 夜雨聆风
夜雨聆风





多智能体金融文档处理怎么选?纽约大学对比 4 种架构,高准确率不等于好方案

一、金融文档为什么难抽
这套数据集包含 10000 份 SEC 申报文件,其中 10-K 和 10-Q 各有 4000 份,8-K 有 2000 份,覆盖了财务指标、治理结构和高管薪酬三类字段。这里10-K 可以理解为年报,10-Q 是季报,8-K 更像重大事项的临时公告。三类文件的长度、结构和披露习惯差别都很大,所以这篇论文测的并不是一种单一文本抽取任务,而是一组难度不同的问题放在一起做比较。
这里的难点主要在于很多值要跨表、跨段落、甚至跨不同披露口径去对齐。这也是单提示抽取几个老问题了,上下文窗口限制会迫使切块,切块之后交叉引用关系就断了,复杂字段上幻觉会增加,而且缺少验证环节时,错误发现的不及时。
所以这篇研究是想看看哪种组织方式更适合把复杂抽取任务拆开再收回来。它比较了四种架构。顺序式是前面产出的上下文一路传给后面。并行式是把财务、治理、薪酬这些子任务拆开同时做,最后再合并。分层式加了一个监督者,由它分配任务、检查置信度、决定要不要重抽。反思式则引入验证和纠错循环,结果不通过就回去改,最多迭代三轮。这个差异,决定的不是表面流程图,而是成本结构和错误传播方式。

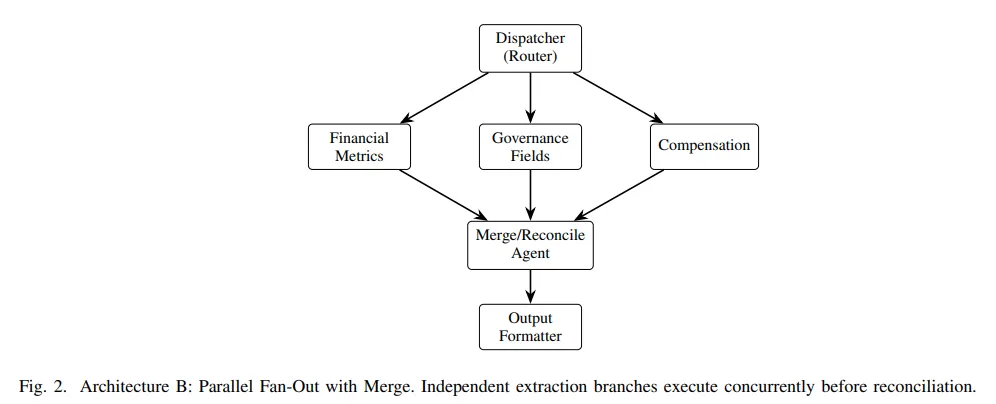
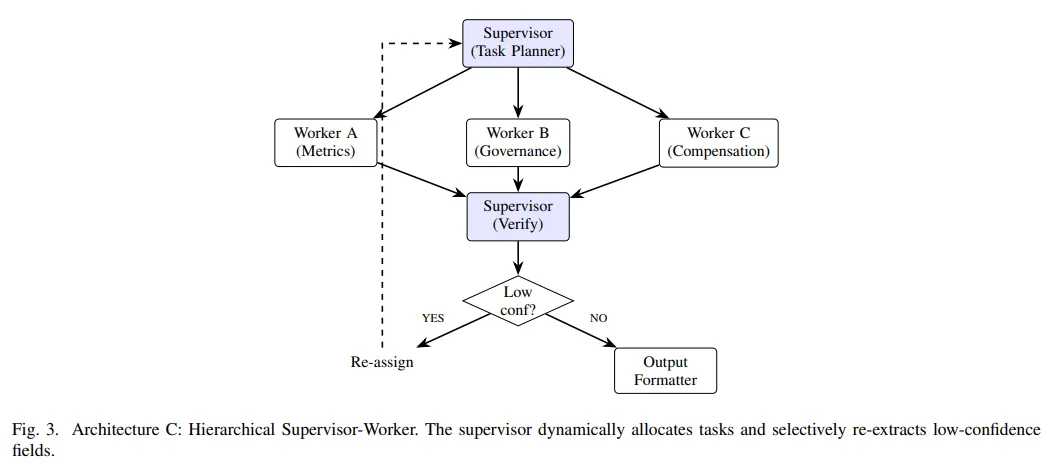
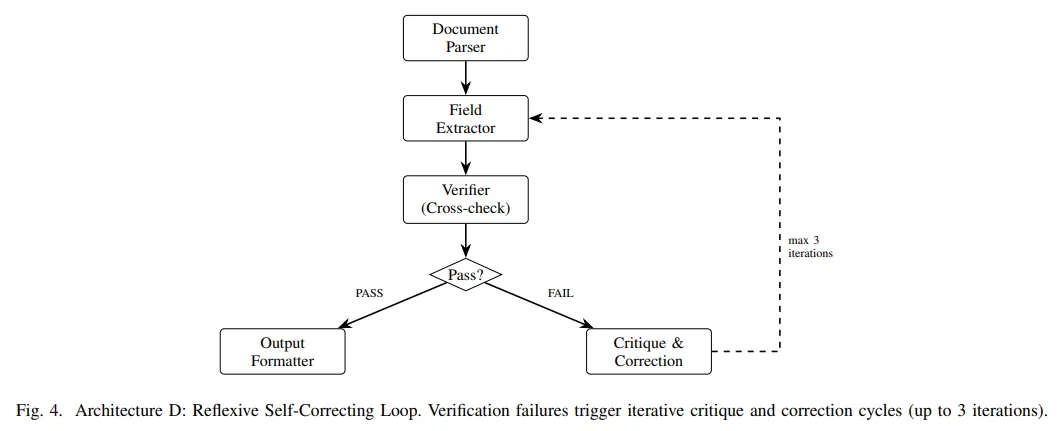
二、四种架构的差异
只从概念上看,分层式和反思式都像是在给系统“加脑子”。但分层式聪明的地方是让监督者根据复杂度分配任务,对低置信度字段选择性重抽,并且允许复杂字段用更强模型,简单字段用更便宜模型。研究把监督者的置信度阈值校准到 0.85时,重抽最多两轮。你得承认,金融抽取里不是每个字段都“一碗水端平”。
而再看反思式,它会做格式检查、跨字段一致性检查,以及来源扎根检查。比如资产负债表恒等式、薪酬合计、数值是否真能在原文找到支撑。这么看的话,这套机制更完整,准确率也确实最高,但它的问题是每多一次验证和纠错,延迟和成本都会往上抬,这种抬升还不是线性的。复杂文档会卡在循环里。到了负载高的时候,这种不确定性会直接变成排队和超时。
三、实验的观察框架
于是研究把四种架构和五个模型交叉组合,放进同一套任务里做测试。任务一共 25 类字段,落在财务指标、治理结构和高管薪酬三组问题上。评估不只看字段级 F1,还同时计算文档级准确率、端到端延迟、单文档成本和 token 效率。
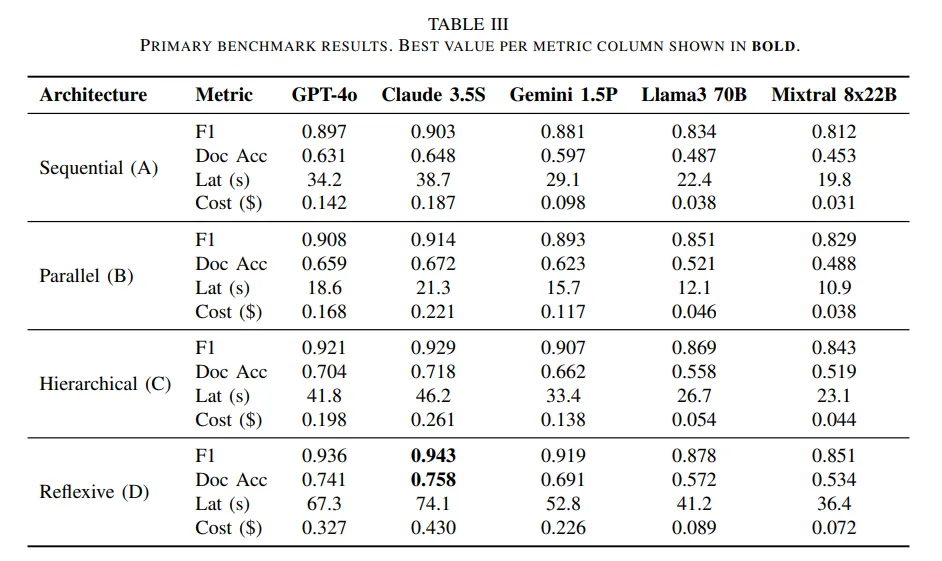
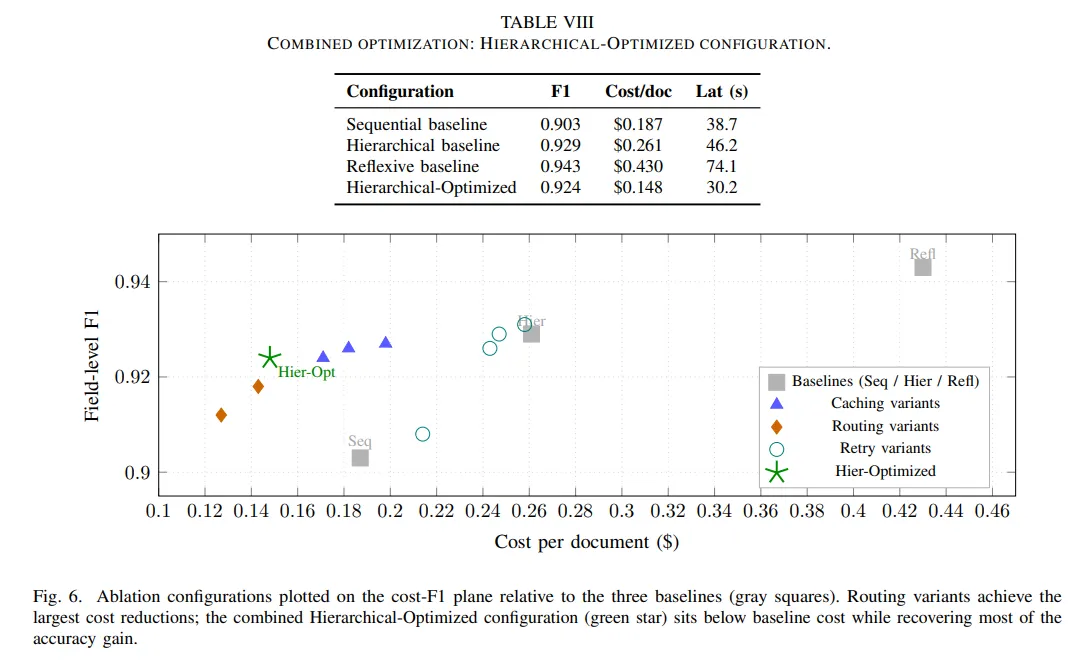
实验阶段,以 Claude 3.5 Sonnet 为例,顺序式字段级 F1 是 0.903,分层式是 0.929,反思式是 0.943。单看准确率,反思式最好。但把成本视角加进来,感觉就有点变化了。顺序式单文档成本是 0.187 美元,分层式是 0.261 美元,反思式则到了 0.430 美元。也就是说,反思式从 0.929 提高到 0.943,代价是从 0.261 再跳到 0.430。而并行式处在另一头,准确率只是略涨,延迟明显下降,更像是为低时延场景准备的方案。
四、成本是怎么降下来的
从分领域结果看,最容易做好的其实是财务指标。这部分内容往往写在格式比较稳定的财务报表里,模型更容易定位;就算抽取有偏差,很多数字之间也能互相校验,容错空间比治理字段和薪酬字段大一些。治理字段的难度处在中间。这部分难点主要由于披露用语并不统一,同一个问题在不同公司文件里可能有不同写法。而最难的还是高管薪酬,因为这里既有分多年归属的奖励安排,也有目标值和实际发放值的区分,模型在抽取时很容易把不同口径混在一起。
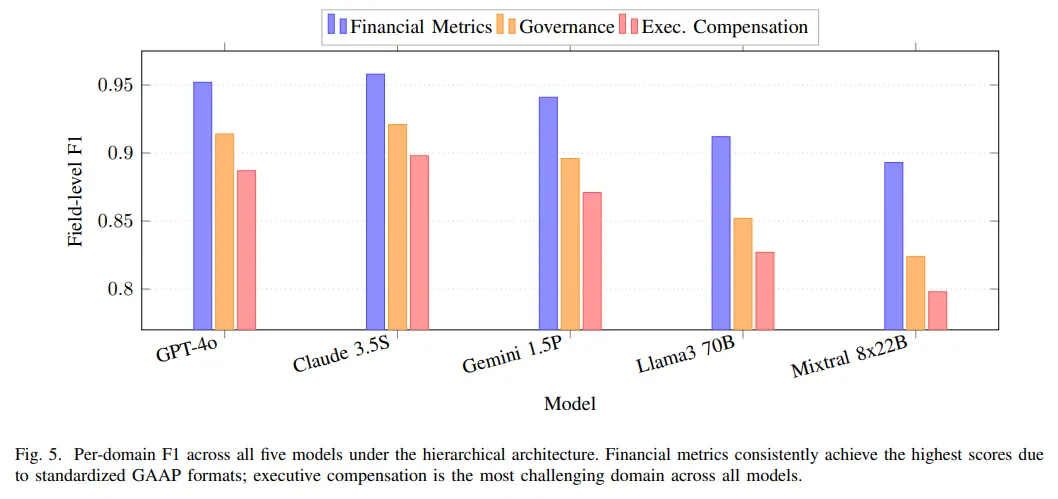
而接下来的这组消融实验则解释了系统里的成本和效果,究竟是被哪些具体设计拉开的。
语义缓存可以直接压低成本,字段级缓存把成本从 0.261 美元降到 0.171 美元,F1 只从 0.929 轻微降到 0.924。模型路由更像是把钱花在刀刃上,简单字段让便宜模型做,复杂字段再用强模型。叠加自适应重试,最后得到的优化分层式配置,F1 做到 0.924,单文档成本只有 0.148 美元。它已经逼近高准确率方案的效果区间,价格却回到了接近基线的位置。
五、规模让排序重来
研究继续往后测了吞吐量。低负载时,反思式的确最强。到了每天 25000 份文档以后,它开始明显掉速。50000 份时已经落到分层式后面,100000 份时反而成了表现最差的架构。究其原因纠错循环在高负载下会形成排队,一旦系统设了超时,反思式最依赖的那部分迭代就会被截断。
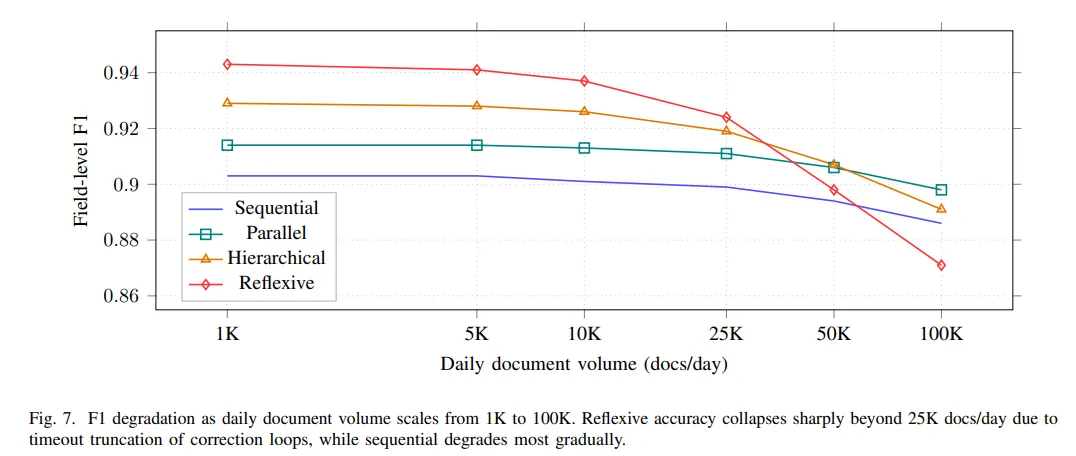
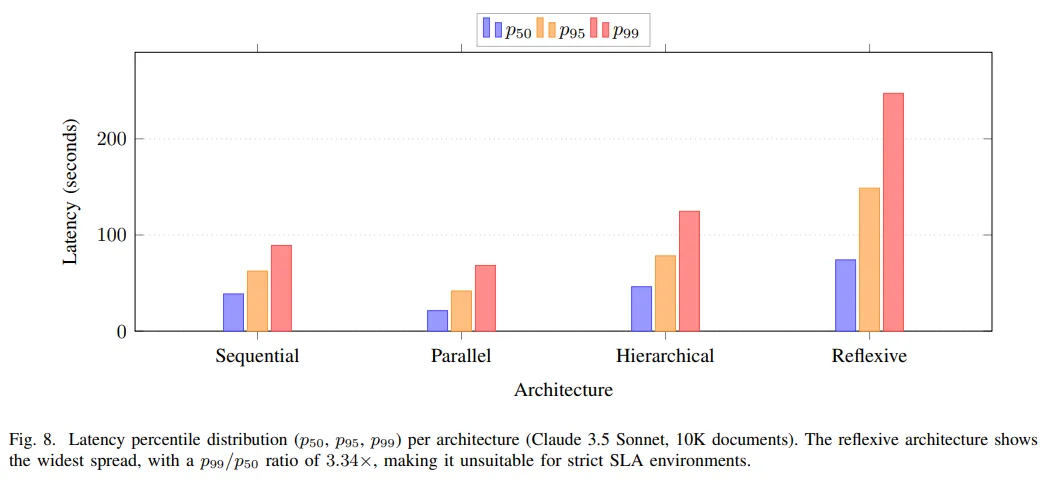
顺序式的表现从每天 1000 份到 100000 份,它的 F1 下降最小。并行式在速度上仍然最好。分层式处在一个相对均衡的位置。反思式除了扩展性问题,延迟分布也最难控制,p99 和 p50 的比值达到 3.34,说明一旦碰到复杂文档,处理时间就很容易被拉长。失败模式分析也能对上这个现象。顺序式最容易在跨表引用上出错,反思式则更容易在表述含糊的披露里反复修正,处理链条越长,这种波动就越明显。
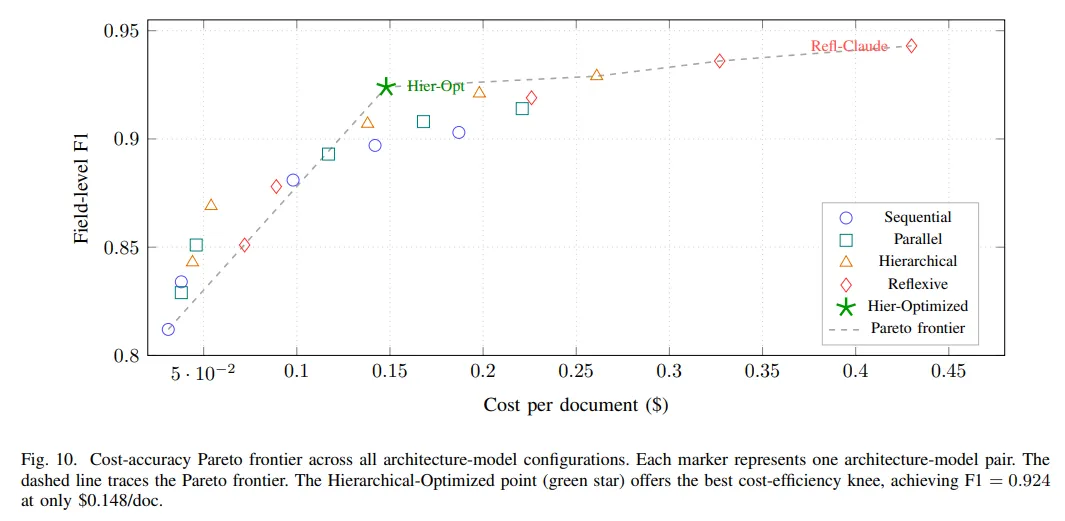
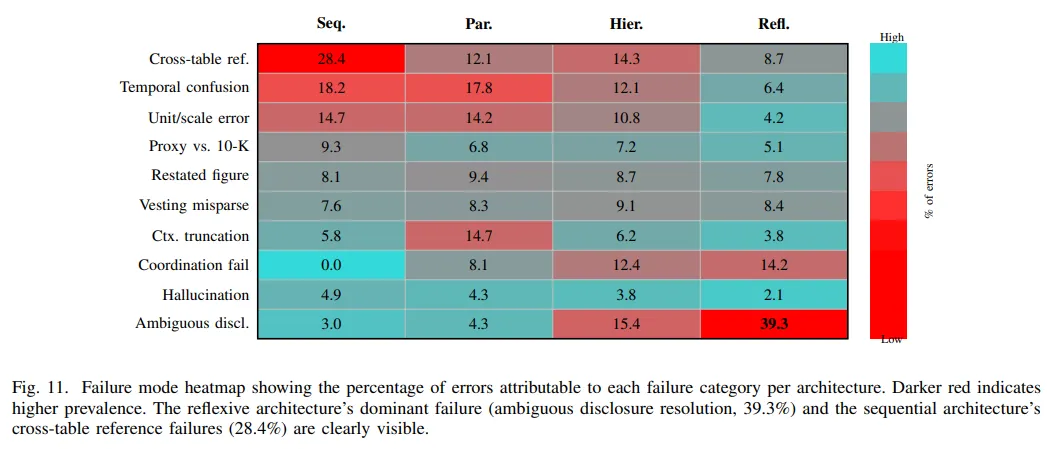
六、最后的判断
从研究的判断来看,生产级金融文档处理中,分层式架构提供了最稳妥的成本与准确率平衡。反思式适合低吞吐、强准确率约束的任务。并行式更适合时延敏感场景。顺序式在高规模和紧预算下更有现实位置。很多时候决定系统能不能落地的,往往不只是模型本身,还包括任务如何分配、错误如何回收、计算资源又是怎么被花出去的。