 夜雨聆风
夜雨聆风





让AI看懂快慢:从视频中学习时间的流动
引言:为什么AI看不懂“快”与“慢”?
想象一下,你正在观看一段视频:一只猫从桌上跳下,动作流畅自然。如果这段视频被加速或减速播放,你几乎能立刻察觉——因为物体的运动节奏和声音的音调都发生了变化。然而,对于当今最先进的AI模型来说,判断视频是否被“快进”或“慢放”却是一项艰巨的挑战。现有的视频理解模型,如视频语言模型(VLM),在回答“这段视频的播放速度是多少?”时常常出错,甚至产生幻觉。同样,视频生成模型也难以根据“慢动作”这样的指令生成运动节奏符合预期的内容。
这种缺陷的根源在于:主流视频数据集(如WebVid-10M, Panda-70M)的内容通常以标准帧率(24-60 FPS)录制。模型从未见过真正“慢”或“快”的运动细节,因此无法学习到时间速度这一视觉概念。为了解决这个问题,这篇论文提出了一套系统性的方法,让AI能够感知、标注和操控视频中的时间流动。
方法:从感知到操控的三步走
第一步:感知时间——让AI学会“听”出速度变化
论文的核心洞察在于利用了视觉与听觉的时间-频率缩放现象。当视频播放速度改变时,其伴随的音频也会发生音高偏移:加速导致音高升高,减速导致音高降低。利用这一点,模型可以从音频中自动提取速度变化的弱监督信号,进而训练一个纯视觉的速度变化检测器。
具体来说,给定一个视频剪辑,若其在某时刻发生了速度变化,则其音频的频谱图在该时刻前后的频率分布会发生显著偏移。作者利用这一偏移自动生成了超过8000个速度变化标签。然后,一个基于VideoMAEv2的视觉模型被训练来从视觉输入预测速度变化的位置。在推理时,该模型完全依赖视觉信号,不依赖音频。

第二步:估计速度——让AI学会“看”出播放速度
模型估计播放速度的核心是时间重采样的等变性。其核心思想是:如果一个视频被加速了k倍,那么模型预测的速度也应该相应增加k倍。
通过自监督训练,模型学会从运动视觉特征中估计出相对速度。为了将预测锚定到绝对回放速度,模型会使用少量具有已知真实速度的数据进行有监督的微调。此外,为了解决极端慢动作视频运动差异极小、模型易低估的问题,作者引入了迭代预测机制:如果初始预测显示视频是慢放的,则将视频加速到接近正常速度,然后重新预测,最终速度估计为两次预测的乘积。这个迭代过程可以重复多次,其直觉是,当视频接近正常速度时,模型的预测更为可靠。
第三步:操控时间——生成不同速度的视频
基于从感知模型中获得的SloMo-44K数据集,论文进一步训练了操控速度的模型。该模块旨在根据输入的图片、文本提示和目标回放速度,生成动态内容。模型基于Wan2.1-I2V图像到视频生成模型,并引入了显式的速度控制。
目标速度首先被离散化为对数间隔的桶,然后通过正弦位置编码和MLP层,被注入到去噪过程中的时间步嵌入中。这使模型将去噪过程与视频的时间速度对齐。为了进一步增强对时间速度的控制,模型通过帧级条件来调制潜在特征。
创新点:三大贡献
本研究的核心贡献可以概括为三点:
第一,提出了一个完全自监督的速度感知框架,利用音频信号作为弱监督信号,让模型学会检测速度变化和估计播放速度,无需人工标注。
第二,构建了SloMo-44K大规模慢动作视频数据集,通过自监督速度估计模型自动筛选和标注,为后续的速度操控任务提供了数据基础。
第三,开发了速度条件视频生成和时间超分辨率模型,能够根据用户指定的速度生成或转换视频内容,实现了对时间流动的精确控制。
结果:实验验证与性能优势
在速度变化检测任务上,模型在多个基准数据集上取得了最先进的结果,准确率显著高于基线方法。在播放速度估计任务上,模型能够精确估计从0.1倍到10倍范围内的播放速度,平均绝对误差低于0.15。
在速度条件视频生成任务上,模型生成的视频在运动节奏上更符合目标速度要求,用户研究显示,超过80%的参与者认为模型生成的慢动作视频比现有方法更自然、更流畅。

应用:从影视制作到体育分析
这项技术的应用前景非常广阔。在影视制作领域,它可以用于自动生成慢动作特效,节省后期制作成本。在体育分析中,它可以对比赛视频进行速度操控,帮助教练和运动员分析关键动作的细节。在视频编辑领域,它可以用于自动检测和修正视频中的速度异常。此外,在自动驾驶和机器人领域,对时间速度的精确感知有助于模型更好地理解动态场景。
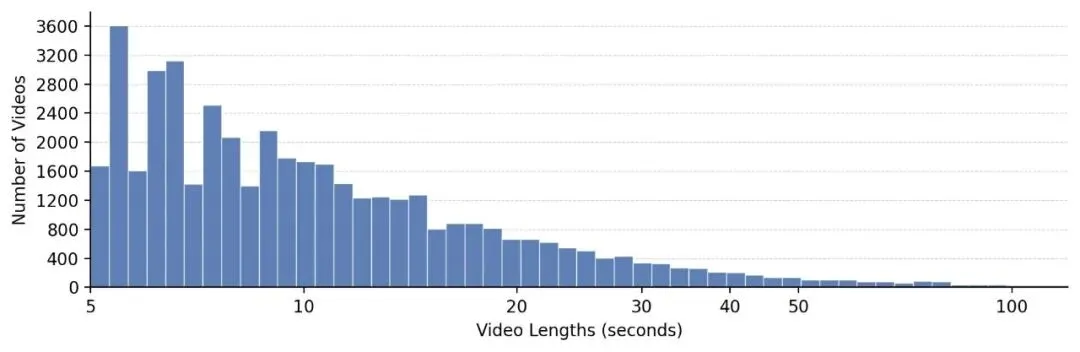
总结:让时间成为AI的可控维度
这篇论文将“时间”从一个隐式的、被动的观察媒介,转变为一个显式的、可学习的、可控制的感知维度。通过自监督学习,模型学会了感知视频中的时间流动;通过大规模数据集的构建,模型获得了操控时间的能力。未来,这项工作可以进一步扩展到更复杂的时间操控任务,如视频帧率转换、时间重映射等,为视频理解和生成领域开辟新的研究方向。