 夜雨聆风
夜雨聆风





当企业不再买软件,而是买结果:AI 服务化浪潮里,一个被忽视的基础设施机会

苏州工业园区,有一家做精密零部件的中小工厂,年产值大概两个亿。老板去年算了一笔账:厂里每年花8万块钱买 ERP 和视觉检测系统的授权,同时花60多万养着一个5人规模的质检外包团队,负责审核供应商来料、生成检测报告、处理客诉单据。
软件那8万块,年年都在付,真正让老板头疼的是那60多万的人工成本——人难招、人难管、人还会出错。他问了一个很直接的问题:“我能不能不养这5个人,而是直接花钱,让AI帮我把这些事干完?”
越来越多的企业都在思考,智能体是不是能够完成更多的服务,交付更多的结果。
今年 3 月,红杉发布了一篇在硅谷创投圈引发广泛讨论的文章《Services: The New Software》,核心判断极其锋利:下一家万亿美元公司,将是一家披着服务公司外衣的软件公司。
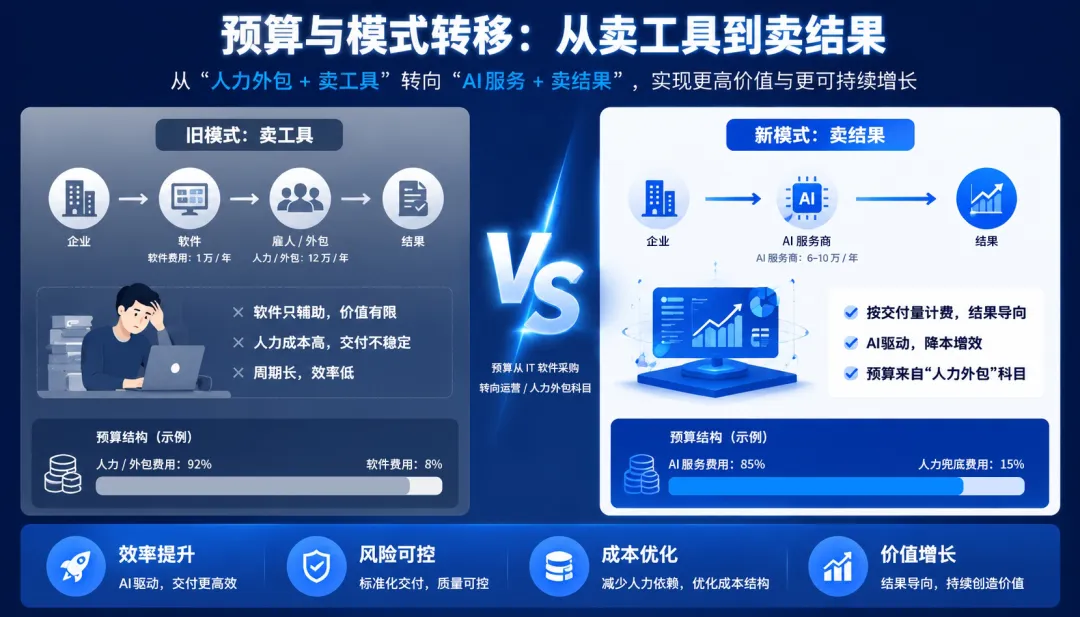
翻译过来就是:AI 的商业模式,正在从”卖工具”转向”卖结果”。而这两者之间的市场天花板,差了整整一个数量级。
说白了,AI 的战场,正在从1万块钱的软件预算,转向12万块钱的人力预算。问题是:企业想要的是“被完成的工作”,市场能给的却仍然是“更好用的工具”。这中间缺了什么?
01
新需求:企业要的不是软件,是“把活干了”
过去十年,制造业企业买 ERP、买 MES、买质检系统,本质上买的是“使用权”。企业自己招人,用这些工具来干活。软件厂商的收入来自 license,卖的是“你用软件的权利”,至于活干没干完、干得好不好,那是企业自己的事。
但现在情况变了。
一方面,人力成本持续上涨,年轻人不愿意进工厂做重复性文职工作,外包团队也在涨价。另一方面,很多制造业企业已经接受了外包模式——报关外包、代理记账、质检外包、能耗审计外包,这些预算本来就存在,而且规模远大于软件采购预算。
红杉给了一个很直观的数据:每花1美元在软件上,就有6美元花在对应的服务上。在制造业的质检、供应链审核、单据处理这些环节,这个比例可能更高。因为软件一年可能就几万块,但养人或者外包,一年可能是几十万甚至上百万。
所以新需求的真实面貌是:企业不再愿意为“使用软件的权利”付费,它们愿意为“工作被完成的结果”付费。
比如:
-
一家电子厂每个月有 200 家长尾供应商,合同条款、报价单、交货周期需要持续比对审核,厂里不想养 3 个采购专员专门干这个;
-
一家医疗器械出口企业,每季度要处理上千份报关单据和合规文件,出错就被海关扣货,但招一个熟手越来越贵;
-
一家新材料公司,每年要做几十份能耗审计和碳排放报告,专门雇人写报告不划算,交给外包公司又觉得质量不稳定。
这些工作的共同特点是:规则复杂但终究有章可循,需要大量人力但价值密度不高,企业已经外包但成本还在涨。老板们真正想买的是:有人(或者某种新形态的服务商)能稳定、便宜、不出错地把这些活包了。
预算来源也变了。以前买软件走 IT 部门的预算,现在买“结果”走的是运营部门或总经理直接管控的人力外包预算。这是两个完全不同的决策链条,也意味着 AI 公司如果还在 IT 部门门口推销“更智能的工具”,其实敲错了门。
02
新供给:应该出现一种“AI 原生服务商”
如果需求是“把活干了”,那供给端应该提供什么?
显然不是传统 SaaS 公司——它们卖的是账号和 license,交付的是功能列表,不承担结果责任。你买了财务软件,账还是得自己找人记。
也不是传统外包公司——它们卖的是人头和时间,按人数、按月、按项目计费。5 个人干 5 个人的活,10 个人干 10 个人的活,无法实现边际成本递减。外包公司本质上还是人力中介。
真正匹配新需求的,应该是一种“AI 原生服务商”: 它用 AI 完成绝大部分规则复杂的重复性工作,用极少数人类专家把控关键判断,按实际交付的结果(处理了多少张单据、审核了多少份合同、生成了多少份报告)收费。
它的组织形态可能很轻。一个懂行业规则的专家,加上一套 AI Agent 团队,就能同时服务十几二十家企业。我们可以把它叫做 OPC(One Person Company)——一人公司。这不是比喻,而是正在发生的现实:在美国,已经有律师用 AI 团队同时服务 50 家企业的合同审核;在中国,也有数据科学家用自动化工具同时给多家工厂做供应链分析。
这种新供给在理论上非常诱人:
-
成本结构不同:AI 处理第1份单据和第1000份单据的边际成本几乎一样,规模越大越便宜;
-
交付速度不同:7×24小时运行,不会因为员工请假、离职、情绪波动而中断;
-
质量一致性不同:规则一旦确定,执行标准统一,不会像人工那样今天一个样、明天一个样。
但问题在于:这种新供给,在今天的中国市场上,几乎找不到。
不是没人想做,而是想做的人发现,从“有一个好想法”到“能稳定交付结果”,中间隔着一道深沟。
03
需求侧的四个卡点:企业想要投入AI,却不敢投入?
企业老板们嘴上都说“愿意试试 AI”,但真到了掏钱的环节,预算往往还是流向了传统外包公司。为什么?因为需求侧有四个实实在在的卡点,把 AI 服务预算锁死了。
第一个卡点:不知道怎么验证。
买软件很简单,开个账号试用两周,功能有没有一目了然。但买“AI 替代人工的结果”,你要验证的是准确率、召回率、极端情况的处理能力,以及出错以后怎么办。比如让 AI 审核报关单,漏掉一个关键条款可能导致整批货被扣,这个风险怎么试?传统 POC(概念验证)只能跑几个样本,真实业务场景的复杂度是 POC 的 100 倍。企业需要一个低成本、低风险的“试金石”,但市场上几乎没有这样的机制。
第二个卡点:出了事谁负责?
传统外包有明确的法律责任主体。如果外包团队审核报关单出错,合同里写得清清楚楚,外包公司担责。但如果换成 AI 服务,一旦出错,是 AI 服务商赔、使用企业自己认栽,还是平台方兜底?现有的法律框架和商业保险体系,对这种新型服务关系几乎空白。老板们一想“万一出事找不到人背锅”,宁可继续用贵一点但“看得见摸得着”的人工外包。
第三个卡点:数据给出去,会不会被反噬?
制造业的质检数据、供应商报价、客户名单,都是命根子。企业担心:我把数据给你训练 AI,模型学会了,你是不是也能服务我的竞争对手?甚至你自己变成我的竞争对手?在缺乏“数据不出域”或“隐私计算”成熟方案的情况下,很多企业宁愿忍受高成本的人工外包,也不愿承担数据泄露的风险。
第四个卡点:换掉老供应商,比想象中难。
理论上,替换外包供应商只是换一个乙方,应该比裁掉内部员工容易。但实际情况是,现有外包供应商往往跟采购部门合作多年,关系盘根错节。引入 AI 服务商意味着打破现有利益格局,采购部门的决策风险远大于技术风险。很多老板即使心里认可 AI,也会卡在“怎么跟现在的外包商分手”这一步。
这四个卡点叠加,造成了一个尴尬的局面:企业非常想要 AI 替代外包带来的降本增效,但预算被锁在了一个“不敢动”的状态里。
04
供给侧的四个瓶颈:为什么想做的人,做不出来?
与此同时,供给侧也是一片“看起来热闹,实际上难产”的景象。大量 AI 从业者看到了“服务即软件”的机会,但几乎都在同一个地方跌倒。
第一个瓶颈:没有“生产系统”。
很多人以为,做一个能替代人工的 AI 服务,就是调个大模型、套个壳、做个聊天界面。但实际上,从企业的原始数据接入,到特征工程、模型训练、API 部署、结果交付、客户反馈、模型迭代,需要一条完整的工程流水线。大多数 AI 应用团队只有“做模型”的能力,没有“开工厂”的能力。他们能做出一个很漂亮的 demo,但无法做出稳定、可扩展、可监控的生产级服务。Demo 和量产之间,差着一整套 DevOps、数据工程、质量监控和安全合规的体系。
第二个瓶颈:找不到合适的人。
既懂 AI 又懂制造业质检流程、既会调模型又懂保险核保规则、既能写代码又懂报关单逻辑的人,极其稀缺。传统公司养不起这类人——年薪百万可能都留不住,因为市场上抢得太凶。而 OPC 模式又要求他们以“一人公司”的形式独立生存,这对个人的全栈能力要求极高:既要懂业务,又要懂技术,还要懂交付、懂客户沟通。这样的人,万里挑一。
第三个瓶颈:冷启动太难。
即使你做出了一个能替代人工的 AI 服务,怎么找到第一个客户?制造业企业不会上百度搜“AI 质检服务”,它们信任的是熟人介绍、行业协会背书、政府推荐。一个没背景、没案例的 OPC 创业者,连厂门都进不去。新供给缺乏一个“被看见、被信任”的渠道,这是比技术更难逾越的障碍。
第四个瓶颈:从项目制到产品化,有一道死亡谷。
很多 AI 团队以“项目制”切入,为单家企业定制开发。但项目制是陷阱——每接一个新客户,都要重新理解需求、重新处理数据、重新调整模型,边际成本不降反升。要实现从“项目”到“产品化服务”的跃迁,需要标准化的数据接口、通用化的模型架构、自动化的交付流程——这恰恰是个人或小团队最缺乏的基础设施。
这四个瓶颈导致了一个残酷的现实:想做 AI 服务的人很多,但能稳定交付结果、能规模化扩张的供给,几乎为零。
05
供需断裂处,出现了一个基础设施层的机会
当需求侧“不敢买”和供给侧“做不出”同时发生时,市场就会出现一个典型的空白地带:需要有人来做连接层,不是做应用,不是做模型,而是做让 AI 服务能够规模化生产与可信交付的基础设施。

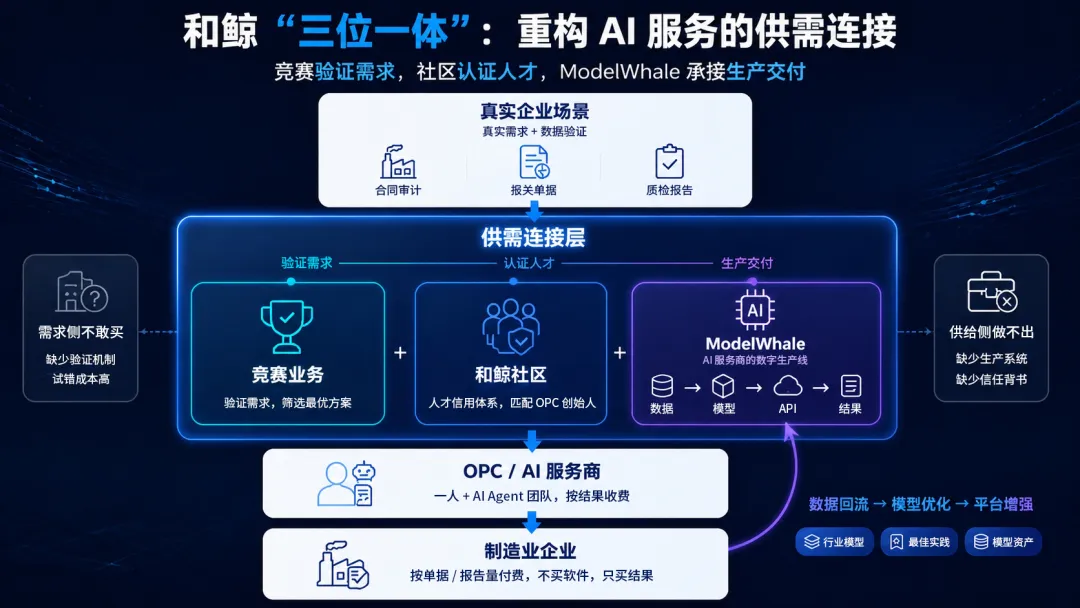
在调研中,我们发现和鲸科技正在尝试一种独特的“三位一体”架构。它不像大厂那样卖算力,也不像应用公司那样直接抢客户,而是卡在供需断裂的缝合点上,试图同时解决“需求侧不敢买”和“供给侧做不出”的问题。
ModelWhale:
给 AI 服务商造一条“数字生产线”
和鲸的核心产品 ModelWhale,过去常被看作数据科学家的开发工具。但如果放在“服务即软件”的语境下看,它的角色更像是一家 AI 服务商的“生产操作系统”。
它解决的是供给侧最痛的“生产系统缺失”问题。一个垂直领域的 OPC 创业者,不需要自己搭建数据 pipeline,不需要自己维护模型训练集群,不需要手写 API 部署脚本。在 ModelWhale 上,他可以一站式完成从数据接入到结果交付的全链路。说白了,行业专家的门槛被大幅降低——你只需要懂业务规则,不需要懂工程化。
更重要的是,随着越来越多的 OPC 在 ModelWhale 上生产服务,平台会沉淀出行业特定的数据模板、模型架构和最佳实践。这种网络效应一旦形成,后来者的启动成本会越来越低,而平台的切换成本会越来越高。
和鲸社区:
解决“人从哪里来”和“怎么被信任”
和鲸社区聚集了大量数据科学从业者,但它真正的价值不是“人多”,而是建立了一种新型的能力信用体系。
社区里的项目作品、竞赛排名、开源贡献,构成了 OPC 创始人的“结果交付背书”。在 AI 服务化的早期阶段,企业不会信任一个陌生的“一人公司”,但会信任一个在公开竞赛中拿过名次、在社区里有持续产出记录的创业者。社区本质上是一个去中心化的能力认证与人才匹配市场,既解决了“复合型人才稀缺”的问题,也解决了“冷启动获客信任”的问题。
竞赛业务:
让企业敢试,让创业者获客
和鲸的竞赛业务,可能是三者中最独特的设计。它把企业的真实外包场景(比如“长尾供应商合同审计”、“医保编码自动化”)包装成公开的数据竞赛题目,用真实数据、真实评判标准,来验证“AI 替代人工”到底行不行。
这精准地刺破了需求侧的“验证困境”:企业不需要承担高昂的定制开发费用,就能在竞赛中看到多个团队用不同技术路线解决同一个问题,直观比较准确率、成本和可扩展性。对于优胜方案,企业可以直接转化为采购意向;对于 OPC 创业者,竞赛既是技术验证,也是免费的客户获取渠道。
而且,当政府或产业园区背书举办此类竞赛时,它天然地解决了“组织惯性”问题——不是企业自己冒险尝试新供应商,而是政府搭建了一个合规的试验场。这对打破采购部门的利益僵局非常有效。
06
为什么这个解法稀缺,而且可能有效?
市场上不缺 AI 工具,不缺数据科学家,也不缺产业需求。但同时解决“生产系统 + 人才信用 + 需求验证”这三件事的平台,几乎找不到。
大厂(阿里云、华为云)拥有算力和政企关系,但它们做的是“卖资源”的生意——卖算力、卖模型 API。它们与应用层存在潜在的竞争关系,很难真心实意地赋能第三方服务商。
垂直 AI 应用公司做的是“点状替代”,它们可能就是未来在 ModelWhale 上生长的 OPC,而不是平台本身。
传统外包巨头拥有客户关系和交付经验,但其组织形态、成本结构和利益格局,决定了它们很难自我革命去拥抱 AI 原生模式。
和鲸科技的稀缺性在于,它选择了“卖铲人”的位置,且不与应用层争利。它的客户不是最终的企业,而是那些想要替代传统外包的 OPC;它的收入不来自抢 OPC 的生意,而来自让 OPC 的生意能够成立。这种平台定位,在万亿级赛道中通常意味着最高的集中度和最深的护城河。
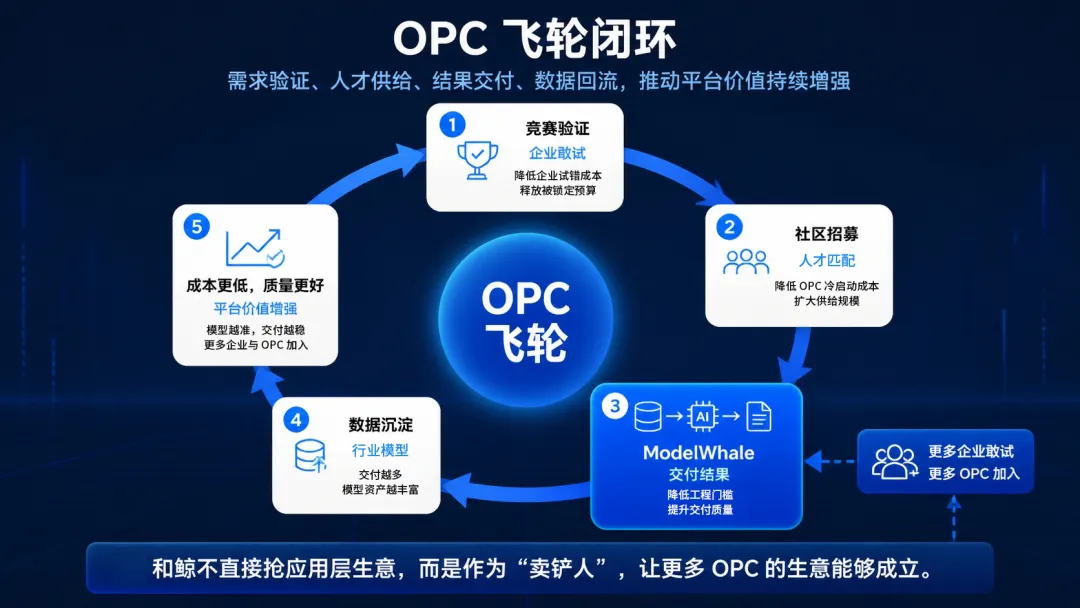
其有效性体现在飞轮设计上:
-
竞赛验证需求 → 降低企业的试错成本,释放被锁定的预算;
-
社区招募人才 → 降低 OPC 的冷启动成本,扩大供给规模;
-
平台交付结果 → 降低服务化的工程门槛,提升交付质量;
-
数据回流优化 → 行业模型越用越准,平台价值越滚越大。
如果这个飞轮在苏州这样的制造业强市跑通,复制成本会极低。长三角、珠三角的每一个制造业城市,都有同质化的外包需求与数字化转型预算。和鲸不需要自己去服务每一家工厂,它只需要让越来越多的 OPC 在平台上生长出来。
07
结语:窗口期很短,必须先把桥梁修好
红杉资本判断,2026 年是“自动驾驶原生”公司的窗口期。现有的 Copilot 工具厂商面临“替代自己客户”的转型困境,而没有历史包袱的新进入者,可以从第一天就直接卖结果。
但窗口期也意味着,基础设施层的卡位战将在未来 12 到 18 个月内决出第一批胜负。和鲸科技的“三位一体”架构,本质上是在 AI 服务化浪潮的早期,抢占了一个极其关键的生态位:让新需求敢买,让新供给能做。
AI 从 1 万的预算走向 12 万的预算的跃迁,不会自动发生。企业想要“买结果”的需求已经摆在那里,AI 原生服务商的供给也在萌芽,但两者之间缺的是一条可靠的通道。有人得先把桥修好,才能让两边的车跑起来。
和鲸科技想修的,就是这样一座桥。
推荐阅读



关注我们 了解更多科技信息