 夜雨聆风
夜雨聆风





植物表型分析进入Agent时代:AI正在从工具变成科研助手



Chen, F., Stogiannidis, I., Wood, A. et al. A conversational multi-agent AI system for automated plant phenotyping. Nat Commun (2026).
植物表型分析
进入“科研助手”时代
2026
– Nature Communications –

导语
PhenoAssistant
依旧梦到哪说哪,这几天没事又想着研究研究把机器学习加到课题里。对于传统农学生,不怕没有数据,就怕中间那一堆技术活。叶片分割、面积计算、表格整理、统计分析、画图、写代码、调模型、复现流程。很多植物研究者都被挡在代码和工具链之外。
上个月Nature Communications 在线发表了一篇文章,介绍了这个叫 PhenoAssistant的系统。它能让植物研究者用自然语言描述任务,然后由系统自动选择工具、调用模型、完成表型提取、数据分析和结果整理。
以后你可能不用从零开始写一堆脚本,只要能把任务说清楚就行:
“帮我从这些拟南芥图片里计算叶片数和投影叶面积。”
“根据这个表格画出生长曲线。”
“比较不同材料的叶面积差异是否显著。”
然后系统会尝试把后面的分析流程接起来。
未来植物表型分析可能不再需要写代码。学习语法,提高表达能力,把科学问题说清楚更重要一些,或许要加开一门叫大学语文的课。


Figure 1
他就是一个“表型分析工作台”



用户把任务和数据交给系统后,中间的 Manager会先制定计划,然后选择工具,再执行任务,最后总结结果。整个流程大致可以理解为四步:计划、选工具、跑工具、写总结。
它背后接了一个工具箱,里面包括视觉模型库、表型计算模块、视觉模型训练、统计检验、表格分析、数据可视化、图形解读、代码生成、文献检索和流程复现等功能。
这个设计很像一个小型科研工作台。用户提出问题,系统把多个分析环节组织起来。对植物表型分析来说这很关键。因为最麻烦的地方在于流程太碎:图片在一个地方处理,表格在另一个地方整理,统计又要换一套软件,最后还要重新画图。
PhenoAssistant就是把这些分散的步骤串起来的“人”。


Figure 2
直接用 通用模型 数叶子行不通




作者拿一张拟南芥俯视图,让 ChatGPT 4o模型直接计算两个指标:叶片数和投影叶面积。结果并不稳定。第一次回答叶片数是4,第二次又变成1,而真实叶片数是14。投影叶面积的计算结果也和真实值差距很大。
后面作者又让ChatGPT 4o尝试做叶片实例分割,也就是把每一片叶子单独分出来。模型先把整盆植物或者花盆大致框出来,再尝试分出叶片区域,最后虽然看起来有一些改进,但依然没有清楚地分开每一片叶子。
这个图提醒我们:植物表型分析和普通看图问答差别很大。
叶片之间会重叠,边界会粘连,背景也可能干扰。对人来说,看到一株拟南芥并不难;对模型来说,要把每一片叶子稳定切出来,再计算面积和数量,就需要专门训练过的视觉模型和配套算法。不能只靠“看起来很聪明”的通用模型。专业数据、专业模型和可检查的流程仍然很重要。


Figure 3
看看他的工作流


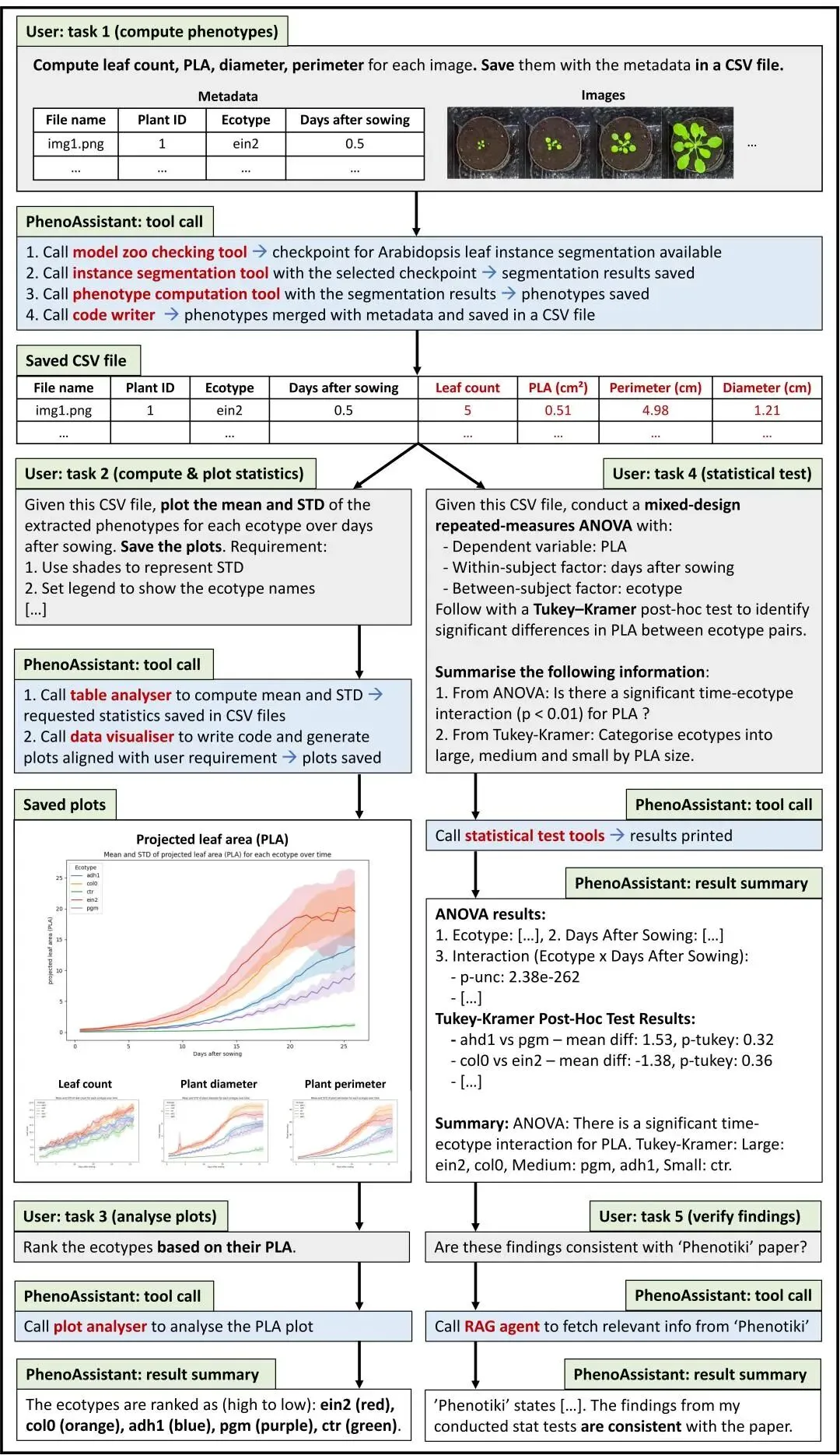

这是文章的第一个案例,研究对象用的拟南芥。作者用到了一个表型数据集:24株拟南芥,5种生态型,连续生长26天,每12小时拍一次图,总共1248张图像。
如果按传统方式来做,研究者需要先从每张图片里提取叶片数和投影叶面积,再把这些结果和样本信息合并成表格,然后画出生长曲线,最后比较不同生态型之间的差异。
PhenoAssistant在这个案例里完成了这一串任务。它先调用适合拟南芥叶片分割的模型,提取投影叶面积和叶片数;然后用代码工具把结果和元数据合并成CSV文件;接着根据用户要求画图;再进一步调用统计工具做ANOVA和Tukey-Kramer检验;最后还可以利用文献检索模块,把分析结果和已有研究进行对照。
图像 → 表型指标 → 表格 → 曲线 → 统计检验 → 结果解释。


Figure 4
土豆叶片


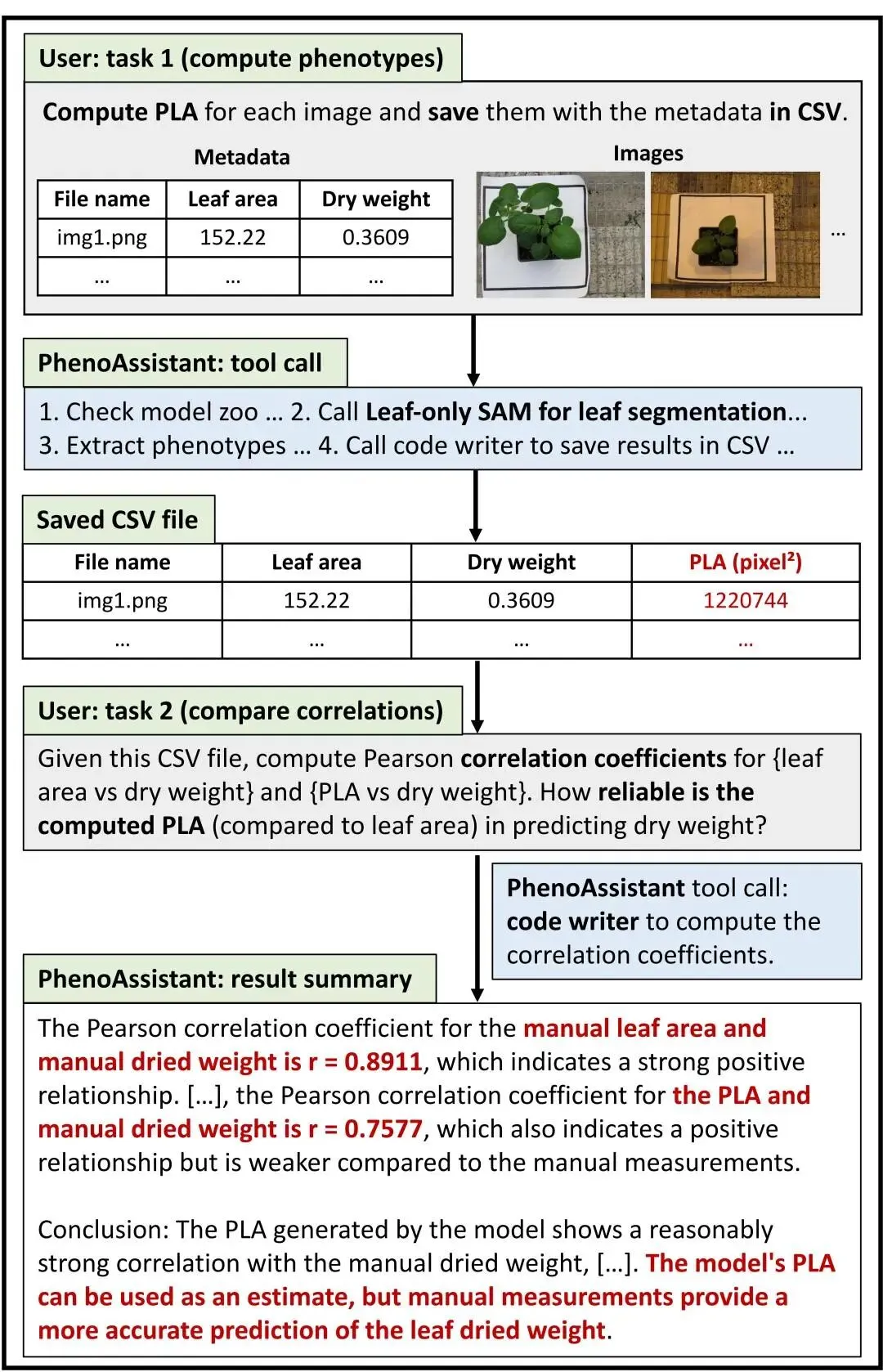

那用模型自动计算出来的投影叶面积,能不能替代人工测量的叶面积,用来预测叶片干重?
PhenoAssistant先调用土豆叶片分割模型,计算投影叶面积;然后继续写代码,分析人工测量叶面积与干重之间的相关性,以及模型计算的投影叶面积与干重之间的相关性。
结果显示,人工叶面积与干重的相关性更强,Pearson相关系数为r = 0.8911;模型计算的投影叶面积与干重也呈正相关,相关系数为r = 0.7577,相关性相对弱一些。
这张图很适合用来讲自动化表型分析的边界。
模型能提高效率,也能批量处理图片;与此同时,模型计算出来的指标会受到分割精度、拍摄角度、叶片形态和图像质量影响。它能提供估计值,研究者还需要判断这个估计值能不能支撑自己的科学问题。


Figure 4
没有现成模型时,系统可以帮你训练


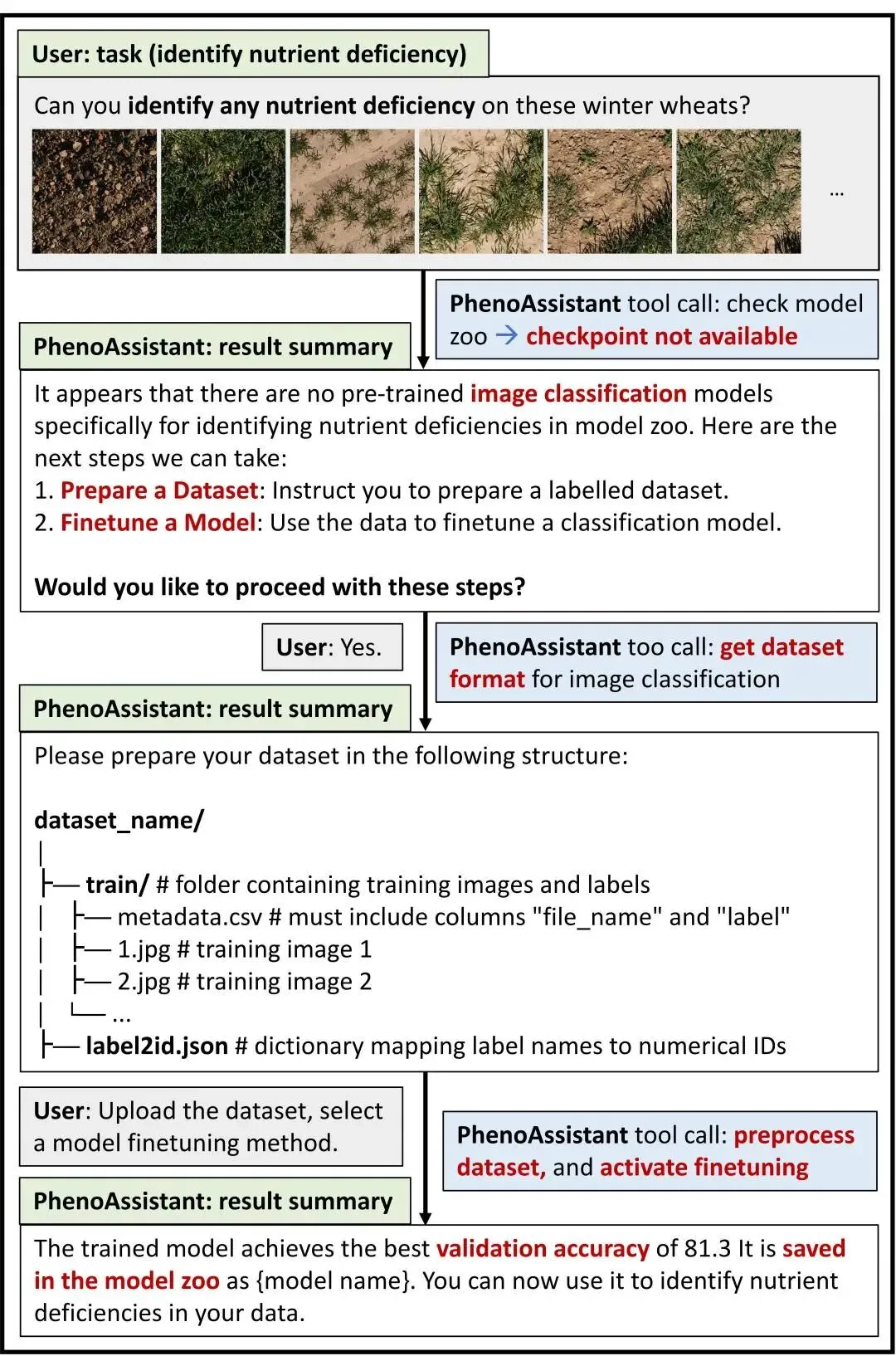

这是第三个案例:
冬小麦营养缺乏识别
这个场景可能更接近真实科研。很多时候,我们面对的任务都很具体:某个作物、某个环境、某种处理、某类症状。公开模型库里很难刚好有一个完全匹配的模型。我的研究也需要自己训练一个小的识别模型。
在这个案例中,用户希望识别田间冬小麦的营养缺乏症状。PhenoAssistant会先检查现有模型库,发现没有合适的预训练模型。接着,它提示用户准备带标签的数据集,并给出数据格式要求。用户上传数据后,系统开始自动进行数据预处理、划分训练集和验证集、选择微调方式、训练模型并评估性能。
最后,训练好的模型会被加入模型库,后续就可以继续使用。
作物不同、器官不同、处理不同、拍摄条件不同,很难靠一个万能模型解决所有问题。大多数情境下,研究者还是需要用自己的数据训练适合自己任务的模型。你要建立自己的工具箱。


植物表型分析是植物科学与作物育种的基础环节。无论是评估某个基因对株型的影响、某种处理对生长的促进效果,还是某份种质资源的抗逆性,都离不开表型数据支撑。
高通量成像、无人机航拍、RGB-D相机、时间序列拍摄等技术的普及,使研究者能够获取数量空前的图像数据。数据量的激增,随之带来了分析压力的同步攀升。
过去,许多实验室的表型分析流程相当依赖人工操作:图片先经一个工具处理,结果导出为表格,表格再用于统计,统计完成后还需绘图,绘图之后往往又要回溯原始数据核查。每个步骤本身都能完成,但步骤之间的衔接容易脱节,整体效率难以提升。
PhenoAssistant帮助研究者将上述环节有机整合。研究者只需将分析任务描述清楚,系统便负责尽可能地将工具链串联贯通。如此一来,咱就得以将更多精力投入实验设计、结果判断和生物学解释,不用消耗在繁琐的流程衔接上。
但它远远没有到可以完全放手的程度。
文章措辞相当坦诚,明确指出了若干局限。其一,复杂任务仍有赖于用户提供足够清晰的描述:
1.任务表述模糊时,系统可能选错工具,或遗漏关键步骤。2.工具选择与数据分析结果仍需人工审核;评估结果显示,引入Critic agent后工具链评分有所提升,但在图形细节解读等任务上,大模型仍存在出错的风险。3.视觉模型的适用范围需格外审慎。针对特定光照条件、特定作物和特定拍摄场景训练的模型,在迁移至其他场景时性能可能显著下滑,研究人员仍需对分割结果、统计结论和最终解释逐一查验。
这也是此类系统未来最亟待突破的方向:模型泛化能力的提升、异常数据的自动识别、分析流程的规范审核、结果可解释性的增强,以及跨数据集的稳定性保障。
AgriPulse点评
傻瓜式操作是潮流。以前我们关注的是某个模型能否分割叶片、某个算法能否测量面积;现在,更关键的问题变成了:这些工具能否被组织成一条稳定、可复现、可检查的科研流程。这不只是效率的提升,而是分析范式的转变。
AI首先要解放研究者的双手。批量分割图像、整理表格、编写代码、绘图、统计。这些工作既耗时,又容易出错。把这些环节交由系统辅助完成,研究者便能将更多精力集中于实验设计和结果解释。AI在不能替代判断,蛋能减少重复。
工具越强,专业判断反而越重要。系统可以更快地给出结果,但结果是否可信、偏差从何而来、能否回答生物学问题。这些仍然依赖专业训练与科学素养,无法被自动化取代,往往需要长期训练。
PhenoAssistant给我们的启示很清晰,未来的植物科研,可能会越来越呈现出”研究者 + 自动化分析系统”的协作格局。研究者负责提出问题、设计实验、判断结果;系统负责串联流程、整合工具、提升效率。
当AI越来越成熟,学生的培养方案会发生什么变化?欢迎留言,AI时代的植物科研该朝什么模式发展。
AgriPulse
文丨橙君
