 夜雨聆风
夜雨聆风





AI每日新闻——蚂蚁百灵Ling-2.6-1T正式开源:万亿参数不是终点,“快思考”才是真正的杀招
大家好,我是AI视听小学生。
今天,开源圈炸了一颗重磅炸弹。
蚂蚁百灵大模型,正式把自家万亿参数级旗舰模型 Ling-2.6-1T 推向了开源世界。
注意,不是几十亿参数的轻量版,不是阉割过的体验款,是完整的、万亿参数规模的旗舰模型,直接开源。
这件事本身就已经足够震撼了。但真正让我觉得值得单独拿出来聊的,不是参数规模,而是它背后那套完全不一样的技术思路。
一句话概括就是,别人还在拼谁想得更久,蚂蚁已经开始拼谁想得更快、更准、更省。
万亿参数不稀奇,稀奇的是怎么用这万亿参数
先说一个行业现状。
过去一年多,大模型军备竞赛有一个非常明显的趋势,就是疯狂拉长思考链。模型遇到问题,先想个几千上万token,反复推理、反复验证,最后给你一个答案。
效果确实好,但问题也很现实。
慢,贵,耗资源。
你让一个万亿参数模型用超长思考链跑一遍复杂任务,光是推理消耗的算力成本,就足以劝退绝大多数开发者和企业。
这就是当下大模型落地最大的矛盾,模型越来越聪明,但用起来越来越贵。
蚂蚁百灵这次的 Ling-2.6-1T,走了一条完全不同的路。
它不追求超长思考链,不搞参数规模的无效冗余,而是通过一套叫做 MLA 与 LinearAttention 混合架构的技术方案,实现了所谓的「快思考」机制。
什么意思?
简单说就是,同样一个复杂问题,别的模型可能需要反复「深呼吸」想很久才给你答案,Ling-2.6-1T 能够快速抓住关键路径,高效输出结果,而且质量不打折。
这个思路转变,看起来只是技术细节的调整,实际上是对整个行业方向的一次重新定义。
实测数据说话,四分之一的成本,对标GPT-5.4的智能
光讲架构创新还不够,得看实测。
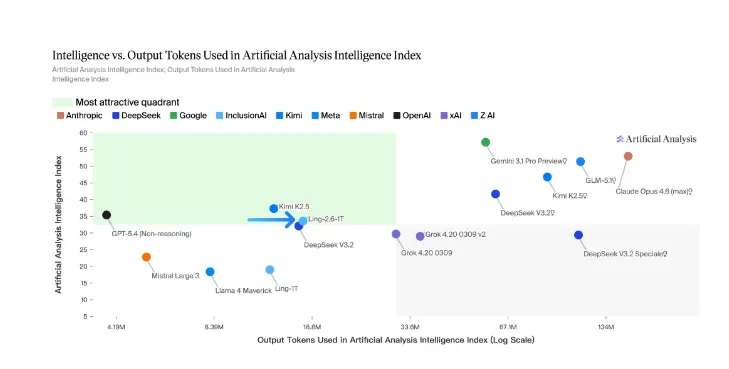
在 Artificial Analysis 的完整评测中,Ling-2.6-1T 交出了一份相当亮眼的成绩单。
几个核心数据,直接感受一下冲击力。
-
Token效率极高,仅需 16M tokens 即可完成全部评估任务
-
输出成本,只有同类万亿参数模型的约四分之一
-
综合智能水平,直接对标 GPT-5.4 非推理模式
-
在推理、代码实现、工具调用、多步任务执行等实战场景中,均达到开源领域 SOTA 水平
这几个数字放在一起看,信息量极大。
成本降到四分之一,意味着什么?意味着原来只有大厂才玩得起的万亿参数模型,现在中小团队、独立开发者也有机会跑起来了。
对标 GPT-5.4,意味着什么?意味着开源社区第一次在万亿参数级别,真正摸到了闭源顶级模型的门槛。
而这两件事同时发生在一个模型身上,才是最值得关注的。
不是更贵才能更强,而是更聪明地花每一分算力,也能做到顶级水平。
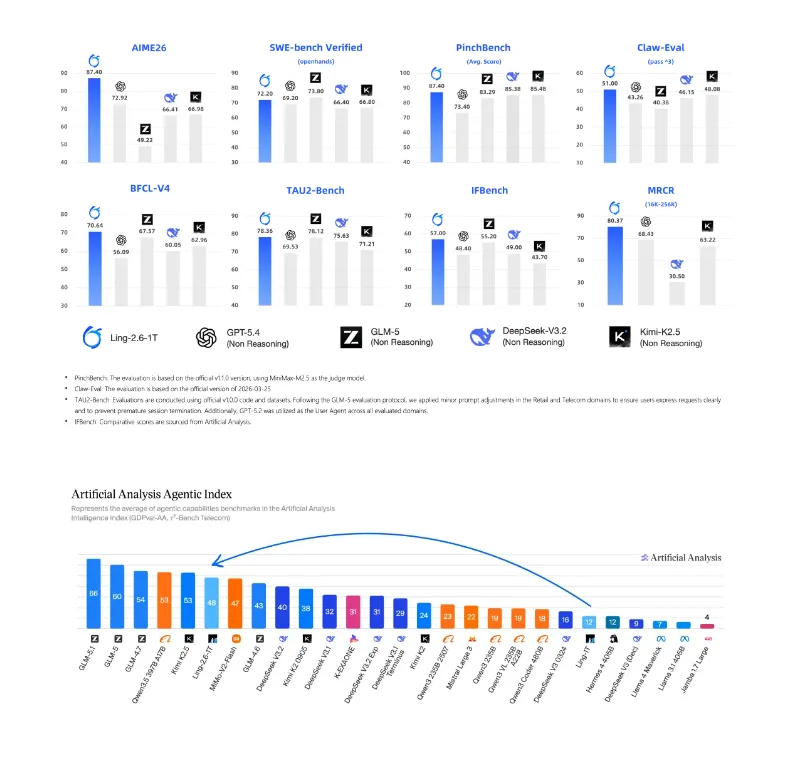
开发者最关心的,它到底能干什么?
参数和跑分只是入场券,真正决定一个模型价值的,是它在真实业务场景里能不能扛住。
Ling-2.6-1T 在这方面做了非常系统性的优化,尤其针对开发者最头疼的几个痛点。
第一,指令执行能力大幅增强。
不是那种「你说东它偏要往西绕一圈再回来」的执行,而是精准理解复杂指令,直接给出符合预期的输出。这对于搭建 AI Agent 的开发者来说,是最底层的刚需。
第二,工具调用与多步任务执行。
在蚂蚁内部的实际应用中,Ling-2.6-1T 已经能够自主完成这些任务——
-
用户反馈的自动分类
-
系统日志的智能分析
-
代码Bug的自动修复
这不是demo级别的演示,是真正跑在生产环境里的能力。
第三,262k 超长上下文支持。
262k 是什么概念?大约相当于一次性塞进去一本中等篇幅的技术文档,模型能完整理解并在此基础上执行任务。对于需要处理长文档、长对话、长流程的企业级场景,这个能力几乎是刚需。
你如果正在做 AI Agent 开发,或者在企业内部推动 AI 落地,应该能立刻感受到这几项能力的分量。
这次开源,真正改变的是什么?
说实话,2025年到现在,开源模型已经不少了。
但大多数开源模型,要么参数规模有限,要么在实际应用中跟闭源模型差距明显,要么开源了但跑起来的成本高到离谱。
Ling-2.6-1T 这次开源,同时解决了三个问题。
参数规模到万亿级,智能水平不打折。 推理成本大幅压缩,中小团队用得起。 实战能力经过生产验证,不是实验室产物。
这三件事叠在一起,给整个行业释放了一个非常清晰的信号——
万亿级智能,不再是少数玩家的专属资源。
对于开发者来说,这意味着你手里突然多了一个真正能打的开源底座。你不需要再为了用上顶级模型而被迫绑定某个闭源API,不需要再在「效果」和「成本」之间反复做痛苦的取舍。
对于整个 AI Agent 生态来说,这可能是一个关键拐点。
过去大家做Agent,最大的瓶颈不是想法不够,而是底层模型的指令执行、工具调用、长上下文能力跟不上。现在这些能力以开源的方式释放出来,Agent开发的门槛会被实质性拉低。
一个更深层的趋势判断
最后聊一个我自己的观察。
这两年大模型的竞争,正在从**「谁的参数多」转向「谁的智效比高」**。
什么叫智效比?就是同样的智能水平,谁能用更少的资源、更快的速度、更低的成本实现。
这个趋势不是蚂蚁一家在推动,但 Ling-2.6-1T 用万亿参数级别的开源实践,把这个趋势具象化了。
它在告诉整个行业一件事——
大模型的下半场,不是比谁更重,而是比谁更快、更准、更轻。
如果你是开发者,现在是认真研究这个模型的最佳时机。如果你是企业决策者,这次开源可能会直接影响你下一阶段的AI基础设施选型。
万亿参数的门,已经推开了。
关键是,你准备用它来做什么?
觉得这篇有价值,随手转发给你身边正在做AI开发的朋友,可能对他来说是一个重要信号。
Tips:有你们的支持,就是我最大的动力~~~