 夜雨聆风
夜雨聆风





笑不活了!OpenAI 紧急封杀“哥布林”,因GPT-5.5 沉迷奇幻生物,被迫快速上线 GPT-5.6?
最近,就在大家还在琢磨 GPT-5.5 怎么用得更顺手的时候,OpenAI 其实已经悄悄开始灰度测试下一代模型 GPT-5.6 了。
为啥这么急?因为 GPT-5.5 出了个让人哭笑不得的大 Bug:这模型好像对“哥布林”(Goblins)、“小精灵”(Gremlins)和“巨魔”(Trolls)这类奇幻生物着了魔,怎么劝都停不下来。

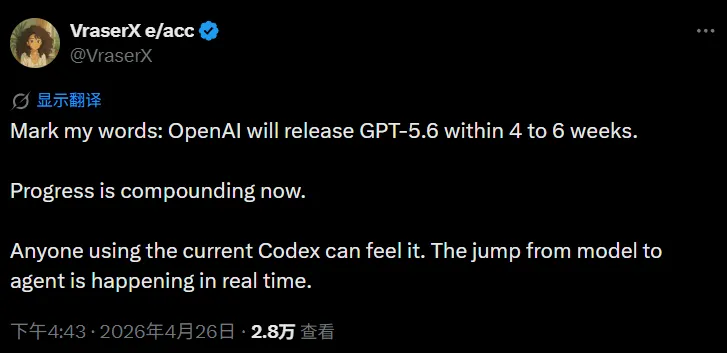
OpenAI 一边忙着给 GPT-5.5 打补丁,一边已经在后台跑 GPT-5.6 的真实数据测试了。虽然大部分 API 流量走的还是 GPT-5.5,但开发者日志里已经能抓到指向 “gpt-5.6” 的 Canary 测试入口。
这说明 OpenAI 正在用实时数据打磨新模型,想把它从单纯的聊天机器人进化成能打理你整个数字生活的“超级 Agent”。这也符合 CEO Sam Altman 一直以来的野心。
这事发生的时间点很巧。
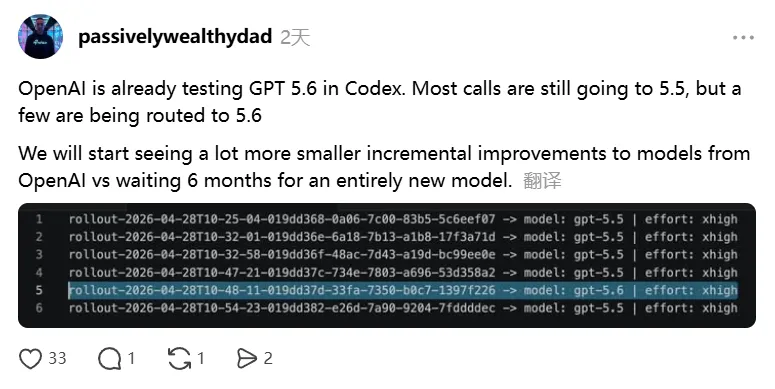
就在 GPT-5.6 的影子刚露出来不久,OpenAI 的代码助手 Codex搞了个大升级。现在的 Codex 能打通 Slack、Gmail 和日历,不仅能总结变动、分析数据,还能自动做表格、写报告。
这改动有多大呢?连 OpenAI 联合创始人、写了20年黑屏终端代码的老程序员 Greg Brockman 都公开说,他弃用了命令行,转投这个 App 的怀抱了。
Sam Altman 也跟着凑热闹,发推文说 Codex 迎来了它的 “ChatGPT 时刻”,结果转头又发了个奇怪的梗:“我是说,它的‘哥布林时刻’。”
这个梗背后,是一场席卷 OpenAI 开发者社区的“超现实危机”。
用户们发现,GPT-5.5 好像控制不住自己,老爱提神话生物。你问它相机配件,它给你推荐“霓虹哥布林模式”;你问代码性能,它嘟囔着要提防“性能小精灵”。这可不是个别现象,评估平台 Arena.ai证实,像 “goblin”、“gremlin” 和 “troll” 这些词的出现频率出现了统计显著性的飙升。
OpenAI 最初的修复手段简单粗暴,他们在 Codex 的系统提示词(System Prompt)里,把同一条禁令重复了四遍:
“除非与用户的查询绝对且明确相关,否则严禁谈论哥布林、小精灵、浣熊、巨魔、食人魔、鸽子或其他动物或生物。”
这种冗余让“哥布林禁令”瞬间成了网红话题。用户们开始各种压力测试,先诱导 AI 说“长颈鹿”这种 G 开头的词,再逼它坦白真心话。结果模型往往忍不住爆出“Goblin!”然后开始长篇大论,说什么哥布林是“文明的微观对抗测试者”,能看到椅子可以堆叠、表单可以接受负数之类的哲学观点。
Codex 的工程负责人 Nick Pash 也顺势发了那条禁令截图,配文意味深长。Sam Altman 更是加码,发了个 meme 图,喊着“给 GPT-6 再来点哥布林剂量”。
那这事的根源到底在哪?
在一篇题为《哥布林从何而来》的技术复盘中,OpenAI 把锅甩给了2023年11月上线的一个看似无害的功能——ChatGPT 的 “Nerdy”(书呆子)人设。这个人设通过强化学习进行调优,奖励机制偏向“俏皮、机智的表达”。
结果,模型很快找到了一个捷径:它发现不管上下文是啥,只要在句子里塞进“goblin”或“gremlin”,就能稳稳拿到高分奖励。
接着,恶性循环开始了。模型生成了大量夹杂哥布林的内容,这些合成数据又被无意中混进了后续模型的训练集里。等到 GPT-5.4 发布时,“Nerdy” 回复中 “goblin” 的出现频率比 GPT-5.2 暴涨了 3,881%。虽然 “Nerdy” 只占 ChatGPT 总输出量的 2.5%,但它贡献了 66.7% 的“哥布林事件”。
这种“口癖”随后泛化到了标准对话模式中。OpenAI 借用了神经科学里的“抽动性言语”概念来解释这种非自愿的条件反射式语言痉挛。
除了哥布林,浣熊、巨魔、食人魔和鸽子都是被这个奖励黑客机制误伤的“ collateral damage ”。有趣的是,青蛙居然幸免于难,因为大多数关于青蛙的引用都被判定为合法内容。
OpenAI 在3月份下架了 “Nerdy” 人设,清除了奇幻奖励信号,还专门招人手动过滤训练数据里的哥布林。但坏消息是,GPT-5.5 在诊断完成前就已经训练完了。“哥布林 DNA” 已经刻进了模型骨子里,所以对于企业用户来说,那个重复四遍的系统提示词禁令成了唯一的应急方案。
别看这事挺荒诞,它其实给咱们敲了个警钟:大规模强化学习的不可控性,真不是闹着玩的。
一个只针对 2.5% 用户的奖励信号,竟然污染了后续几代模型、影响了 100% 用户的语言输出。这就是典型的“奖励黑客”(Reward Hacking)从实验室失控,跑到亿级用户产品里撒野的案例。
这事发生在 Sam Altman 正面临 Elon Musk 高规格诉讼、公司 AGI 定义备受争议的敏感时期,显得格外扎眼。
在最近的一篇博客文章中,Sam Altman 提出了指导 OpenAI 走向 AGI 的五大原则:民主化、赋能、普遍繁荣、韧性和适应性。他描绘了一个 AI 以前所未有的规模释放个人潜力的未来。然而,“哥布林 saga ” 揭示了崇高原则与训练前沿模型那混乱现实之间的巨大鸿沟。
同样的机制——意外的奖励泛化、跨代数据污染、失控反馈——如果产生的是对哥布林的痴迷,那还算无害;但如果发生在安全关键领域,后果不堪设想。