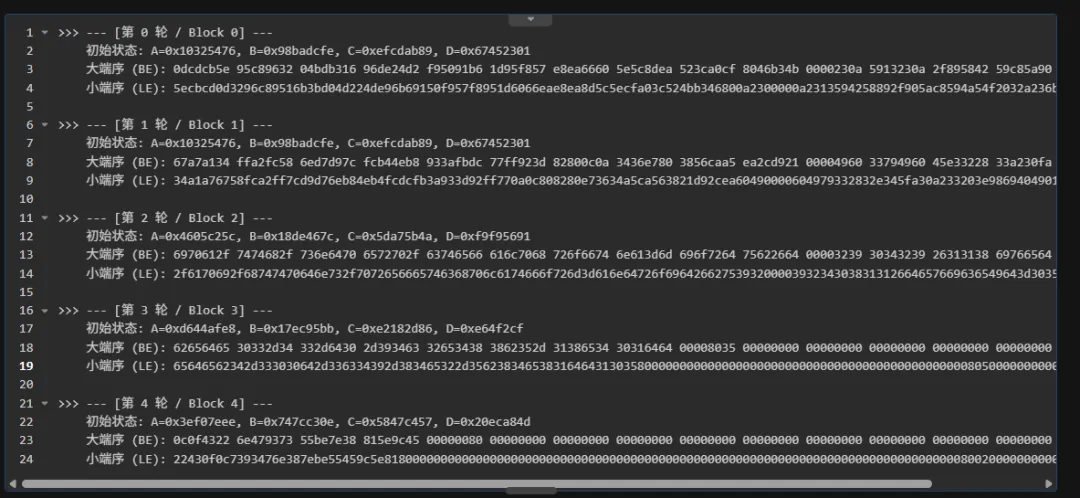
类似这张图里面存在两个md5,然后某个md5有三块64字节,有一个有两块64字节,这个过程还是交叉的哈哈哈哈。
这时候你再去掉第三轮填充的0x80,0x00以及长度位就拿到明文了;这个过程可以应对超过64字节的明文的md5,还可以应对hmac(天生就超过64字节,因为ipad和opad本来就是64字节)。
HMAC
直接用通俗的说法来吧,如下:
-
• 两轮 hash -
• 两个 salt(ipad和opad)
可直接视作多轮 MD5
整理一波 完整还原流程
-
1. 找初始 abcd -
2. 用插件扫描0x80,提取写入0x80前的64字节明文 -
3. 拿标准算法来改 -
4. 逐轮对比计算定位魔改点 -
5. 如果有多块64字节,就先找到初始abcd(这时候就认为是魔改的iv就行),然后从最后一块开始逆向,然后去掉填充部分,然后还原算法;然后再去还原上一块是怎么生成abcd的,直到根据内存中的明文长度比特位;
下面是涉及到的一些核心能力:
-
1. trace分析 -
2. 正则提取 -
3. 自动化脚本 -
4. 64轮二分定位错误点