 夜雨聆风
夜雨聆风





一口气搞清楚AI圈的术语!

如果你也经常听到这些词,但是不是特别清楚他们是什么意思,我们今天会一口气搞清楚他们是什么意思,以及他们是什么关系
我们将用五层结构来解释整个AI产业链:
-
应用层-你每天用的
-
模型层-背后的大脑
-
基础设施层-AI工厂
-
芯片层-发动机
-
能源层-天花板应用层
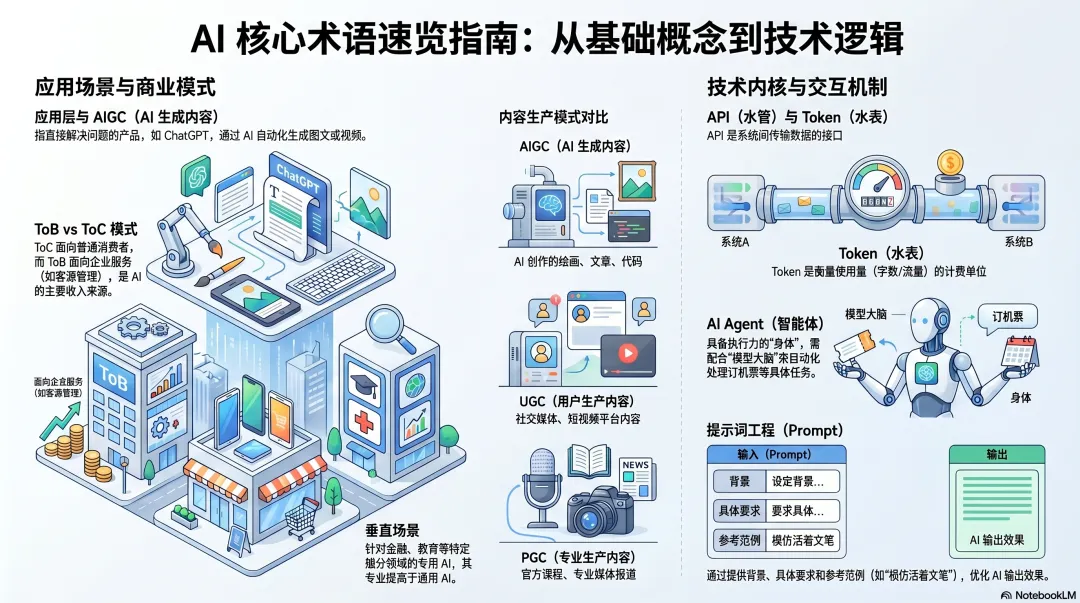
应用层
AI应用
首先离我们大家最近的应用层开始说起,应用层就是每天解决你具体问题的这些产品。比如说国外的ChatGPT、Claude、Gemini等,国内的豆包、DeepSeek等
AIGC
AI 生成内容(AI Generated Content),通常AI生成的图片、文字、视频等内容,已经广泛应用于社交媒体。但是AIGC并不是一个新词,同样的还有UGC(用户生产内容,如各大流媒体平台)PGC模式(专业生产内容,常见于官方课程)等这里不过多解释有兴趣可以了解一下
ToB和ToC
ToC 是面向普通消费者的产品(如免费使用的 AI 工具),ToB 是面向企业的服务(如企业记账、客源管理等),企业客户是 AI 主要收入来源。
API 和 Token(词元)
API 是软件系统间的接口,确保不同系统可互相传输数据;Token 是 AI 用量的统一计量单位,类似 “里程表”,用于衡量文字、图片、视频等的使用量。
如果觉得难懂的话可以这么理解:每个城市都有很多水厂(软件系统企业)他们为了赚钱需要把水管(API)接到用户家里为了精准计费需要根据水表(Token)的数字来收费
Agent(智能体)
具备 “手脚” 能执行具体任务的 AI,如整理文件夹、下载图片、订机票等,可自动化处理人类的琐碎工作。前段时间爆火的小龙虾(Openclaw)就属于AI Agent,Agent更像是一具没有脑子的身体,如果你想让这具身体给你打工你需要一个聪明的脑子。这个脑子也就是模型
提示词工程(Prompt)
通过清晰、具体的指令(提示词)与 AI 交互,指令越详细(含背景信息、具体要求、目标),AI 完成任务的效果越好。越多不等于越好,AI不知道什么叫“好”如果你想让他知道什么叫你理解的好你最好给他一个参考,比如说写一篇像活着文笔的作文
多模态
能同时处理文字、图片、声音、视频等多种形态数据的 AI,如 “全科医生” 般具备综合处理能力。或者是AI具有把自己输出的内容转换为图片、声音、文档、视频等能力
垂直场景
针对特定细分领域(如金融、教育)的 AI 应用,区别于服务全场景的通用 AI。比如说Google发布的TimesFM主要用于零样本的时间序列预测任务。
模型层
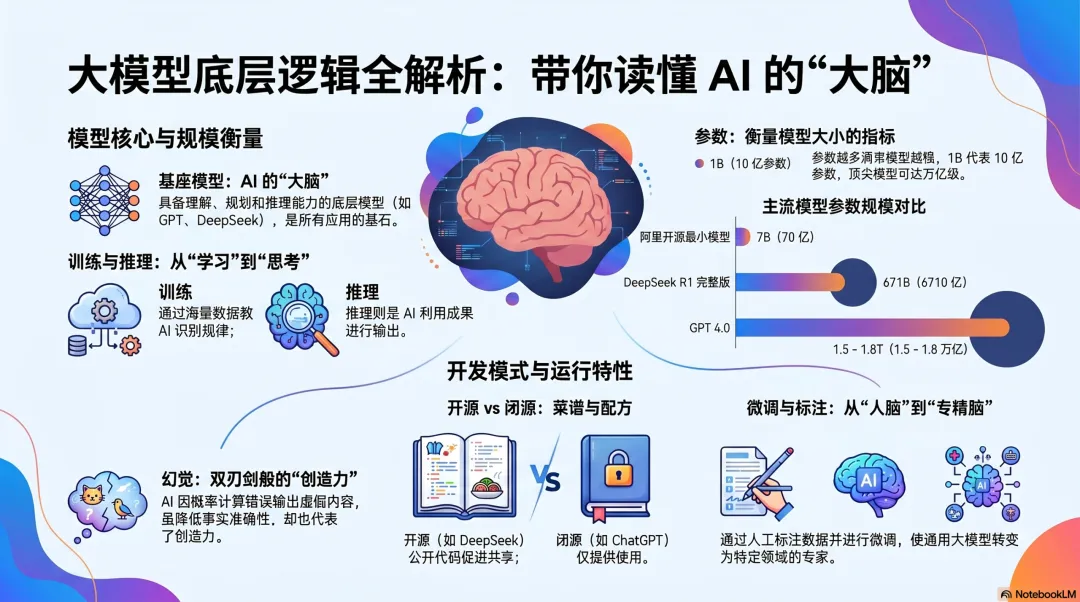
大模型 / 基座模型
AI 的 “大脑”,具备强大的理解、规划和推理能力,如 OpenAI 的 GPT、Anthropic 的 Claude(Opus 模型)、谷歌的 Gemini,国内的豆包底层模型、阿里千文、DeepSeek 等。基座模型可作为基础衍生小模型或应用。
训练和推理
训练是通过大量数据(如万张图片)“教会” AI 识别规律的过程,需消耗芯片、电力和人力;推理是 AI 利用训练成果进行思考和输出的过程,DeepSeek 等模型推理成本低、能力强。这一环节也是最考验企业财力能力的
参数
衡量模型大小的指标,参数越多模型通常越大,一般几十亿参数(几十 B)的模型可称为大模型。1B代表10亿个参数,阿里开源的最小模型为7b,也就是70亿参数。国外大模型如GPT 4.0普遍估算为1.5-1.8万亿(Trillion),DeepSeek R1 的完整开源版本总参数量为 671B(即 6710 亿参数)
微调
基于大模型调整得到更小、更专精或更便宜的模型,如将 “人脑” 调整为特定领域的 “专精脑”。
数据标注
AI 学习的基础,人类需预先标注数据(如标注图片中的猫 / 狗、红灯 / 自行车),AI 通过对比标注结果学习规律。
开源与闭源
闭源模型如可口可乐配方,仅提供使用不公开技术;开源模型如菜谱,公开代码和模型供开发者修改和使用,促进技术共享。比如比较知名的闭源大模型ChatGPT、Gemini、Claude、xAI等开源大模型千问、DeepSeek等
幻觉
AI 因预测下一个词的概率计算错误,导致输出看似合理但不符合事实的内容,技术发展正不断降低错误率。幻觉是一把双刃剑,可以理解为幻觉低和幻觉高代表着大模型的死板和创造力
基础设施层
云服务
AI 的 “水电煤”,提供算力、计算空间等资源,用户无需自建服务器,可像 “开水龙头” 一样调用(如阿里云、腾讯云、AWS)。
数据中心
存放服务器的 “厂房”,需 24 小时供电、断网和降温,是判断 AI 公司实力的指标之一,手机照片等数据通常存储于此。
算力集群
大量 GPU 连接形成的计算集群,直接决定模型训练能力,如 ChatGPT 依赖早期囤积的一万张 GPU 卡。还有同样的Gemini训练用的是谷歌自研TPU
芯片层
算力
AI 的 “燃料”,AI 本质是概率预测模型(如下一个字、像素颜色的概率计算),需芯片支撑快速运算,算力差距可能是指数级的。
GPU
图形处理器(显卡),最初为解决游戏实时画面计算设计,因并行计算能力强成为 AI 基础设施,英伟达是主要厂商。同样的还有谷歌自研TPU
CUDA
英伟达的技术架构,用于高效计算,是其核心竞争力。大范围被用于AI训练,科研数学计算
芯片出口管制
部分国家为限制他国 AI 发展,对高端芯片实施出口限制,体现芯片在 AI 竞争中的战略地位。
能源层
算力成本
包括芯片成本(单块英伟达芯片价格达五位数,需大量采购且持续迭代)、电费(AI 耗电量远超家庭电器)和运维费用。更详细如光模块、机房空调等
电力消耗
一个数据中心的耗电量相当于小型城市,推动清洁能源和核电发展以降低成本。
上面说的每一层都会使AI再一次提高上限,比如说电力效率高了,就会让AI指数跃迁。比如芯片好了就会让大模型和应用都会有提高
现在要做的就是理解底层逻辑不再被天花乱坠的术语迷惑