 夜雨聆风
夜雨聆风





从零开始给OpenClaw装上感官记忆和双手:第12课 学会回忆往事

第12课:想找回半年前的对话?——全文记忆检索配置
进度:12/12,OpenClaw 搭建系列完结篇!你的AI即将拥有「回忆往事」的能力
你有没有遇到过这种情况:
-
三个月前跟AI讨论过一个API设计方案,现在想找回当时的结论,却翻不到记录 -
上周让AI帮你写过一个脚本,今天想用却忘了文件名 -
明明跟AI说过”记住这个项目用Python”,它却问你”用什么语言开发”
MEMORY.md 能存重要信息,但人的记忆是模糊的——你只记得”好像讨论过某个东西”,却想不起具体细节和日期。
这节课给 OpenClaw 装上「全文记忆检索」系统。配置好以后,AI能从海量历史对话中找到你需要的任何信息,哪怕你只记得只言片语。
学完这节课,你的AI能做到:
-
语义搜索:用自然语言描述,找到相关历史对话 -
自动归档:每次会话结束自动保存完整记录 -
精准定位:从半年前的某次对话中提取具体信息 -
关联追溯:找到一次对话后,能继续深挖上下文
这是 OpenClaw 搭建系列的最后一课,也是整个系列的「点睛之笔」——有记忆、能回忆的AI,才真正算得上「智能伙伴」。
准备工作
这节课需要:
-
配置好的 OpenClaw(前11课内容) -
一个支持词嵌入(Embedding)的模型(Gemini 免费提供) -
约 15 分钟时间
不需要:
-
额外付费(Gemini embedding 免费额度充足) -
配置外部数据库 -
复杂的向量检索知识
全文记忆检索是什么?
全文记忆检索 = 让AI能从历史对话中「回忆」信息的能力。
我们之前配置的 MEMORY.md 属于「结构化记忆」——适合存明确的偏好、路径、设定。但它有两个局限:
-
需要主动记录:你记得说”记住这个”,它才会存 -
只能精确匹配:你问”上周的API方案”,如果MEMORY.md里没写”API方案”四个字,就找不到
全文检索解决的问题:
| 场景 | 结构化记忆 | 全文检索 |
|---|---|---|
| 记得说过某个概念 | ❌ 找不到 | ✅ “好像讨论过…” |
| 只记得关键词片段 | ❌ 必须完全匹配 | ✅ 语义相似即可 |
| 需要完整对话上下文 | ❌ 只有摘要 | ✅ 整段对话可追溯 |
| 时间跨度大(数月) | ❌ 只记重要决策 | ✅ 所有对话可检索 |
核心原理(简单版):
OpenClaw 会把每次对话保存下来,用「词嵌入模型」把文字转成数学向量。当你搜索时,同样转成向量,找最相似的——这就是RAG(检索增强生成)。
不用理解原理,只要知道:它能像谷歌一样,用关键词找到你的历史对话。
第一步:启用会话归档(Hooks)
想要检索,首先得有「档案」。OpenClaw 通过 Hooks 机制自动保存每次会话。
1.1 什么是 Hooks?
Hooks 是 OpenClaw 的「事件钩子」——在特定时机自动执行操作。
默认提供的 Hooks:
| Hook 名称 | 触发时机 | 作用 |
|---|---|---|
| 📎 bootstrap-extra-files | 启动时 | 注入额外引导文件 |
| 📝 command-logger | 每次命令 | 记录命令日志 |
| 🧠 session-memory | 会话结束 | 保存完整会话记录 |
| 🚀 boot-md | 网关启动 | 执行 BOOT.md 内容 |
我们要启用的是 session-memory,它会自动保存每次对话的完整内容。
1.2 配置 Hooks
查看当前 hooks 配置:
openclaw config get hooks
预期输出(已启用):
{
"enabled": ["session-memory", "bootstrap-extra-files", "command-logger"]
}
如果没有启用,添加配置:
openclaw config set hooks.enabled '["session-memory", "bootstrap-extra-files", "command-logger"]'
或在配置文件中添加:
{
"hooks": {
"enabled": ["session-memory", "bootstrap-extra-files", "command-logger"]
}
}
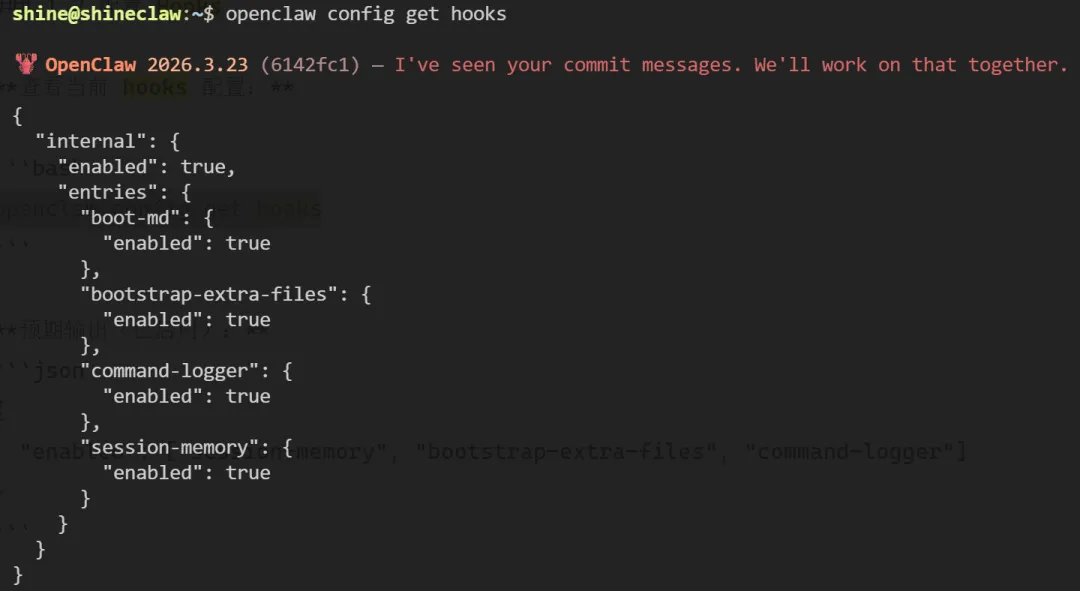
图中显示了 hooks.enabled 配置,session-memory 已启用
1.3 验证归档功能
启用后,每次发出 /new 或 /reset 开启新会话时,之前的对话会被自动保存到:
~/.openclaw/agents/<agentId>/sessions/
检查归档目录:
ls -la ~/.openclaw/agents/main/sessions/ | head -10
预期输出:
drwxr-xr-x 10 shine shine 4096 4月 15 10:00 .
drwxr-xr-x 5 shine shine 4096 4月 15 09:00 ..
-rw-r--r-- 1 shine shine 2048 4月 15 10:00 2026-04-15-abc123.json
-rw-r--r-- 1 shine shine 1536 4月 15 09:30 2026-04-15-def456.json
-rw-r--r-- 1 shine shine 3584 4月 14 16:00 2026-04-14-ghi789.json
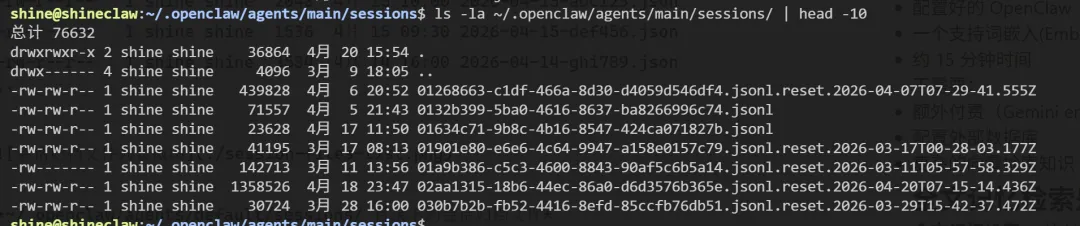
~/.openclaw/agents/main/sessions/ 目录下的会话归档文件
文件名格式: YYYY-MM-DD-会话ID.json
每个文件包含完整的对话记录:用户消息、AI回复、工具调用、时间戳等。
第二步:配置词嵌入模型
有了档案,还需要「索引」才能快速检索。OpenClaw 使用词嵌入模型建立语义索引。
2.1 什么是词嵌入?
简单理解:把文字转换成「语义向量」。
-
“苹果” 和 “iPhone” → 向量很接近(语义相关) -
“苹果” 和 “香蕉” → 向量也较近(都是水果) -
“苹果” 和 “汽车” → 向量很远(语义无关)
当你搜索 “手机”,即使历史记录里只有 “iPhone”,语义相近也能被找到。
2.2 Gemini Embedding(推荐)
Gemini 提供免费的词嵌入模型 gemini-embedding-001,额度充足(每天10万+次请求)。
配置步骤:
-
获取 Gemini API Key(如果已有可跳过)
-
访问 https://aistudio.google.com/app/apikey[1] -
创建新的 API Key
-
-
添加到配置文件:
{
"agents": {
"defaults": {
"memorySearch": {
"enabled": true,
"provider": "gemini",
"remote": {
"baseUrl": "https://generativelanguage.googleapis.com/v1beta",
"apiKey": "YOUR_GEMINI_API_KEY"
}
}
}
}
}
参数说明:
-
enabled: 启用记忆搜索 -
provider: 使用 gemini 作为嵌入 provider -
remote.baseUrl: Gemini API 地址 -
remote.apiKey: 你的 Gemini API Key

memorySearch 配置结构示例
-
重启 OpenClaw 生效
openclaw restart
2.3 使用 OpenAI 兼容接口(备选)
如果你已有 OpenAI 兼容的 embedding 服务(如 text-embedding-3-small):
{
"agents": {
"defaults": {
"memorySearch": {
"enabled": true,
"provider": "openai",
"remote": {
"baseUrl": "https://api.openai.com/v1",
"apiKey": "YOUR_OPENAI_API_KEY",
"model": "text-embedding-3-small"
}
}
}
}
}
2.4 验证嵌入配置
测试对话:
帮我找一下之前讨论过的那个API设计方案
如果配置正确,AI会:
-
调用 memory_search工具搜索历史记录 -
找到相关对话并展示
验证失败排查:
-
检查 API Key 是否正确 -
确认 provider和baseUrl匹配 -
查看 OpenClaw 日志是否有 embedding 相关错误
第三步:安装 session-logs 技能
OpenClaw 提供了专门的 session-logs 技能,用于搜索和分析会话历史。
3.1 安装依赖
session-logs 依赖 jq 和 ripgrep 两个命令行工具:
macOS:
which jq || brew install jq
which rg || brew install ripgrep
Ubuntu/Debian:
which jq || sudo apt-get install jq
which rg || sudo apt-get install ripgrep
验证安装:
jq --version
rg --version
3.2 启用 skill
依赖安装好之后会自动启用,可以通过命令:
openclaw skills list
查看 session-logs 状态

3.3 验证技能可用
测试对话:
搜索我上周关于Python的会话
AI 应该会自动调用 session-logs 技能进行搜索。
第四步:使用记忆检索
配置完成后,你可以用自然语言搜索历史对话。
4.1 基础搜索
你说:
帮我找一下之前讨论过的那个API设计方案
AI会:
-
调用 memory_search在历史记忆中查找 -
如果记忆中没有,调用 session-logs搜索归档会话 -
返回找到的相关内容
AI回复示例:
找到了!在 2026-04-10 的会话中,我们讨论了用户认证API的设计:
当时的方案:
使用 JWT Token 进行身份验证 Token 有效期 7 天,支持刷新 登录接口: POST /api/auth/login返回格式: { token, refreshToken, expiresIn }需要我展示更多当时的讨论细节吗?
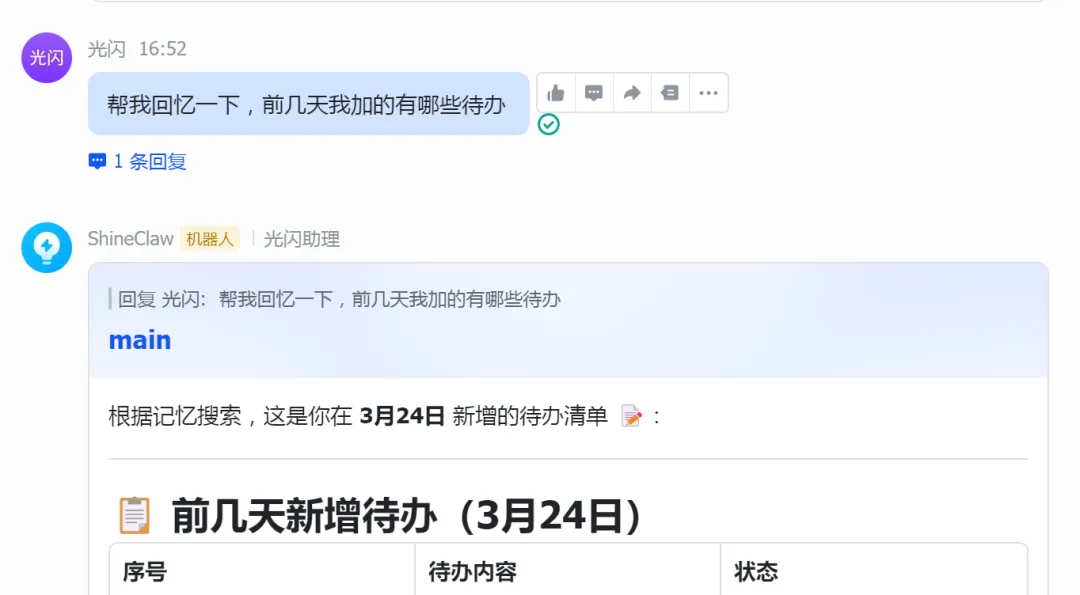
AI根据模糊描述找到历史对话内容
4.2 精准定位
你说:
查看 2026-04-10 那次关于API的完整对话
AI会: 使用 memory_get 或 session-logs 提取完整会话内容。
4.3 跨记忆类型检索
OpenClaw 会同时搜索多个来源:
| 来源 | 内容 | 工具 |
|---|---|---|
| MEMORY.md | 结构化记忆 | memory_search |
| 每日记忆 | 日期摘要 | memory_search |
| 会话归档 | 完整对话 | session-logs |
搜索优先级:
-
先查 MEMORY.md(最精准的结构化信息) -
再查每日记忆(时间维度摘要) -
最后查会话归档(完整对话内容)
4.4 实际应用场景
| 场景 | 你说 | AI动作 |
|---|---|---|
| 找技术方案 | “之前那个数据库设计方案” | 搜索技术相关对话 |
| 找代码片段 | “上周写的那个Python脚本” | 搜索代码块 |
| 找决策记录 | “为什么选Kimi而不是GLM” | 搜索决策讨论 |
| 恢复上下文 | “继续昨天没做完的任务” | 提取上次会话 |
| 知识复习 | “我学过什么关于Docker的内容” | 聚合相关主题 |
第五步:理解其他 Hooks
除了 session-memory,了解其他 hooks 能让你更好地定制 OpenClaw。
5.1 bootstrap-extra-files
作用: 启动时自动注入额外文件到工作区。
使用场景:
-
自动加载项目特定的 AGENTS.md -
注入临时配置或模板 -
多项目切换时加载对应记忆
配置示例:
{
"hooks": {
"config": {
"bootstrap-extra-files": {
"patterns": [
"~/projects/${PROJECT}/AGENTS.md"
]
}
}
}
}
5.2 command-logger
作用: 记录所有执行过的命令到日志文件。
日志位置:
~/.openclaw/logs/commands.log
用途:
-
审计和排查问题 -
统计使用频率 -
恢复误操作前的状态
5.3 boot-md
作用: 网关启动时执行 BOOT.md 文件内容。
使用场景:
-
启动时发送通知 -
初始化环境检查 -
自动执行日常任务
BOOT.md 示例:
# 启动检查清单
- [ ] 检查磁盘空间
- [ ] 同步配置文件到Git
- [ ] 发送启动通知到飞书
常见问题 FAQ
Q1: 搜索不到历史记录?
排查步骤:
-
确认 session-memory hook 已启用: openclaw config get hooks.enabled -
检查会话目录是否存在: ls ~/.openclaw/agents/default/sessions/ -
确认 embedding 配置正确且 API Key 有效 -
等待几秒后重试(嵌入索引可能有延迟)
Q2: Gemini embedding 免费额度够吗?
额度情况:
-
Gemini embedding-001:每天 100,000 次请求免费 -
一次典型搜索:1-3 次嵌入调用 -
正常使用:足够支撑每天数百次搜索
超出额度: 可以配置备用 embedding provider(如 OpenAI)。
Q3: 会话记录会占用多少空间?
空间估算:
-
一次普通对话:10-50 KB -
每天 10 次对话:约 300 KB/天 -
每月:约 9 MB -
每年:约 100 MB
清理旧记录:
# 删除 3 个月前的会话
find ~/.openclaw/agents/default/sessions/ -name "*.json" -mtime +90 -delete
# 归档到压缩包
find ~/.openclaw/agents/default/sessions/ -name "*.json" -mtime +90 -exec tar -rvf old-sessions.tar {} \;
Q4: 敏感对话会被记录吗?
默认行为:
-
✅ 所有对话都会归档 -
✅ 包括可能包含敏感信息的对话
隐私建议:
-
定期清理敏感会话:
# 找到并删除包含敏感词的会话
rg -l "密码|密钥|token" ~/.openclaw/agents/default/sessions/ | xargs rm -
使用私密模式:
/private 开启私密会话(不记录到归档) -
工作区隔离:
-
敏感工作使用独立 Agent -
每个 Agent 有独立的会话目录
-
Q5: 记忆搜索和谷歌搜索有什么区别?
| 特性 | 记忆搜索 | 谷歌搜索 |
|---|---|---|
| 数据来源 | 你的历史对话 | 互联网 |
| 隐私性 | 完全私密 | 公开网络 |
| 个性化 | 高度个性化 | 通用结果 |
| 时效性 | 历史记录 | 最新信息 |
| 用途 | 找回往事 | 获取新知 |
两者互补:
-
记忆搜索 = “我什么时候说过…” -
谷歌搜索 = “现在世界上发生了什么”
Q6: 可以用自己的 embedding 模型吗?
可以,配置自定义 provider:
{
"models": {
"providers": {
"my-embedding": {
"baseUrl": "http://localhost:8000",
"apiKey": "",
"models": [
{
"id": "local-embed",
"name": "Local Embedding",
"input": ["text"]
}
]
}
}
},
"agents": {
"defaults": {
"memorySearch": {
"enabled": true,
"provider": "my-embedding",
"model": "local-embed",
"remote": {
"baseUrl": "http://localhost:8000"
}
}
}
}
}
Q7: 如何让AI更频繁地使用记忆?
方法1:在 AGENTS.md 中强调
## 记忆使用准则
- 回答前优先搜索相关记忆
- 不确定时查看历史记录
- 主动关联过去的讨论
方法2:通过对话训练
以后回答我的问题前,先搜索一下历史记忆,看看有没有相关讨论
方法3:配置强制搜索
{
"agents": {
"defaults": {
"instructions": [
"每次回答前,先调用 memory_search 搜索相关历史信息"
]
}
}
}
进阶技巧
技巧1:定期记忆维护
每周整理一次:
帮我整理这周的记忆:
1. 把重要的临时信息写入 MEMORY.md
2. 删除过期的每日记忆
3. 归档旧的会话记录
技巧2:跨会话任务追踪
建立任务档案:
在 MEMORY.md 中创建一个「进行中任务」列表,每完成一个就勾选掉
示例 MEMORY.md:
## 进行中任务
- [x] 配置 OpenClaw 基础环境
- [x] 接入飞书频道
- [x] 配置记忆系统
- [ ] 配置全文检索
- [ ] 测试视频生成功能
## 已完成项目
### OpenClaw搭建系列(12/12课)
- 2026-04-20: 完成全文记忆检索配置
技巧3:关键词标签化
在对话中主动打标签:
【项目A】这个需求需要用到Redis缓存...
搜索时:
搜索关于【项目A】的所有讨论
技巧4:记忆备份策略
定期备份会话:
#!/bin/bash
# backup-sessions.sh
BACKUP_DIR="~/backup/openclaw-sessions"
SESSION_DIR="~/.openclaw/agents/default/sessions"
DATE=$(date +%Y%m%d)
mkdir -p $BACKUP_DIR
tar -czf $BACKUP_DIR/sessions-$DATE.tar.gz $SESSION_DIR
# 保留最近10个备份
ls -t $BACKUP_DIR/sessions-*.tar.gz | tail -n +11 | xargs rm -f
技巧5:使用记忆做周报
每周五:
根据本周的每日记忆,帮我生成一份工作周报
AI 会自动:
-
读取本周的 memory/2026-04-*.md -
提取完成的任务 -
整理成周报格式
总结:完整的 OpenClaw 记忆体系
恭喜,你的 OpenClaw 拥有了「完整记忆能力」!
回顾整个记忆体系:
| 记忆类型 | 存储位置 | 检索方式 | 用途 |
|---|---|---|---|
| 结构化记忆 | MEMORY.md 等 | 直接读取 | 偏好、路径、设定 |
| 每日摘要 | memory/YYYY-MM-DD.md | memory_search | 快速回顾 |
| 完整会话 | sessions/*.json | session-logs | 深度追溯 |
| 语义索引 | 向量数据库 | memory_search | 模糊查找 |
现在你的AI可以:
-
✅ 记住重要信息(第11课) -
✅ 回忆历史对话(第12课) -
✅ 持续学习你的偏好 -
✅ 越用越懂你
OpenClaw 搭建系列 12 课全部完成!
回顾 12 节课成果:
| 课程 | 能力 | 状态 |
|---|---|---|
| 第1课 | 大脑(模型配置) | ✅ 能思考、能推理 |
| 第2课 | 嘴巴(飞书接入) | ✅ 能收发信息 |
| 第3课 | 耳朵(实时搜索) | ✅ 能获取新信息 |
| 第4课 | 眼睛(图片理解) | ✅ 能看懂图片 |
| 第5课 | 双手(文生图) | ✅ 能生成图片 |
| 第6课 | 嗓子(语音回复) | ✅ 能开口说话 |
| 第7课 | 耳朵(语音识别) | ✅ 能听懂语音 |
| 第8课 | 眼睛(视频分析) | ✅ 能看懂视频 |
| 第9课 | 导演(视频生成) | ✅ 能制作视频 |
| 第10课 | 双手(浏览器自动化) | ✅ 能操控浏览器 |
| 第11课 | 记忆(长期记忆系统) | ✅ 能记住重要的事 |
| 第12课 | 回忆(全文记忆检索) | ✅ 能找回历史对话 |
你的 AI 已经从一个「工具」成长为「伙伴」:
-
能听、能说、能看、能写 -
能搜索、能浏览、能创作 -
能记住、能回忆
这不是终点,而是起点。
接下来的「实战系列」,我们将用这些能力完成真实任务:自动生成公众号文章、自动发布B站视频、让AI主动找活干…
准备好了吗?实战系列见!
课后作业
试试这些玩法:
-
找回一次旧对话:试着用模糊描述让AI找回一周前的某个讨论 -
建立个人知识库:把重要技术笔记通过对话存入记忆 -
测试语义搜索:用不同的关键词搜索同一主题(如”Python”和”Py”) -
整理记忆文件:让AI帮你整理 MEMORY.md,删除过期的 -
创建任务追踪:在 MEMORY.md 中建立项目进度追踪表
附录:配置速查表
记忆搜索配置
{
"agents": {
"defaults": {
"memorySearch": {
"enabled": true,
"provider": "gemini",
"remote": {
"baseUrl": "https://generativelanguage.googleapis.com/v1beta",
"apiKey": "YOUR_API_KEY"
}
}
}
}
}
Hooks 配置
{
"hooks": {
"enabled": ["session-memory", "bootstrap-extra-files", "command-logger"]
}
}
依赖安装
# macOS
brew install jq ripgrep
# Ubuntu/Debian
sudo apt-get install jq ripgrep
常用命令
# 查看会话列表
ls -lt ~/.openclaw/agents/default/sessions/
# 搜索会话内容
rg "关键词" ~/.openclaw/agents/default/sessions/
# 查看今日记忆
cat ~/.openclaw/workspace/memory/$(date +%Y-%m-%d).md
# 备份所有记忆
tar -czf backup-$(date +%Y%m%d).tar.gz ~/.openclaw/workspace/
🎉 OpenClaw 搭建系列(12/12)完结!
文章作者:光闪
系列:OpenClaw 搭建与配置
发布日期:2026-04-20
下一步
实战系列预告:
-
实战1:公众号文章自动生成与发布 ✅ 已发布 -
实战2:B站视频全自动投稿 -
实战3:定时任务与心跳机制 -
实战4:自动提交 Issue 和 PR
敬请期待!
引用链接
[1]https://aistudio.google.com/app/apikey