 夜雨聆风
夜雨聆风





代码并不廉价:AI 时代里软件基本功为何更重要

一个对你可能是安慰的消息
我有个消息要告诉那些觉得自己的技能在这个新时代不再有价值的人——这或许是一种安慰:我相信软件基本功现在比以往任何时候都更重要。
我是一名教师,最近在准备一门课程,叫做 “Claude Code for Real Engineers”。名字够挑衅吧。
为了准备这门课,我必须设计一份关于 AI 编程的课程大纲,这有点像噩梦,因为一切都在不断变化。AI 是一种全新的范式,我们当然要抛弃旧规则、引入新东西——围绕这种心态出现了一场”规约转代码”(spec-to-code)运动。
它的主张是:你写一份规约描述应用应该如何工作,然后用 AI 把它编译成代码;如果出了问题,你不去看代码,而是回到规约,改完再编译一次。
我试过。我跑了一遍,试着不去看代码,但我还是看了——第一遍跑出来是一回事,再跑一遍代码变得更糟,再跑一遍,更糟。我不停地运行编译器,最后得到的就是一堆垃圾。
那种”我们可以忽略代码,让代码自己管理自己”的想法,不过是另一个名字的氛围编程。
复杂性与软件熵
我当时并不愿意接受这个结论。我想:好,那我怎么修复编译器,让它不再每次都产出更糟的代码?于是我意识到:我得用英语向 LLM 解释什么叫”好的代码库”。
我翻出 John Ousterhout 的《软件设计的哲学》(A Philosophy of Software Design)。他给糟糕代码起了个名字——复杂性:任何与软件系统结构相关、使其难以理解和修改的东西。糟糕的代码库,就是难以修改的代码库;好的代码库,就是容易修改的代码库。
我又翻了《程序员修炼之道》(The Pragmatic Programmer),里面有一整章讲软件熵——事物趋向于灾难、彼此疏离、最终崩塌。这正是大多数软件系统的演化方式:每次你改代码,如果只盯着这一次改动,而不思考整个系统的设计,代码库就会越来越糟。
“spec to code”理念里的一切——你只需要不断重新运行编译器——都在制造更糟糕的代码。
代码并不廉价
推动”spec to code”运动的一个核心观点是:代码很廉价。
我不认为这是对的。事实上,糟糕的代码现在比以往任何时候都更昂贵。因为如果你的代码库难以修改,你就拿不到 AI 能给你的红利——AI 在好的代码库里表现得非常、非常出色。
这意味着好的代码库比以往任何时候都更重要,意味着软件基本功比以往任何时候都更重要。这就是这场演讲的论点。
下面我想谈几种具体的失败模式,以及如何通过翻回那些”老旧”的书、参考已经存在的好软件实践来避开它们。
失败模式一:AI 没在做我想要的事
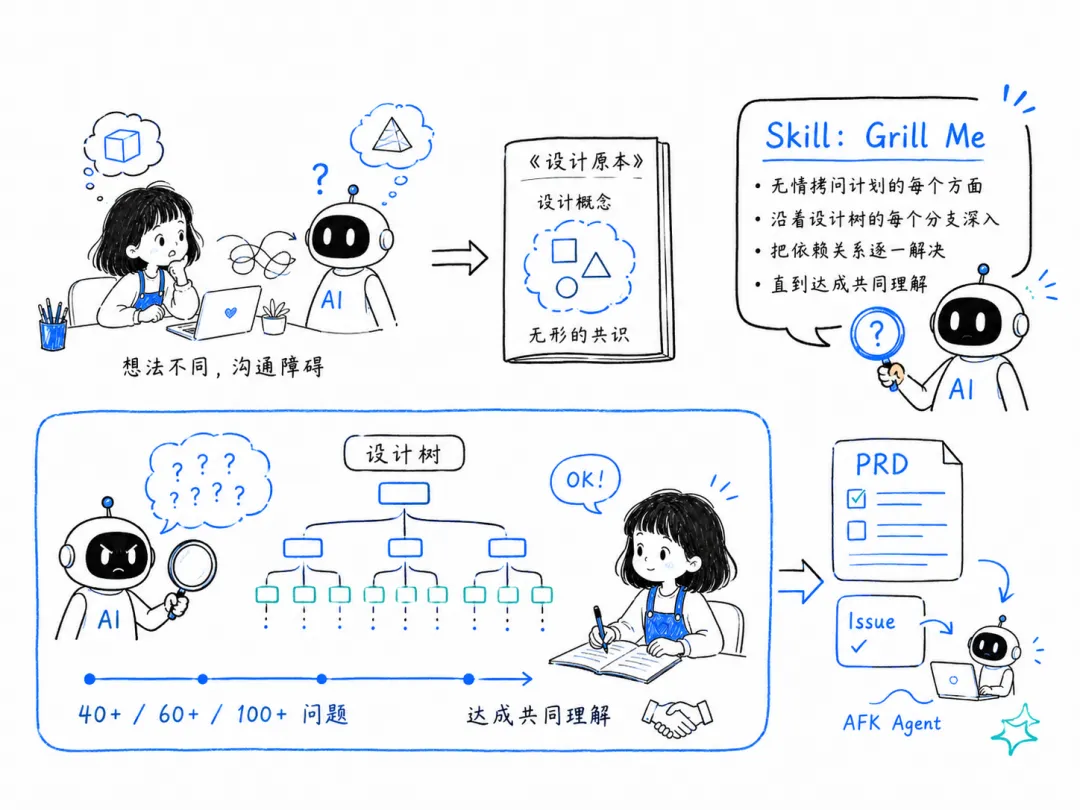
你脑子里以为有一个好主意,但 AI 做出来的是完全不一样的东西,或者干脆是你不想要的东西。
《程序员修炼之道》里有句话:没人确切知道自己想要什么。也就是说,你和 AI 之间存在沟通障碍。当你和 AI 对话时,它其实在做需求收集——它在从你嘴里搞清楚你需要什么。
我后来意识到,Frederick P. Brooks 的《设计原本》(The Design of Design)里讲过一个概念,叫”设计概念”(Design Concept)。当你和不止一个人一起设计一样东西的时候,你们之间漂浮着一种关于”我们正在构建什么”的飘忽不定的概念。它不是资产,不是你能放进 markdown 文件里的东西,而是一种关于你所构建之物的无形理论。
于是我意识到:我和 AI 没共享同一份设计概念。
我做了一个非常简单的 skill,叫 “Grill Me”(拷问我)。它的内容大致是:
无情地就这个计划的每一个方面拷问我,直到我们达成共同的理解。沿着设计树的每个分支走下去,逐一解决决策之间的依赖关系。
就这么几行字,装着这个 skill 的仓库就拿到了一万三千多个 star,意外地传开了。
这几行字会让 AI 变成一个对手,向你抛出 40 个、60 个,我让它最多问过别人 100 个问题,直到它认为双方达成了共同理解。它持续不断地把想法甩给你,逼你在交付任何东西之前先和它对齐。
对话结束之后,你拿到的内容可以直接拿去写 PRD;如果只是一个小改动,可以直接转成 issue,丢给你的 AFK agent 去处理。
请别因为这句话来 @我:我个人觉得这比 Claude Code 默认的计划模式好。计划模式非常急切地想产出一个产物,它就想搞个计划然后开干。我觉得更好的做法是:先达成一份共同的设计概念。
失败模式二:AI 太啰嗦
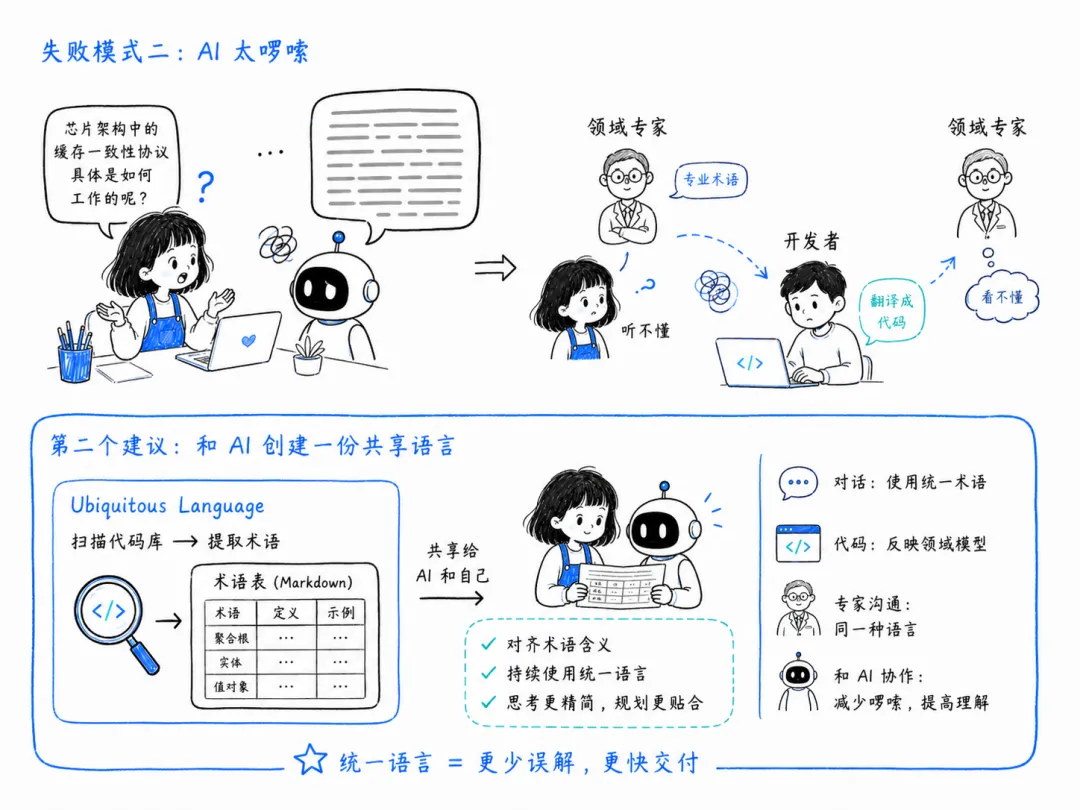
你和 AI 像在鸡同鸭讲。AI 会用太多的词去解释它在做什么,你们感觉不像在用同一种语言。
这种感觉对我来说非常熟悉。如果你做开发久了,一定和领域专家合作过。比如领域专家想让你做关于微芯片的东西,而你完全不知道微芯片是什么。你需要建立某种共同语言,否则他们用你听不懂的术语描述需求,你把这些术语翻译成你自己都不太理解的代码,而领域专家更读不懂。
所以我回到了领域驱动设计(DDD)。这个东西我目前还在边缘探索,但我读到的关于 DDD 的一切都让我心潮澎湃。
DDD 有一个核心概念叫统一语言(Ubiquitous Language):开发者之间的对话、代码本身的表达、以及和领域专家的对话,都源自同一份领域模型。本质上就是一份 markdown 文件,里面装着你和 AI 共有的术语清单。然后你聚焦于这些术语,确保它们和实际意思保持一致,并且在代码里、在你谈论代码时、在和领域专家交流时——在我们这里,是在和 AI 交流时——始终使用它们。
我做了第二个 skill,就叫 Ubiquitous Language。它扫描你的代码库,把术语抓出来,生成一份 markdown 表格,把所有术语列在一起。
我把它喂给 AI,自己也一直开着读。在我和 AI 反复打磨规划时,通过读它的思维过程,我注意到:它不仅改善了规划本身,还让 AI 用一种不那么啰嗦的方式思考,实现也更贴合你实际规划的内容。
第二个建议:和 AI 创建一份共享语言。
失败模式三:AI 做出了对的东西,但它就是不工作
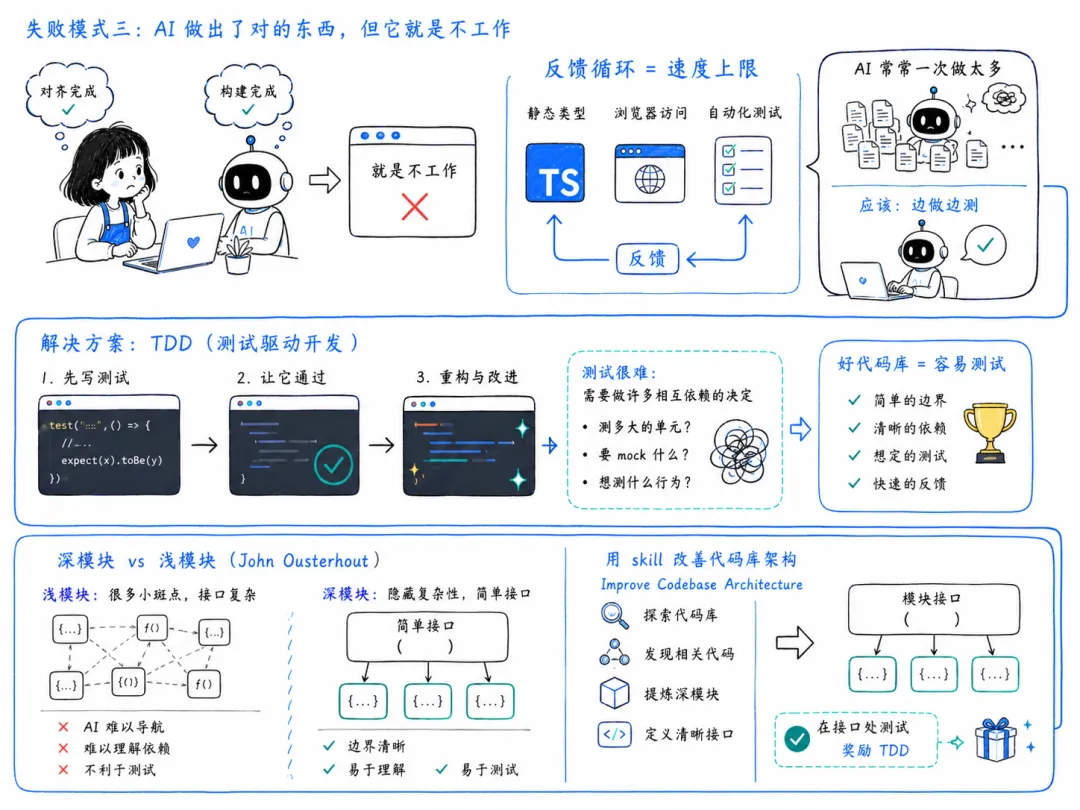
假设你已经和 AI 对齐了,你知道要构建什么,AI 也构建出了正确的东西——但它就是不工作。
有一件显而易见的事可以改善这一点:用反馈循环。静态类型——如果你不用 TypeScript,简直疯了。如果你做前端,却没给 LLM 浏览器访问权限让它能查看页面,这绝对是必备的。还有自动化测试。
但我注意到的一件事是:即使有这些反馈循环,LLM 也用不好。它不像资深开发者那样从反馈循环里榨取最大价值。它常常一次做太多——生成一大堆代码,然后才想”哦,我应该跑一下类型检查”,或者”我应该看看测试”。
《程序员修炼之道》把这描述为”开过你的车头灯”(outrun your headlights)。本质上就是开得太快——反馈的速率就是你的速度上限。
反馈速率就是速度上限。这意味着你应该”边做边测”,采取小而深思熟虑的步骤。AI 默认在这件事上真的不太行。
所以第三个 skill 是 TDD——测试驱动开发。TDD 强迫 LLM 真正地一小步一小步走:先写一个测试,让它通过,再去重构,改进设计。
测试很难,因为代码库很难
这里的问题是:测试真的很难,一直都很难。原因是写测试时你需要一次做出一大堆相互依赖的决定:
-
你要测多大的一个单元? -
要 mock 什么? -
你究竟想测什么行为?
如果你测一个非常大的单元,比如整个应用,它可能很不稳定;你可能不想测那么多行为;而你只测某一个单元时,又得 mock 它依赖的东西。一切都纠缠在一起。
我思考这个问题很多年了,贯穿我整个开发生涯。我们注意到的是:好的代码库,就是容易测试的代码库。
我们绕回到了最初那个观点——代码很重要。代码库越好,反馈循环越好;反馈循环越好,你给 LLM 的反馈越好;反馈越好,它产出的代码也越好。
深模块 vs 浅模块
那么,什么样的代码库是好的?什么样的代码库是好测试的?我们再次回到 John Ousterhout。
他主张代码库里应该有深模块,而不是浅模块。不是一堆暴露大量函数的小模块,而是相对较少、较大的深模块,带着简单的接口。
-
深模块:大量功能,藏在一个简单的接口背后。复杂性被隐藏起来。如果你愿意,可以查看深模块内部,但你不需要——直接用接口就行。 -
浅模块:没多少功能,接口却很复杂。
充满浅模块的代码库长什么样?你会有大量小斑点,AI 必须在它们之间穿行、导航。这对 AI 来说非常难探索。这就是为什么经常出现:AI 不理解你的代码到底在做什么。它会尝试去探索,但因为代码布局糟糕、浅模块到处都是,它来不及找到正确的模块,或者不理解所有的依赖关系——它就是不理解你的代码。
而 AI 又非常擅长产出这种代码库。
充满深模块的代码库长什么样?是同样的代码,但被组织在边界之内,边界顶部有清晰的接口。对这些接口你应该掌握很多控制权,把它们设计好;否则 AI 可能会把设计搞砸。但实现部分,可以稍微放手交给 AI。
我有一个 skill 来做这件事:Improve Codebase Architecture。它要做的事并不复杂,但是一组你可以反复重复的步骤——去探索代码库,寻找那些看起来彼此相关的代码,把它们包进一个深模块里。
这就是一个可测试的代码库:模块周围的边界非常简单,你在接口处测试,用那个接口去验证,就齐活了。这是一个奖励 TDD 的代码库。
失败模式四:你的大脑跟不上
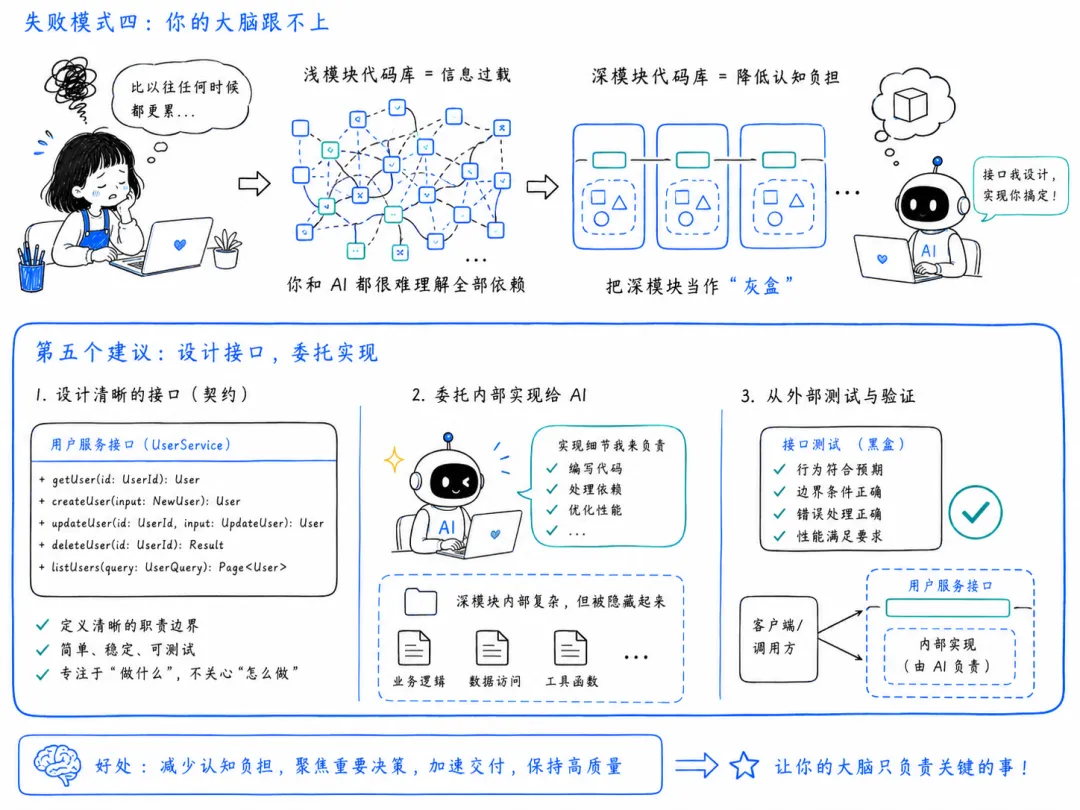
假设你的反馈循环已经跑起来了,事情在加速。你比以往任何时候都能发更多代码——但你的大脑跟不上。
如果你在自己的开发生涯里,现在比以往任何时候都更累,请举手。我也是。这真累。
我认为浅模块的代码库实际上让你的大脑更难处理,因为你和 AI 一样,需要把所有信息一起塞进脑子里。
而深模块代码库不只是更容易阅读和理解——它还意味着你可以把这些深模块当作”灰盒”。你可以说:”好,我只设计接口,我不去过多地审查实现。”
显然,对于应用中不那么关键的东西,你可以这样做;对于金融之类的关键路径,不能这样做。但在你应用中很多很多模块上,只要外部有一个可测试的边界,只要你理解它的目的、能从外部设计它,你就不需要太多去想实现内部。
我发现这真的拯救了我的大脑。我可以直接说:”好,AI,大斑点内部的事我交给你。我只从外部测试并验证它。”
第五个建议:设计接口,委托实现。
每天投资于系统的设计
但这意味着,每当我们碰代码、每当我们规划任何事情,都需要意识到应用中存在哪些模块。我们要知道那张应用地图,把它变成统一语言的一部分,也变成规划 skill 的一部分。所以当我写 PRD 时,我会具体写明哪些模块要改、它们内部的接口要怎么改。我一直在思考它们。
这一点来自 Kent Beck:
每天都要投资于系统的设计。
这就是核心。”规约转代码”并没有在投资系统的设计——它是在从中撤资,在摆脱设计。
而设计,我认为绝对是关键。
代码很重要
代码并不廉价。这是我希望你们带走的信息。代码很重要。
如果我们把 AI 看作一个非常出色的”一线程序员”——一个战术型程序员、一个在前线做代码改动的中士——那么它之上必须有一个人,从战略层面思考。那个人就是你。
而这需要软件基本功——那些我们已经用了二十年,甚至更久的技能。
如果你对我提到的任何 skill 感兴趣,它们都在我的 GitHub skills 仓库里。如果你对我做的培训或免费内容感兴趣,我在 YouTube,在 Twitter,也在 aihero.dev——我在那里有一份新闻通讯,你可以订阅。
希望这能让你在这个新的 AI 时代更有信心:你确实可以产生良好的影响。