 夜雨聆风
夜雨聆风





2026年AI模型终极对决:Claude、GPT、Gemini谁才是真正的王者?
原文链接:https://www.buildfastwithai.com/blogs/best-ai-model-per-task-2026作者:Satvik Paramkusam译者:倔强青铜三
前言
大家好,我是倔强青铜三。欢迎关注我,微信公众号:倔强青铜三。欢迎点赞、收藏、关注,一键三连!!!

Claude vs GPT-5.4 vs Gemini 3.1 Pro(2026):哪个 AI 在各项任务中胜出?
我每周都会在编码、写作、研究和 Agent 工作流中使用 AI。上个月,我在相同的任务上测试了 Claude Opus 4.6、GPT-5.4 和 Gemini 3.1 Pro。结果出乎意料——和营销宣传完全不同。Claude 在编码上碾压对手。Gemini 在科学领域遥遥领先。GPT-5.4 在需要准确性的写作任务中是最稳妥的选择。以下是完整解析——逐模型、逐任务,附基准测试数据以及排行榜网站不会告诉你的真实世界细节。
我经历过这一切。以下是诚实答案:2026 年没有单一的”最佳”AI 模型。取而代之的是,几乎所有特定任务都有一个明确的赢家。编码?Claude Opus 4.6 在 SWE-Bench 上得分 75.6%。科学推理?Gemini 3.1 Pro 在 GPQA Diamond 上得分 94.3%。大规模预算 API?DeepSeek V3.2 每百万输入 token 仅需 $0.14。
本指南涵盖了 2026 年当前活跃的每个主要模型、每个模型真正擅长什么、证明它的基准测试,以及针对你的用例到底该选哪个模型。没有历史废话,没有凑数内容,只有核心信息。
1. 2026 年 AI 发生了什么变化(以及为什么你可能用错了模型)
四个关键因素定义了 2026 年 3 月的 AI 模型市场。
前沿模型的性能趋同。 Gemini 3.1 Pro、Claude Opus 4.6 和 GPT-5.4 在大多数基准测试上的差距都在个位数百分比之内。一年前,GPT-4 还遥遥领先。如今,差距已经小到”正确”的模型取决于用例、成本和生态系统,而非纯粹的智能。
专业化成为新战略。 OpenAI 专门为终端 Agent 编码构建了 GPT-5.3 Codex。Anthropic 专门为持续生产工作流构建了 Claude Sonnet 4.6。Google 专门为高容量、低成本 API 使用构建了 Gemini 3 Flash。通用模型仍然存在,但专业化模型正在各自领域获胜。
开源真正具有竞争力了。 Meta 的 Llama 4 Scout 拥有 1000 万 token 的上下文窗口。智谱 AI 的 GLM-5 在 Artificial Analysis 上获得了 50 分的智能指数评分,跻身开源模型顶级梯队。DeepSeek V3.2 每百万输入 token 仅需 $0.14,输出质量达到 GPT-4o 级别。自托管现在是一个真正的选择,而不仅仅是爱好者的实验。
价格同比下降了 80%。 2025 年到 2026 年初,前沿质量模型的 API 成本下降了约 80%。2023 年每 1000 token 需 0.002。这意味着 18 个月前在经济上不可行的 AI 应用,现在已成为常规生产工作负载。
2. 完整模型目录:当前所有主流 AI 模型
以下是 2026 年 3 月正在为用户提供服务的每个重要 AI 模型,按提供商分类。
Anthropic:Claude 系列
-
Claude Opus 4.6(自适应推理,最大努力)— 旗舰模型。SWE-Bench 75.6%,GPQA Diamond 91.3%,100 万上下文窗口(beta),128K 输出 token。最适合:复杂编码、长文分析、需要推理深度的 Agent 工作流。 -
Claude Sonnet 4.6 — Claude.ai 免费和专业计划的默认模型。GDPval-AA Elo 1,633(领先所有模型)。100 万上下文(beta)。在 Claude Code 中 59% 的用户更偏好它而非 Opus 4.5。最适合:生产工作流、内容流水线、大规模 AI 辅助开发。 -
Claude Haiku 4.5 — 快速、高性价比。每百万 token 5.00 输出。最适合:分类、摘要、成本比深度更重要的高批量任务。
OpenAI:GPT 系列
-
GPT-5.4 — 在 Artificial Analysis 智能指数上与 Gemini 3.1 Pro 并列第一。100 万 token 上下文。与 GPT-5.2 相比减少了幻觉。最适合:长篇推理、关键文档、通用专业任务。 -
GPT-5.3 Codex — 专为 Agent 编码和基于终端的软件开发打造的专家模型。原生计算机使用能力,可直接操作 IDE。最适合:运行重度终端 Agent 任务的软件开发者。 -
GPT-5 / GPT-5.2 — 较早的 GPT-5 系列。仍在活跃使用。每百万 token 10 到 14。通用能力强。 -
GPT-4o — 多模态(文本、音频、图像、视频)。具有自然韵律的实时语音。每百万 token 输出 $10。最适合:语音界面、图像理解、实时对话。 -
GPT-4o mini — 预算层级。低成本,高速度。最适合:简单问答、轻量聊天机器人、原型开发。 -
O3 Pro — 用于最苛刻研究任务的推理模型。每百万 token $150 以上。最适合:成本不是限制的专家级科学和数学分析。
Google DeepMind:Gemini 系列
-
Gemini 3.1 Pro — 2026 年 2 月发布。ARC-AGI-2 77.1%(是 Gemini 3 Pro 的两倍多)。GPQA Diamond 94.3%,领先所有模型。每百万 token 12。最适合:科学推理、Agent 多步任务、大上下文处理、Google Workspace 工作流。 -
Gemini 3 Pro — 上一代旗舰。在大多数基准测试上仍然具有竞争力。在 Google 产品中原生集成。 -
Gemini 3.1 Flash — 低延迟,100 万上下文窗口,每百万 token 3。最适合:高容量 API 应用、多语言任务、大规模文档处理。 -
Gemini 2.5 Pro — 较旧但仍广泛使用。每百万 token 10。100 万上下文。 -
Gemini 2.0 Flash-Lite — 每百万 token 0.30。简单任务中仍能良好工作的最便宜选择。
xAI:Grok 系列
-
Grok 4.20 Beta — 多 Agent 架构:四个 AI Agent 并行运行。截至 2026 年 3 月完整 API 尚未开放。SWE-Bench 约 75%(基于 Grok 4 基线)。实时访问 X(Twitter)数据。最适合:研究、科学、数学、社交媒体情报。 -
Grok 4.1 — 每百万 token 0.50 输出,最便宜的闭源前沿级选择。200 万上下文窗口。最适合:需要实时数据访问的成本敏感部署。 -
Grok 4.1 Fast — 200 万上下文,Grok 系列中最低延迟。适合实时应用。
Meta:Llama 系列(开源)
-
Llama 4 Scout — 1000 万 token 上下文窗口,2026 年所有模型中最大的。在 Meta 商业许可下开放权重。最适合:极长上下文任务、整个知识库的 RAG、自托管部署。 -
Llama 4 Maverick — 更大能力的 Llama 4 模型。在许多基准测试上与闭源模型具有竞争力。开放权重。 -
Llama 3.3 70B — 上一代,广泛微调的社区变体。高效,已在生产中验证。
DeepSeek:预算前沿(开源)
-
DeepSeek V3.2 — 每百万 token 0.28 输出。生产 API 使用中性价比最高的模型。MIT 许可下开放权重。在编码和推理方面表现出色。 -
DeepSeek R1 — 推理模型。在数学和编码基准测试上匹配 OpenAI o1,训练成本低 95%。开源。
Mistral:欧洲开源
-
Mistral Large 2 — Apache 2.0。在技术和多语言任务上表现出色。具有数据驻留要求的欧洲企业部署的首选。 -
Mistral 7B / Mistral Nemo — 超轻量级。每百万 token $0.02(Nemo)。可在普通硬件上运行。最适合边缘部署。
阿里巴巴:Qwen 系列
-
Qwen 3.5 — 阿里巴巴最新开源模型。在许多基准测试上与 GPT-4o 级别具有竞争力。在中文任务上尤其强大。Apache 2.0。
智谱 AI:GLM 系列
-
GLM-5 — 在 Artificial Analysis 智能指数上排名最高的开源模型,得分 50。7440 亿总参数,400 亿活跃参数(混合专家架构)。MIT 许可。在 Hugging Face 上可用。
Microsoft:Phi 系列
-
Phi-4 — 小型语言模型。140 亿参数下基准测试表现强劲。最适合:边缘计算、领域特定数据微调、计算受限环境。
Cohere:Command 系列
-
Command R+ — 1040 亿参数。专为检索增强生成优化。多语言表现强劲。最适合:企业搜索、知识库问答、RAG 流水线。
3. 基准测试总表:所有模型并排对比
以下为 2026 年 3 月的基准测试数据。SWE-Bench Verified 测量真实软件工程任务完成度。GPQA Diamond 测试专家级科学知识。ARC-AGI-2 测量无法记忆的新颖问题解决能力。HLE(Humanity’s Last Exam)使用 2,500 道专家策划的多领域问题。
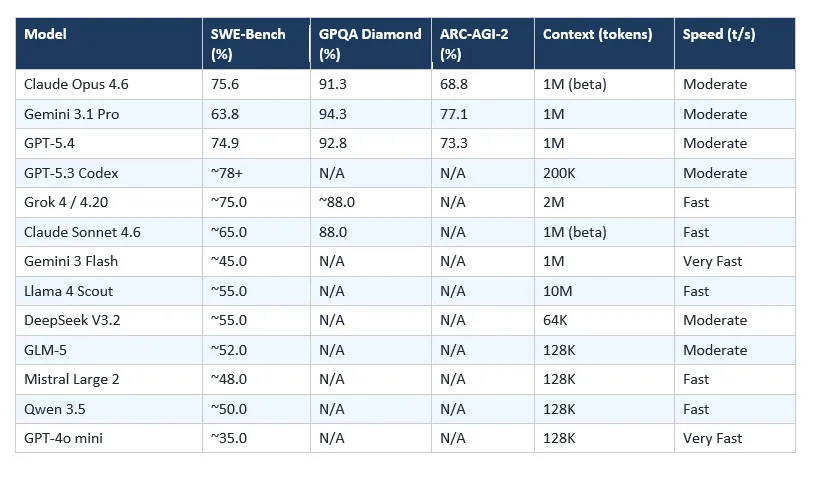
注意:部分模型的某些基准测试数据尚未公开。’~’ 表示社区共识估计值。
在我自己的一次 3,000 行 TypeScript 重构测试中,Opus 4.6 发现了 4 个 Gemini 3.1 Pro 完全遗漏的类型错误。Sonnet 4.6 以五分之一的成本发现了其中 3 个——这就是为什么它现在是我日常生产工作的首选。
4. 按任务评选最佳 AI 模型:2026 年权威排名
这是大多数人真正需要的部分。对于每个任务类别,我确定了赢家和一个强有力的亚军,以及背后的基准测试证据。
编码 — 编码与软件工程最佳
赢家: Claude Opus 4.6(获胜者)+ GPT-5.3 Codex(Agent 终端任务)
Opus 4.6 在 SWE-Bench 上以 75.6% 领先。对于重度终端的 Agent 编码,GPT-5.3 Codex 是专用构建的,可以说是专家赢家。
Claude Opus 4.6 在 SWE-Bench Verified 上获得 75.6%,这是通用模型中公开确认的最高分。它默认驱动 Cursor 和 Windsurf。它有 128K 输出 token,这在你生成整个代码库时很重要。在 Claude Code 测试中,59% 的用户更偏好 Sonnet 4.6 而非 Opus 4.5,因此出于成本考虑,Sonnet 值得在日常任务上测试。
GPT-5.3 Codex 是一种不同的动物。它不在通用基准测试上竞争。它专门为 Agent 终端使用而构建:编辑文件、运行命令、在环境中调试。如果你的工作流是”软件开发即 Agent”而非聊天辅助编码,Codex 是专家之选。
Grok 4 在 SWE-Bench 上也达到了约 75%,其多 Agent 架构中有四个 Agent 并行处理同一问题。当完整 API 开放时,我看好 Grok 4.20。
科学 — 科学与专家推理最佳
赢家: Gemini 3.1 Pro
GPQA Diamond 94.3%,领先所有模型。ARC-AGI-2 达到 77.1%,是其前身的两倍多。
Gemini 3.1 Pro 在 GPQA Diamond 上的 94.3% 是你需要知道的数字。GPQA Diamond 测试跨生物学、化学和物理学的专家级科学知识。之前的记录由 GPT-5.4 的 92.8% 和 Claude Opus 4.6 的 91.3% 保持。Gemini 的领先优势是有意义的,而非微不足道的。
对于 ARC-AGI-2,它测试无法从训练数据中记忆的纯新颖逻辑,Gemini 3.1 Pro 得分 77.1%。这是 Gemini 3 Pro 分数的两倍多。这一跳跃表明模型在处理新颖问题方面有真正的架构改进,而不仅仅是对训练数据的更好回忆。
如果你的工作涉及解读研究论文、回答专家级医学或科学问题,或通过 AI 系统运行结构化实验,Gemini 3.1 Pro 就是答案。
写作 — 写作、内容与长篇工作最佳
赢家: Claude Sonnet 4.6(生产)+ GPT-5.4(研究导向)
Sonnet 4.6 的 GDPval-AA Elo 为 1,633,在专家级真实办公工作中领先所有模型。
Claude Sonnet 4.6 在 GDPval-AA 上领先,这是 OpenAI 创建的基准测试,衡量 AI 在 44 个专业知识工作职业上的表现。Elo 1,633 使其在真实专家级办公工作中超越 Opus 4.6 和 Gemini 3.1 Pro。对于持续的写作任务、内容流水线和编辑工作,这就是我使用的模型。
GPT-5.4 是任何需要广泛事实深度的内容的强力第二选择。其幻觉率比 GPT-5.2 低 33%,这在撰写准确性很重要的主题时很关键。对于研究密集型长篇写作,降低的幻觉特征值得稍高的成本。
对于纯粹需要大量个性和声音的创意写作?Claude 读起来仍然比 GPT 的输出更像人类作家,后者往往更像百科全书。
数学 — 数学与竞赛问题最佳
赢家: Gemini 3.1 Pro + OpenAI o3 Pro(极端难度)
在 MATH-Level 5 和 AIME 级别问题上领先。o3 Pro 用于真正的研究级数学。
Gemini 3.1 Pro 的分级思考级别(低、中、高)让你可以控制每个问题的计算量,这对于某些问题需要 5 秒推理而其他问题需要 5 分钟的数学工作负载来说是一个真正有用的设计。
对于 AIME 和竞赛级数学,推理模型优于通用模型。OpenAI 的 o3 Pro 处于极端端:每百万 token $150 以上,手动评分标准评定的响应,专为真正的研究级数学设计。对于 99.9% 的人来说,这是杀鸡用牛刀。对于解决开放问题的学术研究人员,这是唯一认真的选择。
多模态 — 图像、音频和视频理解最佳
赢家: GPT-4o(语音/音频)+ Gemini 3.1 Pro(视频/文档)
GPT-4o:具有自然韵律的实时语音。Gemini 3.1 Pro:完整视频处理,24 种语言语音。
GPT-4o 的语音模式仍然是所有模型中最自然的。它匹配韵律,识别情感语调,并以接近真正对话节奏的方式回应。如果你正在构建语音界面或任何需要自然口语交互的东西,GPT-4o 是当前的标准。
Gemini 3.1 Pro 处理视频和文档分析方面:完整长度视频处理,24 种语言语音支持,重复内容 75% 的 prompt 缓存折扣。对于需要大规模处理视频文件、长 PDF 或音频转录的应用,Gemini 的多模态技术栈领先。
Agent — AI Agent 和自主任务完成最佳
赢家: Claude Opus 4.6(复杂 Agent)+ Gemini 3.1 Pro(工具编排)
Claude 的 Agent Teams 和自适应思考。Gemini 的原生工具使用和结构化输出可靠性。
Agent AI,即模型使用工具采取一系列行动来完成目标,已成为 2026 年的决定性用例。两个模型因不同原因在此领先。
Claude Opus 4.6 的 Agent Teams 功能允许多个 Claude 实例在同一任务上协作。结合自适应思考和努力控制,它能处理早期模型无法持续的多小时、多步研究和编码任务。
Gemini 3.1 Pro 的原生工具使用与实时 API、Google 搜索和结构化数据输出的集成更紧密。对于需要与开放网络或结构化企业数据交互的 Agent,Gemini 的工具可靠性在生产中有更好的记录。
Grok 4.20 的并行多 Agent 架构——四个 Agent 同时在同一问题上运行——是一种真正不同的方法,尚未完全落地市场。当 API 开放时值得关注。
长上下文 — 处理超长文档最佳
赢家: Llama 4 Scout(1000 万 token)+ Gemini 3.1 Pro(100 万 token,最佳闭源)
Llama 4 Scout 拥有 1000 万 token 的最大上下文窗口。
Llama 4 Scout 的 1000 万 token 上下文窗口是行业中最大的。打个比方,1000 万 token 大约相当于 750 万字,或约 25 部完整长篇小说。如果你需要在单个 prompt 中处理整个法律文档库、巨型代码库或多年研究档案,这是唯一能做到的模型。
在闭源选项中,Gemini 3.1 Pro 的 100 万 token 和 GPT-5.4 的 100 万 token 实力相当,但 Gemini 的 prompt 缓存折扣(重复内容最高 75% 折扣)使其在跨许多请求重用相同上下文的长上下文应用中显著更便宜。
翻译 — 多语言和翻译任务最佳
赢家: Gemini 3.1 Pro + Qwen 3.5(亚洲语言)
Gemini:24 种语言语音,为全球多语言训练。Qwen:中文、日语、韩语最佳。
Gemini 3.1 Pro 的多语言训练覆盖 100 多种语言,24 种语言有原生语音。对于欧洲和全球语言对,它在准确性和语域方面持续优于竞争对手。
对于东亚语言,特别是中文任务,阿里巴巴的 Qwen 3.5 是专家之选。它以美国实验室无法匹敌的规模使用原生中文语言数据进行训练。如果你的用例涉及大量中文、日语或韩语,Qwen 应该在你的评估之列。
客服 — 客户服务自动化最佳
赢家: Kimi K2(Moonshot AI)+ Claude Sonnet 4.6
Kimi K2 在 Tau2-Bench Telecom 上排名第一,这是 Agent 客户支持基准测试。
Moonshot AI 的 Kimi K2 在 Tau2-Bench Telecom 基准测试上获得了第一名,该测试专门测量 Agent 设置中的客户支持自动化。这是大多数西方 AI 报道遗漏的数据点,但对于任何构建客户服务 Agent 的人来说,这是最直接相关的基准测试。
对于大规模英语客户支持,Claude Sonnet 4.6 是经过生产验证的选择。每百万 token 15,非紧急任务可享受 50% 的批处理 API 折扣,对于高批量客户支持,其经济性比 GPT-5.4 更好。
企业隐私 — 自托管和隐私敏感部署最佳
赢家: Llama 4 Maverick + DeepSeek V3.2
开放权重,可自托管,无需将数据发送到外部 API。企业级质量。
任何由于 HIPAA、GDPR、客户协议或安全要求而无法将数据发送到第三方 API 的组织,都需要一个可以在自己基础设施上运行的开源模型。
Llama 4 Maverick 提供了能力和生态系统的最强组合。Meta 的微调工具、量化方案和社区适配器生态系统比任何其他开源模型家族都大。DeepSeek V3.2 是强有力的第二名:MIT 许可,GPT-4o 级性能,如果完全自托管不可行,第三方托管上每百万 token 仅需 $0.14。
5. 按预算评选最佳 AI 模型
预算和功能一样影响模型选择。以下按支出层级的诚实分析。
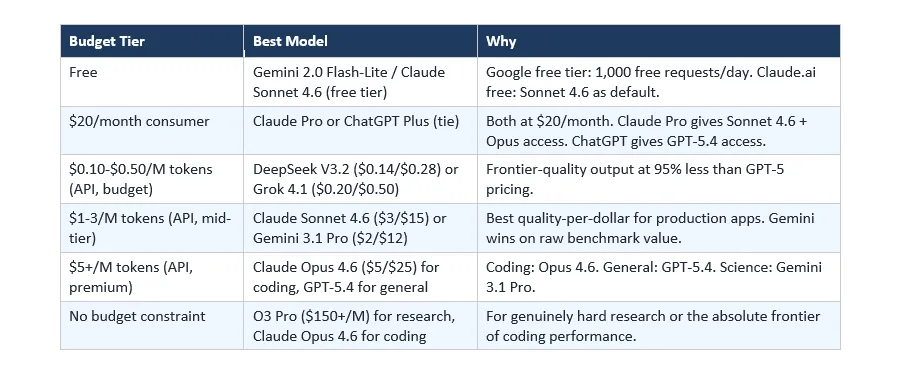
2026 年最佳免费 AI 模型
不花钱你能得到什么? Google Gemini Flash 每天给你 1,000 个免费 API 请求——这是所有前沿模型中最慷慨的免费层级。对于 Web 界面,Claude.ai 免费版让你使用 Claude Sonnet 4.6(在专业写作基准上以 Elo 1,633 位居榜首的模型),每日消息数量有限。ChatGPT 免费版默认仍运行 GPT-4o mini,而不是 GPT-5。
免费日常使用:如果你需要数量,Gemini 免费层是最好的选择。如果你需要写作质量,Claude 免费版是最好的选择。ChatGPT 免费版最熟悉但已不再是免费层中最强的。
6. 开源 vs 闭源:你该选哪个?
开源 vs 闭源的问题曾经有一个明显的答案:闭源模型明显更好。在 2026 年,在中端及以下这已不再成立。
选择开源,如果:
-
你有数据隐私或合规要求,无法将数据发送到外部 API -
你需要在专有数据上微调并希望拥有生成的模型 -
你在成本敏感的环境中构建,规模化时每次请求 $0.01 也太贵 -
你想在自己的硬件上运行推理,没有持续的 API 成本
选择闭源,如果:
-
你需要复杂推理或编码任务上的绝对最佳性能 -
你想要托管基础设施、可靠性 SLA 和支持合同 -
你在快速构建,没有 ML 工程师来处理模型部署 -
你需要多模态能力,特别是音频和视频,这些在闭源模型中仍然更强
诚实的中间地带:从开源模型开始进行开发和成本估算,然后仅当质量差距值得价格时才切换到闭源模型。对于许多生产应用,DeepSeek V3.2 或 Llama 4 Maverick 以二十分之一的成本就”足够好了”。
7. Claude Pro vs ChatGPT Plus vs Gemini Advanced:每月 $20 值得吗?
对于不使用 API、只想要月度订阅的人:
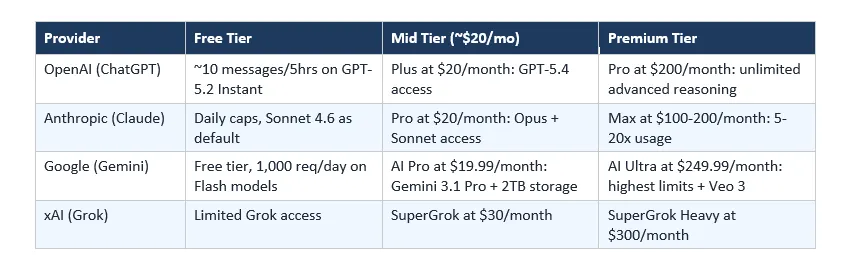
对于大多数个人专业人士,Claude Pro 每月 17/月)提供了上下文窗口、输出质量和 Sonnet 与 Opus 两级访问的最佳组合。对于已经在 Google 生态系统中的任何人,Gemini AI Pro 捆绑的 2TB 存储和 Workspace 集成使其价值更高。
8. API 定价对比表(每百万 Token)
以下为 2026 年 3 月的当前 API 定价。输入和输出价格分别列出。在大多数提供商中,输出 token 的成本是输入 token 的 3-8 倍。
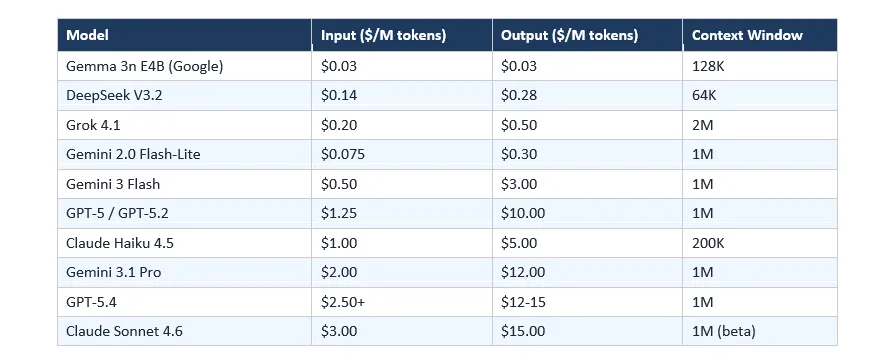
省钱技巧:所有主要提供商都提供 prompt 缓存。重复的系统提示或上下文可以以标准输入价格最高 90% 的折扣缓存。Anthropic 的批处理 API 为非紧急异步任务提供 50% 折扣。Gemini 的上下文缓存为重复的长上下文内容提供最高 75% 的折扣。
9. 如何为你的用例选择合适的 AI 模型
在选择模型之前,先走一遍这个决策树:
第一步:你的主要任务是什么? 使用第 4 节的赢家框。如果你的任务是编码,从 Claude Opus 4.6 开始。如果是科学推理,从 Gemini 3.1 Pro 开始。首先将任务匹配到领域赢家。
第二步:你有数据隐私要求吗? 如果有,你需要开源模型。根据你的计算预算,Llama 4 Maverick 或 DeepSeek V3.2 是首选。
第三步:你的 token 预算是多少? 如果你正在规模化构建生产应用,模型之间的成本差异是巨大的。5/百万(Claude Opus)是 35 倍的差距。每月 1 亿 token,那就是每年 500,000。
第四步:你的生态系统是什么样的? 已经深入 Google Workspace?Gemini 3.1 Pro 原生集成。使用 GitHub Copilot?Claude Sonnet 4.6 驱动它。使用 Cursor 或 Windsurf?Claude Opus 4.6 是默认的。生态系统契合度对减少摩擦很重要。
第五步:在承诺之前先测试。 每个主要提供商都提供免费层级或免费额度。用你的实际用例,而不是通用基准测试,对你的前 2 个候选者进行测试。真实世界的任务表现往往与公布的基准测试分数不同。
欢迎关注我的微信公众号:倔强青铜三,获取更多 AI 自动化和开发技巧分享!