 夜雨聆风
夜雨聆风





工业软件最容易被忽略的坑:告警疲劳

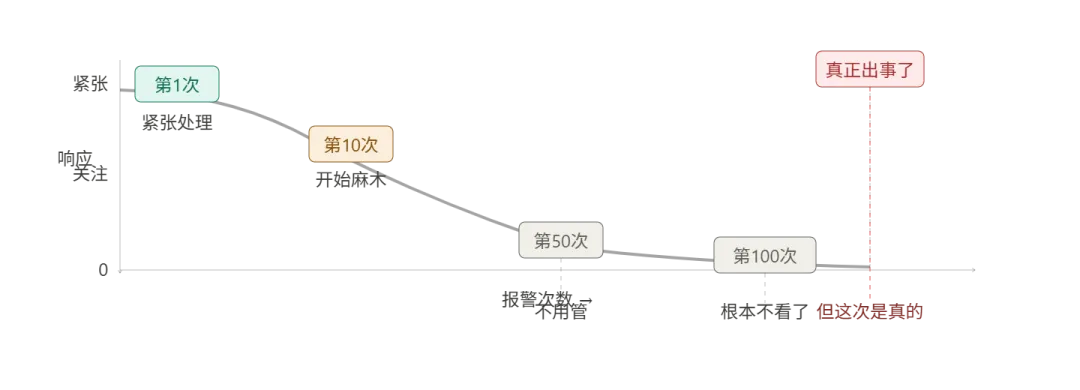
那条产线的报警,响了三个月没人理。
不是没人看到。每天都看到。屏幕右下角弹窗,三色灯闪,蜂鸣器每隔几分钟叫一声。操作工知道,班长知道,工程师也知道。
但大家发现,这个报警出现之后产线照样跑,不处理也没事,过一会儿系统自己就恢复了。
于是三个月里,没有人处理过它一次。
第四个月的某天,同样的报警又响了。操作工习惯性地扫了一眼,继续干活。
但这次不一样。这次是真的出问题了——上传通道彻底断了,当班两个小时的数据全部积压,没有一条传到平台。
发现的时候,已经是下班交接才对上账的。
这就是告警疲劳。它不是一天形成的,是被系统一次次”狼来了”训练出来的。
报警是怎么失去信任的
很多系统做报警时,信奉一个原则:能报就报。
看起来监控很全面。但现场跑一段时间之后,问题来了:
一天几十条报警,大部分过一会儿自己就好了,不处理也不影响生产。
于是现场开始用经验过滤:这个不用管,那个等会儿再说,这个经常有,那个重启就好。
但这不是系统在管理风险,是人在硬扛系统设计缺陷。
真正危险的时刻是:某天那个”不用管的报警”背后真的出问题了,但现场已经形成了条件反射——看到它就忽略。
报警系统还在响,但它已经死了。
根本原因:小事和大事长得一样
告警疲劳的根源只有一个:报警没有分级。
纸量不足是红色弹窗,PLC 断线也是红色弹窗。自动重试是蜂鸣,数据库写入失败也是蜂鸣。普通提醒和停线故障挂在同一个列表里。
系统没有帮人区分风险,现场当然会疲劳。
成熟的报警至少要分三类:
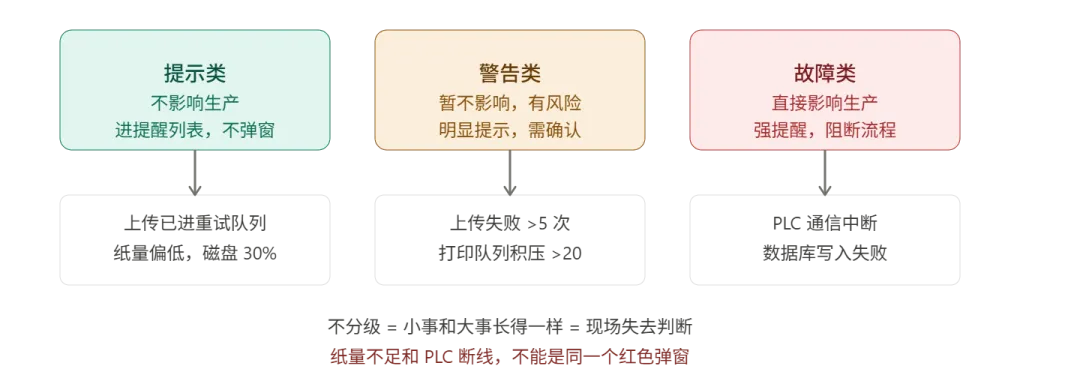
上传已进重试队列、打印机纸量偏低、磁盘空间低于 30%。
进提醒列表,不弹窗,不蜂鸣。让现场知道,但不打断节奏。
上传失败连续超过 5 次、打印队列积压超过 20 条、PLC 响应时间持续升高。
明显提示,要求有人确认。暂时不停产,但已经有风险了。
PLC 通信中断、数据库写入失败、打印机离线且任务无法完成、剔除机构无响应。
强提醒,可以阻断流程,必须人工处理后才能恢复。
分了级,现场就有判断了——提示类扫一眼,警告类要跟进,故障类立刻停下来处理。不会再用经验猜”这个要不要管”。
分级还不够——报警必须能闭环
很多系统只有”报警发生”,没有”报警处理状态”。报警弹出来之后,没人知道它后来怎么样了。
这会带来一个问题:大家都看到了,大家都以为别人会处理,最后没人处理。
还有一个更隐蔽的问题:设备恢复了,业务没恢复。
如果系统只判断设备状态恢复就关闭报警,业务隐患就这么留下来了。
真正的闭环,需要报警变成一张可跟踪的任务卡:

一个完整的报警应该能回答:发生了什么,影响了哪个业务对象,责任人是谁,当前处理到哪一步,恢复条件是什么。
不是弹窗喊一声”出事了”,然后消失。
还有两件容易被忽略的事
报警要能合并。 网络断了一下,系统可能同时抛出 PLC 超时、打印服务不可达、上传失败、设备心跳丢失——四条独立报警。现场被刷屏,根因其实只有一个。成熟的系统应该能识别根因,把影响范围收拢在一条报警下面,而不是制造四倍的噪音。
报警要有抑制机制。 某个接口每秒失败一次,如果每次都弹窗,几分钟就能让现场彻底放弃看报警。正确的做法是:第一次失败记录,连续失败五次警告,持续三十秒升级为报警,恢复后提示已恢复。同一个问题,只轰炸一次。
文章开头那条产线,后来复盘的时候发现,那个”不用管的报警”在三个月里其实已经出现了两次真正的上传异常,只是数据量很小,没有被察觉。
第三次量大了,才被发现。
如果当时报警有分级,上传失败超过五次会升到警告,有人确认,有责任人跟进,也许第一次就能拦住了。
但系统把它和纸量不足做成了同一个红色弹窗。