 夜雨聆风
夜雨聆风





从 Claude 源码里学到的:怎么让模型稳定输出 JSON
做 AI 应用开发的人,大概都遇到过这个场景:你严格让模型”输出合法 JSON”,甚至连格式都给它写上了,但是它仍会损坏json,且claude要比gpt更频发。本文从一个真实的线上 bug 出发,通过翻 Claude Code 的源码,搞清楚了 Anthropic 自己是怎么解决这个问题的。
先说一个真实的 bug
AI Agent 项目中的一个环节需要让 Claude 分析一段文本,返回结构化的 JSON 结果,大概长这样:
{"tasks":[{"name":"创建实例","steps":"xxx...","type":"ui"},{"name":"配置接口","steps":"调用 API...","type":"api"}]}我在 prompt 里写得很清楚——”请仅以严格的 JSON 格式提供您的回复,不包含任何其他文本。 确保所有双引号都已正确转义,并且 JSON 有效,使用以下 JSON 键进行回答”。
结果跑到线上就炸了。
炸了三种姿势
第一种:引号没转义。
模型在 JSON 的字符串值里直接写了带引号的内容:
{"reason": "处理"程序"的方式"}"程序" 两边的引号和 JSON 的结构引号撞车了,整个 JSON 直接废掉。这个问题在 Reddit 上一堆人报过,大概每 10 次出现 1 次。
第二种:先自言自语再输出。
模型先写一段话——”Now I have all the positions needed. Let me construct the final JSON output:”——然后才开始输出 JSON。你拿到的是一大段文字加 JSON 的混合物。
第三种:写到一半不写了。
输入文本比较长的时候,模型的 JSON 输出到一半就停了,括号没闭合。
为了兜住这些问题,我前后加了四层解析策略:
-
• 直接 JSON.parse,能解析就用 -
• 用正则把代码块里的 JSON 提出来 -
• 找到第一个 {,从尾部往前找},挨个试 -
• JSON 截断了,就尝试在尾部补括号闭合
大部分场景能兜住,但引号没转义会质检导致失败。因为 "处理"程序"的方式" 这种东西,JSON 解析器在 "处理" 之后就认为字符串结束了,后面全是语法错误,怎么补都补不回来。
prompt 对模型的约束是概率性的,模型读了prompt的指令后,生成每个 token 时确实会倾向于正确的格式,但这只是提高了概率,没法保证 100%。比如生成到 "处理" 的时候,模型可能 90% 的概率会正确转义引号,但那 10% 它就是会直接输出一个裸引号——而只要出错一次,整个 JSON 就废了。
翻 Claude 的源码,发现了一个巧妙的解法
Claude Code 是 Anthropic 官方的 AI 编程工具,它内部也需要让模型输出 JSON。翻了源码后发现,它可以通过把文本包成工具,然后用工具的协议来约束输出合法的Json。
具体来说,SDK 在运行时可以根据你的 Schema 动态创建一个空壳,它不会执行任何实际操作,唯一的作用就是接收模型的输出数据。关键在于:模型一旦走了工具调用的路径,数据就从文本通道切换到了专用通道,格式保障从”靠 prompt 约束”变成了”靠协议保证”。
为什么这样就能解决?看 Claude Code 的源码就明白了。
关键:模型输出文本和工具参数,不同的路
Claude API 返回的内容不是一整段文本,而是分成了不同类型的”区块”。看源码里的流式处理部分(claude.ts):
// 模型返回的内容分成不同类型的区块case'content_block_start':switch (part.content_block.type) {case'tool_use': // 工具调用区块 contentBlocks[part.index] = { ...part.content_block,input: '', // 工具参数,初始化为空字符串 }breakcase'text': // 文本区块 contentBlocks[part.index] = { ...part.content_block,text: '', // 文字内容,初始化为空字符串 }break }文本区块和工具调用区块从一开始就是分开的。模型说的”废话”和你要的 JSON 数据不会混在一起。
再看数据怎么流入这两种区块:
// 两种区块的数据流入通道也完全不同case'content_block_delta':switch (delta.type) {case'input_json_delta': // JSON 碎片,只能流入工具调用区块 contentBlock.input += delta.partial_jsonbreakcase'text_delta': // 文本碎片,只能流入文本区块 contentBlock.text += delta.textbreak }注意这里,工具参数是通过一个叫 input_json_delta 的专用通道传过来的,每次传一小段 JSON 碎片(partial_json)。这些碎片拼在一起,就是完整的工具参数 JSON。
这些碎片拼完之后,还要过一道关——JSON.parse。如果解析失败,参数会变成空对象 {},绝不会把一段残缺的文本当作 JSON 传给下游(messages.ts):
// 工具参数拼完后,必须通过 JSON.parse 这道关case'tool_use': {let normalizedInputif (typeof contentBlock.input === 'string') {const parsed = safeParseJSON(contentBlock.input) // 必须是合法 JSON normalizedInput = parsed ?? {} // 解析失败就变成空对象 }return { ...contentBlock, input: normalizedInput } // 下游拿到的一定是 JS 对象}所以整个链条就很清晰,:API 服务端把工具参数拆成 JSON 碎片 → 通过专用通道传输 → 客户端拼起来 → JSON.parse 验证 → 传给下游代码。这个过程中没有模型”自由发挥”的空间——要么输出合法 JSON,要么变成空对象触发重试。
但问题来了:上面说的是”工具调用”的天然通道,对于工具是天然的Json,那怎么用到自己的文本上?
答案就是传入的 outputFormat 参数。你定义 schema 并传入 outputFormat,SDK 会在运行时动态创建一个空壳工具,把你的 schema 当作这个工具的参数定义,塞进发给 API 的工具列表里。模型看到工具列表里多了一个叫 StructuredOutput 的工具,就会通过”调用工具”的方式输出数据——自然而然地走上了 tool_use 区块这条路。
下面这张图展示了两种方式的区别:
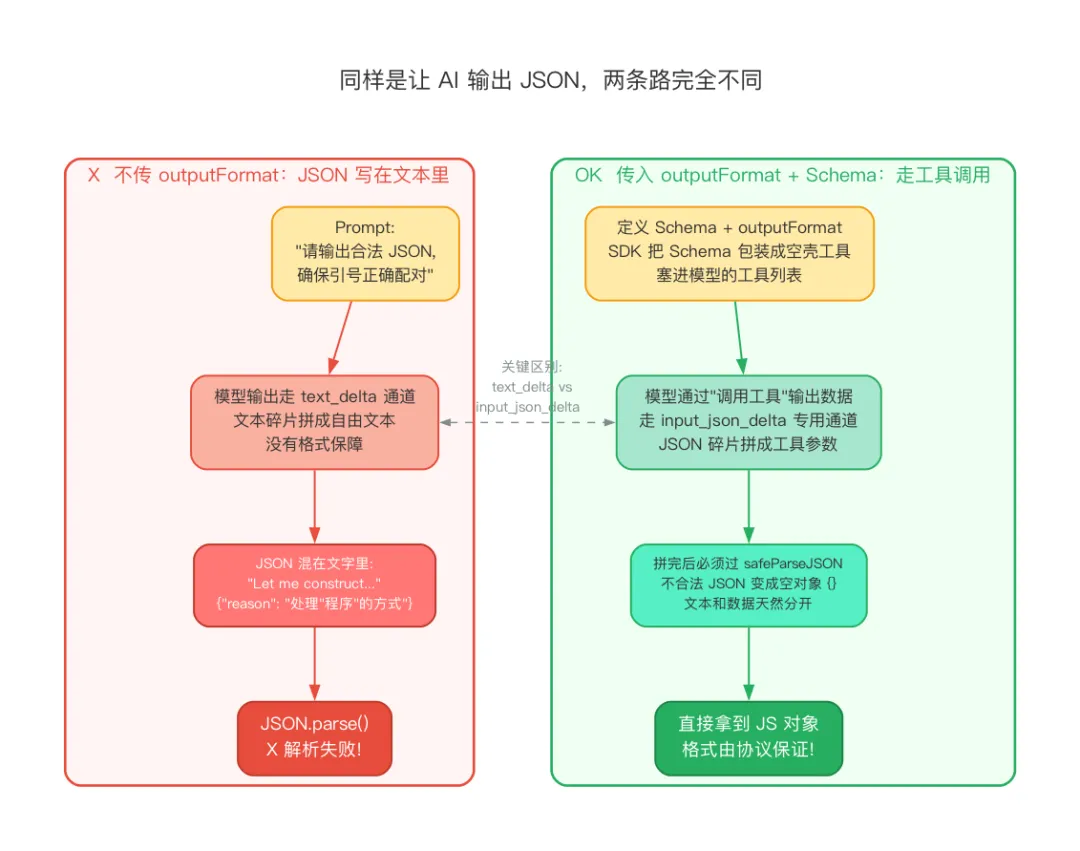
左边是老办法:不传 outputFormat,模型把 JSON 写在文本区块里,走 text_delta 通道,没有格式保障。
右边是新办法:传入 outputFormat + schema,SDK 把 schema 包装成空壳工具,模型通过工具调用输出数据,走 input_json_delta 专用通道,必须通过 JSON 解析。
到这里,JSON 格式的问题已经被通道机制解决了。但格式合法不代表内容正确——模型可能输出了一个完全不相关的结构,比如你要 tasks 字段,它给了一个 result 字段。
格式合法之后,还要校验内容
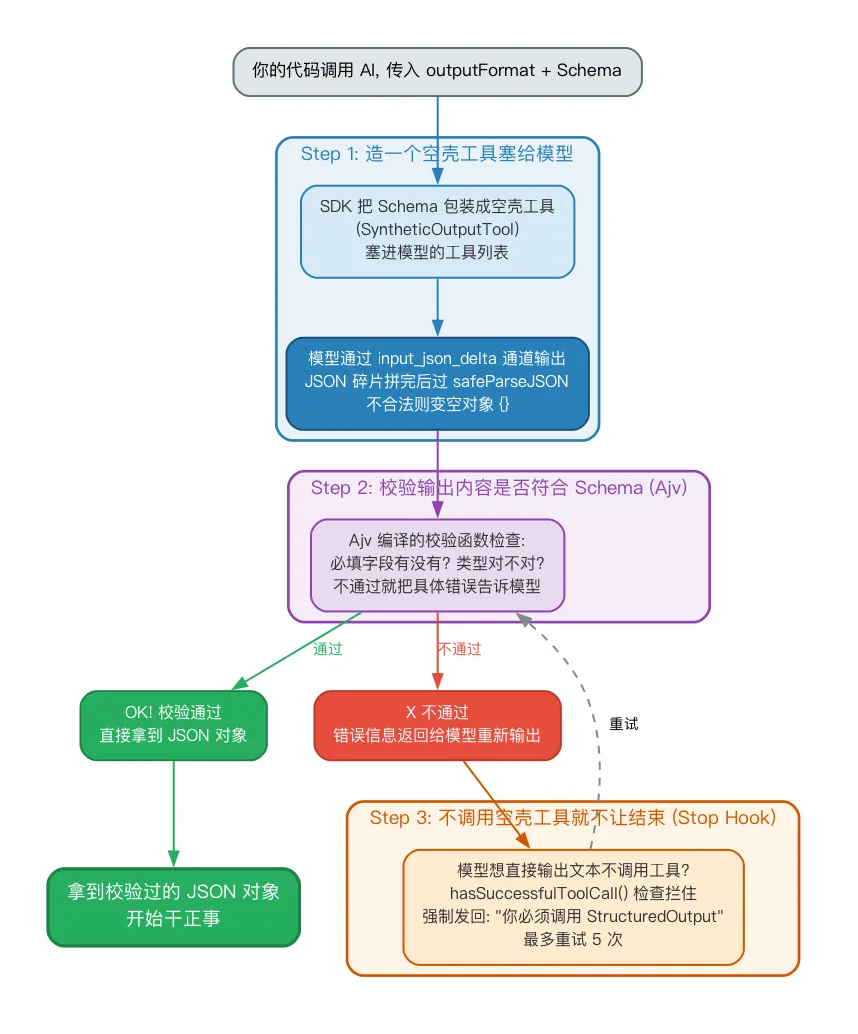
所以 Claude Code 在空壳工具里还加了一层校验。看源码里带 Schema 校验的版本(SyntheticOutputTool.ts):
// 创建空壳工具时,会把你定义的 JSON Schema 编译成校验函数const ajv = newAjv({ allErrors: true })const validateSchema = ajv.compile(jsonSchema) // jsonSchema 就是你定义的格式// 模型调用工具时,先校验再返回asynccall(input) {const isValid = validateSchema(input)if (!isValid) {// 校验失败:把具体错误告诉模型,让它改const errors = validateSchema.errors ?.map(e =>`${e.instancePath || 'root'}: ${e.message}`) .join(', ')thrownewError(`Output does not match required schema: ${errors}`)// 这个错误会变成 tool_result 返回给模型,模型看到后会重试 }return {data: 'Structured output provided successfully',structured_output: input, }}不对?模型会看到类似”缺少必填字段 tasks”这样的错误信息,然后重新输出。
如果模型压根不调用空壳工具呢?
还有一种情况:模型压根没调用那个空壳工具,直接在文本里写了结果就想收工。
Claude Code 用一段很简短的代码解决了这个问题(hookHelpers.ts):
// 注册一个"停止检查":每次模型想结束对话,都会触发这个检查addFunctionHook( setAppState, sessionId,'Stop', // 在模型停止时触发'',messages =>hasSuccessfulToolCall(messages, 'StructuredOutput'), // 检查:调用过空壳工具吗?'You MUST call the StructuredOutput tool to complete this request. Call this tool now.', { timeout: 5000 },)逻辑很直白:模型每次说”我说完了”,系统就去消息记录里找——你成功调用过 StructuredOutput 这个工具吗?
没有?拒绝让你停下来,把那句”你必须调用 StructuredOutput 工具”发回去。模型被迫继续。
这个过程最多重复 5 次,5 次之后还不行才报错放弃。
把上面的整个机制串起来看:
实践,只用改两处
定义你要的 JSON 格式:
const schema = {type: "object",properties: {tasks: {type: "array",items: {type: "object",properties: {name: { type: "string" },steps: { type: "string" },type: { type: "string", enum: ["ui", "api"] }, },required: ["name", "steps", "type"], }, }, },required: ["tasks"],};调用时加一个参数:
const options = { ...原来的参数,outputFormat: { type: "json_schema", schema },};const { structuredOutput } = awaitcallAgent(task, options);if (structuredOutput) { parsed = structuredOutput; // 直接用,不需要 JSON.parse}原来四层策略链的代码没删,留着兜底。但正常情况下走的是工具调用路径,那四层根本不会被触发。
改完跑端到端测试:再也没出现过 JSON 解析失败。
核心思路用一句话描述:claude SDK 根据你的 Schema 动态创建空壳工具,模型被迫通过调用这个工具来输出数据,数据就从文本通道切换到了工具调用专用通道——这条通道在协议层面保证 JSON 格式合法,再加上 Schema 校验保证内容正确,不调用工具就不让结束,保证了JSON格式的合法性。