 夜雨聆风
夜雨聆风





AI什么都懂,是因为它把知识都背下来了吗?答案出乎意料

今天跟团队伙伴开会,有个小伙伴提到了一个问题
“AI 的那些知识,是存储在模型里的吗?”
因为这个答案真的很有趣却又反常识,所以,我写了这篇来详细回答一下,先说答案:
AI(大语言模型)不存储任何知识。
是的,即使你看到AI非常流畅的背出唐诗三百首,甚至能够直接输出某个传记全文。
但但但是,这些内容并没有存在大模型中,一丝一毫都没有。
啊,这就非常神奇了,如果没有记下来,没有存下来,那AI是如何知道要说什么呢?为什么看起来像是他完全记得,全部背下来了一样。
如果你也很好奇,那稍安勿躁,我们得先了解一下AI(大语言模型)是如何被练成的。
AI的训练方式,虽然也是用了大量的书本、大量的知识。
但是,AI的学习方式并不像人一样,拿着一本一本书认真阅读、做笔记、背诵、记忆。
AI训练和学习的方式,从头到尾,练的都不是“记住”知识,而是“预测下一个词”。
你可以把大模型想象成一个规模极其夸张的“文字接龙机器”。
训练时,工程师会给它看海量文本:
新闻、小说、论文、网页、代码、对话、百科……
然后不断让它做一件事:
根据前面这段文字,猜测,下一个最有可能出现的词是什么。
比如:
“床前明月光,疑是地上___”
它要猜“霜”。
再比如:
“秦始皇统一六国的时间是公元前___年”
它要猜“221”。
AI不是在“脑子”里翻一本历史书,也不是从某个“知识仓库”里把答案取出来。
它只是根据自己在训练过程中形成的海量参数关系,判断:
在这样的前文后面,什么词出现的概率最高。
这就是大模型最底层的原理。
就像视频中一样,这就是模型输出内容的最底层的原理,根据前文,输出后边出现的可能性最大的词。
那这个概率词是怎么算出来的呢?
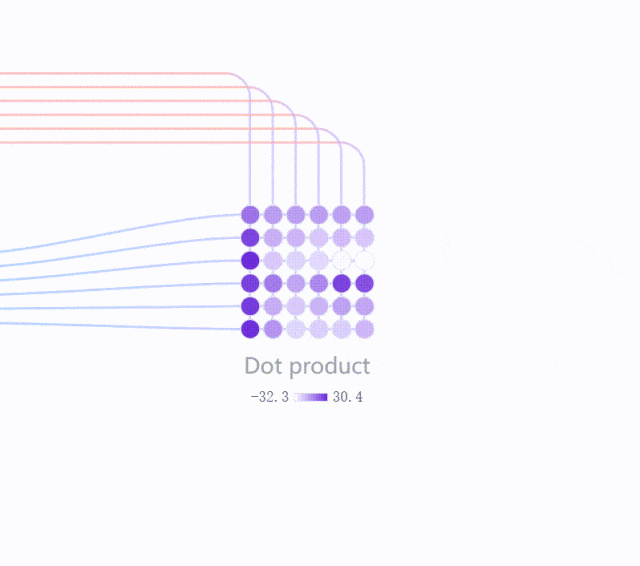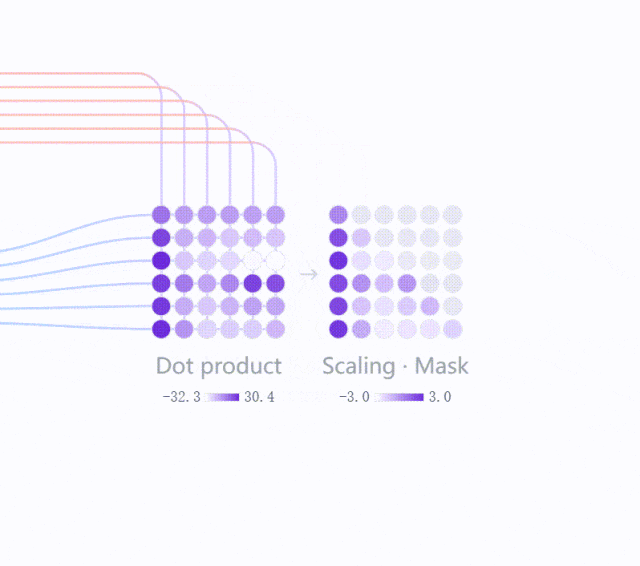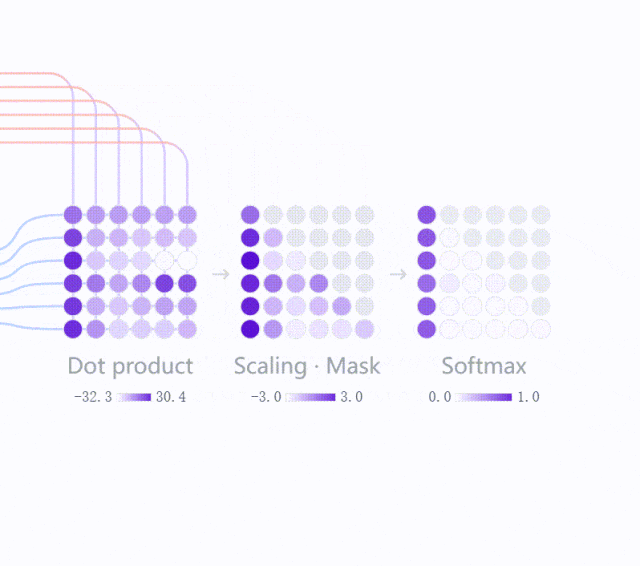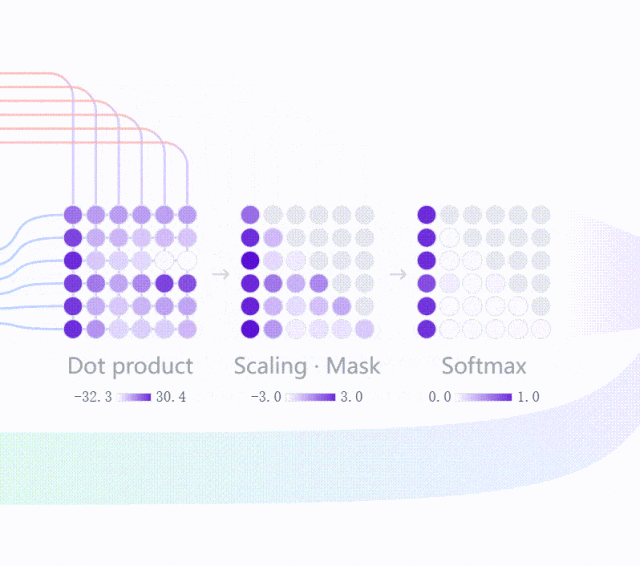
你看下方这个视频,就是预测下一个词的时候模型内部发生的过程简化示意。
视频里出现了一些专业名词,但是你不用关心,你只需要知道,我们看到的文字其实是被转化成了一串非常长的数字编码。
模型处理文字时,并不是直接处理“字面上的字”,而是先把文本切成一个个“词元”,再转成数字表示。
在后续训练中,模型会逐渐学到:哪些表达经常一起出现,哪些概念彼此接近,哪些上下文后面更可能接什么内容。
所以在模型内部,语义相近的表达,往往会形成更接近的内部表示。
比如“快乐”和“happy”,虽然字面不同,但在很多语境里它们可能会被模型处理成相近的含义;在模型的空间中,这两个词的距离更近。
就像是视频中,当你输入“你是谁?”时,模型也不是去某个知识库里把答案“取出来”,而是根据上下文和训练中学到的参数关系,计算出下一个词最可能是什么。
如果“我”在这个位置的概率最高,它就输出“我”,然后继续预测下一个词,直到整句话结束。
所以,大模型内部真正存在的,是一句句文本,也不是一段段资料,更不是一个可以打开查看的“数据库”。
在模型中存在的其实是一种非常复杂的参数结构。
大模型记住的不是“内容本身”,是内容之间的统计规律。
这就像一个人听了无数遍中文之后,慢慢掌握了中文的语感、结构、搭配、逻辑。
当你说出一句话的前半句时,他已经大概知道后半句会往哪个方向走。
大模型也是一样。
它不是把《唐诗三百首》一首一首存起来了,
而是在海量训练中,学会了“唐诗这种文本一般长什么样”“李白的语言通常是什么感觉”“床前明月光后面极大概率会接什么”。
所以它看起来像背下来了。
但本质上,他没有“回忆”知识,他是在靠感觉重新:生成文本。
这也是为什么,大模型有时候会让人产生一种强烈错觉:
你会觉得它脑子里一定有一个超级图书馆。
你问什么,它就从里面精准翻出来。
但其实不是。
它更像一个经过极端训练之后,拥有超强语言压缩能力和模式拟合能力的系统。
它不是把互联网装进脑子里了。
而是把互联网上海量文本里那些“规律”,压缩进了参数里。
所以,AI模型不是知识仓库,更没有记住全部世界知识。
他更像是:语言规律机器。
那既然是概率,那为什么AI有时候又能把一些内容说得那么准,甚至像是原文复述?说的那么对呢?
这因为当某段内容在训练数据里出现得足够多、足够稳定、足够标准化的时候,
这些模式就会被“压”得非常牢,这些词的前后出现概率已经高到几乎“固定”了。
比如:
-
常见古诗
-
著名定义
-
高频历史事实
-
固定格式的经典文本
-
大量公开传播的名句和段落
这些内容由于分布太广、重复太多、结构和概率太稳定,所以模型就很容易在生成时“猜”出来。
所以,AI只是看似在背答案。(其实,他压根不知道对与错,他只知道,下一个词,大概率就是这个!)
理解这一点之后,你就会明白另外一件更重要的事:
为什么 AI 会一本正经地胡说八道。
因为它的目标,从来不是“说真话”,而是“说得像真的”,说的趋近于真的。
这句话非常关键。
因为诗词后续有标准答案,但是更多的问题是没有标准答案的,只要预测的近似于正常回答,既可以得到高分。
所以在训练的时,大模型得到的核心目标是:让输出在语言上足够自然、连贯、符合上下文。
而遗憾的是“语言上是对的”,不等于“事实上是真的”。
当它面对一个自己没有学扎实、或者语境不够明确的问题时,
它依然甚至必须努力往下生成。
没有见过答案,那就只能根据内部已有参数的概率,预测出下一个词,最终给你一个“看起来很合理”的回答。
于是,幻觉出现了。
比如它可能会:
-
编一个不存在的论文
-
造一个听起来很像真的案例
-
杜撰一本并不存在的书
-
给你一个逻辑顺滑但事实错误的解释
这不是因为它故意骗你。
而是因为它本质上是在做概率续写。 他真的不知道对错~
在这里,提出一个问题?那既然大模型本身不存储知识,他也不懂知识,只是在预测。那我们还让 AI 做知识库问答、查企业资料、读内部文档,这AI给出的回答还靠谱吗?
3
2
1
即使用了知识库,AI回答的也不一定靠谱。
只是有了知识库之后,AI可以更!大!概!率!输出正确的答案。(因为外部资料可以改变它后续输出的概率分布。)
但,并不一定能得到正确的答案。
比如,当前时间,现在是几月几日。
如果不联网,AI是一定不知道当前时间的,如果硬是要问,AI只能瞎说一通,或者拒绝回答。
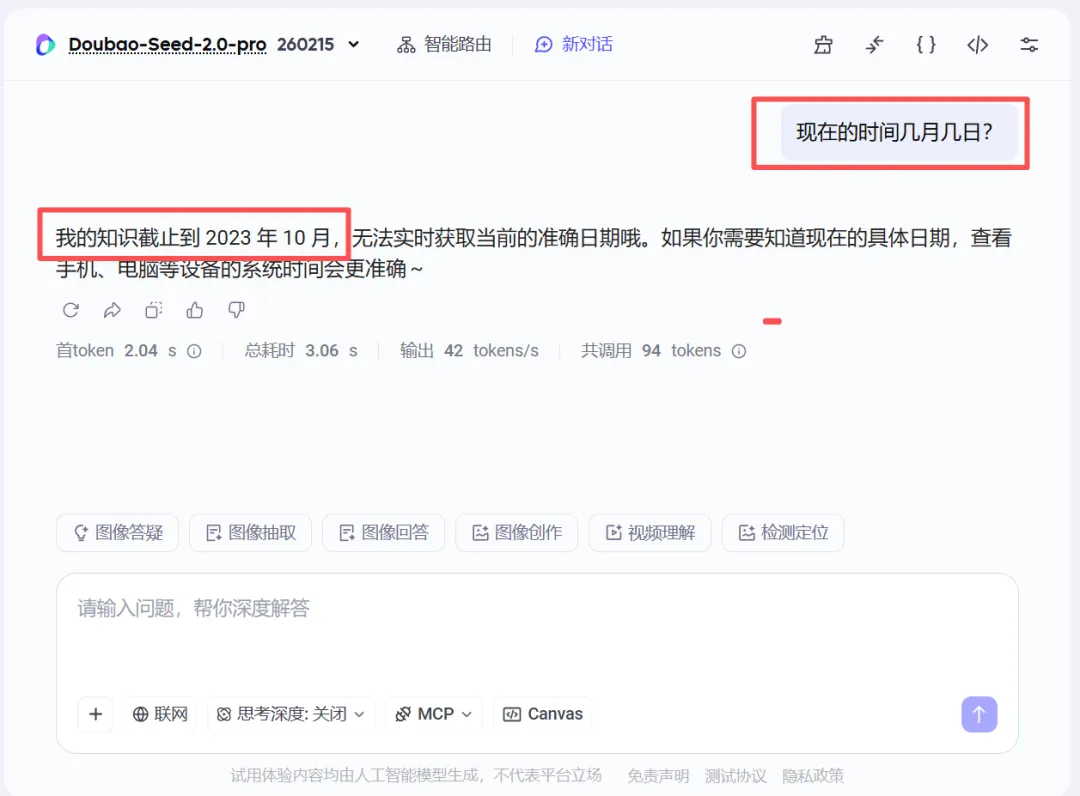
但是如果你通过外部工具告诉他现在的时间,当你再问到时间的时候,他才更大概率的能回答正确。
下图中实际时间是4月20日,但是我给了他6月6日的前文,那么 他就一定会输出:6月6日。
因为在这个语境下,6月6日的出现概率更高。
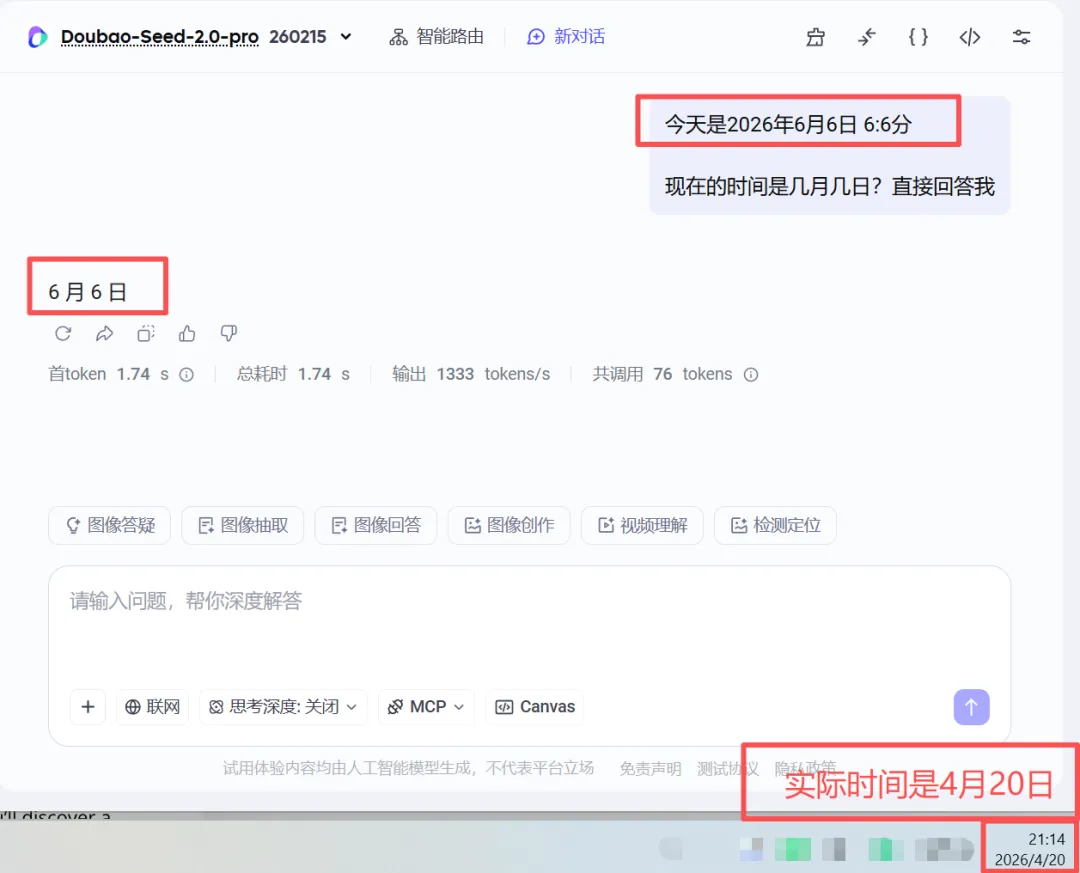
所以,无关正确,无关记忆,全是概率。
而输入的文本,提问的问题,就极大的影响了后续输出的每个词出现的概率。
这也是为什么这两年提示词工程、RAG、知识库、工作流这些东西这么重要,也是为什么即使不一定准确,但是知识库依然是有价值的:就是因为更准确的引导内容,才更能提高后续回答的正确概率。
这是根本。
回到最开始那个问题:
AI 的知识,是存储在模型里吗?
很明确:不是。
模型里没有一篇篇文章,也没有一本本书,更没有一个整整齐齐的知识文件柜。
模型里只有参数。
而参数里保存的,是海量文本被压缩之后形成的关联、权重、模式和概率结构。
AI 只是看起来像是“记得”,
其实它是在“生成”。
看起来像是在“调用知识”,
其实它是在“沿着最有可能的路径,把语言继续写下去”。
这就是为什么它如此强大。
同时也是为什么,它并不可靠到可以被无条件相信。
在这里,我要插一句,很多人,非常轻信于AI的回答,这一点我在我爸的身上看到了非常明显的案例,关于购物决策,豆包的回答甚至能够影响他60%以上的决策。
这是非常恐怖的,
因为,你以为得到的是豆包结合了全网知识给出的公正回答,
但其实,你可能得到的是被精心设计的答案。
AI不是一个会背书的万事通大脑。
它只是一个被训练到极致的概率生成系统。
理解这一点,才算真正理解了大语言模型。
我是梦飞,我们下次见~