 夜雨聆风
夜雨聆风





AI知识管理插件分享|如何把网页一键整理成本地笔记
本文要点
- none !important
一键保存网页与 AI 对话。 - none !important
自动整理标题、链接等信息。 - none !important
用模板沉淀个人知识库。
最近找到了一个好用的网页插件:Obsidian Web Clipper。
现在我们每天都会和 AI 对话,也会浏览大量网页。很多时候,我们会遇到一些很有价值的内容:一段 ChatGPT 的回答、一篇文章里的观点、一个教程里的方法,或者某个突然触发自己思考的句子。 这些内容如果只是停留在网页里,很快就会被忘记。
收藏到浏览器书签里,时间久了基本不会再打开;复制到微信文件传输助手里,最后也很难重新找到;临时粘贴到笔记里,又经常没有标题、来源和结构。
所以我最近开始尝试用 Obsidian Web Clipper,把网页上的关键信息直接保存到自己的 Obsidian 知识库里。
它不是简单地收藏网页,而是把网页内容转化成可以长期管理的本地 Markdown 笔记。
一、Obsidian Web Clipper 是什么?
Obsidian Web Clipper 是 Obsidian 官方推出的浏览器扩展,可以把网页内容、高亮、元数据等保存到 Obsidian vault 中。
它支持 Chrome、Firefox、Safari、Edge 等浏览器,也支持一些基于 Chromium 的浏览器。
简单来说,它可以帮我们完成三件事:
-
第一,把网页正文保存下来; -
第二,把网页标题、作者、发布时间、来源链接等信息自动整理好; -
第三,把这些内容保存成 Obsidian 可以长期管理的 Markdown 笔记。
在 AI 时代,获取信息已经变得越来越容易。但真正重要的能力,可能不是看到更多信息,而是:
能不能筛选出真正有价值的信息,并把它沉淀到自己的知识系统里。
二、基础用法:一键保存网页内容
安装插件后,当打开一个网页,只需要点击浏览器里的 Obsidian 图标,就可以预览要保存的内容,然后点击 Add to Obsidian,网页内容就会进入我们的 Obsidian。
默认情况下,它会尽量提取网页的主体内容,而不是把广告、导航栏、推荐栏这些干扰信息全部保存下来。
它也支持保存选中的文字,或者保存我们已经高亮的内容。
比如,我在和 ChatGPT 对话时,如果只想保存其中一段关键回答,就可以先选中这部分内容,然后点击 Obsidian Web Clipper。这样保存下来的就不是整页内容,而是我真正想留下的那一部分。
举例:我选中和 ChatGPT 的部分对话,直接点击这个插件,保存的内容就是我选中的内容。
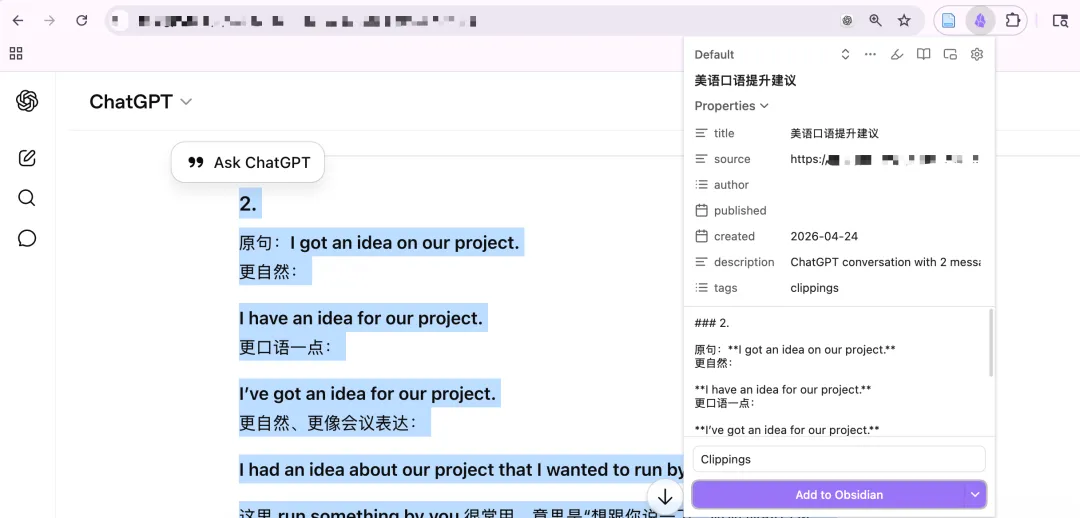
借助这个插件,网页不再只是临时浏览的信息,而可以进入我的长期知识系统。
比如:
-
看到一篇值得精读的文章,可以先保存下来; -
看到一个教程,不想以后链接失效,可以保存下来; -
看到某个观点,想放进自己的研究、写作或项目资料库里,也可以保存下来。
三、设置个人专属模板
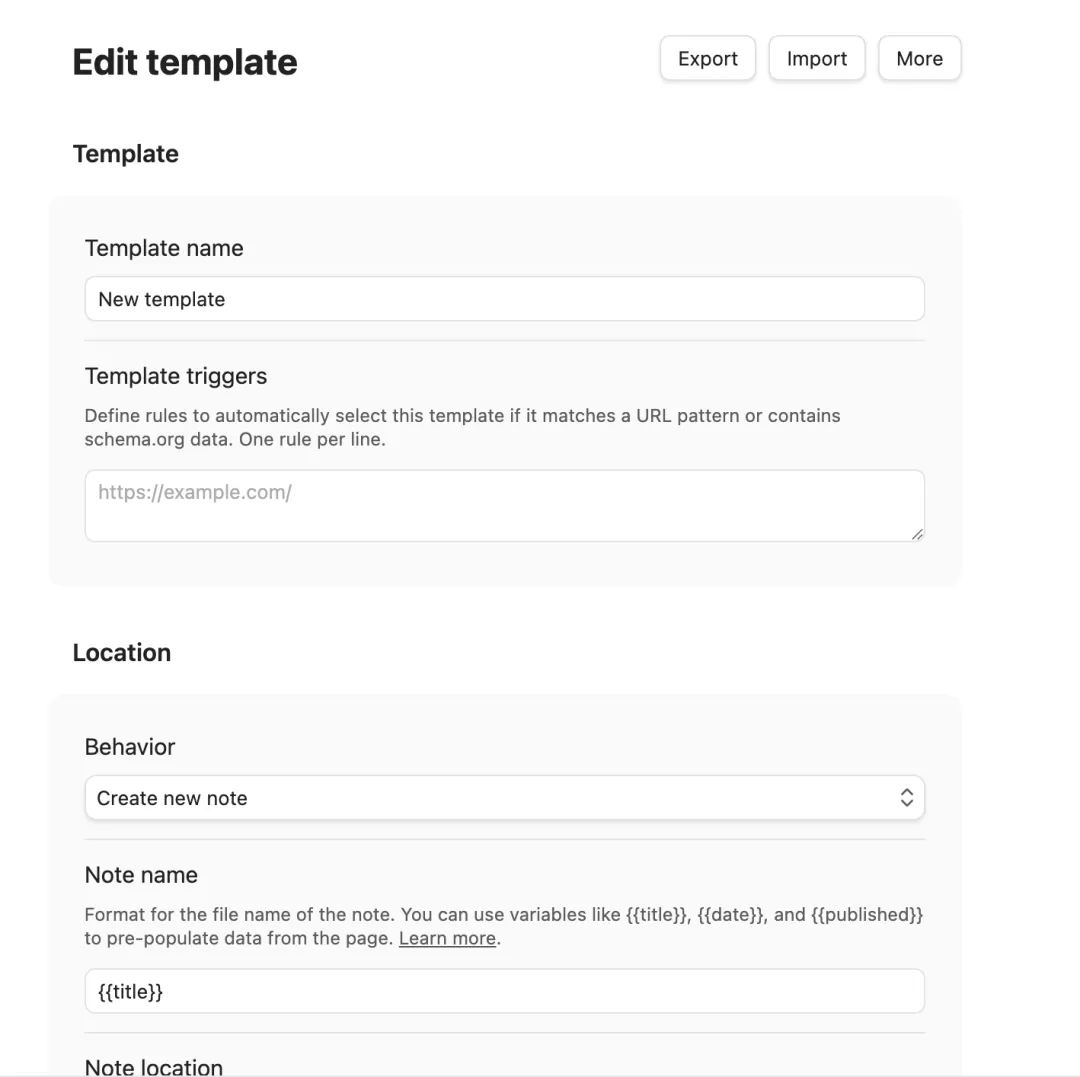
Obsidian Web Clipper 还可以设置模板。比如我可以设置一个文章模板:
--- title: {{title}} author: {{author}} source: {{url}} published: {{published}} tags: [web, clipping] --- # {{title}} ## 原文摘要 {{description}} ## 正文 {{content}} ## 我的想法这样每次保存网页时,标题、作者、链接、发布时间、正文都会自动填进去。 模板的价值在于,它让每一次保存都不是随手复制,而是按照固定结构进入知识库。
我们也可以根据不同场景设置不同模板:
-
保存普通文章,用【阅读笔记模板】; -
保存学术论文,用【文献模板】; -
保存工具教程,用【技术笔记模板】; -
保存灵感材料,用【写作素材模板】。
它还可以根据不同网站,自动匹配不同模板。
-
看到 arXiv 页面,自动用【论文模板】; -
看到博客文章,自动用【文章模板】; -
看到菜谱页面,自动用【菜谱模板】; -
看到电影、书籍、播客页面,自动用【资料卡片模板】。 这就很像给不同信息来源建立了不同入口。不同类型的信息,用不同结构保存,这就是将我们浏览的信息组织起来。
三、设置保存位置
我们还可以设置笔记保存的位置。
先打开 Obsidian,插件会自动保存到我们打开的这个文件夹。
也可以个人设置存放的文件夹,比如可以统一保存到:
Inbox/Web Clippings也可以根据用途保存到不同文件夹:
Projects/ResearchProjects/WritingResources/TutorialsResources/Articles五、Interpreter:用自然语言处理网页内容
Interpreter 功能可以让我们用自然语言处理网页内容,比如让它总结网页、提取关键信息、解释概念、转换格式,甚至翻译内容。官方文档说明,Interpreter 可以用自然语言与网页互动,帮助提取和修改要保存到 Obsidian 的数据。
Interpreter 并不是 Obsidian 自己内置的 AI,而是需要连接你选择的语言模型服务商,比如 OpenAI、Anthropic、Gemini、DeepSeek、OpenRouter,也可以使用本地模型 Ollama。使用外部模型时,网页内容会发送给对应的模型服务商,因此涉及隐私内容时需要谨慎;如果希望更私密,也可以配置本地模型。
比如,我们可以在模板中加入这样的内容:
## 三句话总结{{"请用中文用三句话总结这篇文章"}}## 关键观点{{"请提取这篇文章中最重要的5个观点"}}## 对我的启发{{"这篇文章对一个正在做研究和写作的人有什么启发?"}}这样保存网页时,它不只是把网页原文保存下来,还可以帮助我们生成摘要、提炼观点、整理结构。
这对我来说特别适合三类场景:
第一,保存长文章时,先生成一个快速摘要;第二,保存英文资料时,顺便提取中文要点;第三,保存教程时,自动整理出步骤和关键方法。
六、不要只保存,要写一句自己的想法
每次保存重要内容时,至少写一句自己的想法。
比如:
## 我为什么保存它?这篇文章提醒我:工具的价值不在于功能多,而在于它能不能进入我的真实工作流。这句话提升了我们的知识管理能力,因为知识管理的关键,不是把别人的内容搬进自己的库里,而是让这些内容和自己的问题发生关系。
只有当我们写下具体联结时,信息才开始变成我们自己的知识。
一起用起来吧~