夜雨聆风
夜雨聆风





AI进阶!9种RAG架构
环境:Spring Boot 3.5.0
1. 简介
什么是RAG,它为何如此重要?
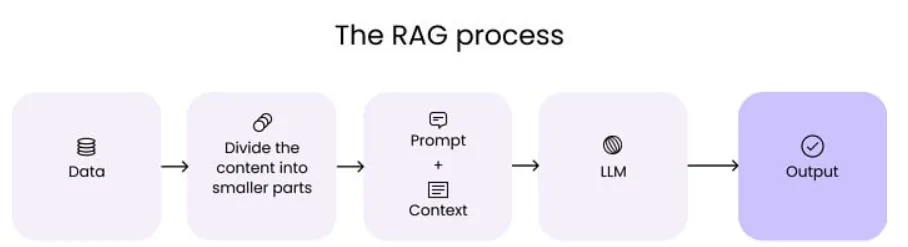
在我们深入探讨架构之前,先明确一下我们讨论的内容。
检索增强生成(RAG,Retrieval-Augmented Generation)通过让模型在生成回复之前参考外部知识库,来优化其输出结果。它不单纯依赖模型在训练过程中所学到的知识,而是从你的文档、数据库或知识图谱中提取相关且最新的信息。
具有流程如下:
-
当用户提出问题时,你的检索增强生成(RAG)系统首先根据该查询从外部来源检索相关信息
-
然后,它将原始问题与检索到的上下文相结合,并将所有内容发送给语言模型
-
该模型生成基于实际可验证信息的回复,而不仅仅是其训练数据(中的内容)
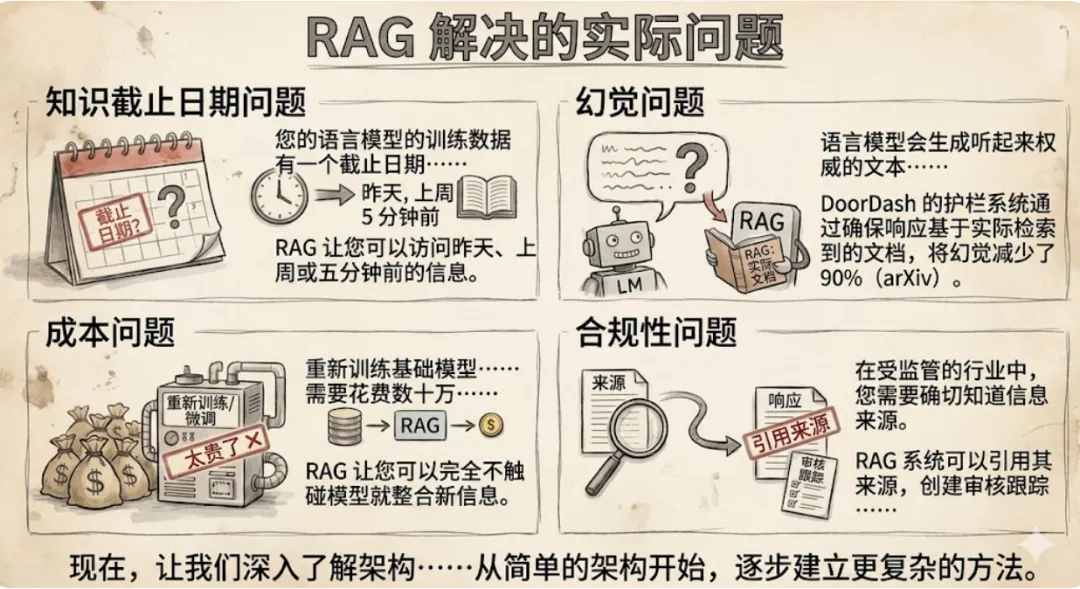
RAG实际解决的问题:
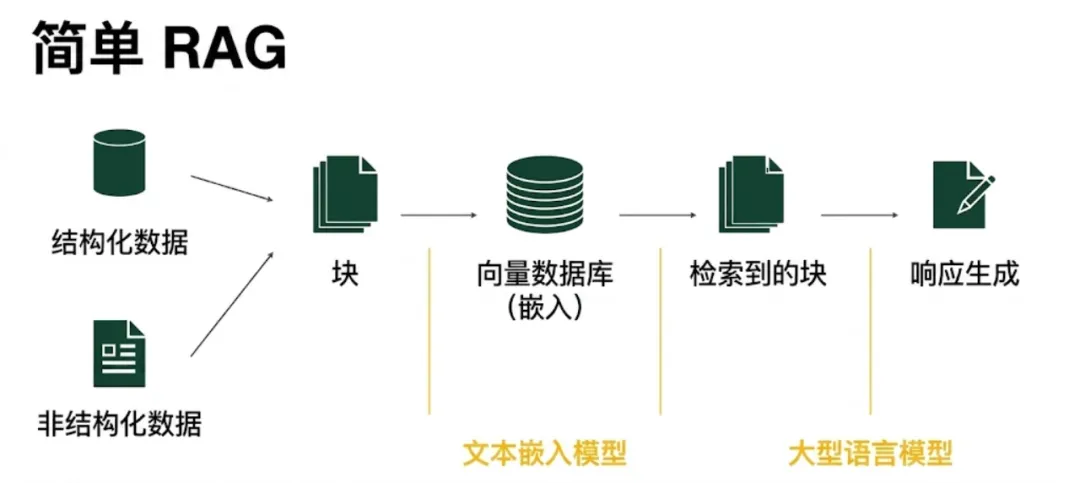
标准RAG就像是该生态系统的“入门程序(Hello World)”。它将检索视为简单的单次查找操作。它的存在是为了在无需微调的情况下将模型基于特定数据(进行训练/调整),但它假定你的检索引擎是完美无缺的。
它最适合用于风险较低且的环境。
其工作原理:
-
分块:将文档拆分为短小、易于处理的文本片段
-
嵌入:将每个片段转换为向量,并存储在数据库(如Milvus)中
-
检索:对用户查询进行向量化,并使用余弦相似度提取“前K个”最相似的片段
-
生成:将这些片段作为“上下文”输入到大语言模型中,以生成有依据的回复
现实示例:一家小型初创公司的内部员工手册机器人。用户询问:“我们的宠物政策是什么?”机器人会从人力资源手册中检索特定段落来回答。
优点:
-
延迟在秒级(很低)以下(即响应速度快)
-
计算成本极低
-
调试和监控简单
缺点:
-
极易受到“噪声”干扰(检索到不相关的片段)
-
无法处理复杂的、由多个部分组成的问题
-
如果检索到的数据有误,则缺乏自我纠正能力
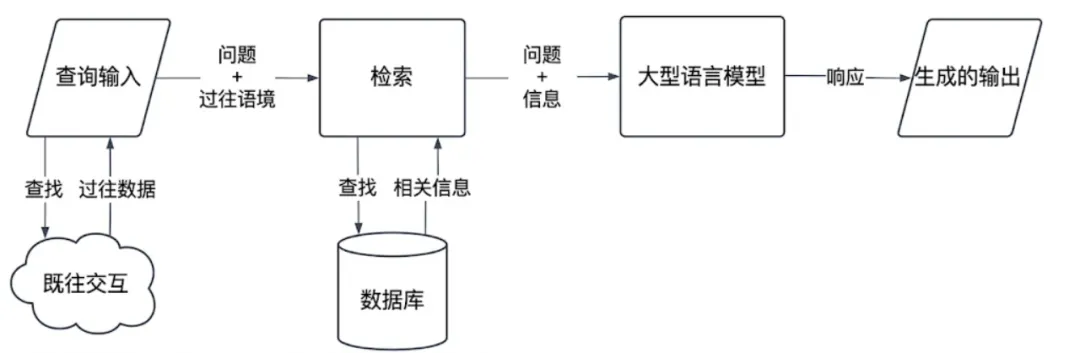
其工作原理:
-
上下文加载:系统存储对话中最近5到10轮的内容
-
查询改写:大语言模型根据历史记录和新查询生成一个“独立查询”(例如,“企业套餐的价格是多少?”)
-
检索:使用这个扩展后的查询进行向量搜索
-
生成:使用新的上下文生成答案
现实示例:一个软件即服务(SaaS)公司的客户支持机器人。用户说:“我的API密钥有问题。”然后接着问:“你能重置它吗?”系统知道“它”指的是API密钥。
优点:
-
提供自然、类人的聊天体验
-
避免用户重复表达(相同内容)
缺点:
-
记忆漂移:10分钟前的不相关上下文可能会干扰当前的搜索
-
由于“查询改写”步骤,导致Token成本更高。
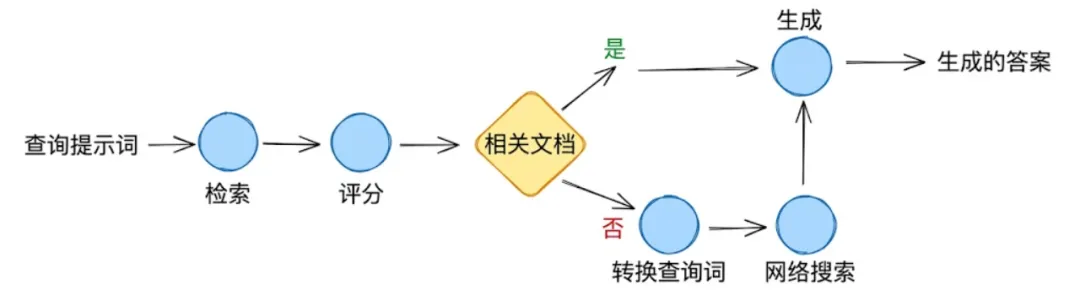
CRAG是一种专为高风险环境设计的架构。它引入了一个“决策关卡(决策门控/决策关卡机制)”,在检索到的文档到达生成器之前对其质量进行评估。如果内部搜索效果不佳,则会触发回退到实时网络(搜索)。
根据部署CRAG风格评估器的团队报告的内部基准测试结果,与简单基线相比,(语言模型的)幻觉现象已有所减少。
其工作原理:
-
检索:从内部向量存储中获取文档
-
评估:轻量级的“评分器”模型为每个文档片段分配一个分数(正确、模棱两可、错误)
-
触发门控(机制):
-
正确:进入生成器
-
错误:丢弃数据并触发外部API
-
合成:使用经过验证的内部数据或新的外部数据生成答案
实际案例:一个理财顾问机器人。当被问及某只股票的具体价格,而该价格未收录在其2026年数据库中时,CRAG会意识到数据缺失,并从财经新闻API中获取实时价格。
优点:
-
大幅减少(语言模型产生的)幻觉现象
-
弥合内部数据与现实世界实时事实之间的差距
缺点:
-
延迟显著增加(增加2-4秒)
-
需要管理外部API的成本和速率限制(调用次数限制)
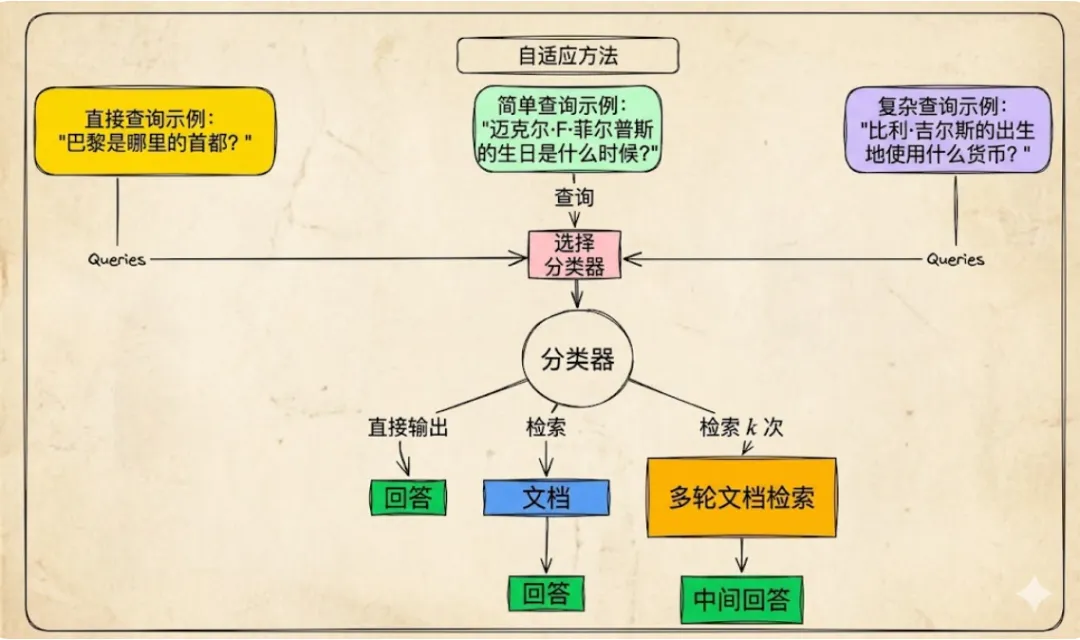
自适应RAG是“效率冠军”。它意识到并非每个查询都需要“大动干戈”(使用复杂方法处理)。它利用一个路由(选择)器来判断用户意图的复杂程度,并选择最经济、最快的方式(路径)来获取答案。
其工作原理:
-
复杂度分析:一个小型分类器模型对查询进行路由(分配处理路径)
-
路径A(不检索):对于大语言模型已经知晓的问候语或常识性问题(采用此路径)
-
路径B(标准检索增强生成):用于简单的事实查询(查找)
-
路径C(多步骤代理):适用于需要搜索多个来源的复杂分析性问题
现实示例:一个大学助手(聊天机器人)。如果学生说“你好”,它会直接回应。如果学生问“图书馆什么时候开放?”,它会进行简单搜索。如果学生问“比较过去5年计算机科学(CS)专业的学费情况”,它会触发复杂度分析(进而选择合适处理路径)。
优点:
-
跳过不必要的检索,大幅节省成本
-
简单查询的延迟(耗时)最优(较短)
缺点:
-
错误分类风险:如果系统认为一个难题很简单,就不会进行搜索(而直接回答,可能给出错误答案)
-
需要高度可靠的路由模型
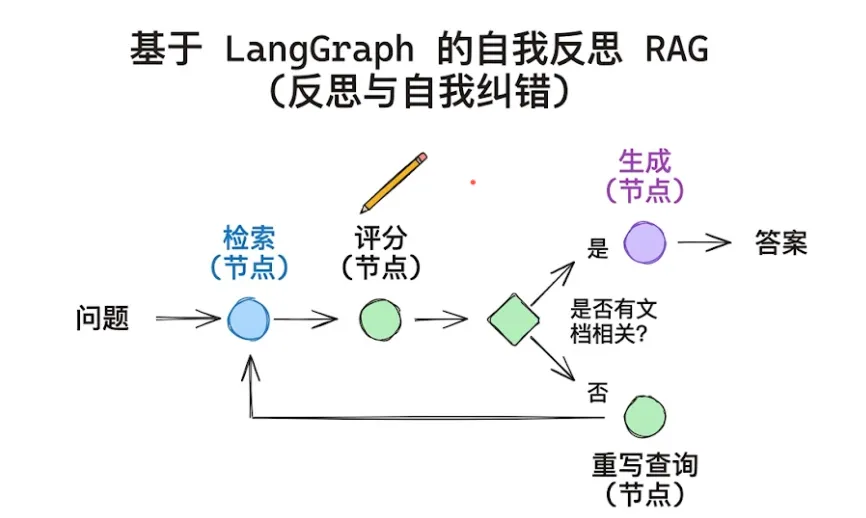
自我评审检索增强生成(Self-RAG)是一种复杂的架构,在这种架构中,模型被训练来评判(批判)自身的推理过程。它不仅进行检索;还会生成“反思标记(反思令牌/反思标识符)”,作为对其自身输出的实时审核(审查)。
其工作原理:
-
检索:由模型自身触发的标准搜索
-
带标记生成:模型生成文本以及一些特殊标记,如[IsRel](这相关吗?)、[IsSup](这一说法有依据吗?)和[IsUse](这有帮助吗?)
-
自我纠正:如果模型输出了一个[NoSup](无依据)标记,它会暂停,重新检索,并重写该句子
现实示例:法律研究工具。模型撰写了一个关于某个法庭案例的论断,意识到检索到的文献实际上并不支持该论断,于是自动搜索不同的判例。
优点:
-
事实“有据可依(基于事实)”程度最高
-
推理过程具有内置透明度(推理过程可解释、可追溯)
缺点:
-
需要专门的微调模型(例如Self-RAG Llama)
-
计算开销极高
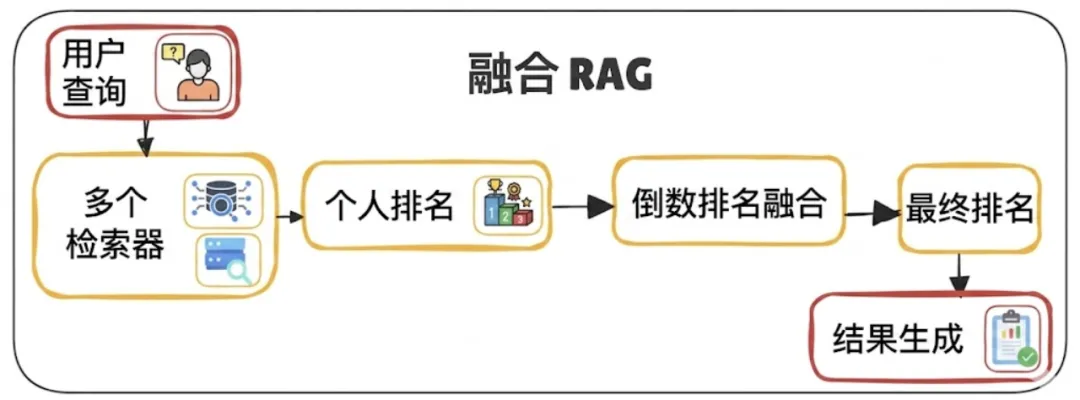
融合检索增强生成(Fusion RAG)旨在解决“歧义问题”。大多数用户都不擅长搜索。融合检索增强生成接收一个查询,并从多个角度对其进行审视,以确保高召回率(尽可能全面检索到相关结果)。
其工作原理:
-
查询扩展:针对用户的问题生成3-5个变体
-
并行检索:在向量数据库中搜索所有变体
-
互惠排名融合(Reciprocal Rank Fusion, RRF):使用数学公式对结果重新排序
-
最终排名:在多次搜索中排名靠前的文档将被提升至前列
现实示例:一位医学研究人员搜索“失眠治疗方法”。融合检索增强生成还会搜索“睡眠障碍药物”、“非药物失眠疗法”和“认知行为疗法治疗失眠(CBT-I)方案”,以确保不会遗漏任何相关研究。
优点:
-
召回率极高(能查到单个查询会遗漏的文档)
-
对用户表述不佳的情况具有较强的适应性(鲁棒性强)
缺点:
-
使搜索成本成倍增加(增加3到5倍)
-
由于需要重新排序计算,延迟(耗时)更高
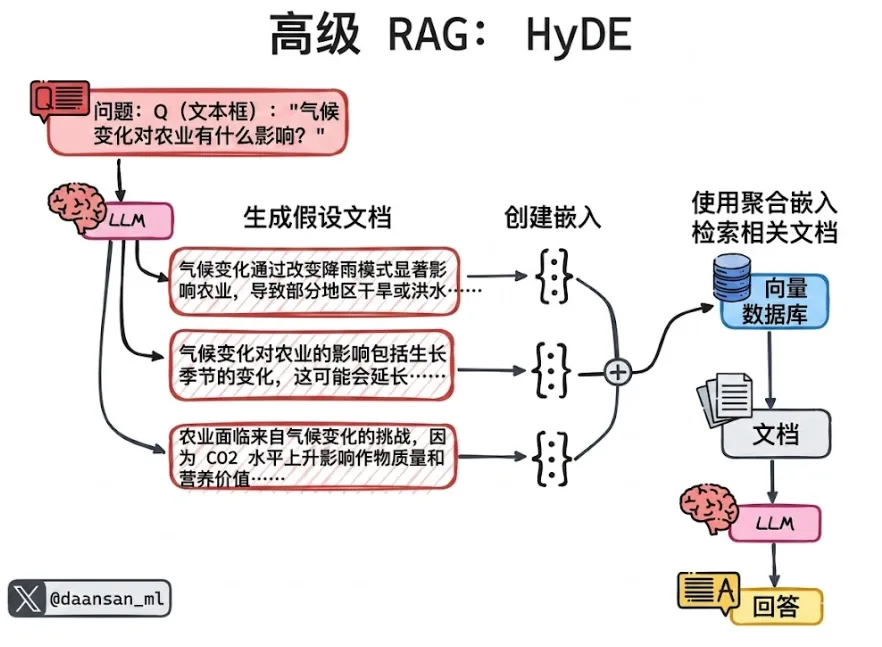
HyDE,是一种反直觉但绝妙的方法(模式)。它认识到“问题”和“答案”在语义上是不同的。它通过首先生成一个“虚假(假设性)”答案来在两者之间架起一座桥梁。
其工作原理:
-
假设:大语言模型针对查询编写一个虚假(假设性)答案
-
嵌入:将虚假答案向量化
-
检索:使用该向量查找与虚假答案相似的真实文档
-
生成:利用真实文档撰写最终回复
现实示例:用户提出一个模糊的问题,如“加州那条关于数字隐私的法律”。HyDE编写一个关于《加州消费者隐私法案》(CCPA)的虚假摘要,用它来查找CCPA的实际法律条文,并提供答案。
优点:
-
显著提升对概念性或模糊查询的检索效果
-
无需复杂的“代理(智能体/处理程序)”逻辑
缺点:
-
偏差(偏见)风险:如果“虚假答案”从根本上是错误的,那么搜索将会被误导
-
对于简单的事实查询(例如,“2加2等于多少?”)效率不高
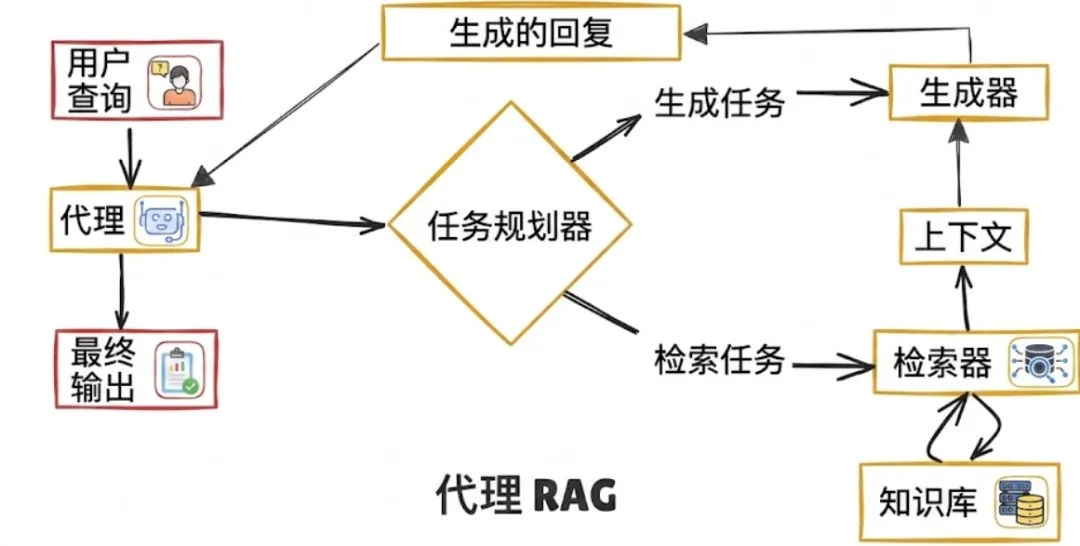
它不再盲目地获取文档,而是引入了一个自主代理(智能体),该代理在生成答案之前会进行规划、推理,并决定如何以及从哪里检索信息。它将信息检索视为研究过程,而非简单的查找过程。
其工作原理:
-
分析:代理首先解读用户查询,并确定该查询是简单问题、多步骤问题、模糊问题,还是需要实时数据的问题
-
规划:它将查询分解为子任务,并制定策略。例如:是否应先进行向量搜索?网络搜索?调用应用程序接口(API)?还是提出后续问题?
-
执行:代理通过调用向量数据库、网络搜索、内部API或计算器等工具来执行这些步骤
-
迭代:根据中间结果,代理可能会优化查询、获取更多数据或验证信息来源
-
生成:一旦收集到足够的证据,大语言模型就会生成一个有依据、上下文感知的最终回复
现实示例:用户问:“根据印度法规,金融科技应用程序使用大语言模型进行贷款审批是否安全?”
优点:
-
可处理复杂、多部分(多环节)及存在歧义的查询
-
通过验证和迭代减少幻觉(不实信息)现象
-
可访问实时和外部数据源
-
更适应不断变化的情境和需求
缺点:
-
由于多步骤执行,延迟(耗时)更高
-
运行成本高于简单的检索增强生成(RAG)
-
需要谨慎地进行工具和代理(智能体)协调编排
-
对于直接的事实性查询而言过于复杂(大材小用)
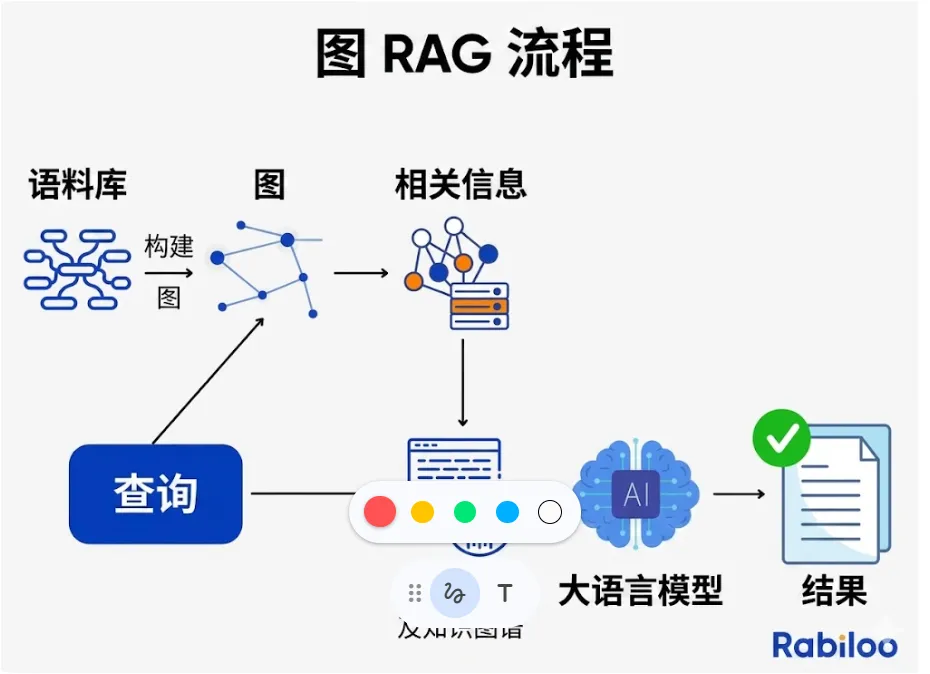
所有先前的架构都是基于语义相似性来检索文档,而图检索增强生成(GraphRAG)则是检索实体以及实体之间的明确关系。它不再问“什么文本看起来相似”,而是问“什么(事物)是相互关联的,如何关联?”
其工作原理:
-
图构建:将知识建模为一个图,其中节点是实体(人、组织、概念、事件),边是关系(影响、依赖、资助、监管等)
-
查询解析:分析用户查询,以识别关键实体和关系类型,而不仅仅是关键词
-
图遍历:系统遍历该图,以找到跨多跳连接实体的有意义的路径
-
可选混合检索:图检索通常与向量搜索结合使用,以在非结构化文本中定位实体
-
生成:大语言模型将发现的关系路径转换为结构化的、可解释的答案
现实示例:查询:“美联储利率决定如何影响科技初创企业的估值?”
图检索增强生成(GraphRAG)遍历:
-
美联储 → 利率决策 → 加息
-
加息 → 影响 → 风险投资(VC)资金供给
-
风险投资供给减少 → 影响 → 早期阶段(企业)估值
-
科技初创企业 → 由……资助 → 风险投资
答案源于关系链,而非文档相似度。
其不同之处在于:
向量检索增强生成(Vector RAG):“哪些文档与我的查询相似?”
图检索增强生成(GraphRAG):“哪些实体重要,它们如何相互影响?”
这使得图检索增强生成在因果推理、多跳推理(跨多步推理)和确定性推理方面要强大得多。
在确定性搜索任务中,将图检索增强生成与结构化分类法相结合的系统准确率已接近99%。
优点:
-
擅长因果推理
-
由于存在明确的关系,输出结果具有高度可解释性
-
在结构化和规则繁杂的领域中表现优异
-
减少因语义相似性导致的误报(错误结果)
缺点:
-
构建和维护知识图谱的前期成本高
-
构建图谱的计算成本可能很高
-
随着领域变化更难发展(演化/迭代)更新
-
对于开放式或对话式查询而言过于复杂(大材小用)
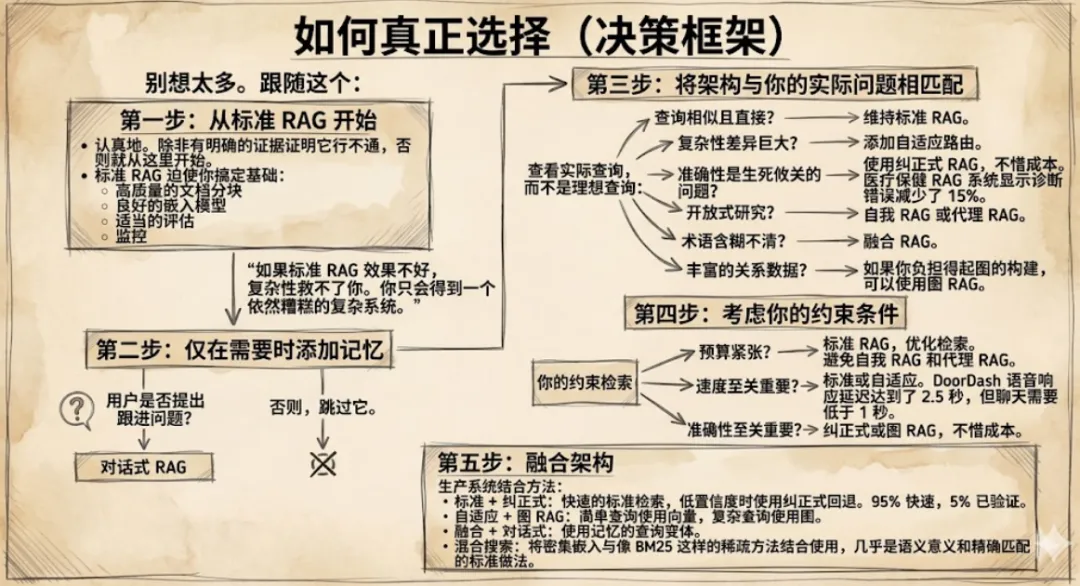
如何真正做出选择(决策框架)
高级开发!Spring Boot 动态控制 Controller 接口新方法
告别事务超时!Spring Boot 构建 SQL 超时自动重试机制
效率提升300%!Spring Boot 单接口动态实现6种数据格式
Spring Boot+WebSocket+Redis:毫秒级实时在线系统
惊爆!Spring AI 引入 Agent Skills 标准,AI 智能体开发要变天啦!
动态JSON不要再使用Map!Spring Boot + JsonNode完美解决
性能优化!Spring Boot 弃用 Jackson,性能提升50%