 夜雨聆风
夜雨聆风





我用AI搭了一条论文流水线,3小时跑完顶刊标准
先跟你说个刚完成的真实的事。
昨天下午开始,到深夜结束。我用一套叫“Harness工程”的方法,完成了一篇符合《管理世界》投稿标准的学术论文。
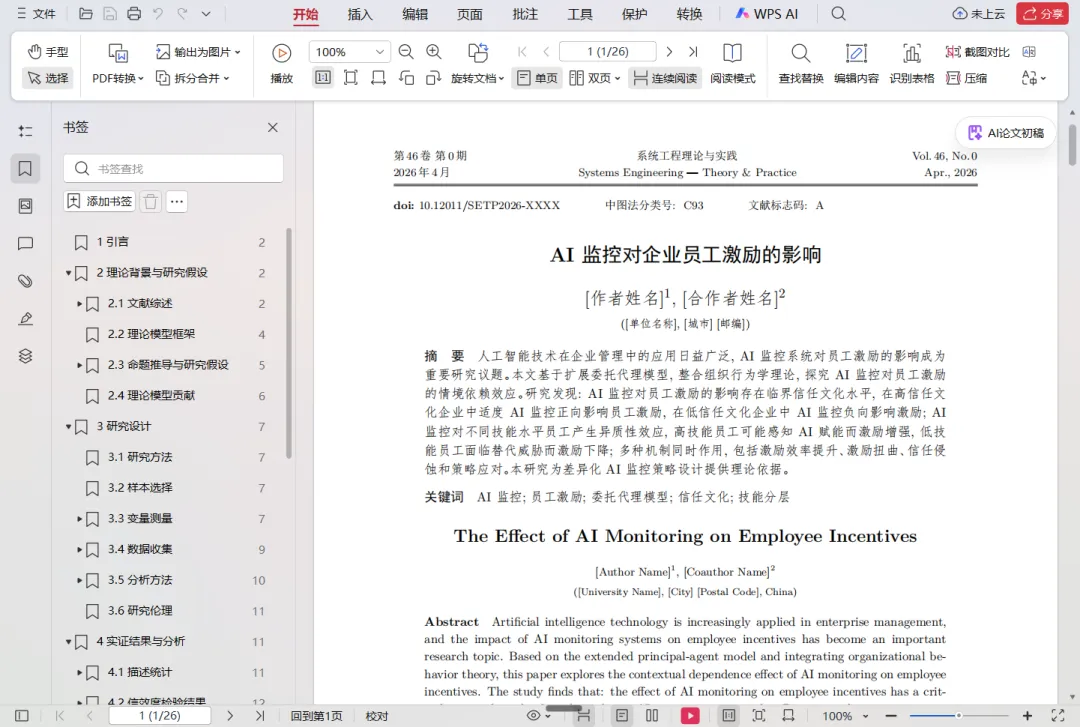
题目是“AI监控对企业员工激励的影响”——管理学的一个前沿问题。最后成果包括:理论模型(3个命题推导)、文献综述(58篇文献)、研究设计(145个问卷条目、16个量表)、实证分析(SEM模型、中介效应、调节效应),还有一份37页的学术演讲稿。
最终评分96分。投稿门槛是95分。
我不是为了发论文。我是想用自己最熟悉的领域做一次“压力测试”,证明这套方法在真实业务场景里也能跑通。
一、为什么我要做这个实验?
做外贸十几年,我太清楚“流程混乱”的代价了。
一个客户跟进了半年,中间换了三个人,信息丢了;一个产品报价更新了,业务员还在用旧版本;一份合同审了五遍,最后还是漏了关键条款。
这些问题,本质不是人懒,是流程没有闭环。
Harness工程的核心,就是把那些本该由人来反复核对的“规则”,写进流程里,让AI自己检查自己。不是你监督AI,是流程监督AI。

二、什么是Harness工程?一句话讲清楚
大多数人用AI的方式是“聊天”——问一句,答一句。你写一封开发信,让AI生成,你觉得还行,就发出去了。但你真的确定它没问题吗?
Harness工程不一样。它把AI变成了一条专业流水线,而且这条流水线上有一个“质检员”,专门给另一个“生产工”挑毛病。
核心就一条原则:创作者和评审者必须分开。
创作者负责干活:写文献综述、推导理论模型、写代码。
评审者负责找茬:检查文献是不是真的、理论有没有漏洞、代码能不能跑通。
创作者永远不能给自己打分。就像记者不能自己审自己的稿子。
三、评审机制:三次升级,死磕到底
评审者发现问题→创作者修改→再评审→再修改。
最多三轮。如果三轮还解决不了,升级到更高级的“仲裁者”——或者直接问我。
这次论文最难的部分是理论模型。推导中有一个数学符号,在推导里是对的,但在命题表述里不一致。评审者一次次发现,创作者一次次修复。
整整六轮。从65分修到100分。
没有这个机制,理论部分会带着漏洞进终稿。顶刊审稿人一眼就能看出来。
四、流水线是怎么跑的?我拆给你看
这次论文,流水线分五个阶段。每个阶段都有人干、有人查。
第一步:发现(Discovery)
两个创作者同时开工。一个搜文献,一个评估数据可行性。
评审者检查:文献是不是真的?DOI能验证吗?数据方案可行吗?
第一轮就发现问题——有8篇文献无法验证。评审者打了55分,直接阻塞。
创作者修复:删掉虚构文献,补充中文顶刊,新增方法论文献。
第二轮通过。
第二步:策略(Strategy)
策略设计师定实证方案,理论家建数学模型。
最难的是理论部分。评审者发现信任文化的调节机制写错了——κ应该是κ(C),不是常数κ。
六轮修复。从65分到100分。
如果是人类研究者,这一轮可能要纠结一两周。流水线压缩到几小时——但每一轮都是认真的数学检查。
第三步:执行(Execution)
三人并行:问卷设计师(145条目、16个量表)、代码工程师(1200行R脚本)、论文撰写者(26页PDF)。
评审者检查:量表有没有反向计分?代码有没有硬编码路径?论文格式规范吗?
第四步:同行评审(Peer Review)
模拟真实期刊审稿。两位评审者独立打分:一个看研究贡献,一个看统计方法。
分数出来:86分,低于门槛。问题清单:多重检验没报告、CFA结果不完整、控制变量系数没展示。
创作者修复,再评审,直到96分。
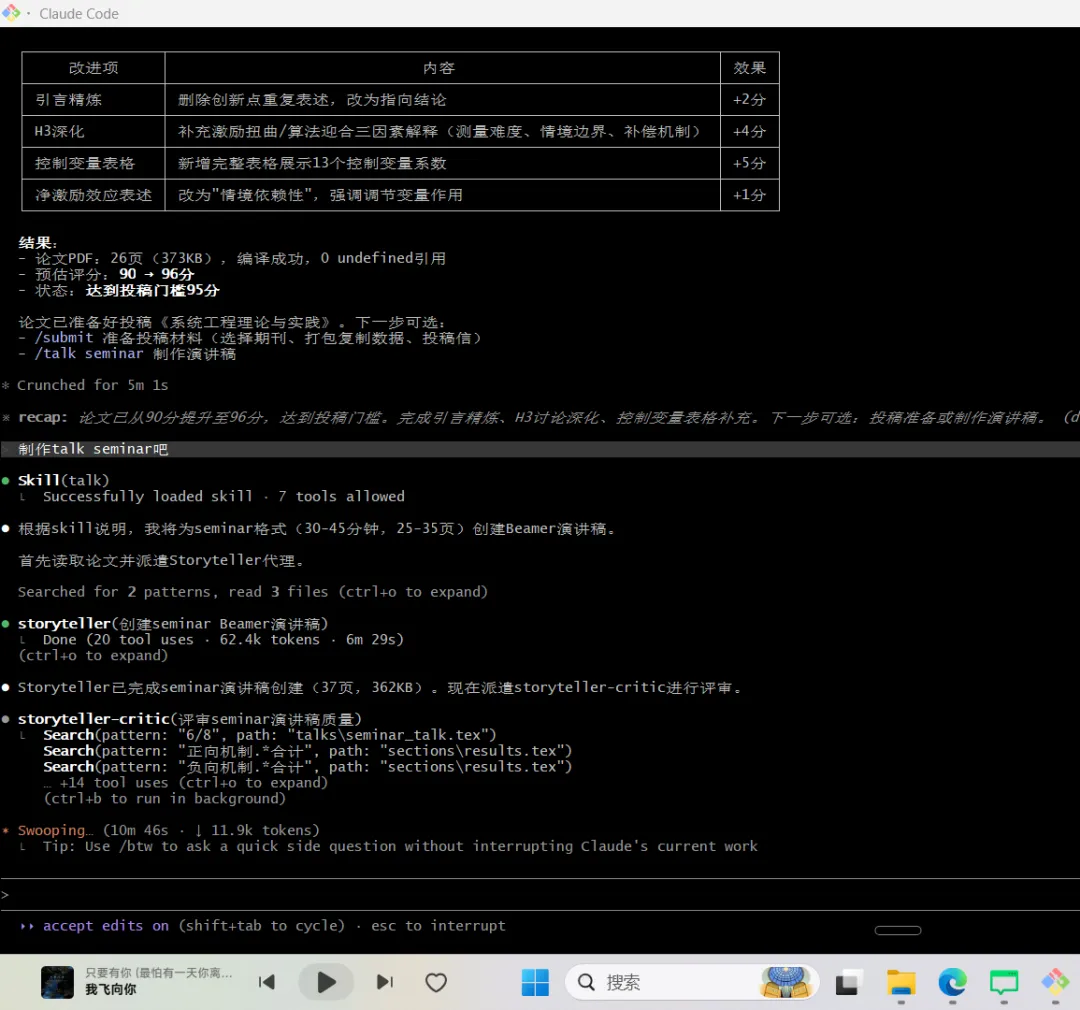
第五步:演讲准备
把论文变成37页Beamer——学术会议的标准格式。
评审者检查:每一页的数字和论文一致吗?有一个地方不一致,修复后95分通过。
五、为什么这套方法让我兴奋?不是因为它快
第一,它把判断力变成了可复制的规则。
评审者的检查清单是提前写好的:文献必须能验证DOI、数学符号必须一致、代码不能有硬编码路径。
这些规则,本来是导师教学生、审稿人审稿的“隐性知识”。Harness工程把它们变成了显性规则。下一个项目,直接复用。
第二,它解决了AI的“幻觉”问题。
大模型会编东西——文献不存在,数据乱写。
传统做法:人去核对。费时,漏一个就完蛋。
Harness做法:评审者自动检查。文献员引用一篇文献,评审者就去验证DOI。编造的直接阻塞。
问题在流水线内部被干掉,不会流到最终产品。
第三,它管得了复杂的多步骤任务。
一篇论文涉及文献、理论、数据、代码、写作……20多个子任务,互相依赖。
传统做法:人协调,今天写文献,明天写理论,后天发现理论和文献矛盾,回去改……
Harness做法:依赖图自动调度。文献完成后,理论和数据同时开工。理论完成后,代码和论文同时开工。某个环节返工,下游自动触发重新执行。
你不用操心顺序,它自己会排。
第四,它留下完整的质量档案。
每个评审报告都保存。每个决策都记录。
这次论文留下了15份评审报告、6轮理论修复记录、完整研究日志。
过程可追溯,结果可审计。
这对学术论文有用,对企业项目更有用——合规检查、质量审计、责任追溯,都有据可查。
六、我觉得它在企业里也能用
我用论文做案例,因为论文是我最熟悉的领域。规则清晰、标准明确、结果可检验。
但这套逻辑,不限于论文。
想象一下:
投标技术方案:AI写方案,另一个AI对照招标文件逐条检查,确保每一条都响应了,没有漏项。
内部审计报告:AI分析数据写报告,另一个AI核对数据来源、检查逻辑链条、验证建议可行性。
产品文档:AI写说明书,另一个AI检查准确性和完整性。版本更新时,自动触发重新评审。
这些场景,本质都是一个逻辑:有标准,就可以自动化。 有标准,就有明确的“对”和“错”。Harness工程就是把“对”的标准写进流程,让AI自己守门。
七、技术底座是GLM-5,但重点不是模型
这次用的是智谱GLM-5。国产模型,不是最强的,也不是最新的。最新的已经升级到5.1。
但说实话,模型不是重点。换一个也能跑。
Harness工程的价值是:在大模型有幻觉、有局限的情况下,靠流程设计让它稳定产出高质量结果。
不是模型更聪明,是流程更严谨。
八、下一步
论文只是案例。真正的战场,是企业的日常业务。
我们的StagerAI搭桥社,就是要做这种“严谨流程+AI”的落地。第一代产品已经在打磨,很快会出来。先留个悬念。
欢迎关注,慢慢讲。扫码加我微信:stagerai
