 夜雨聆风
夜雨聆风





实战案例|当本体遇上 Agent:让 AI 真正“听懂业务”并“按规矩办事”【上】
点击上方蓝字加入我们



01

-
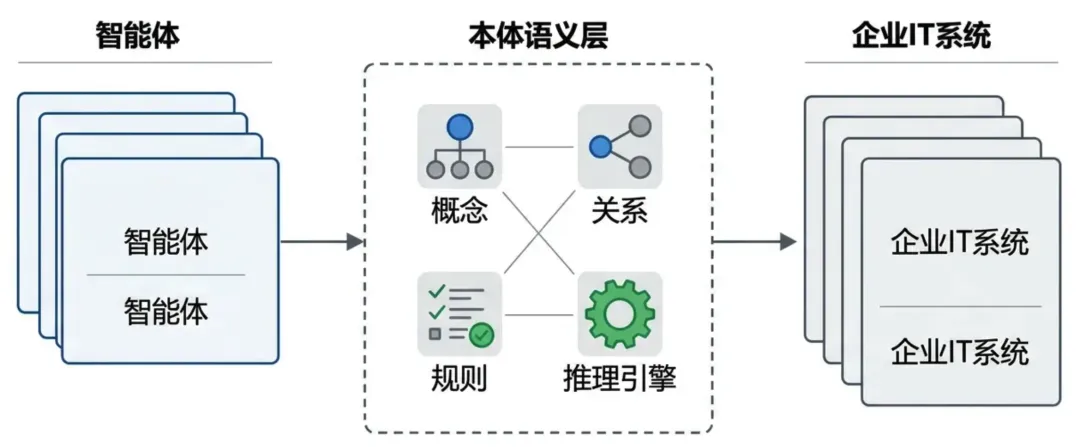
“地图”:承载的是业务概念(客户、订单、库存等)、关系(谁依赖谁、谁属于谁、谁拥有谁)、规则(什么条件可以发货?什么客户是VIP?)、语义映射(客户在哪些系统里有对应)等等。 -
“仓库”:承载的则是海量明细数据、事务更新、分析结果等。

02

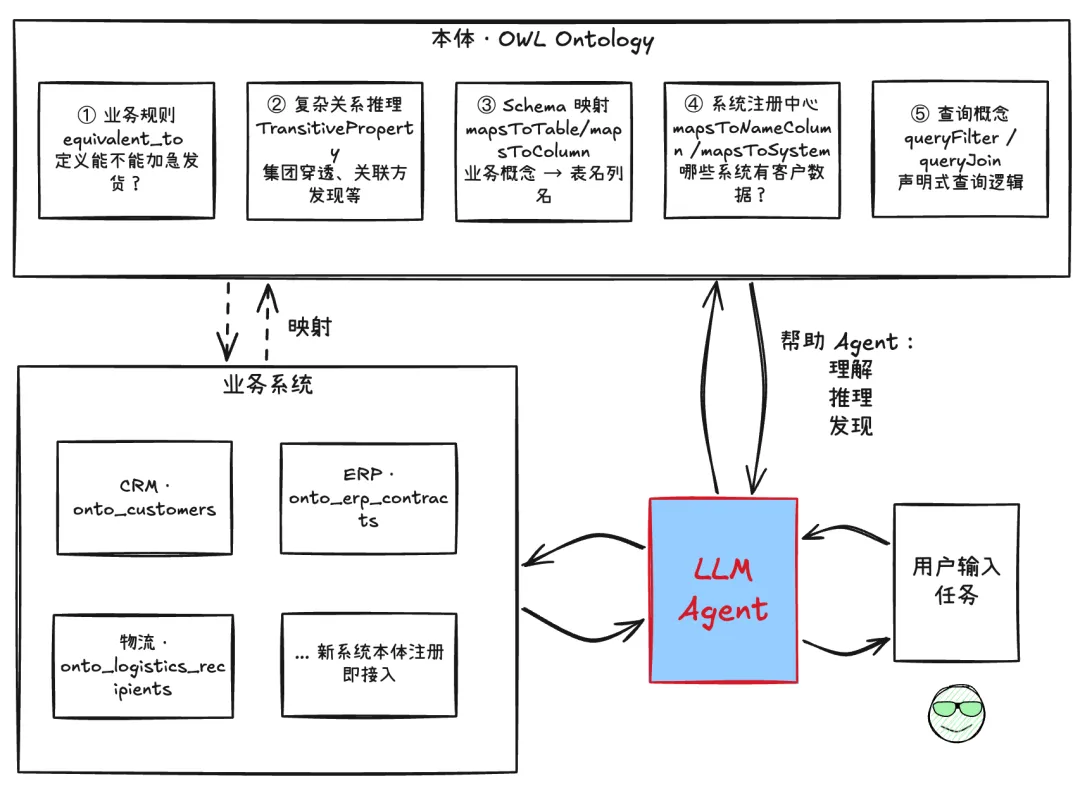
-
规则引擎:比如告诉 Agent 什么算符合“加急发货”的条件?。 -
复杂关系推理:典型的比如多跳关联 — 如集团股权穿透。 -
充当映射层:把业务语言翻译成数据库实现。 -
统一业务视图:比如将客户映射到不同系统中的数据实体。 -
查询语义层:告诉 Agent 复杂查询怎么查,哪些过滤条件和关系。
-
Agent 框架:LangChain
-
后端数据层:PostgreSQL
-
本体存储推理:owl文件 + owlready2 + HermiT 推理机
-
LLM:OpenAI Like
tools = [# 数据库直接查询 query_customer, list_orders, query_order,# 本体规则推理(根据实际需要修改定制) check_shipment_eligibility, check_expedite_eligibility,# 本体规则查询等 get_business_rules, ] system_prompt = ("你是一个本体增强的企业管理助手。你背后接入了基于 OWL 本体的业务推理引擎。""## 工具选择原则\n""- 日常查询(客户、订单列表)→ 直接用数据库查询工具""- 规则判定(能否发货、能否加急等)→ 使用本体推理工具""- 基于语义概念查询(VIP客户、待处理订单等)→ 使用语义概念查询""## 回答原则""- 推理结果要说明判定依据""- 用简洁清晰的中文回答" ) llm = ChatOpenAI(model="gpt-5-mini", temperature=0)return create_agent(llm, tools, system_prompt=system_prompt)|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
03
-
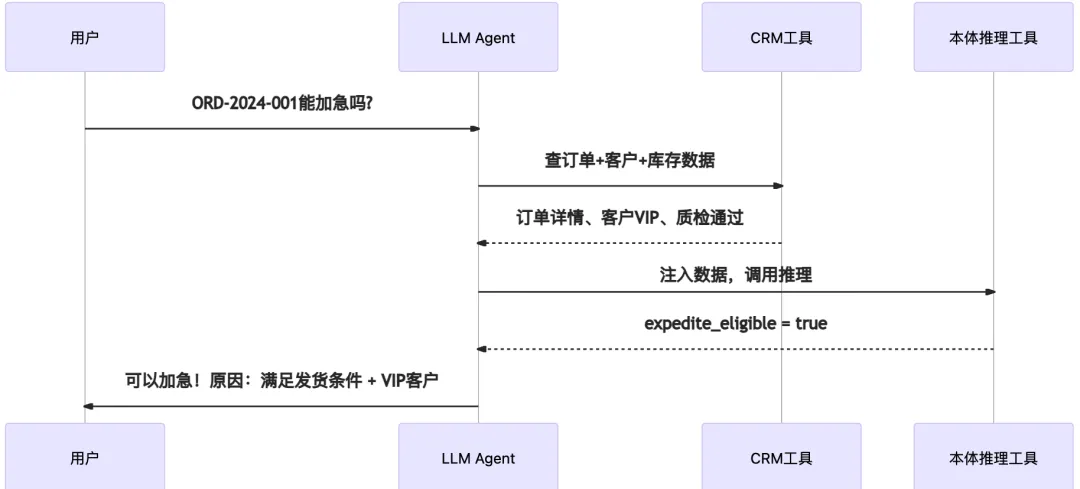
可发货条件:订单已占用库存,且质检通过 -
可加急条件:在可发货基础上,客户还是 VIP
-
首先把“什么才算符合条件”用形式化方式声明出来(OWL) -
Agent 按需调用本体里的这些规则做推理 -
Agent 根据推理反馈来决定下一步动作(如回复客户)
-
从数据库取事实:订单、客户、库存、质检状态(ABox) -
把这些事实临时注入本体:相当于把“各种事实”摆上台面 -
让推理机根据规则分类:这笔订单是否属于“可发货”“可加急”这两个类型
class OntologyReasoner:"""按需将单笔订单数据注入本体,推理后返回业务分类结果。"""def reason_order(self, customer_tier, customer_id, order_id, required_qty, allocations): onto = self._base_onto self._clear_abox() # 清空旧的临时实例数据# 1. 注入客户 cust_cls = self._cls("VIPCustomer") if customer_tier == "VIP"else self._cls("Customer") cust_ind = cust_cls("customer_id")# 2. 注入库存与质检信息 alloc_inds = []for a in allocations: alloc_ind = self._cls("InventoryAllocation")(a["id"]) alloc_ind.qcPassed = [a["qc_passed"]] alloc_inds.append(alloc_ind)# 3. 注入订单并建立关系 order_ind = self._cls("Order")(order_id) order_ind.hasCustomer = [cust_ind] order_ind.hasAllocation = alloc_inds# 4. 调用推理机with onto: sync_reasoner(infer_property_values=True)# 5. 读取推理结果return {"ready_to_ship": order_ind in self._cls("ReadyToShipOrder").instances(),"expedite_eligible": order_ind in self._cls("ExpediteEligibleOrder").instances(), }-
这笔订单有库存占用 -> 质检通过了 -> 属于 ReadyToShipOrder -
客户是 VIP -> 属于 ExpediteEligibleOrder

04
def classify_product(product): categories = []if product["is_hazardous"]: categories.append("危险品")if product["requires_cold_chain"]: categories.append("冷链")if product["is_export_controlled"]: categories.append("出口管控")if categories: categories.append("特殊处理")return categories-
产品属性从数据库来,分类规则写在代码里 — 两处维护
-
新增一个分类维度,就要改代码与回归测试
-
多个不同厂家的 Agent 可能会各自维护一套分类逻辑
-
想知道”系统里有哪些分类规则” — 只能翻代码,没有统一视图
-
在本体声明分类业务规则,也就是“什么产品是危险品”等 -
从数据库获取数据,注入本体做推理,得出产品类型
# 危险品:含危险成分 → 自动归类class DangerousGoods(Product): equivalent_to = [Product & isHazardous.value(True)]# 冷链产品:需要冷链运输 → 自动归类class ColdChainProduct(Product): equivalent_to = [Product & requiresColdChain.value(True)]# 出口管控产品:受出口管制 → 自动归类class ExportControlledProduct(Product): equivalent_to = [Product & isExportControlled.value(True)]# 特殊处理产品 = ①②③ 的并集class SpecialHandlingProduct(Product): equivalent_to = [Product & ( isHazardous.value(True) | requiresColdChain.value(True) | isExportControlled.value(True) )]defreason_product_classification(self, products):"""把产品属性注入本体,推理机自动完成所有分类。""" onto = self._base_onto self._clear_abox() prod_cls = self._cls("Product")# 四个分类类别,全部在本体初始化时由 equivalent_to 声明 category_classes = {"DangerousGoods": self._cls("DangerousGoods"),"ColdChainProduct": self._cls("ColdChainProduct"),"ExportControlledProduct": self._cls("ExportControlledProduct"),"SpecialHandlingProduct": self._cls("SpecialHandlingProduct"), }# 1. 将数据库中的产品属性注入本体(ABox) individuals = {}for p in products: ind = prod_cls(p["name"]) individuals[p["name"]] = ind ind.isHazardous = [p.get("is_hazardous", False)] ind.requiresColdChain = [p.get("requires_cold_chain", False)] ind.isExportControlled = [p.get("is_export_controlled", False)]# 2. 推理机一次运行 —— 所有分类自动完成with onto: sync_reasoner(infer_property_values=True)# 3. 读取分类结果(不是 if/else,是检查推理机的归类结论) .......省略......

-
这些规则用 if/else 也能写,为什么要用本体?

END


