 夜雨聆风
夜雨聆风





顶级AI源码泄露后,2026年我们该押什么?

2026年3月31日,由于一次低级的打包失误,AI巨头Anthropic的明星产品Claude Code的源代码在公开的npm仓库中意外暴露。
Claude Code被业内视为最接近生产环境的AI编程智能体(Agent)之一。泄露内容指向近2000个内部文件和约50万行代码,这像一张X光片,把顶级Agent是如何思考、如何记忆、如何行动的工程结构,清清楚楚摊在了全世界面前。
针对这场技术圈地震,我们与三位AI领域的中欧EMBA校友王靖华、李世平、郭润平进行了长谈。他们的观点不约而同:系统性布局AI协作能力的窗口期已经到来,但多数企业的治理、流程和判断力还没到位。
1
不是工具,是组织

王靖华
中欧EMBA2022
美敦力中国基金管理合伙人
美敦力中国基金管理合伙人王靖华(中欧EMBA2022)最先看到的,是源码里藏着的一套组织结构。
他提到一个关键词,协调员模式(Coordinator Mode)。
源码里,一个“大Agent”充当“首席架构师”,负责拆解任务、分派工作、审计结果,再由多个“搬砖Agent”去具体执行。这像极了商学院里讲的组织行为学,有人定方向,有人干执行,有人做复核。
王靖华的判断很直接:单体Agent时代已经结束,“Agent矩阵”时代已经到来。
未来企业的竞争力,不在于你雇了多少会写Prompt的员工,而在于你构建了一套多高效的AI协同协议。最终,人类也将是Agent系统中的一环,并且极有可能是系统最先碰到的瓶颈。
这段话,把Agent从“工具位”推到了“组织位”。
2
壁垒在“做梦”里
过去大家以为,AI壁垒是算力,是参数量。现在被泄露源码照出来的,却是另外一层:记忆管理、任务拆解、超长路径规划、容错机制、上下文的高效调度。这些不如“千亿参数”性感,却决定了一个Agent到底是在演示中惊艳五分钟,还是能在生产环境里稳定干活。
王靖华特别看重两处设计。
第一处,是“做梦”机制(Dreaming)。不是简单把上下文窗口做大,而是在系统闲暇时,能自动梳理历史交互,剔除矛盾点,把零散观察蒸馏、合并成确定的事实,再写入项目根目录文档中。这个设计模仿的是人类睡眠时处理记忆的机制。
在王靖华看来,这标志着Agent正在从“瞬时智能”走向“累积智慧”。他说,谁能把记忆管理做成非线性、自生长的,谁就掌握了Agent的灵魂。
第二处,是Kairos能力(古希腊语,意为关键时刻)。这个模块尚未启用,却揭示了一个潜在的范式转移:未来,Agent不再是等你发问才动作的“召唤式工具”,而是成为永不离线、主动预判并适时补位的“常驻数字员工”。你下班了,它还在看日志、跑检查、补缺口、找风险。
王靖华把今天的行业变化概括为:AI正在跨越从副驾驶(Copilot)到自动驾驶(Autopilot)的临界点,从“在旁边递扳手”走向“接管方向盘”。
所以,投资逻辑也跟着变了。他给出的判断标准,从“看技术参数”转向“看落地闭环”:是否切入到业务流中,解决了真实痛点;是否具备长程记忆,成本可控;是否不容易被底层模型的迭代直接抹平……以及最关键的一点——把不确定的模型概率,驯化出确定的商业产出。
3
被低估的“工程鸿沟”

李世平
中欧EMBA2022
杭州大简智能创始人
前腾讯云AI技术专家
杭州大简智能创始人、前腾讯云AI技术专家李世平(中欧EMBA2022)的表达,很适合把这次事件,解释给非技术背景的管理者听。
他打了一个好懂的比方:大模型底座像研发部门,Agent更像生产制造部门。问题就在这里。我们往往高估研发,低估制造;同样,今天也很容易高估模型,低估Agent的工程实践能力。
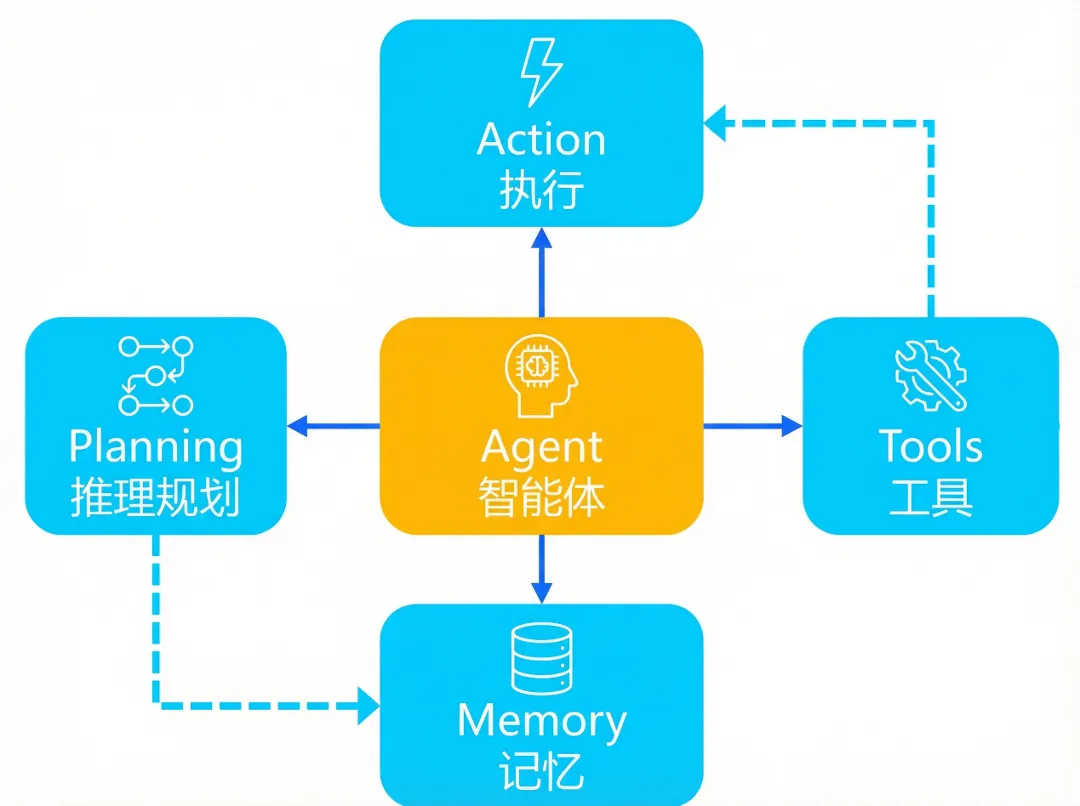
Agent的典型架构如上图所示,一句话就能定义:能自主感知、思考、行动并完成目标的智能实体(李世平)
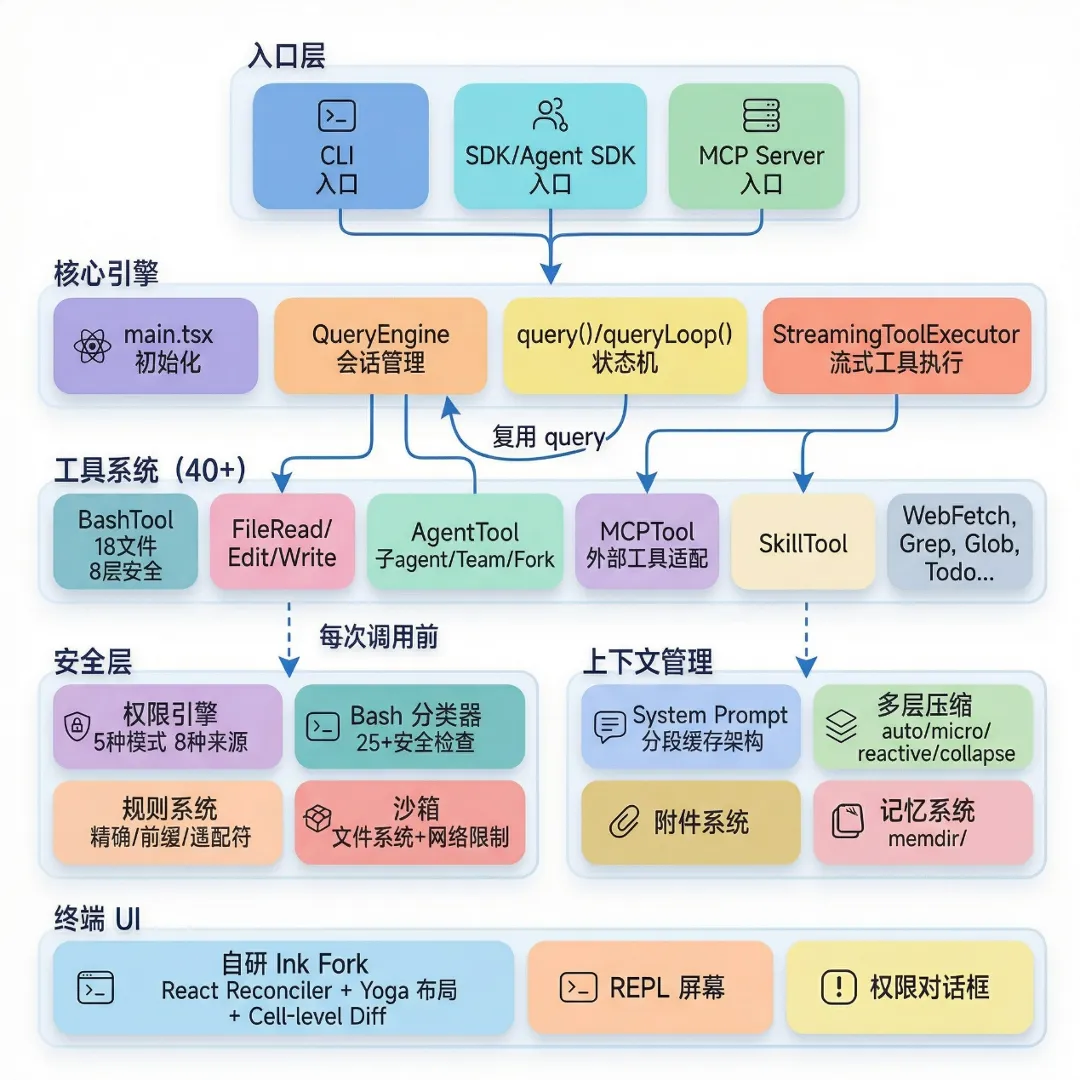
根据Claud Code泄露代码画出的架构图如上图所示,功能模块没有超出Agent的典型架构,但每个模块设计得极其复杂(李世平)
在李世平看来,Claude Code是“长上下文+复杂推理”的王者,在多文件、跨模块的工程任务上表现卓越。它的强,强在把那些用户看不见、却最磨人的工程环节,做深了。
考验功力的部分,是上下文管理。
大模型本身没有真正的长期记忆,只有有限的上下文窗口。李世平说,用户下达一次指令,Agent在后台平均要调用10次大模型。换句话说,Agent表面上像在聊一句话,背后却在持续组织一部上限为200万token的“长篇或超长篇小说”。能把这部“长篇小说”写得不乱、不漏、不崩,才是真壁垒。

郭润平
中欧EMBA2022
微软中国Azure解决方案部总经理
微软中国Azure解决方案部总经理郭润平(中欧EMBA2022)的基本判断是,类似Claude Code的AI编程产品,本质上不是简单的模型封装或工具集,而是一个复杂的Agent系统,至少包含推理层、执行层和编排层。其中的壁垒在于,能否把推理、执行、安全、反馈做成可靠闭环。
他举例,很多团队明明有不错的模型,却做不出同等体验,问题就出在低估了从“模型demo”到“生产系统”之间的工程鸿沟。
4
机会在“脏活累活”
把视线从Anthropic拉回中国团队,三位中欧EMBA校友都指向了同一个方向:机会不在“做一个看起来像Claude Code的东西”,而在做脏活累活,进深水区。
王靖华讲得最坚决:源码泄露之后,复刻一个“形似”的同质化工具会迅速变得廉价。中国团队的机会,在那些难而深的场景里——残酷的竞争环境、独特的合规要求、复杂的内网数据。这些地方,恰恰是通用工具难以深入的。
他由此会看好医疗研发、法律合规、复杂系统运维这类垂直领域深度专家型 Agent。而容易被高估的,是只接API、做漂亮UI、没有任何底层工程支架的提示词工程型公司。
李世平的判断是:大厂资金充裕、人才储备雄厚,往往会同时发力大模型底座和Agent;创业公司则更适合围绕具体应用场景,做垂直领域的Agent。不同的组织,打法本来就不一样。
郭润平建议大多数厂商优先在企业场景做“可控Agent”,同时保持对通用底座的技术跟踪和局部投入。原因很实际,企业客户最大的顾虑,不是“AI不够聪明”,而是“AI会不会失控”。
数据泄漏、合规违规、输出不可预测、责任无法追溯,才是拦住企业买单的门槛。谁能把AI行为做到可解释、可审计、可干预,谁就更接近商业价值。
5
先押工作流
把问题继续往前推一步,企业管理者的关切和焦虑在于,有限的资源,该怎么投?
郭润平的答案很明确:押工作流,其次是应用,模型更适合采取“合作而非自建”的策略。
这个判断之所以重要,是它一下子把企业AI投入的轻重缓急讲清楚了。
模型是技术密集、资本密集、赢家通吃的领域,绝大多数企业根本不该把有限资源砸进“重复造轮子”。应用当然重要,但AI应用更多是解决具体的业务痛点。
有最高战略价值的,是工作流——把多个AI模型、传统软件系统、人工环节串联起来,形成端到端的业务流程自动化。
一旦建立起成熟的工作流平台,企业可以快速将新的AI能力(新模型、新应用)集成进来,而无需每次从零搭建。同时,工作流沉淀了企业的业务逻辑与知识资产,形成了外部厂商难以模仿的护城河。
6
喂了数据,AI就懂业务了?
在企业落地这一层,李世平和郭润平给了两个看似不同、其实互补的提醒。
李世平强调的,是燃料。
他认为,未来衡量企业的竞争力,不仅看人类人才密度,也要看数字人才密度。企业给人类员工发薪酬福利,给数字员工发token。token将是AI时代企业的“生产燃料”。
郭润平关注的,则是地基。
他认为,2026年企业容易忽略、却关键的基础设施,是企业知识沉淀(知识图谱)和语义层。很多管理者误以为“把数据喂给AI,它自然就懂业务了”,其实不然。
企业的数据,往往散落在不同系统内、不同部门中、不同老员工的脑子里,还有“只可意会不可言传”的隐性知识。
没有知识图谱、没有统一语义层,Agent很容易成为一个“聪明的外行”——它会查资料、会做浅层的“文本匹配”和“模式识别”,但它不懂你这家公司的业务逻辑。
郭润平举例,智能采购Agent可能会仅凭“价格最低”就盲目下单,却不知道这家供应商上个月因为质量问题,被列入观察名单;也可能因为“库存为0”就紧急采购,却不知道有一批货正在运输途中,只是ERP更新滞后。
没有燃料,Agent干不了活;没有地基,Agent干的活不靠谱。
这两件事,恰恰都是今天很多企业容易忽略的。
7
3年窗口期
王靖华谈的是产业逻辑,李世平谈的是工程现实,郭润平谈的是落地条件。三条线索最后汇成一句话:决定胜负的,不只是“有没有最强模型”,更是能不能把模型嵌进组织、流程、知识和业务闭环里,变成稳定的组织能力。
模型可以买,能力要自己长。
郭润平有一句话,很适合做文章收尾:
现在是开始系统性布局AI协作能力的窗口期。过早投入(3年前),可能面临技术不成熟的风险;过晚进入(3年后),可能错失先发优势,且面临更高的组织变革阻力。
窗口期从来不是敲锣打鼓来的。
它往往都很安静。
安静到很多人以为,一切还来得及。
直到它关上。█


点击卡片,关注中欧EMBA
点击此处“阅读全文”查看更多内容