 夜雨聆风
夜雨聆风





企业本地部署 AI 智能完整方案教程
无

一、为什么企业需要本地部署 AI?
🔒 数据安全与隐私合规
数据不出境:敏感数据(财务、医疗、法务、客户信息)无需上传云端
合规要求:满足《数据安全法》、《个人信息保护法》要求
完全可控:模型、数据、API全部自主管理
💰 成本优势
对比项 云端 API 本地部署
长期成本 按调用量付费,累计成本高 一次性硬件投入,长期摊薄
规模化成本 线性增长 边际成本趋近于零
隐藏成本 数据传输、存储溢价 硬件+运维
⚡ 性能与稳定性
低延迟:内网访问,无网络抖动
离线可用:断网也能正常使用 AI 能力
定制优化:针对业务场景微调模型

二、技术架构总览
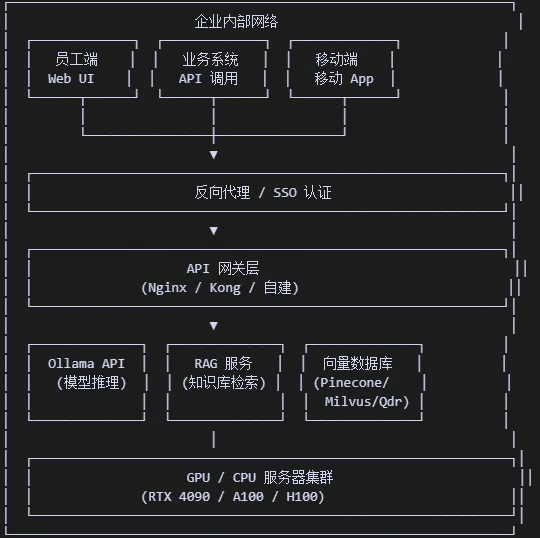

三、硬件配置方案
入门级(适合中小企业,10-50人)
组件 推荐配置 预算参考
CPU Intel i7/i9 或 AMD Ryzen 9 ¥2000-4000
内存 64GB DDR5 ¥1500-2500
显卡 NVIDIA RTX 4090 24GB ¥15000-18000
存储 2TB NVMe SSD ¥800-1500
总计 约 ¥20000-25000
进阶级(适合中大型企业)
组件 推荐配置 预算参考
CPU AMD EPYC 7643 / Intel Xeon Gold ¥15000-30000
内存 256GB – 512GB ECC DDR5 ¥8000-20000
显卡 NVIDIA A100 40GB 或 H100 80GB ¥80000-200000
存储 企业级 NVMe + HDD 冷存储 ¥5000-15000
总计 约 ¥100000-250000
运行模型参考
模型 最低显存 推荐显存 适用场景
Qwen2.5 7B 6GB 8GB 日常对话、简单问答
Qwen2.5 14B 12GB 16GB 文档分析、代码生成
Qwen2.5 72B 48GB 80GB 复杂推理、专业领域
Llama 3.1 70B 48GB 80GB 多语言、专业知识
DeepSeek-R1 70B 48GB 80GB 数学推理、代码

四、软件部署完整步骤
阶段一:基础环境安装
1.1 安装 Ollama(核心推理引擎)
Windows 系统:
方法1:官网下载安装包
访问 https://ollama.com/download 下载 Windows 版安装包
方法2:命令行安装(如已安装 winget)
winget install Ollama.Ollama
Linux 系统:
官方脚本一键安装
curl -fsSL https://ollama.com/install.sh | sh
或手动安装
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama.tgz
sudo tar -C /usr/local -xzf ollama.tgz
macOS 系统:
Homebrew 安装
brew install ollama
或官网下载安装包
1.2 安装 Docker(推荐用于管理服务)
Windows:
安装 Docker Desktop
下载地址:https://www.docker.com/products/docker-desktop
启用 WSL2 后端(Windows)
wsl –update
Linux:
Ubuntu/Debian
curl -fsSL https://get.docker.com | sh
CentOS/RHEL
yum install -y docker-ce docker-ce-cli containerd.io
阶段二:下载和运行模型
2.1 常用模型命令
运行通义千问(推荐中文场景)
ollama run qwen2.5
运行 Llama 3.1(推荐英文/多语言场景)
ollama run llama3.1
运行 DeepSeek(推荐推理场景)
ollama run deepseek-r1
运行Phi-3(微软小而强模型)
ollama run phi3
查看已下载模型
ollama list
删除模型
ollama rm qwen2.5
2.2 模型参数配置
创建自定义模型文件 Modelfile:
Modelfile 示例
FROM qwen2.5
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER top_k 20
PARAMETER num_ctx 4096
TEMPLATE “””
{{ if .System }}<|system|>
{{ .System }}
{{ end }}
<|user|>
{{ .Prompt }}
<|assistant|>
“””
SYSTEM “””
你是一个专业的企业助手,请用专业、简洁的语言回答问题。
“””
应用配置:
创建自定义模型
ollama create my-assistant -f Modelfile
运行自定义模型
ollama run my-assistant
阶段三:Web UI 界面部署
3.1 Open WebUI(推荐,功能最全)
Docker 部署
docker run -d \
-p 3000:8080 \
–add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
–name open-webui \
–restart always \
ghcr.io/open-webui/open-webui:main
访问地址
http://localhost:3000
首次需要注册管理员账号
3.2 切换模型
在 WebUI 界面中:
点击左下角设置图标 ⚙️
选择 Models 标签
从下拉菜单选择要使用的模型
保存设置
阶段四:本地知识库(RAG)部署
4.1 AnythingLLM(最简单方案)
Docker 部署
docker run -d \
–name anythingllm \
-p 3001:3000 \
-v anythingllm:/app/storage \
-e STORAGE_DIR=”/app/storage” \
mintplexlabs/anythingllm:latest
功能特点:
支持 PDF、Word、Excel、TXT、Markdown 等文档
支持网站抓取
支持 YouTube 视频转录
简洁的向量数据库管理
4.2 手动搭建 RAG 系统
向量数据库选型:
数据库 特点 适用规模
Chroma 轻量、易用 小规模(<100万向量)
Qdrant 高性能、云原生 中等规模
Milvus 分布式、高可用 大规模企业级
Pinecone 托管服务 不想自建
示例:使用 Qdrant + LangChain
requirements.txt
langchain==0.1.0
langchain-community==0.0.10
qdrant-client==1.7.0
openai==1.10.0
pypdf==3.17.0
rag_pipeline.py
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Qdrant
from qdrant_client import QdrantClient
1. 加载文档
loader = PyPDFLoader(“document.pdf”)
documents = loader.load()
2. 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = text_splitter.split_documents(documents)
3. 连接向量数据库
qdrant = Qdrant.from_documents(
chunks,
OpenAIEmbeddings(),
url=”http://localhost:6333″,
collection_name=”enterprise_docs”
)
4. 查询
query = “公司年假政策是什么?”
results = qdrant.similarity_search(query, k=3)
阶段五:API 服务配置
5.1 开启 Ollama API
设置 API 主机(允许外部访问)
export OLLAMA_HOST=0.0.0.0:11434
设置允许的跨域源
export OLLAMA_ORIGINS=*
重启服务
ollama serve
5.2 API 调用示例
对话接口:
curl http://localhost:11434/api/chat -d ‘{
“model”: “qwen2.5”,
“messages”: [
{“role”: “user”, “content”: “你好,请介绍一下你们公司”}
],
“stream”: false
}’
代码补全:
curl http://localhost:11434/api/generate -d ‘{
“model”: “qwen2.5”,
“prompt”: “写一个Python快速排序函数”,
“stream”: false
}’
嵌入向量:
curl http://localhost:11434/api/embeddings -d ‘{
“model”: “nomic-embed-text”,
“prompt”: “这是要向量化的文本”
}’
阶段六:企业集成方案
6.1 对接企业微信/钉钉
企业微信机器人方案:
wechat_bot.py
import requests
from flask import Flask, request
app = Flask(__name__)
OLLAMA_API = “http://localhost:11434/api/chat”
@app.route(‘/wechat/callback’, methods=[‘POST’])
def wechat_callback():
data = request.json
message = data.get(‘text’, ”)
调用 Ollama
response = requests.post(OLLAMA_API, json={
“model”: “qwen2.5”,
“messages”: [{“role”: “user”, “content”: message}]
})
result = response.json()
reply = result[‘message’][‘content’]
return {“code”: 0, “msg”: “ok”, “data”: {“content”: reply}}
if __name__ == ‘__main__’:
app.run(host=’0.0.0.0′, port=5000)
6.2 对接飞书
// feishu-bot.js
const express = require(‘express’);
const axios = require(‘axios’);
const app = express();
app.use(express.json());
const OLLAMA_API = ‘http://localhost:11434/api/chat’;
app.post(‘/feishu/webhook’, async (req, res) => {
const { message } = req.body;
const response = await axios.post(OLLAMA_API, {
model: ‘qwen2.5’,
messages: [{ role: ‘user’, content: message }]
});
res.send({
msg_type: ‘text’,
content: { text: response.data.message.content }
});
});
app.listen(3000);
6.3 对接现有业务系统
business_api.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import requests
app = FastAPI(title=”企业AI助手API”)
class ChatRequest(BaseModel):
query: str
user_id: str = None
context: dict = None
@app.post(“/api/chat”)
async def chat(request: ChatRequest):
添加企业上下文
system_prompt = “””你是一个专业的企业客服助手。
请根据以下信息回答用户问题:
“””
response = requests.post(
“http://localhost:11434/api/chat”,
json={
“model”: “qwen2.5”,
“messages”: [
{“role”: “system”, “content”: system_prompt},
{“role”: “user”, “content”: request.query}
]
}
)
if response.status_code != 200:
raise HTTPException(status_code=500, detail=”AI服务不可用”)
return {“answer”: response.json()[‘message’][‘content’]}
启动:uvicorn business_api:app –host 0.0.0.0 –port 8000

、高级功能配置
5.1 模型微调(Fine-tuning)
使用 Ollama 微调工具(需要准备训练数据)
ollama create fine-tuned-model -f Modelfile
训练数据格式(JSONL)
{“text”: “问题:… 答案:…”}
{“text”: “问题:… 答案:…”}
5.2 多模型组合
根据任务类型选择不同模型
def route_model(task_type, query):
if task_type == “code”:
model = “codellama”
elif task_type == “math”:
model = “deepseek-r1”
elif task_type == “creative”:
model = “qwen2.5”
else:
model = “llama3.1”
return call_ollama(model, query)
5.3 负载均衡
nginx.conf 配置示例
upstream ollama_backend {
server 192.168.1.10:11434;
server 192.168.1.11:11434;
server 192.168.1.12:11434;
}
server {
listen 80;
location /api/ {
proxy_pass http://ollama_backend;
}
}

六、安全与运维
6.1 安全配置
1. 限制 API 访问来源
export OLLAMA_ORIGINS=https://company.com,https://intranet.company.com
2. 启用认证(Nginx Basic Auth)
sudo htpasswd -c /etc/nginx/.htpasswd admin
3. 配置 HTTPS
使用 Let’s Encrypt 免费证书
sudo certbot –nginx -d ai.company.com
6.2 监控与日志
查看 Ollama 日志
journalctl -u ollama -f
Docker 日志
docker logs -f open-webui
资源监控
nvidia-smi GPU 使用情况
htop CPU/内存使用
6.3 备份策略
备份模型
cp -r ~/.ollama/models/ /backup/ollama-models/
备份知识库
docker exec qdrant ./qdrant_backup /backup/vectors
定期备份脚本
0 2 * * * /opt/scripts/backup-ai.sh 每天凌晨2点

七、常见问题排查
问题 解决方案
模型下载慢 使用镜像源或代理;选择更小的模型
GPU 不被识别 安装 NVIDIA 驱动 + CUDA;检查 nvidia-smi
显存不足 (OOM) 减少模型参数;调小 num_ctx;关闭其他占用
API 超时 增加超时时间;使用流式响应 stream: true
Docker 端口冲突 修改映射端口 -p 3001:3000
中文回答乱码 确认终端编码为 UTF-8;模型选择支持中文的

END


关注我们