 夜雨聆风
夜雨聆风





为什么规范驱动开发(SDD)不是AI辅助软件开发生命周期的银弹
字数 4570,阅读大约需 23 分钟
使用流行的SDD GitHub规范工具包和真实项目功能实验
项目GitHub仓库:https://github.com/alexcpn/speckit_test
规范驱动开发是当前AI编程浪潮中涌现出的较佳理念之一。
与从模糊提示直接跳转到生成代码不同,SDD要求开发者和编程智能体首先产出结构化规范、澄清需求、定义验收标准,并制定实施计划。这一点非常有价值。
但我们必须谨慎,不要将更好的提示工程规范与完全自主的软件开发混为一谈。
在执行时,即使是最复杂的SDD工作流程,最终仍会成为模型上下文。规范、计划、约束、护栏和任务分解最终都会被传递给LLM,由其进行解读。SDD提高了上下文的质量,但并没有消除模型的局限性。
这与链式思维风格的分解通常有帮助的原因类似。详细、结构化的中间表示通常比模糊的表示产生更好的结果。但这并不会神奇地赋予模型架构判断力、领域理解力、库选择规范或长期工程可靠性。
每个企业都在追求的圣杯是完全自主的软件开发。但目前的模型尚未达到这一水平,即使有更好的前期规划和像SDD这样的框架。
需要明确的是,我并不是在否定SDD。恰恰相反,我计划在未来的项目继续使用规范工具包或类似的框架。它们减少了样板提示,为感觉式编程注入了结构,使AI辅助开发更加规范。
但我的实验清楚地展示了边界所在。将抽象(规范)具体化,本身就是一个逻辑矛盾。
我尝试将SDD用于一个真实项目功能,使用GitHub规范工具包v0.8.9和Claude Code配合Claude Opus 4.7。结果在许多方面都令人印象深刻。生成的架构很有用,实施流程优于简单的提示工程。但正如我所怀疑的,它在选择正确的库和框架方面失败了。
这个实验也为本文提供了实证基础:截至目前,完全自主的开发与SDD结合并非对所有项目都是最优方案。
背景
当缺乏真实世界经验的人宣称”规范”是软件开发的银弹时,我的思绪立刻回到《人月神话》。这是一本40年前的书,现在很少有人阅读,但它至今仍有深刻的意义。
Fred Brooks写道:”软件的复杂性是本质属性,而非偶然属性。因此,抽象掉复杂性的软件实体描述往往也抽象掉了其本质。”
无论规范是由AI撰写还是由人类撰写,其实质并不重要。软件的基本复杂性永远无法被任何规范完全捕获。
我可以在此停笔。这个论断足以解释和证明为什么仅有规范是不够的。
除了对于非从业者/非程序员可能不明显的一个小问题之外,软件的基本复杂性会在软件开发过程中不断演化。
这是SDD忽略的一个关键流程,实际上也是其最大的弱点。
规范的第一稿通常从来都不是最好的,无论是来自专家人类还是AI。良好的实现设计和框架选择来自于对代码的迭代改进。 AI生成的代码同样如此,因为在代码运行过程中会发现未知因素。
用程序员的话说,软件偏离规范不是bug,而是一个feature。
同样来自那一章——”我相信构建软件最难的部分是这一概念结构的规范、设计和测试,而不是将其表示出来的劳动……我们确实会犯语法错误,但不能;它们与大多数系统中的概念错误相比微不足道。如果这是真的,构建软件将永远是困难的。本质上不存在银弹。”
规范是随着代码和设计迭代开发的,并不断更新。从业者将这种实践称为另一个词:原型设计。
在没有首先进行编码/ 原型设计的情况下,我从来不会为一个新功能写一个字的规范。
软件开发中没有银弹。
40年前这是真的;AI驱动开发的今天仍然如此。可以用《神话般的AI加速》来替代《人月神话》,而这仍然相当接近真相。
当我刚入行时,Rational Rose是市场上最被炒作的工具之一。UML被视为那个年代的银弹:画方框、箭头和图表,工具就会神奇地将它们转化为可工作的代码。
当时我持怀疑态度,从未相信仅凭图表就能取代工程判断。炒作最终消退,行业学到了同样的教训。
因此,当围绕规范驱动开发的当前兴奋开始时,我有了熟悉的反应。
然而,SDD复兴了许多被社区普遍遗忘的最佳实践——前期分析、规划、设计、测试先行/驱动开发。
SDLC究竟是什么?
SDLC是一个长期以来从大多数现代程序员词汇表中消失的缩写——更多与瀑布式方法论相关联。
亚马逊的AI聚焦IDE Kiro将其重新引入,将其重新定位为”AI原生SDLC或AIDLC“的支柱。
其核心描述的是分析→设计→实施的循环周期。
人们错误地认为SDLC意味着瀑布式开发。 像Scrum和敏捷这样的迭代方法论遵循完全相同的阶段——只是范围被限制为功能列表的子集,通常一次一个功能——一个更小的子集称为用户故事和任务,现在几乎所有现代软件开发组织都有CI和CD的自动化流水线。因此,将其Dismiss或与瀑布式模型的所有旧问题联系起来是不正确的。
如果您使用SDD开发整个产品或大型功能——用Scrum的术语说是一个Epic——并给出类似”我想构建一个新的数据库系统”这样的提示,范围很大,生成的工件数量庞大,任务列表也非常庞大。如果以这种方式使用,这种批评有一定的道理。
如果整个项目一次性被指定,人类不可能在一次或几天内处理如此多的认知负荷。结果是规范者最终放弃,变成一个过度劳累的职员,盲目地在SDD驱动的智能体循环中签署文件,按”是”或”确定——继续”。
但SDD也可以针对更小的功能子集进行,我认为这是更好的方式。
对SDD的另一个反驳是AI模型是非确定性的,因此不同模型或同一模型在不同时间可能对规范有不同的解释。
实际上这不是主要问题。SDD框架作为结构化提示,现代模型在被引导时产生高度一致的输出。
真正的问题——为什么代码成为事实的来源,以及为什么这是一件好事。
良好的设计和算法创意是在编码过程中精心打磨的。
这是所有编码和发布复杂产品的人都能明白的简单真理,而所有不这样做的人都不明白。
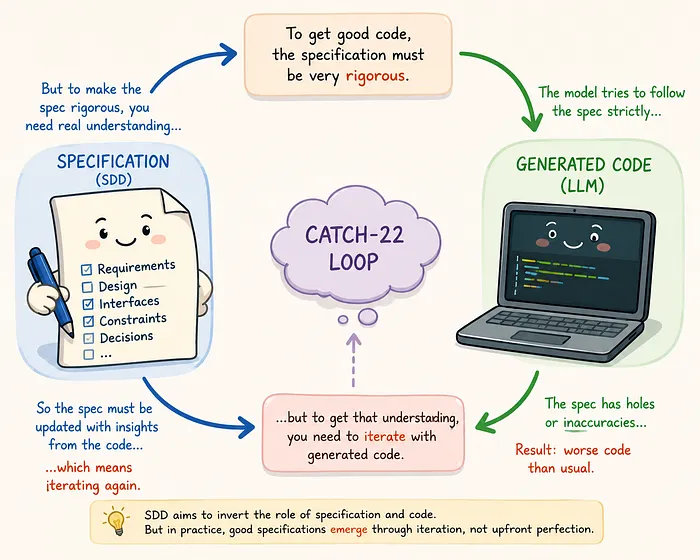
这就是为什么初始分析和设计规范会过时,以及代码成为事实来源的原因。SDD试图通过反转规范和代码的角色来颠覆这一点。
SDD试图通过反转规范和代码的角色来颠覆这一点。它的基本论点是:无需先进行代码调整和原型设计,就有可能预先指定良好的设计,而这在根本上是错误的。
对这个论点的反驳是AI模型的编码能力。这些模型足够强大,可以”精心打磨”最佳的设计、库和框架决策。
使用严格的SDD,这成为即使是非常有能力的模型也面临的问题,因为它试图严格遵循规范,而规范中存在漏洞或不准确之处,实际上生成了比通常更差的代码。
这就像一个第22条军规困境。规范必须在一开始就非常严格,但要做到这一点,它需要根据生成的代码进行迭代修改。
在完全自主编码的情况下,LLM像写诗一样进行代码和设计的自回归生成。没有重构或返工。我们只能祈祷提示或规范足够好。生成的代码量如此之快、如此之大,以至于不可能手动审查或重构。
完全自主编码适合快速原型或概念验证——但不适合生产环境。
第二部分:端到端实验测试SDD论题
为了具体测试这一局限性,我使用流行的规范驱动开发框架Spec Kit进行了端到端实验。
我在实验中使用的是Spec Kit,但我不认为结果仅限于Spec Kit。我预期在使用OpenSpec、BMAD或任何通过AI编码智能体从规范过渡到实现的类似框架时,会出现类似的模式。
我选择的功能是真实且非平凡的:一个用于处理USGS 3DEP/NED图块美国高程数据的Python模块。我之前处理过这个问题,所以已经知道实际实现中最终会出现的架构类型。
目标很简单:SDD流程能否自行发现类似的架构?
实验可在此查看:https://github.com/alexcpn/speckit_test
实验设置
我遵循了标准Spec Kit流程:初始化→宪章制定→规范定义→澄清→规划
使用的工具:
-
• Spec Kit v0.8.9 -
• Claude Code -
• Claude Opus 4.7
初始宪章创建了关于代码质量、测试驱动开发、一致性和性能方面的合理原则。在这个阶段看起来没有明显的问题。事实上,这些原则是明智的。
但两个隐藏的力量已经被引入。首先,宪章要求每个新依赖项都必须有书面理由。这听起来很好,但它悄悄地给Python标准库带来了优势和不公。 标准库解决方案从零辩护成本开始,而每个外部依赖项必须为自己辩护。
其次,宪章要求预先制定可衡量的性能预算。 理论上这很合理。但如果这些预算是架构未理解之前猜测出来的,它们后来就变成了人为约束。
这就是SDD开始暴露其弱点的地方。早期假设硬化为规则。
初始规范从一个简单的用户请求开始:构建一个Python模块来存储美国高程文件并计算两个经纬度点之间的高程剖面。
智能体生成了一份看起来干净的规范。但一些重要假设是错误的。这在SDD框架生成的提示传递给LLM的下一阶段被正确捕获。
澄清阶段
第一个版本假设了更小、更简单的范围:本质上是一个仅限美国本土的数据集和一个更偏向业余爱好的存储问题。实际需求要大得多:完整的美国本土加上所有美国领土,如夏威夷和波多黎各,大约1,756个NED文件,约230亿个高程样本,以及约180GB的原始数据。
澄清阶段非常有用。这是工作流程中最有力的部分。智能体识别了关于数据集规模、支持的数据源格式和性能预期的重要缺失问题。 一旦数据集规模被澄清,问题就变得更加现实。
但也存在一个微妙的问题。
当智能体询问图块索引持久化时,它提供了重建索引、存储小元数据副文件或缓存解码图块有效载荷等选项。推荐的选项是小元数据副文件。
这个选择是合理的。但选项菜单本身悄悄地限制了设计空间。
一个更好的架构——将数据集转码为Zarr存储——没有作为一等选项被呈现。 它在概念上接近”缓存解码有效载荷”,但没有被框定为不同的产品形态或架构路径。
这是AI驱动规范工作流程中一个被低估的风险:澄清菜单本身就是一种设计决策。用户可能认为他们只是在回答需求问题,但智能体已经缩小了架构可能性。
信任SDD提示能够真正覆盖所有架构和设计需求,这确实是一个巨大的风险。
规划阶段
在规划阶段,智能体选择了SQLite,使用标准的sqlite3模块和R树虚拟表进行空间查询。
这在隔离情况下不是一个糟糕的选择。它干净、可检查、简单,且无依赖。这也与宪章完美对齐。
但这恰恰是问题所在。
当被问及为什么选择SQLite时,智能体 heavily依赖于是标准库的一部分且没有引入新依赖这一事实。 像Parquet、LMDB、DuckDB,或在这个案例中更好的Zarr或TensorStore等替代方案被部分拒绝,因为它们增加了依赖。
换句话说,宪章已经倾斜了决策。
该计划与通用SDD框架(在本例中为Spec Kit)附带的模板内部一致。但它也是一个局部最优:一种最小化与规范框架摩擦的设计,而不是深入从实际数据问题的形态进行推理。
计划提交后,我挑战了这个决定,就像我之前做过这个功能一样。
为什么选择SQLite?为什么不是Zarr?为什么不将所有源文件一次性转码为Zarr存储,避免重复的启动/索引开销?
智能体最初拒绝了这个想法,因为一次性转码会违反早期冷注册的性能预算。
但这个预算不是需求。它是早期作为规范流程的一部分引入的,然后被视为真正的约束。
一旦被挑战,智能体撤销了论证。它承认如果将注册重新定义为可以花费更长时间的一次性设置步骤,Zarr设计是完全合理的。
那是实验中最重要的时刻。
更好的架构不需要新信息。它需要的是质疑规范流程本身创建的早期假设的意愿。
实验展示了什么
这个实验并没有证明Spec Kit不好。事实上,我发现工作流程很有用。它带来了结构,暴露了缺失的问题,使开发过程比简单提示工程更加规范。
但它也展示了SDD在AI辅助开发中的核心局限性。
使用AI创建规范可能会引入在很久以后才能看到的遗漏。
即使开始时更慢,让工程师手动撰写规范的第一个版本,然后使用AI来改进、完善和挑战它——可能通常会更好——而不是反过来。
这让我再次回到Fred Brooks在《人月神话》中写的内容:
“软件的复杂性是本质属性,而非偶然属性。因此,抽象掉复杂性的软件实体描述往往也抽象掉了其本质。”
在这个上下文中,这句话有非常实际的含义。如果规范抽象掉了太多复杂性,它也可能抽象掉了正在构建的软件的核心本质。
这就是为什么代码通常成为真正的信息来源。 不是因为规范是无用的,而是因为规范很少能够捕获在实施过程中出现的每个设计压力、边缘情况、库限制、性能权衡和算法细节。
好的设计并不总是在编码开始前就被发现。许多重要的设计和算法创意是在编码、原型设计、调试、测量和重构过程中精心打磨出来的。
这也是为什么初始分析和设计文档经常变得过时,而代码逐渐成为系统最准确的描述。这不一定是问题。这只是良好软件的构建方式。我们不是仅通过阅读规范来修复困难的bug。我们最终走向的是实际运行的真相:代码。
SDD试图通过使规范成为主要产物和代码成为下游输出来颠倒这种关系。它的隐含论点是,足够严格的前期规范可以指定好的设计,然后实施可以从中遵循。这个实验表明,对于非平凡软件,这个论点是错误的。
规范是有用的。计划是有用的。规范是有用的。但最好的设计往往出现在编码功能的过程中。
参考资料
-
• 项目GitHub仓库:https://github.com/alexcpn/speckit_test -
• 规范驱动开发:在AI编程助手时代从代码到契约(https://arxiv.org/html/2602.00180v1),虽然支持SDD的理念,但在失败模式部分有很多好的观点 -
• 互联网上的许多文章通常对SDD持积极态度,而Reddit等用户论坛中的许多评论大多持负面态度。