 夜雨聆风
夜雨聆风





从 OpenClaw 切到 Hermes Agent,那些没人告诉你的事
从 OpenClaw 切到 Hermes Agent,那些没人告诉你的事
“
Hermes Agent 用十周时间冲到了 110k GitHub stars——这是 2026 年增长最快的 Agent 框架。这篇文章聊聊它到底跟 OpenClaw 有什么本质区别、自学习循环是怎么运作的,以及什么情况下值得换、什么情况下别动。
背景:开源 Agent 圈正在发生什么
OpenClaw 是奥地利开发者 Peter Steinberger 在 2025 年底做的一个周末项目,后来成了 GitHub 历史上增长最快的开源项目之一——到 2026 年 4 月初已经积累了 34.5 万 stars,ClawHub 社区市场里有 13000+ 技能包,覆盖 24 个消息平台的集成。它解决了一个真实问题:自托管 AI Agent、支持主流模型提供商、帮团队自动化工作流,同时不被任何厂商绑定。
然后安全事故来了。2026 年 3 月,四天内爆出九个 CVE,其中一个 CVSS 评分高达 9.9。有人对 ClawHub 做了供应链审计,在扫描的 2857 个技能包里发现了 341 个恶意包——大约 12% 的恶意率。安全研究员在 82 个国家找到了超过 13.5 万个公开暴露的 OpenClaw 实例。Cisco 直接把这类个人 AI Agent 称为”安全噩梦”。
就在这个时间节点,Nous Research——就是 Hermes、Nomos、Psyche 这几个模型系列背后的那家实验室——在 2026 年 2 月 25 日发布了 Hermes Agent。它押注的是一条完全不同的架构路线。
Hermes Agent 到底是什么
Hermes Agent 是一个开源 AI Agent 框架,核心只围绕一个架构理念:让 Agent 在你的具体工作流上越用越好。不是靠微调,不是靠模型更新,而是靠每次任务结束后都会运行的闭合学习循环。
大多数 Agent 框架的流程是固定的:接收任务 → 规划 → 执行 → 返回结果,然后会话结束,什么都不留下。下次任务从同一个起点重新开始。在 OpenClaw 里,同类任务做一百遍,Agent 也不会变得更擅长——每次都当新问题处理。
Hermes 在执行之后加了一层。任务完成后,它会进入 Nous Research 所说的”反思阶段”:分析自己的表现,提取可复用的模式,然后把解决这个问题的方法写成一个新的技能文件存下来。下次遇到类似任务,Agent 会先查自己的技能库,而不是从头推理。这些积累下来的”机构记忆”会跨会话持续叠加。

“
架构上的核心差异在这里:OpenClaw 的技能是人写的,通过 ClawHub 分发,你写、你审、你装。Hermes 的技能是 Agent 从自身经验里写出来的。可以这么理解:OpenClaw 是那种照着说明书干活的助手;Hermes 是那种干完活之后自己写说明书的助手——为的是下次做得更好。
闭合学习循环:它是怎么越用越聪明的
学习循环是 Hermes 的技术核心,也是它能以 OpenClaw 做不到的方式持续积累的原因。整个机制由三个部分构成。
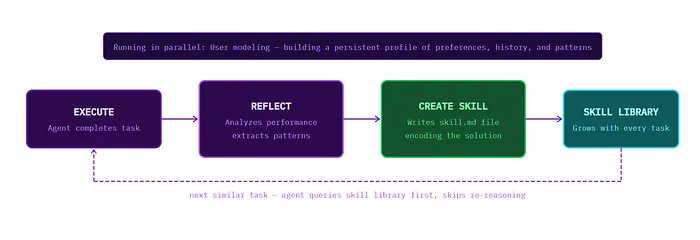
图 1 — Hermes 的闭合学习循环。每次完成的任务都会反馈进一个不断扩展的技能库。未来遇到相似任务,直接查已有技能,跳过重新推理——在积累了 20+ 个技能之后,同类任务的耗时能缩短 40%。
技能创建:任务成功完成后,Hermes 会把操作步骤写成一个 Markdown 技能文件。格式遵循 agentskills.io 开放标准——跟 Claude Code、Cursor 用的是同一套规范,所以技能文件是可以跨平台迁移的。技能库会从 118 个预装技能出发,随着 Agent 的使用经验不断扩展,逐渐长出几百个领域专属技能。
用户建模:Hermes 会跨会话持续构建用户画像,不只记录你分配了什么任务,还包括:你偏好什么格式的回答、需要多少细节、在类似场景下做过哪些决策、给过哪些反馈。这个画像会持续保留。用上几周之后,那些它已经知道答案的问题,它就不会再反复来问你了。
自我评估:生成新技能之后,Hermes 会跑一遍内部评估,检验这个技能是否真的能泛化,还是只适用于产生它的那个具体情形。评估不通过的技能会先被修正,再加入技能库。这是防止库里堆垃圾的关键机制。
三层记忆系统

从 v0.10.0 开始,记忆系统完全插件化。可以通过插件接口换成第三方后端——Honcho、向量数据库或者自定义数据库——开箱支持六个第三方记忆提供方。这是一个有意识的架构选择:Nous Research 不想让记忆层成为用户被绑定的地方。
“
一个很容易踩的坑:自学习功能默认是关闭的。很多第一次用的人都在这里栽了跟头。必须在
~/.hermes/config.toml里手动开启持久化记忆和技能生成。跳过这一步,Hermes 就跟普通的单会话 Agent 没区别,”越用越聪明”的承诺根本不会兑现。
上手配置
Hermes 对运行环境要求很低,从 5 美元的 VPS 到 Serverless 都能跑,空闲状态下几乎没有成本——只有 Agent 真正在思考的时候才会消耗 LLM API 费用。对独立开发者来说,跑一个复杂任务通常只需要 0.3 美元左右(用预算模型的话)。
# 安装 Hermes Agentpip install hermes-agent# 或者从源码安装git clone https://github.com/NousResearch/hermes-agentcd hermes-agent && pip install -e .# 初始化工作区hermes init ~/my-hermes-workspacecd ~/my-hermes-workspace最关键的配置——开启学习循环:
# ~/.hermes/config.toml — 最重要的文件[model]provider = "anthropic" # 或 openai, google, openrouter 等model = "claude-opus-4-5"base_url = "https://api.anthropic.com" # 改这一行就能切换模型供应商[memory]enabled = true # 必须开启 — 默认是关闭的skill_generation = true # 必须开启 — 启用学习循环user_modeling = true # 构建持久用户画像episodic_archive = true # SQLite FTS5 冷存储召回backend = "sqlite" # 或 "honcho"、"pinecone"、自定义[agent]workspace = "~/my-hermes-workspace"skill_eval = true # 入库前验证技能质量max_skills = 500 # 上限,超过后淘汰低频技能reflection_depth = "standard" # "light" | "standard" | "deep"[integrations]slack = falsediscord = falsetelegram = false从 OpenClaw 迁移
Hermes 自带迁移工具,可以把 OpenClaw 的 persona、记忆、技能、配置和 API Key 一并导入:
# 先做 dry run——预览会导入什么hermes claw migrate --dry-run --source ~/.openclaw# 执行实际迁移hermes claw migrate --source ~/.openclaw# 验证导入结果hermes skills listhermes memory status代码示例
跑任务 + 观察技能生成
import asynciofrom hermes_agent import HermesAgentasyncdefmain(): agent = await HermesAgent.create( config_path="~/.hermes/config.toml" )# 第一次:Agent 从头推理 result = await agent.run("Review this PR diff and flag any security issues: {diff}", context={"diff": open("pr_diff.txt").read()} ) print(result.response) print(f"新生成技能: {result.skills_created}") print(f"调用技能: {result.skills_used}") print(f"反思内容: {result.reflection_summary}")asyncio.run(main())第一次运行的输出:
新生成技能: ["pr-security-review-v1.md"]调用技能: []反思: "在第47行发现SQL注入风险。已创建技能用于未来SQL审查任务。"做了 20 个类似 PR 之后的输出:
新生成技能: []调用技能: ["pr-security-review-v1.md", "sql-injection-patterns.md"]任务完成速度提升40%——技能库直接处理了模式匹配查询技能库
asyncdefinspect_skills(): agent = await HermesAgent.create()# 列出所有自生成技能 skills = await agent.skills.list(source="self-generated")for skill in skills: print(f"{skill.name}: 调用{skill.use_count}次, "f"成功率={skill.success_rate:.1%}")# 查看用户模型 user_model = await agent.memory.get_user_model() print(f"偏好: {user_model.preferences}") print(f"常见任务类型: {user_model.frequent_task_types}") print(f"会话记录数: {user_model.session_count}")两者的全面对比
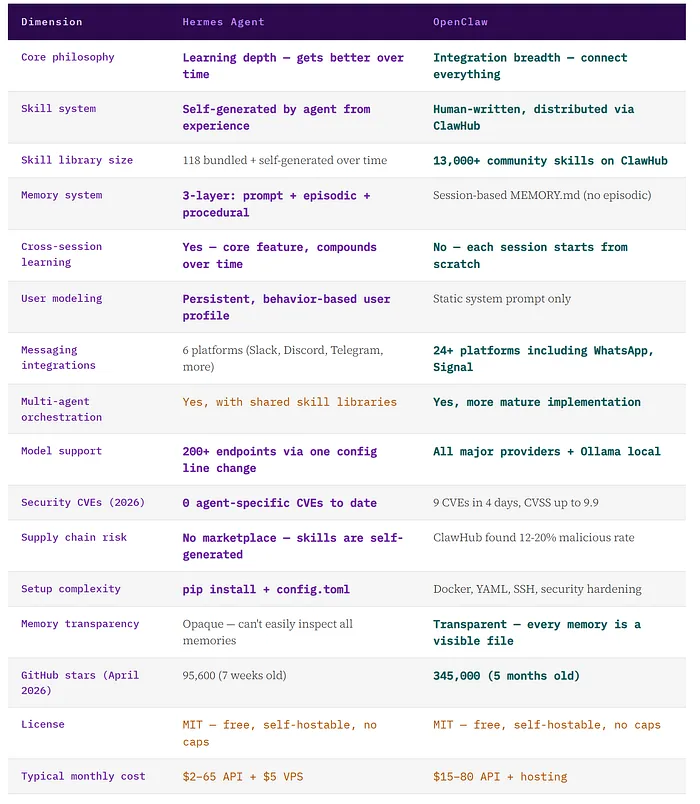
安全层面的对比
这部分对 OpenClaw 来说有点难看。CVE-2026-25253(CVSS 8.8)暴露了一个 WebSocket 跨站劫持漏洞——/api/export-auth 接口缺少鉴权,局域网内任何人都能从任何可访问的 OpenClaw 实例里拿走所有存储的 API Key。这只是 2026 年 3 月四天内爆出的九个 CVE 之一,同期安全研究员在全球 82 个国家找到了超过 13.5 万个公开暴露的实例。
根源不是技术能力不行,是架构问题。OpenClaw 最初是个消费者向的本地工具,后来慢慢长成了一个联网 Agent,很多安全假设在个人工具的场景下说得通,但在大规模部署时就成了隐患。
截至 2026 年 4 月,Hermes 没有任何已报告的 Agent 专项 CVE。它的架构包含容器隔离、子 Agent 的命名空间隔离,以及通过插件化记忆系统实现的凭证轮转。更重要的是:Hermes 的技能由 Agent 自己生成而非从社区市场下载,从架构上就规避了供应链攻击的风险——没有 ClawHub 那样的渠道,恶意包就没有分发的途径。
“
一个必要的注脚:Hermes 是 2026 年 2 月才发布的,OpenClaw 在更大规模上运行了更长时间。暴露时间短意味着发现的漏洞少——但这不等于架构上更安全。零 CVE 记录值得鼓励,不等于安全保证。企业级部署场景下,两个框架都需要认真做安全评审,不能光看公开漏洞记录。
一些局限性
自学习默认关闭。这是新用户吐槽最多的地方。”越用越聪明”的承诺必须在配置里手动开启持久化记忆和 skill_generation 才会生效。没开的话 Hermes 跟任何其他单会话 Agent 没什么两样。很多评价 Hermes”没什么特别的”评测者,其实根本没开过学习循环。
它不是代码生成工具。Hermes 明确定位是对话式 Agent 框架。写代码、调 Bug、重构这类软件工程任务,Cursor、Windsurf、Claude Code 的表现都比它强。如果主要需求是换掉 AI 编程助手,Hermes 不是合适的选项。如果要的是一个能在几个月里持续积累研究、分析、重复性工作流上下文知识的个人 AI,它是个有力的候选。
记忆不透明。OpenClaw 的记忆是透明的——每条记忆都是一个可以直接查看、编辑、删除的文件。Hermes 用便利性换掉了这种透明度。SQLite 的情节记忆档案对人来说不太好直接读。v0.10.0 加了一个 hermes memory inspect 命令,可以看到用户模型和最近的情节条目,但跟 OpenClaw 的每条记忆一个文件相比,还是差点意思。
集成平台少——这是有意为之。六个消息平台对比 OpenClaw 的 24 个以上。Nous Research 的态度很明确:宁愿把六个平台做深,也不愿把二十四个做浅。如果需要 WhatsApp + Telegram + Slack + Discord 全部接在同一个 Agent 实例上,OpenClaw 仍然是更强的选择。
项目还年轻,版本少。Hermes 发布了 10 个版本,OpenClaw 已经有 82 个。Reddit 上有人直说:”Hermes 才 6 个版本对 OC 的 82 个,其中 3 个根本跑不起来。别信那些说它更稳定的话,它根本没经历过足够长的时间来证明这一点。”这条评论是基于更早的计数,v0.10.0 的稳定性已经改善了不少,但这个逻辑本身站得住脚——Hermes 还没在 OpenClaw 量级的规模上跑过。
到底该不该换
建议切到 Hermes 的情况:每天都在做同类任务——每周的代码审查、固定的调研工作流、重复的文档分析。学习循环的收益是按月计的,不是按天。在特定领域积累了 20 个以上自生成技能之后,40% 的任务提速是实实在在的。另外如果追求更简单的部署和更好的默认安全性,也值得考虑。
建议留在 OpenClaw 的情况:需要单个 Agent 实例接 24 个以上消息平台;在给团队或组织部署 Agent、生态广度比单实例学习能力更重要;重视透明的文件式记忆;需要 OpenClaw 成熟的多 Agent 编排能力;或者已经在 ClawHub 技能生态上投入了大量时间。
两个都用的情况:这是 Reddit 社区里复杂场景的主流答案。OpenClaw 负责多渠道编排层,Hermes 作为特定工作流的执行 Agent,在那些需要持续积累学习成果的场景里跑。两者与其说是竞争关系,不如说互补。
实际成本参考:Hermes 实例跑在 5 美元 VPS 上、配合 Claude Sonnet 使用,中等使用量每月 API 费用大约 30-65 美元。同等使用量的 OpenClaw 实例在自托管 Docker 环境下大约 40-80 美元。对独立开发者来说成本差距不大——真正的问题是:时间花在 Docker 配置上,还是花在跟 Agent 一起工作上,哪个对你更值得。
“
说到底:OpenClaw 证明了自托管 AI Agent 可以管收件箱、自动化工作流、全天候运行并接入所有常用应用。Hermes Agent 证明了 Agent 不必每次任务都从零开始。这两件事都是真实的进步,只不过走的是不同的取舍路线。问题不是哪个更好,而是哪种取舍更适合自己的实际工作方式。

如果你觉得这篇文章对你有帮助,别忘了点个赞、送个喜欢
>/ 作者:ChallengeHub小编
>/ 作者:欢迎转载,标注来源即可