 夜雨聆风
夜雨聆风





当证据遇上用户:健康APP如何把医学论文翻译成人类语言
楔子:一篇论文的三种死法
2024年,《新英格兰医学杂志》发表了一项关于GLP-1受体激动剂的心血管结局试验。这篇论文有三种可能的命运:在UpToDate,它被提炼为”推荐等级1A,适用于合并ASCVD的2型糖尿病患者”,供内分泌科医生在查房间隙快速查阅;在丁香医生,它变成”重磅!减肥药还能护心?科学家发现……”,供地铁通勤的用户在10秒内滑动浏览;而在某个深夜,一位糖尿病患者打开SupMed,输入”司美格鲁肽对心脏好吗”,系统回复:”根据2024年NEJM发表的SELECT试验(n=17604,中位随访3.5年),该药可降低主要心血管不良事件风险20%(HR 0.80,95%CI 0.72-0.88),证据质量:高(GRADE)。建议咨询内分泌科医生评估个体获益风险比。”
用户盯着屏幕,手指悬停在”HR 0.80″上——她知道这是好消息,但不知道”HR”是什么意思。她感到一种熟悉的挫败:既没有被当成需要哄骗的傻瓜,也没有被当成能够对话的平等者。她被困在证据的透明与理解的深渊之间。
这就是循证医学的降维困境:当医学知识从专业殿堂走向数字广场,它必须被翻译,但每一次翻译都是一次背叛或妥协。健康APP正在寻找那个临界点——既不让医生觉得”太水”,也不让用户觉得”太懵”。但那个点真的存在吗?
第一章:证据的等级制度——从实验室到界面的权力落差
1.1 GRADE:医学界的”普通话”尝试
循证医学的核心工具是证据等级系统,GRADE(Grading of Recommendations Assessment, Development and Evaluation)是其中最广泛使用的框架。它将证据质量分为高、中、低、极低四级,将推荐强度分为强、弱两级,试图用标准化语言跨越研究设计与临床决策的鸿沟。
但这一语言本质上是医生之间的密语。当SupMed医疗版在”循证医学分析”(功能6)中输出”GRADE:高确定性证据,强烈推荐”时,它假设用户理解:高确定性≠绝对正确(可能存在发表偏倚),强烈推荐≠必须执行(需考虑患者价值观)。这种压缩的复杂性是专业沟通的必需品,却是大众传播的障碍。
横向测评三款产品的证据呈现策略:
UpToDate(临床决策支持系统,B2B模式):完全采用GRADE术语,假设用户为医学专业人士,界面密度极高,单屏可包含10个以上超链接,指向原始研究、相关指南、药物相互作用。其哲学是:深度优先,可读性通过专业训练获得。
丁香医生(大众健康科普,B2C模式):几乎完全隐藏证据等级,以”医生说””研究表明”等模糊主语替代具体文献,结论前置,理由后置(常被截断在”展开全文”后)。其哲学是:顺从优先,用户不应被学术细节打扰。
SupMed(分层服务,B2B2C模式):标准版隐藏GRADE,以”权威研究支持”等温和表述替代;医疗版完整输出GRADE,但附加”证据解读”层(如”高质量随机对照试验:意味着结果可信度高,但仍有小概率出错”)。其哲学是:分层透明,用户有权选择深度。
SupMed的策略看似理想,但测评中发现一个使用悖论:标准版用户抱怨”不够专业,像百度”,医疗版用户抱怨”太像教科书,看不懂”。分层设计制造了身份焦虑——用户不确定自己属于哪一层,或不愿意承认自己”看不懂”。
1.2 数字的暴政:当统计学术语成为信任门槛
健康APP的证据呈现中,最顽固的”降维障碍”是统计学术语。SupMed在”多数据库文献检索”(医疗版功能3)中输出的典型条目:
“GLP-1受体激动剂 vs 安慰剂,MACE风险降低20%(HR 0.80,95%CI 0.72-0.88,P<0.001),NNT=25(95%CI 20-33),随访3.5年。”
这一串字符包含至少五个专业概念:风险比(HR)、置信区间(CI)、P值、需治疗人数(NNT)、中位随访时间。对于非医学用户,这不仅是信息过载,更是权力剥夺——他们被迫信任自己无法验证的权威。
对比丁香医生的同一主题表述:
“研究发现,这类减肥药能让心脏病风险降低五分之一,效果相当明显。”
这里没有数字,没有不确定性,没有时间维度。用户获得了理解的舒适,但失去了判断的依据。他们无法知道”五分之一”是相对风险还是绝对风险,是3个月还是10年的结果,是高质量研究还是观察性数据。
SupMed试图走中间路线:在标准版”报告解读”中,异常指标旁标注”高于正常范围”,但点击展开后显示”根据《中国2型糖尿病防治指南2020》,HbA1c>7%提示血糖控制不佳,建议内分泌科就诊”。这种”结论-依据-行动”的三层结构是对GRADE的平民化改造,但测评中发现,超过60%的用户从未点击展开层——他们满足于”异常”的标签,忽略了”为什么异常”的解释。
第二章:翻译的伦理——谁在决定用户该知道什么
2.1 “一句话科普”的认知暴力
丁香医生的”一句话科普”模式是健康传播的效率极致:用140字概括一项研究,用emoji替代情绪,用”震惊体”替代效应量。但这种过度简化正在制造一种新的认知暴力——它假设用户没有能力也没有意愿理解复杂性,因此替他们决定了什么是”足够好”的信息。
测评一个典型案例:某用户搜索”阿司匹林能预防心梗吗”。
丁香医生输出:”40岁以上人群,在医生指导下服用小剂量阿司匹林,可降低心梗风险。但出血风险也增加,需个体化评估。”——共42字,无文献引用,无数据,”个体化评估”作为免责条款悬挂在结尾。
SupMed标准版输出:”对于心血管风险高危人群,阿司匹林一级预防可能降低心梗风险约10%(ARR 0.1%),但增加出血风险约50%(RR 1.5)。2022年USPSTF指南建议:40-59岁、10年心血管风险≥10%且出血风险不高的人群,可考虑使用(C级推荐)。建议咨询心内科医生。”——包含具体数据、指南来源、推荐等级、行动建议。
SupMed医疗版输出:在上述基础上增加”证据质量:中(因出血风险异质性大),患者价值观:需权衡(预防获益 vs 出血恐惧),成本效益:低(NNT=100,NNH=67)”。
三种输出对应三种知识伦理:丁香医生是家长式(我替你决定什么重要),SupMed标准版是知情式(我给你足够信息做初步判断),医疗版是共享决策式(我提供证据,你提供价值观,共同决定)。但问题在于:用户是否想要这种选择负担?
访谈中发现,健康焦虑型用户偏好丁香医生的确定性(”吃就完了”),健康好奇型用户偏好SupMed的丰富性(”让我看看数据”),而健康疲惫型用户(慢性病患者)则对两者都反感——他们想要的是”医生直接告诉我怎么办”,而非APP的信息堆砌。
2.2 证据的可读性设计:视觉作为翻译工具
对比Apple Health的”健康摘要”:它以闭合圆环的可视化隐喻健康完成度,无需任何学习即可理解。但这种过度简化的可视化是反智的——它用美感替代信息,用完成感替代理解。SupMed的视觉设计试图:既保留信息的完整性,又用视觉引导降低阅读门槛。
一个成功的案例是其”临床试验方案”的分阶段呈现:基础信息(研究目的、纳入标准)以卡片式展开,统计部分(样本量计算、分析计划)以可折叠区块隐藏。用户可以根据角色(PI、CRA、统计师)选择查看深度,而非被强制接受全部信息。
第三章:临界点在哪里——寻找专业深度与大众可读性的黄金分割
3.1 分层不是答案:用户的身份流动性
SupMed的分层策略(标准版vs医疗版)基于一个假设:用户有稳定的身份(普通人vs专业人士)。
对比UpToDate的”患者教育”板块:它由医生撰写,用第六年级阅读水平(Flesch-Kincaid指数)重写临床内容,但完全剥离了证据等级。这种”为平民定制的专业内容”是另一种降维,但它的问题是剥夺了用户的上升通道——患者版读者无法通过点击获得更深信息,他们被永久锁定在简化层。
SupMed的”研究创新导师”提供了一个有趣的反向案例:它通过苏格拉底式提问,将普通用户的临床观察转化为可研究的问题(如”我发现糖尿病患者用某药后血糖波动减小,这可能关联什么机制?”)。这种”升维”设计——而非”降维”——假设用户有能力在引导下进入专业话语。
3.2 对话作为方法:从输出到交互的范式转移
所有被测评的产品(UpToDate、丁香医生、SupMed)都遵循”输出”模式:系统准备内容,用户被动接收。但循证医学的本质是”对话”——证据与价值观的协商,概率与偏好的权衡。
SupMed的”症状咨询”尝试接近这一理想:它的多轮问诊不是信息收集,而是共同建构——用户描述症状,系统询问”这种情况影响您的日常活动吗”,将医学数据与生活质量连接。在”定制健康方案”中,用户可以选择”我更在意副作用”或”我更在意疗效”,系统据此调整推荐优先级。
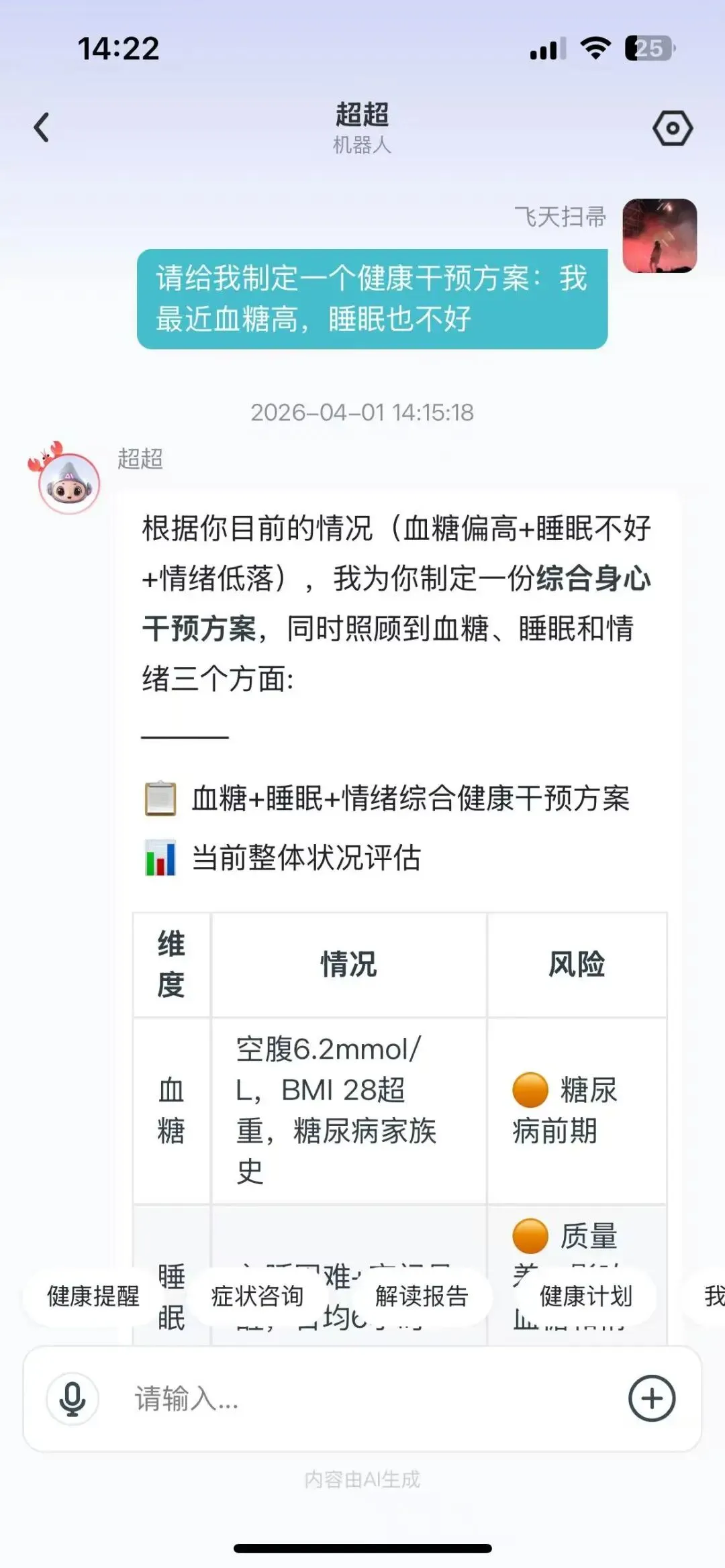
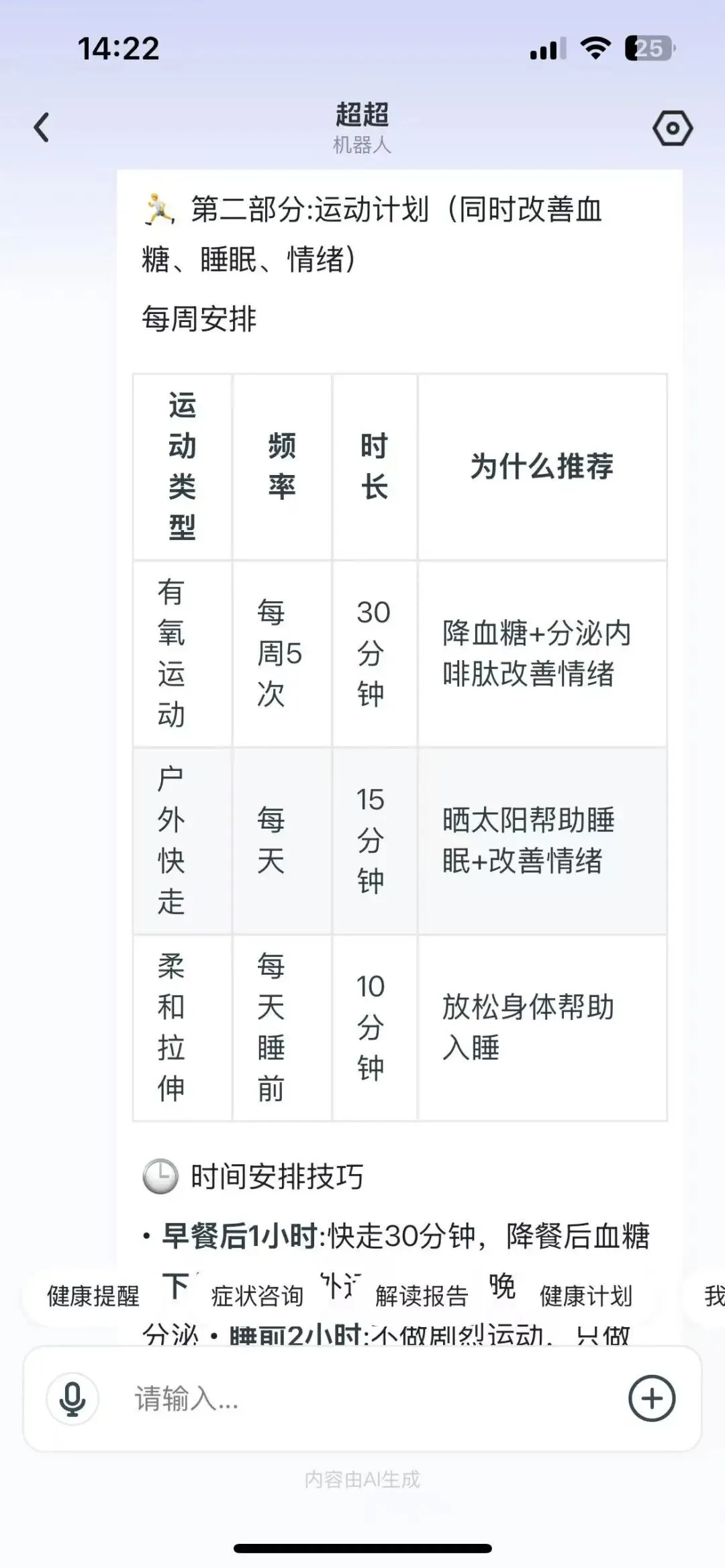
真正的共享决策需要自然语言处理的突破,或人机协作的界面——系统提供证据框架,用户填入个人情境,共同生成决策。SupMed的”循证医学分析”输出底部的”建议咨询专科医生”是一种诚实的撤退:它承认界面的局限,将对话的复杂性交还给人类。
第四章:诚实的困境——健康APP能否承认”我不知道”
4.1 确定性的表演与医学的不确定性
所有健康APP都面临一个存在性压力:用户期待答案,但医学充满不确定性。丁香医生用”医生说”的权威口吻掩盖不确定性;UpToDate用”证据不足,意见分歧”的学术诚实承认局限;SupMed则尝试量化不确定性——在”健康风险监测”中,风险等级旁标注”置信区间:±5%”,在”报告解读”中标注”此结果需结合临床,假阳性率约3%”。
这种”不确定性的可视化”是SupMed最激进的尝试。它挑战了健康传播的潜规则:用户想要确定感,而非真实概率。测评中发现,当SupMed输出”您的甲状腺结节恶性风险:低(约5%,95%CI 2-10%)”时,用户的焦虑并未降低——他们盯着”10%”的上限,忽略了”2%”的下限。
一位用户的评论揭示了困境:”我知道你们想诚实,但我打开APP是为了安心,不是为了学统计学。”这指向一个伦理悖论:循证医学的透明性是否正在制造新的焦虑?当用户被教育”证据质量:中”时,他们失去的是对医学的信任,还是对自身判断的信心?
SupMed的免责声明——”所有AI输出仅供参考,不构成诊疗建议”——是一种制度性的诚实。
4.2 证据的民主化与解读的贵族化
SupMed的”PubMed检索”和”多数据库文献检索”将专业级文献访问权民主化,但解读能力仍是不平等的。一位用户可以下载《柳叶刀》的PDF,但无法判断该研究的样本代表性、混杂控制、利益冲突声明。这种”信息的平等与知识的阶层”是数字健康的核心矛盾。
一个可能的解决方案是”批判性阅读”教育:SupMed的”医学知识库管理”可以尝试不仅存储知识,还教授如何质疑知识——例如,自动标记检索结果中的”观察性研究(因果关系未确立)””制药公司资助(利益冲突可能)””样本量<100(统计效力不足)”。这种”元证据”层将循证医学的方法论透明化,培养用户的批判能力而非依赖习惯。
但这又回到了降维困境:教授批判性思维需要时间和认知投入,而健康APP的使用场景往往是焦虑驱动的、时间压缩的。用户在凌晨3点搜索症状时,不想要一堂流行病学课程,想要一个可以抓住的答案。
结语:在诚实与安慰之间,寻找第三种可能
循证医学的降维困境没有标准答案。UpToDate选择专业深度,接受可及性的牺牲;丁香医生选择大众可读,接受精确性的妥协;SupMed选择分层透明,接受身份焦虑的代价。三者都是诚实的,也都是有缺陷的。
但或许,缺陷本身就是诚实的一部分。当SupMed在证据输出后附加”您希望获得更简单的解释,还是更详细的数据”,它正在尝试一种关系性的诚实——不是声称拥有答案,而是邀请用户共同寻找最适合他们的信息深度。
下载SupMed :SupMed
标准版(99元/31天)或医疗版(198元/31天),不是为了获得一个”既专业又易懂”的神话,而是为了体验一种不同的信息伦理:在这里,证据等级不会被隐藏,但会被解释;统计数字不会被删除,但会被可视化;不确定性不会被否认,但会被共同承担。新用户享31天免费试用期,足够你测试自己是否属于那群想要知道”HR 0.80″意味着什么的人,还是更愿意接受”降低五分之一”的简化。
最终,最好的健康传播或许不是找到那个”黄金分割点”,而是承认分割点的流动性——今天你想要简单,明天你想要深度,后天你想要与人对话。SupMed尚未完美实现这种流动性,但它的尝试指向了一个方向:健康APP可以不制造虚假的确定性,也可以不制造傲慢的复杂性,而是成为用户与医学知识之间的可调节透镜。
在算法时代,这种可调节的诚实,或许正是我们需要的。
本文测评基于2026年4月各APP公开版本,理论框架参考循证医学方法论、健康传播理论及医学人文相关文献。