 夜雨聆风
夜雨聆风





三个AI工具,三套规矩,听谁的
我当时正在用 Claude Code 写项目,顺手就回了句,差不多吧。
结果那天晚上躺在床上,越想越不对劲。
因为就在上周,我刚把一套规则从 Cursor 迁移到 Claude Code 上,又从 Claude Code 迁移到 Copilot 上。三份配置文件,内容几乎一模一样,但格式不一样,放的位置不一样,甚至连文件名都不一样。
这哪是差不多啊,这分明就是三套完全不同的系统。
我好奇心一下就上来了。
上期我们聊了怎么评估AI的输出质量,搭了一套审核清单。但审核的前提是你得有规则,你得告诉AI「我的代码应该长什么样」「我的项目有什么特殊要求」。那规则本身呢?不同工具的规则系统,差别到底有多大?
带着这个问题,我做了一件可能有点轴的事。
我准备了一套标准的规则,大概就是那种「项目用 TypeScript,代码风格要干净,注释用中文,不要用 any 类型」之类的基础规范。然后我把这套规则,分别在 Cursor、Claude Code 和 Copilot 三个工具上配置了一遍。
不是随便配一下,是认真配,按照每个工具官方推荐的方式,放到它该放的位置,用它该用的格式。每个工具我都花了至少半个小时去研究它的文档,搞清楚它的规则系统到底是怎么工作的,有哪些坑需要避开。
我舍友看我忙活半天,问我你这是在干嘛。我说我在做实验。他说啥实验。我说我在测试三个工具的规则系统到底有什么区别。他翻了个白眼,说你有这闲工夫不如多写两行代码。
愚钝如我,确实有点轴。但我觉得这件事值得搞清楚。
然后我发现了一些让我挺意外的事。
先说 Cursor。
Cursor 的规则系统,可能是这三个里面知名度最高的。如果你在 GitHub 上搜 .cursorrules,能搜到一大堆现成的模板,各种语言、各种框架,社区生态非常成熟。它最早广泛采用这种用一个配置文件告诉AI怎么干活的模式,很多后来的工具多多少少都受了它的影响。
配置方式有两种。旧版是直接在项目根目录放一个 .cursorrules 文件,纯文本格式,你想写什么就写什么。新版更灵活一些,支持在 .cursor/rules/ 目录下放多个 .mdc 文件,可以按功能分类管理。
我用的旧版,因为简单直接。创建了一个 .cursorrules 文件,把规则贴进去,保存,搞定。
Cursor 的读取时机是每次 AI 交互开始时自动读取,所以你改完规则之后,下一次跟 Cursor 聊天的时候它就会用新的规则。这个体验还是挺顺滑的。
但问题也很明显。
这套规则只在 Cursor 里面生效。你把这个 .cursorrules 文件放到 Claude Code 的项目里,Claude Code 根本不读它。你放到 Copilot 的项目里,Copilot 也不认识它。
它就是Cursor自己的方言。
不过话说回来,Cursor 的社区生态确实做得好。你想要 React 项目的规则模板,搜一下就有。想要 Vue 的,也有。想要 Python 数据分析的,还有。甚至有人专门整理了最佳 .cursorrules 合集,star 数上千。对于只用 Cursor 的朋友来说,这套系统够用了。

但如果你跟我一样,三个工具都在用,那问题就来了。
因为你在 Cursor 里精心打磨的那套规则,换个工具就全废了。
接着说 Claude Code。
Claude Code 的规则系统叫 CLAUDE.md,放在项目根目录就行,Markdown 格式。
这个设计我觉得挺聪明的。Markdown 大家都会写,不像 .cursorrules 那样需要记一套特殊的格式。而且 Claude Code 还支持全局配置,你可以在 ~/.claude/CLAUDE.md 放一份全局规则,所有项目都会自动加载。项目根目录再放一份项目级的规则,两层叠加。
我当时配的时候,先在全局配置里写了通用的编码规范,然后在项目目录的 CLAUDE.md 里写了项目特有的要求。这个两层结构用起来确实舒服,不用每个项目都重复写一遍通用规则。
Anthropic 自家的产品,跟 Claude 模型的配合确实深。你写的规则,Claude 理解得就是比其他模型更到位,这个体感上的差异是真实存在的。
但同样的老问题。
CLAUDE.md 只在 Claude Code 里面生效。你给 Cursor 写的 .cursorrules,Claude Code 不读。你给 Claude Code 写的 CLAUDE.md,Cursor 也不认识。
封闭的。
而且 Claude Code 的核心配置是单文件 CLAUDE.md,虽然也支持 .claude/rules/ 多文件扩展,但主流用法还是单文件。如果你的规则很多,一个 CLAUDE.md 会变得很长,管理起来不太方便。
我当时配完之后,体感是,规则系统本身没什么问题,但只在自己家能用这个限制,真的挺烦的。
你想想看,你花了一下午时间把规则调得恰到好处,Claude Code 的输出质量明显提升了,你正高兴呢,结果打开 Cursor 发现一切归零。这种体验,怎么说呢,就像你花了一个月把新房装修得漂漂亮亮,然后房东告诉你合同到期了,你得搬走。
不是哥们。
然后是 Copilot。
Copilot 的规则系统,说实话,配完之后我有点被惊艳到。
不是那种「哇好厉害」的惊艳,而是一种「卧槽还能这样」的惊艳。
它的配置文件叫 .github/copilot-instructions.md,放在项目根目录的 .github 目录下。Markdown 格式,这个跟 Claude Code 一样,上手没门槛。
但 Copilot 做了一件很骚的事。
我配的时候真的愣了一下,心想这玩意还能这么玩。
它支持 YAML frontmatter。
啥意思呢,就是你可以在文件开头加一段元数据,指定这条规则适用于哪些文件。比如你可以写一条规则专门针对 .tsx 文件,再写一条专门针对 .css 文件。Copilot 在你编辑不同类型的文件时,会自动加载对应的规则。
这个叫上下文感知。
你写 React 组件的时候,它用 React 的规则。你写样式的时候,它用样式的规则。你写测试的时候,它用测试的规则。不用你手动切换,它自己就知道该用哪套。
而且规则是可以叠加的。你可以有一条仓库级别的通用规则,再叠加项目级别的特定规则,再叠加文件级别的精细规则。三层叠加,灵活度拉满。
还有一点,Copilot 支持组织级配置。如果你是一个团队,可以在组织层面设置统一的编码规范,所有仓库自动继承。个人在仓库里还可以覆盖。这个对团队协作来说,真的挺实用的。
我配完之后的感受是,就规则系统的灵活度而言,Copilot 确实是三个里面最强的。
但。
它也是封闭的。
copilot-instructions.md 只在 Copilot 里面生效。你写的那些上下文感知规则、那些精心设计的 applyTo 匹配,拿到 Cursor 里面就是一堆 Copilot 看得懂但 Cursor 完全不认识的文字。

因为我发现了一个让我有点尴尬的事实。
三个工具,三套规则系统,设计理念完全不同,但有一个共同点。
它们都是各自为政的。
你给 Cursor 写的规则,Claude Code 不读。你给 Claude Code 写的规则,Copilot 不读。你给 Copilot 写的规则,Cursor 也不读。
如果你跟我一样,日常在三个工具之间切换,那你需要维护三份几乎一样的配置文件。格式不同,文件名不同,放的位置不同,但内容差不多。
每次改一条规则,你要改三个地方。
这种感觉,怎么说呢,就像你手机有三种充电接口,Type-C、Lightning、Micro-USB,换一个手机就要换一根线。
你说烦不烦。
说到这个,我顺便聊一个我觉得挺有意思的事。
你可能听说过 MCP,Model Context Protocol,Anthropic 在 2024 年底推出的一个开放协议。这个东西,坦率的讲,就是给 LLM 设计的一个统一接口。
我之前看过《系统之美》这本书,里面有一个概念叫系统边界。一个系统的能力,很大程度上取决于它的边界在哪里,以及它能不能跟边界之外的东西连接。MCP 做的事情,就是扩展 LLM 的系统边界,让它能用一个标准化的方式去连接各种外部工具和数据源。
MCP 的架构分三层,Host 是宿主(比如 Claude Code),Client 是客户端(负责跟具体的工具对接),Server 是服务器(提供具体的功能)。这三层解耦之后,任何 LLM 工具只要实现了 MCP 协议,就能接入任何 MCP 兼容的工具服务器。
听起来很抽象对吧。
但我换个说法你就懂了。
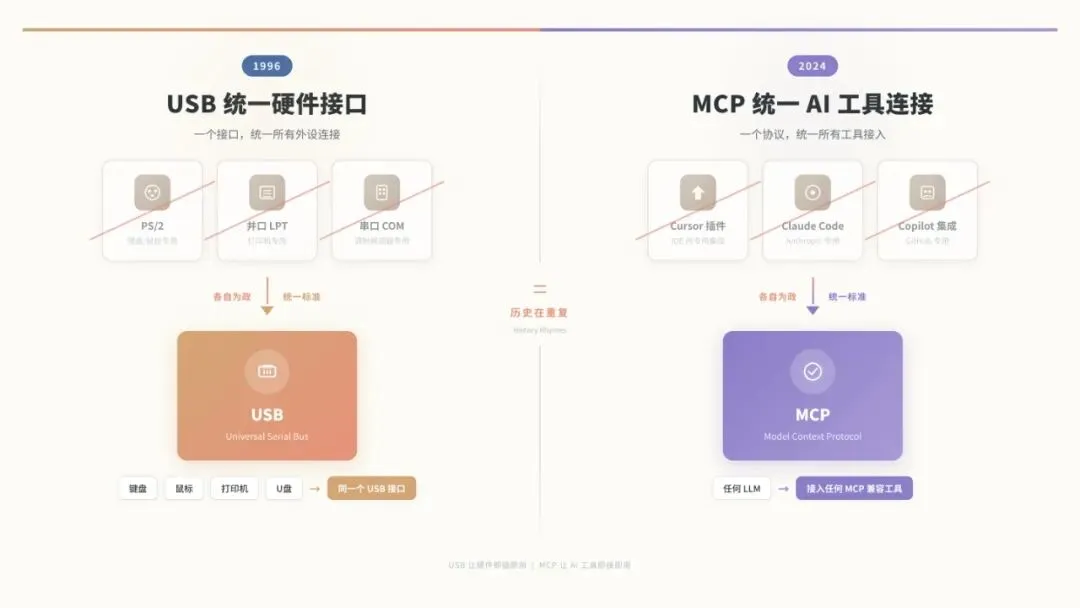
你记不记得,1996 年 USB 1.0 发布之前,电脑上的外设接口是什么样子的?
键盘用 PS/2 接口。打印机用并口。鼠标用串口。游戏手柄又有自己的接口。你换一个外设,可能就要换一个接口,甚至要重启电脑。每个外设厂商都有自己的标准,互相不兼容。
然后 USB 出来了。
一个接口,统一所有外设。键盘、鼠标、打印机、U盘、手柄,全部用同一个接口。即插即用,不用重启。
USB 不是在做一个更好的键盘接口或者更好的鼠标接口。USB 是在做一件更根本的事,它在统一连接这件事本身。
MCP 在 LLM 世界里做的事情,跟 USB 在硬件世界里做的事情,是一模一样的。
在 MCP 之前,每个 AI 工具调用外部工具的方式都不一样,Cursor 有自己的插件体系,Claude Code 有自己的 MCP 实现,Copilot 有自己的 GitHub 集成。换一个工具,你之前配好的外部工具连接就全废了。MCP 试图建立一套统一的协议,让工具和数据源可以在不同的 LLM 之间无缝流转。
其实这种从各自为政到统一标准的事情,在软件行业发生过很多次。编辑器的配置也曾经是各自为政,每个编辑器都有自己的缩进设置、编码格式、换行符风格,后来出了 .editorconfig,一个文件统一所有编辑器的配置。Git 的 .gitignore 也经历了类似的过程,从各家 VCS 各有各的忽略规则,到现在 .gitignore 成了事实上的标准。
历史在重复。
我最近发现了一个叫 Soul Spec 的东西。
说真的,刚看到这个名字的时候我以为是什么玄学项目,点进去一看才发现是个正经的开放标准。
Soul Spec 是一个第三方的开放标准,它的配置文件叫 SOUL.md 或者 .soul/ 目录(多文件结构),也是 Markdown 格式。但跟前面三个工具的规则系统不一样,Soul Spec 设计的目标就是跨工具通用的。
你写一份 SOUL.md,Cursor 能读,Claude Code 能读,Windsurf 也能读。一份规则,多个工具共享。
而且它还做了一些挺有意思的事情。比如有一个社区注册表,81 多个预置配置,你直接一行命令 npx clawsouls install 就能装上别人写好的规则模板。还有一个叫 SoulScan 的安全扫描工具,可以检测你的规则文件里有没有泄露的密钥或者注入攻击的风险。甚至支持多 Agent 协作,通过 AGENTS.md 文件来管理多个 AI Agent 的分工。
听起来挺美好的对吧。
但我得坦诚地说,Soul Spec 目前还处于早期阶段。它是一个第三方标准,不是任何一家官方的。 adoption 还在增长中,社区在壮大,但跟 Cursor 那种 GitHub 上满天飞的 .cursorrules 模板比起来,规模还差得远。
而且三大工具官方并没有宣布支持 Soul Spec。它之所以能在 Cursor 和 Claude Code 里用,是因为这些工具本身就会读取项目目录下的 Markdown 文件作为上下文,Soul Spec 只是恰好利用了这个机制。这不是官方支持,这是借道。
就像你拿着一张超市会员卡去便利店买东西,便利店刚好也认这张卡,但那不是因为它支持这个会员体系,只是因为卡上的条形码恰好能被扫出来。哪天便利店升级了系统扫不出来了,你的卡就废了。
所以现在的局面是这样的。
三大工具各自为政,规则系统互不通用。MCP 在试图统一工具连接层。Soul Spec 在试图统一规则配置层。但都还在早期。
回到我最初的好奇心。
三个工具的规则系统,哪个最强?
如果单看功能丰富度和灵活性,Copilot 的上下文感知确实做得最好。如果看跟模型的配合深度,Claude Code 的体验最丝滑。如果看社区生态和上手门槛,Cursor 的 .cursorrules 模板最多最好找。
但配完三个之后,我的结论是,规则系统的强弱,真的不在于功能多少。
而在于一个更根本的东西。
谁在控制规则。
Cursor 让你写规则,但规则只在 Cursor 生态内生效。Claude Code 支持全局加项目两层,但也是封闭的。Copilot 的上下文感知最灵活,但也是封闭的。它们都在说来,在我这里写规则,我帮你执行,但没有一个在说你写的规则,到处都能用。
这就像三家快递公司,每家都有自己的包裹格式。A 家用红色包装袋,B 家用蓝色包装袋,C 家用绿色包装袋。每家都做得很好,服务也很好,但你的包裹只能在自家的体系里流转。你想从 A 家寄到 B 家的网点?对不起,请重新打包。
你写的规则,被困在了某个工具的生态里。
这才是我觉得最尴尬的地方。
不是说这些工具的规则系统做得不好,它们各自都做得挺好的。但各自都好和整体好用是两回事。就像 USB 出现之前的电脑外设生态,每个接口单独看都没问题,放在一起就是一场灾难。
我现在自己的做法是,维护一份主规则文档,每次需要给某个工具配规则的时候,从主文档里复制粘贴过去,然后按那个工具的格式稍微调整一下。
笨,但能用。
说实话我也不确定有没有更好的办法。我试过写脚本自动同步三个配置文件,但每个工具的格式差异太大,自动同步经常出问题,改着改着还不如手动复制粘贴靠谱。有时候技术方案反而不如笨办法好用,这事儿我也踩过坑。
我也在关注 Soul Spec 和 MCP 的发展。如果有一天,规则配置能像 MCP 统一工具连接那样被统一,真正实现写一次规则,到处运行,那才是规则系统真正变强的时刻。
不过在那一天到来之前,我们这些在三个工具之间来回切换的人,只能继续当那个带着三种充电线出门的人。
= =
其实想想也挺有意思的。我们一直在聊怎么让 AI 越用越强,怎么沉淀规则、怎么建立体系、怎么让 AI 的输出质量越来越高。但我们可能忽略了一个前提,你沉淀下来的这些东西,能不能跟着你走?
如果规则被困在某个工具里,那你的越用越强也是有天花板的。你换一个工具,一切从头开始。
还记得我们之前聊过的沉淀之路吗?沉淀的前提是可迁移。不可迁移的沉淀,不叫沉淀,叫锁定。
不可迁移的沉淀,不叫沉淀,叫锁定。

所以我现在越来越觉得,工具的规则系统做得好不好,不能只看它本身的功能,还要看它有没有在为可迁移这件事做努力。哪怕只是支持导入导出一个通用格式,都比完全封闭要好得多。
屏幕前的你如果也在用这些工具,不妨想想,你写的那些精心设计的规则,是真正属于你的,还是被锁在某个工具的生态里的?
这个问题,可能比哪个工具的规则系统更强更重要。
好了,这期就聊到这里。下期我们聊一个更刺激的话题,AI 能自己进化吗?不是那种科幻电影里的自我意识觉醒,而是更现实的,AI 能不能通过使用经验的积累,真的变得越来越好用?
想想就觉得兴奋。
以上,如果你也在三个工具之间来回切换过,应该懂那种感受吧。下期见。