 夜雨聆风
夜雨聆风





文档解析方案最新进展:MinerU2.5-Pro更新、数据工程及FlowExtract流程图解析思路
今天是2026年4月10日,星期五,北京,天气晴
来看文档解析相关前沿进展,这块依旧比较卷,两个点。
一个是传统CV方式做流程图解析思路FlowExtract,一个是MinerU2.5-Pro更新及其中的数据工程思路,重点的重点,还是要看数据怎么做的。
会有一些思路,虽然很常规。
一、传统CV方式做流程图解析思路FlowExtract
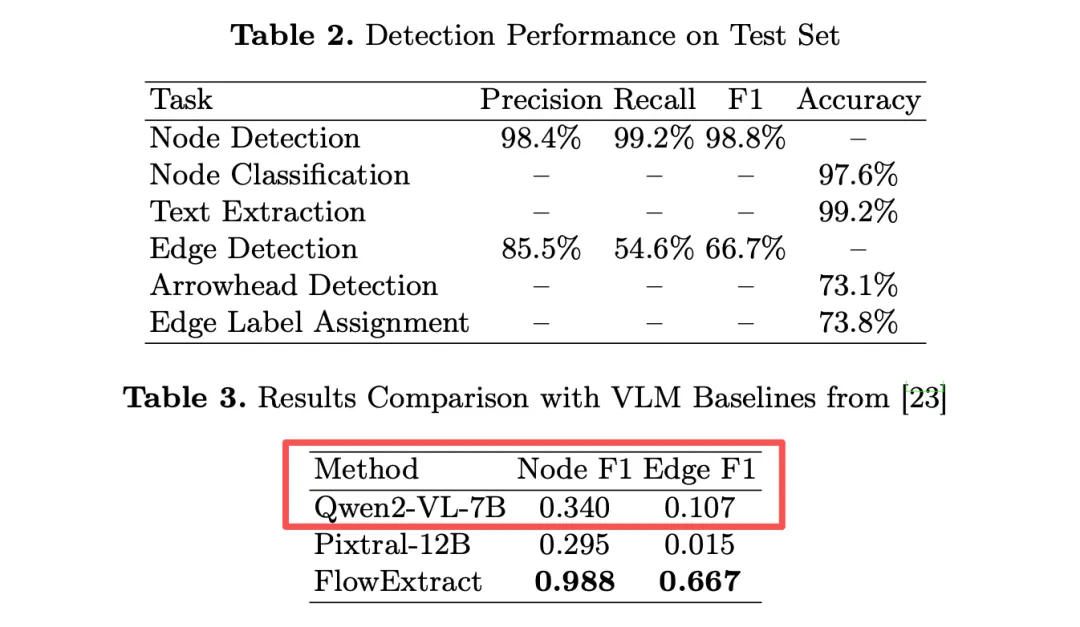
来看流程图解析的一个方案,面向ISO 5807 标准工业维护流程图的流程知识结构化提取开源纯cv pipeline【视觉语言模型在节点与文本检测尚可,但连接拓扑重建能力很弱,F1值低于0.30】,主要针对的场景是PDF/扫描版维修流程图设计【注意:主要解决的是维修/故障流程图,通用流程图适配有限,指标也不高,纯cv方式】,《FlowExtract: Procedural Knowledge Extraction from Maintenance Flowcharts》,https://github.com/guille-gil/FlowExtract,https://arxiv.org/pdf/2604.06770,核心思路是节点检测->文本提取->边提取三阶段。
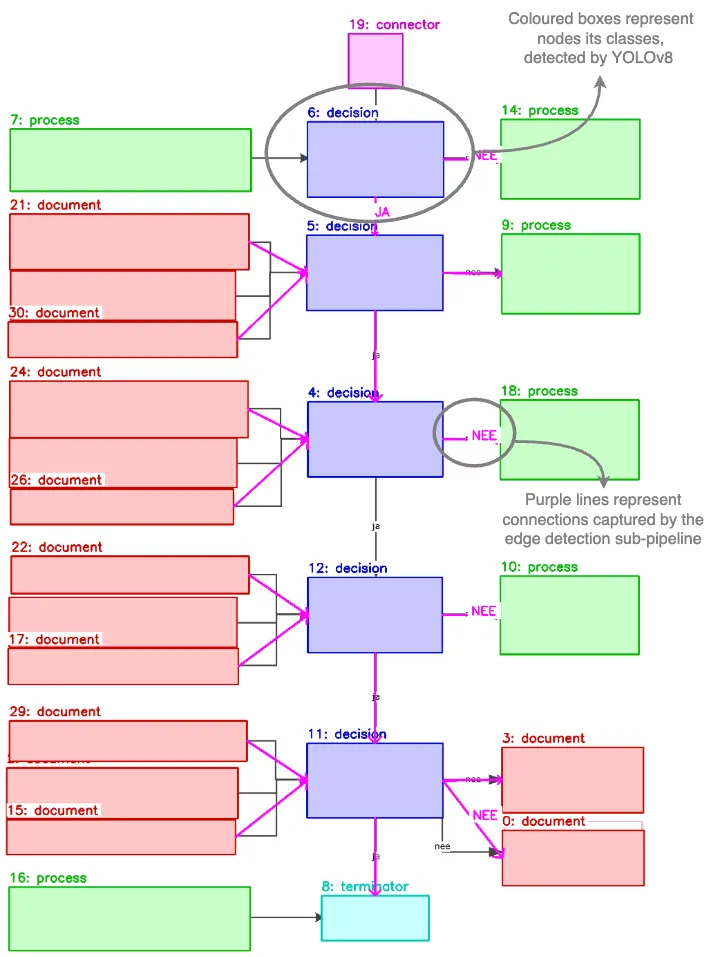
重点看实现逻辑:
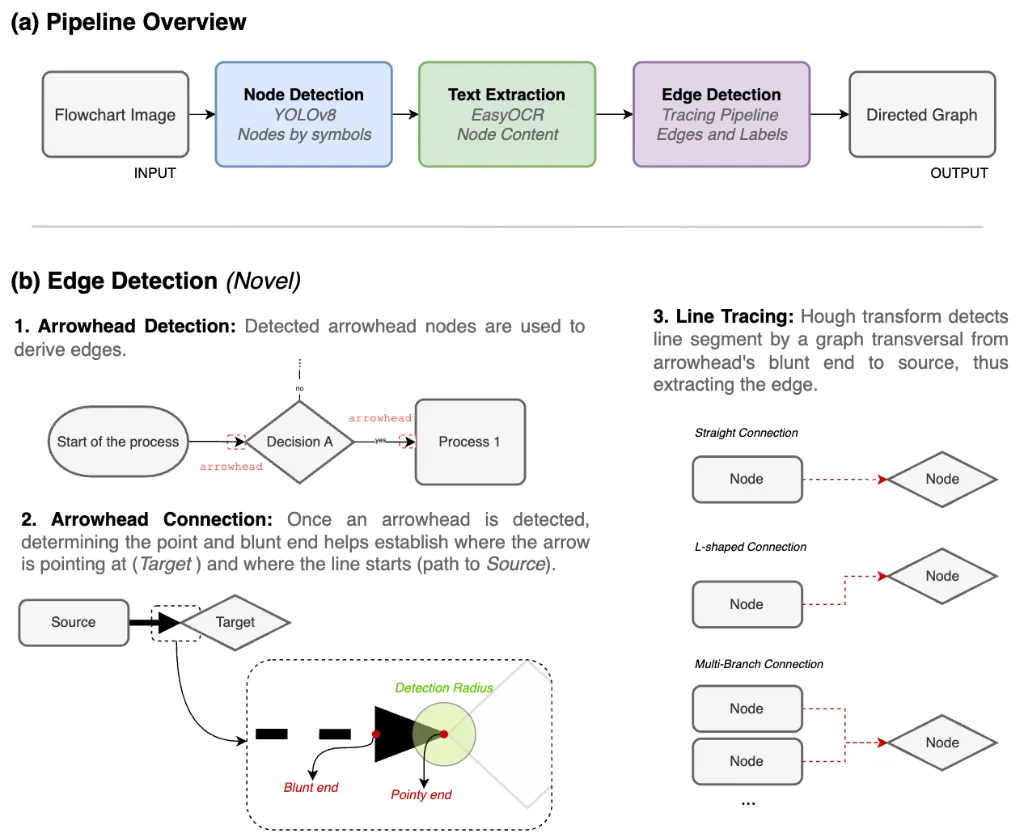
step1.节点检测,使用YOLOv8s定位并分类流程图符号(Process、Decision、Document、Terminator、Connector、Arrowhead(共 6 类),增强策略使用马赛克增强 + HSV 亮度变换,解决类别不平衡)【指标节点F1,98.8%】;
step2.文本提取,使用EasyOCR提取节点内文本;
step3.边(连线)提取,使用霍夫变换+箭头追踪(以箭头为锚点,判断箭头指向(尖端=目标,钝端=源方向),用概率霍夫变换回溯连线至源节点,支持直线、L型、多分支结构),重建有向边与分支逻辑【最终指标F166.7%,精度85.5%】。
二、MinerU2.5-Pro更新及其中的数据工程
继续看文档解析领域多模态方向,MinerU2.5-Pro更新,主要特点是保留MinerU2.5的1.2B参数架构,主要改动点是训练数据从不足1000万页扩至6550万,可以再回顾下这块的内卷形势:
功能侧,对齐ppocr-vl,加了流程图解析,表格带图片、表格合并、段落合并功能。

工作报告在:《MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale》,https://arxiv.org/pdf/2604.04771,代码在: https://github.com/opendatalab/MinerU,模型权重在: https://huggingface.co/opendatalab/MinerU2.5-Pro-2604-1.2B。
核心可以借鉴的点,还是其中的数据工程和训练方式。
1)看数据部分步骤
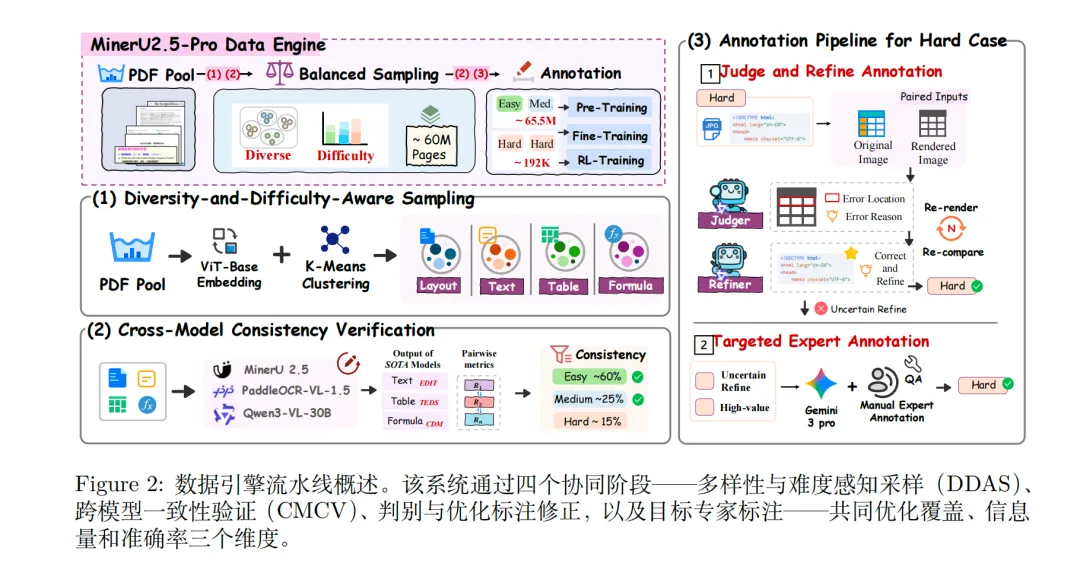
Step1.多样性与难度感知采样(DDAS),先对全部PDF页面做ViT-Base嵌入+K-Means聚类,再做页面级与元素级双粒度采样;简单簇下采样、困难/小簇上采样,纠正长尾分布偏移,最终把训练数据从不足1000万页扩充到6550万页,覆盖复杂嵌套表格、稠密公式、非常规版式等高难度场景;
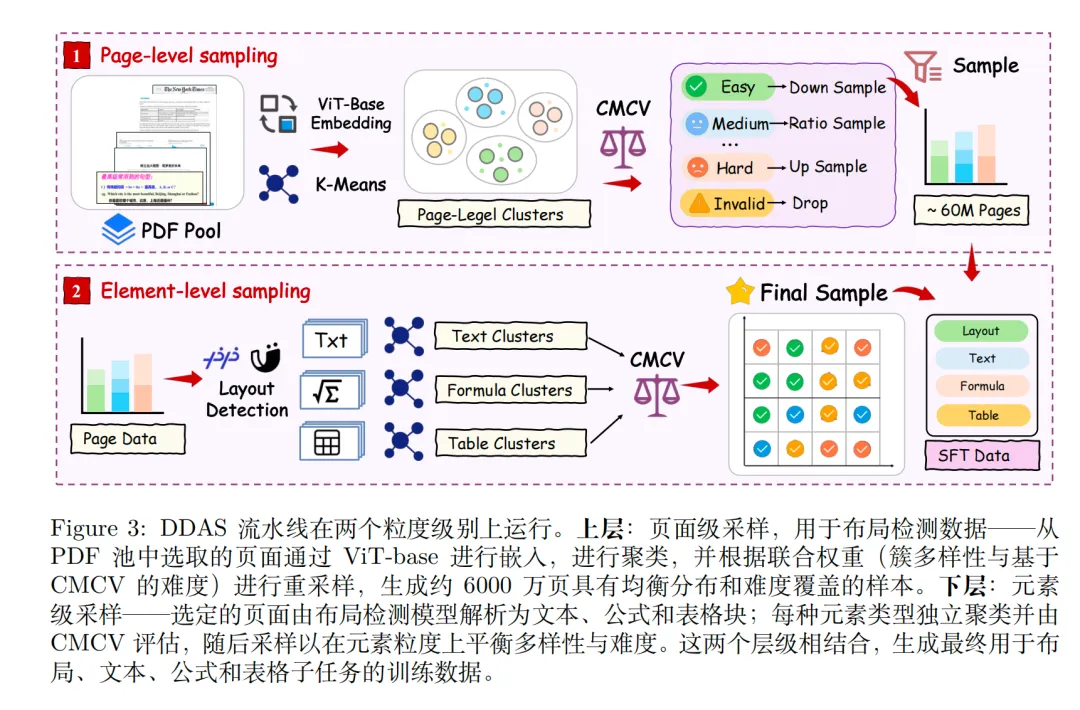
->Step2.跨模型一致性验证(CMCV),用MinerU2.5、PaddleOCR-VL、Qwen3-VL-30B多个异构模型交叉验证,按文本编辑距离、表格TEDS、公式CDM计算一致性,自动划分三级难度:简单60%、中等25%、困难15%;简单/中等样本直接用多模型共识做可靠自动标注,不用人工;
->Step3.判别-标注流水线,针对困难样本,采用“渲染→视觉对比→迭代修正”机制:把模型输出的LaTeX公式/HTML表格重新渲染成图像,和原图对比让模型直观识别错误,多轮迭代修正标注,提升难样本标注准确率;
->Step4.目标专家标注,对自动修正仍无法解决的极难样本,优先分配标注资源;用Gemini3Pro预标注+专业人员精修,最终产出19.2万条人工标注数据,只聚焦模型最薄弱、提升最大的场景;
2)看训练方式,典型的三段式。
Step1.大规模预训练(Stage1),使用数据引擎产出的6550万页简单+中等难度自动标注样本,覆盖文本、公式、表格、版面、图像分析全任务;全参数可训练,构建全面、均衡的文档解析基础能力;
->Step2.高质量难样本微调(Stage2),使用390万混合样本,其中包含19.2万条专家标注难样本,搭配不同比例的回放数据防止遗忘,重点强化复杂表格、稠密公式等困难场景;
->Step3.GRPO强化学习对齐(Stage3),使用19.2万标注样本,以文本编辑距离、公式CDM、表格TEDS、布局IoU为直接奖励。
参考文献
1、https://arxiv.org/pdf/2604.06770
2、https://arxiv.org/pdf/2604.04771
关于我们
老刘,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解等技术方向感兴趣,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。