 夜雨聆风
夜雨聆风





图解 Word2vec-中文讲解版
本文档为学习用途的中文讲解版,使用中文重新组织表达,所有图片来自原站(直链引用,未做修改),章节顺序与原文一致。版权归原作者 Jay Alammar 所有。
万事万物皆有其纹理——它们对称、优雅、富有韵律,是真正的艺术家所捕捉的特质。可以在四季交替中看见它,可以在沙脊上的沙痕里看见它,也可以在灌木丛的枝叶聚集中看见它⋯⋯然而,去寻找终极的完美也存在危险。终极的纹理意味着固化,而在那种完美中,万物趋向死亡。——《沙丘》(1965)
嵌入(Embedding)是机器学习中最迷人的想法之一。如果你用过 Siri、Google Assistant、Alexa、Google 翻译,或者用过手机输入法的”下一词预测”,那你都受益于这个已经成为现代 NLP 核心的概念。
过去十多年里,神经网络中嵌入的应用持续演进——最近的发展是上下文相关的词嵌入,催生了 BERT、GPT-2 这类突破性模型。而 Word2vec(2013 年问世)是高效生成词嵌入的一种经典方法。除此之外,它的核心思想还被广泛用于推荐系统和各类序列数据建模——Airbnb、阿里巴巴、Spotify、Anghami 等公司都从中获益。
本文将带你从概念出发,逐步走完 word2vec 的训练机制(skipgram + 负采样)。
1. 从”性格嵌入”开始:你是个怎样的人?
怎么用一个数字来概括一个人的性格?我们先从一个简单的维度开始:外向性 / 内向性。在 0(最内向)到 100(最外向)的尺度上,你大概是几分?
你或许做过类似 大五人格(Big Five) 这样的性格测试。如果你还没做过,这个网站 提供一份不错的免费版。
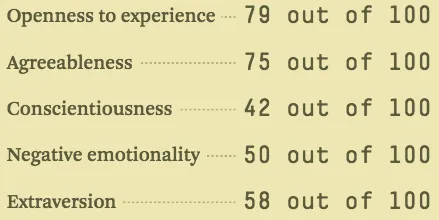
假设我在”内向 ↔ 外向”维度上拿了 38/100,可以画成这样:
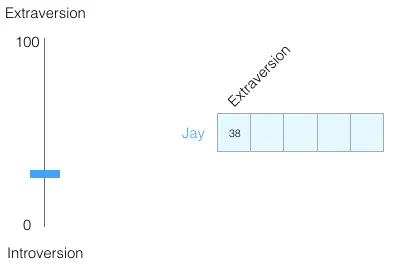
把范围归一化到 -1 到 1:

仅凭这一个数字,你对我的了解非常有限。我们再加一个维度——比如大五 中的另一项性格特征。这样每个人就由 两个 数字(一个二维向量)表示:
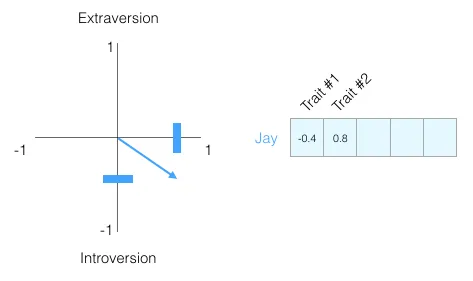
这样表示有个有用的好处:可以拿一个人和另一个人比较。下图中,哪两个人的性格更接近?
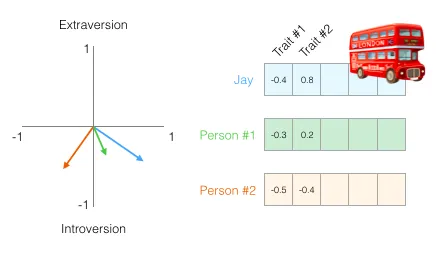
处理向量时,常用的相似度度量是余弦相似度(cosine similarity):

但二维仍然不够丰富。心理学界用了几十年才相对收敛到大五人格——也就是五个维度。我们用这五个维度来表示每个人:

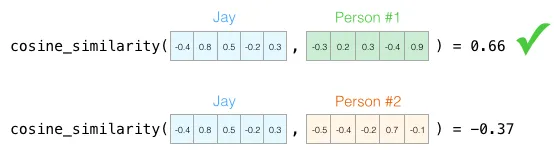
问题来了:五维向量没法直接画出来。但余弦相似度公式对任意维度都适用。下图比较了 1 号和另外两个人——余弦值越接近 1,方向越接近,性格越像:
本节三点收获:
-
我们可以把人或事物表示成一个向量(电脑很喜欢这种数据); -
可以方便地比较两个向量的相似程度; -
用足够多维度的向量,能容纳足够丰富的信息。

2. 词嵌入
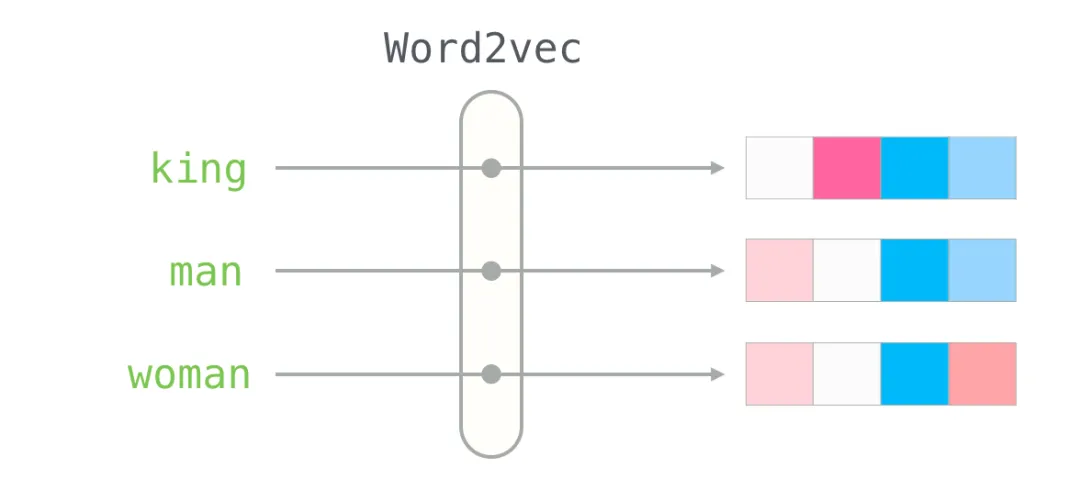
性格的类比讲完了,可以正式登场了——下面看一下”king”这个词在一个真实预训练词嵌入(GloVe,基于维基百科训练)里的向量长什么样:
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
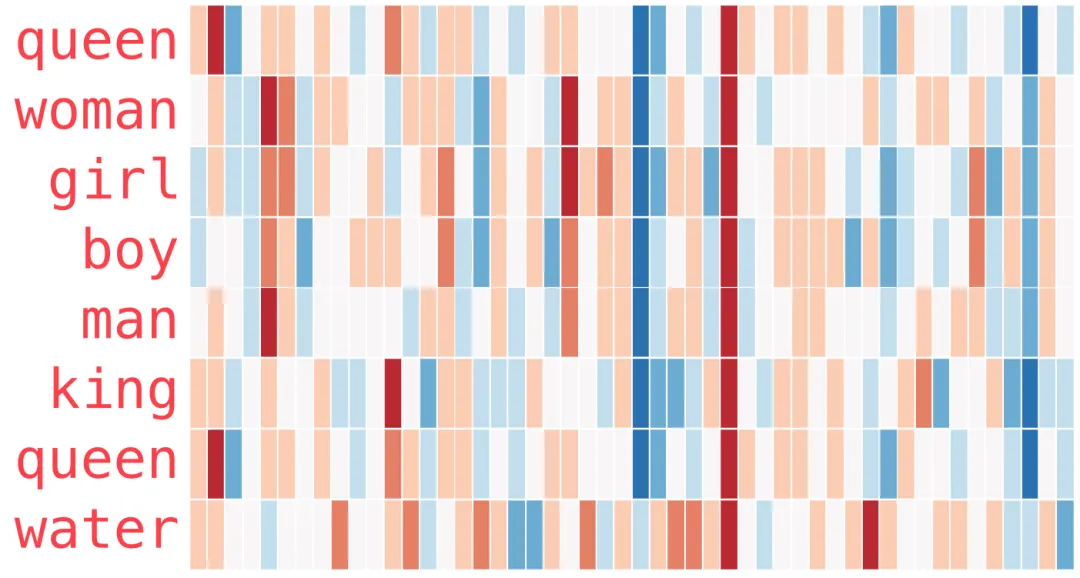
50 个数字。光看数字看不出什么,我们做点可视化:把所有数字摆成一行,并按数值大小染色(越接近 2 越红,越接近 0 越白,越接近 -2 越蓝):


把”man”和”woman”也按同样方式画出来,与”king”对比一下:

注意几件事:
-
所有词都有一条贯穿整个 50 维的”红色”列——它们在那个维度上数值都很相似(这条维度具体编码了什么,外人很难解释); -
“woman”和”girl”之间的相似度,比”woman”和”king”之间的相似度明显更高; -
“king”和”man”在某些维度上有惊人的对应——直觉上呼应了”king 是男性版的某种地位”这种语义关联。
3. 类比与向量运算
词语能承载我们希望它承载的任何重量——前提是有共识与传统作为基石。——《沙丘:神帝》
展示词嵌入魔力的经典例子是类比(analogy):你可以对词向量做加减运算,得到惊喜的结果。最有名的就是:
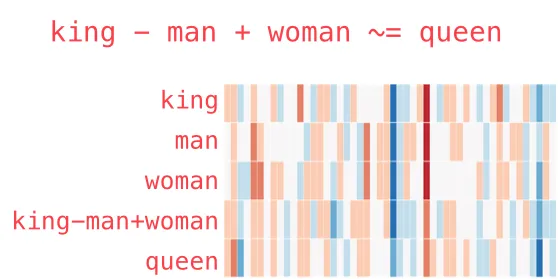
king − man + woman ≈ ?
用 Python 的 Gensim 库做这个运算后,再去 40 万词的词表里找最接近的那个向量——结果是 queen:
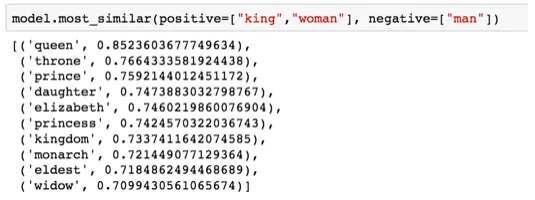
用图示更直观:
了解了”训练好的词嵌入”长什么样、能做什么之后,下面看它是怎么训练出来的。在讲 word2vec 之前,先看它的概念前身——神经语言模型。
4. 语言模型
NLP 应用中最日常的例子,莫过于手机输入法的”下一词预测”了——几十亿人每天都在用的功能。
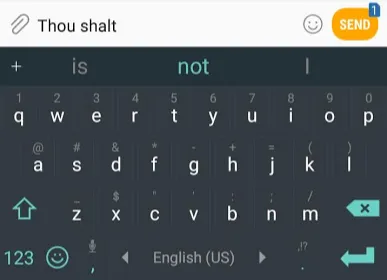
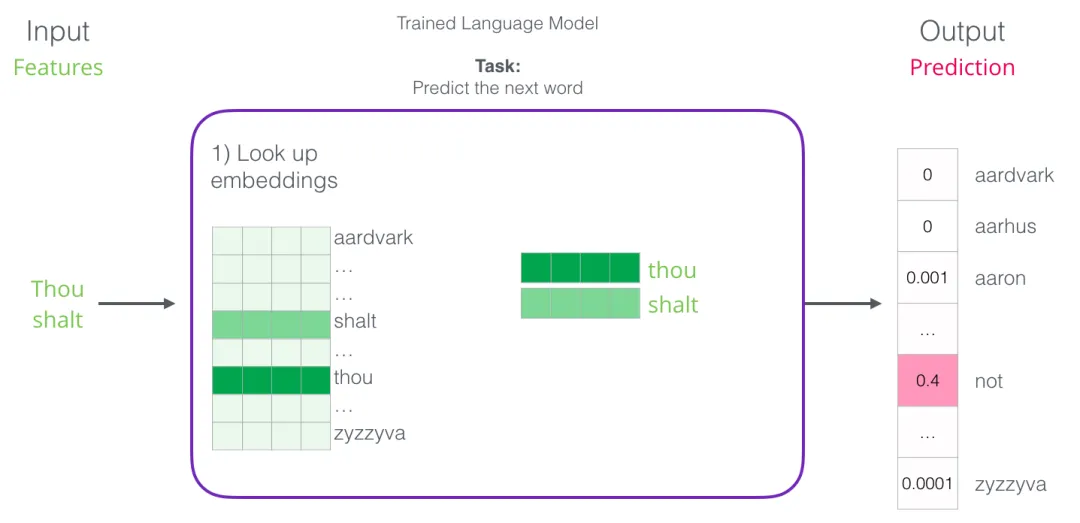
下一词预测可以通过语言模型 完成。给定若干个词(比如两个),语言模型预测最可能跟在后面的下一个词。比如上图中,模型看到”thou shalt”,然后给出三个候选并按概率排序:

把语言模型当一个黑盒:

实际上模型不是只输出一个词,而是对它词表里所有词各打一个概率分(比如词表 1 万词,输出就是 1 万维向量),由应用层(输入法)挑出概率最高的几个展示:
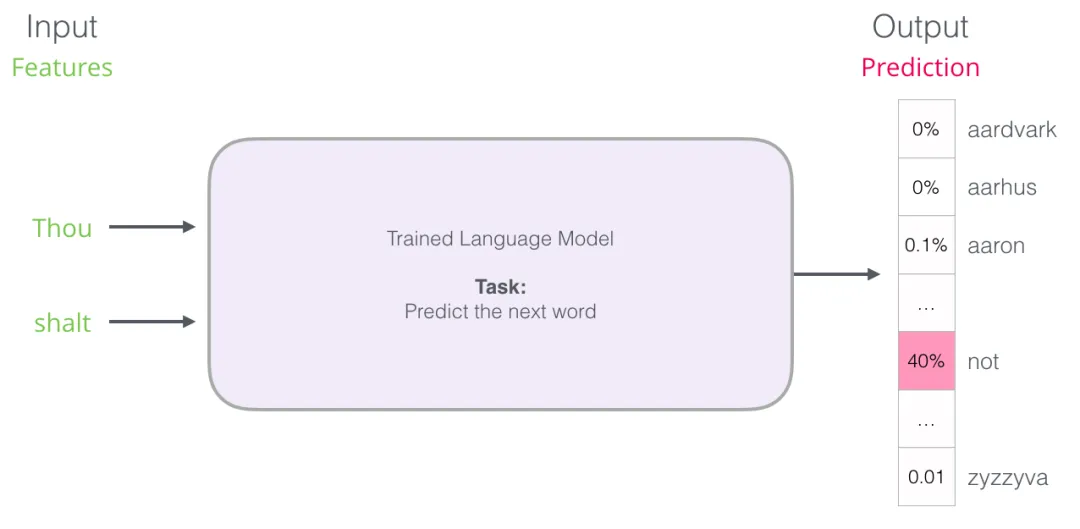
训练完成后,早期的神经语言模型(Bengio 2003)这样工作:先在词嵌入矩阵里查找输入词对应的向量,然后做几步处理给出预测:
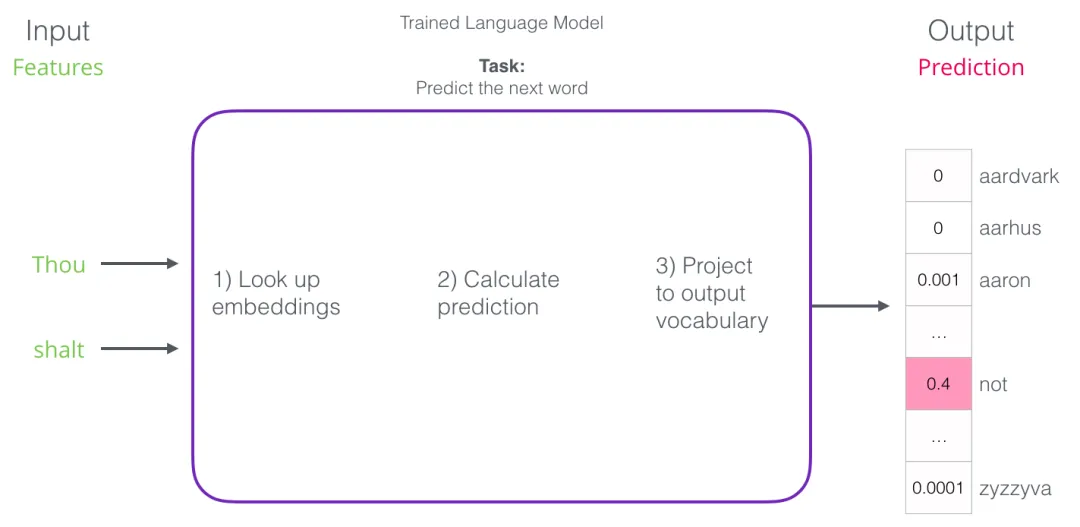
本节关键收获:嵌入矩阵是语言模型训练的”副产品”。模型本来的训练目标是预测下一个词,但训练完成后,那张查找用的嵌入矩阵就成了非常有价值的”词表示资产”——可以拿去用在别的 NLP 任务上。
5. 语言模型如何训练
语言模型相比绝大多数机器学习模型有个巨大优势:训练数据天然就有——所有书籍、文章、维基百科、各种文本数据都行。和图像分类(要花钱标注)、语音识别(要花钱转写)形成对照。
怎么用文本喂模型?很简单:滑动窗口。给定一个目标词,把它前面 N 个词作为上下文。比如取窗口大小 3,从这句话开始:
“Thou shalt not make a machine in the likeness of a human mind”
第一步,窗口对准句首三个词,前两个作为输入,第三个作为标签(要预测的目标):

把这条样本加入数据集。

窗口右移一格,得到第二条样本:
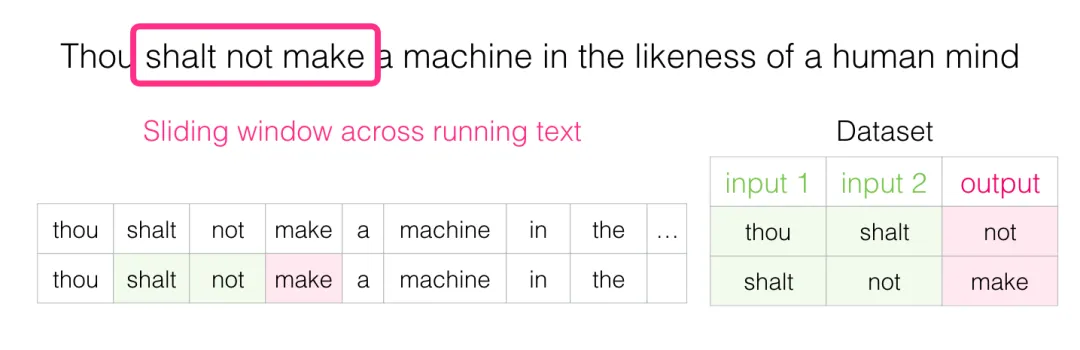
就这样一直滑下去,很快就能积累出庞大的训练集:

实践中,这个数据集是在我们滑动窗口的过程中”虚拟”构造出来的,不会真的把它落盘——这种方式效率高得多。
6. 两个方向都看:上下文很重要
悖论是一个指针,指向超越它本身的存在。——《沙丘:神帝》
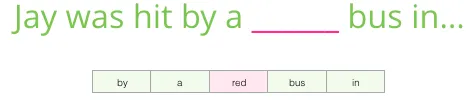
带着前面学的知识,先做个填空:

这里我给的上下文是空白前的 5 个词(以及更前面的”bus”提及)。多数人会猜空白处是”bus”。但如果我再给你空白后的一个词呢?

答案完全变了——”red”成了空白处最可能的词。这告诉我们:一个词左边和右边的词都对它的含义有信息价值。同时考虑前后文,能学到更好的词嵌入。下面看怎么调整训练方式来兼顾两侧。
7. Skipgram
智慧就是在错误既可能也必然发生的领域里,用有限数据去冒险。——《沙丘:圣殿》
把窗口从”只看前面两个词”改成”前后各看两个词”。这样虚拟构造的数据集长这样:

这种架构叫 CBOW(Continuous Bag of Words,连续词袋),在 word2vec 论文中有详细描述。
另一种架构思路反过来:不用上下文猜中心词,而是用中心词去猜它周围的词。窗口看起来像这样:

这种方法叫 Skipgram。注意:滑窗一次会拆成 4 条独立的训练样本(一个中心词对一个邻居词,每个滑窗位置生成 4 条):
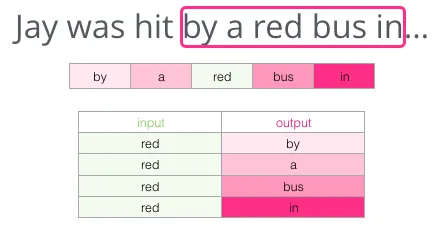
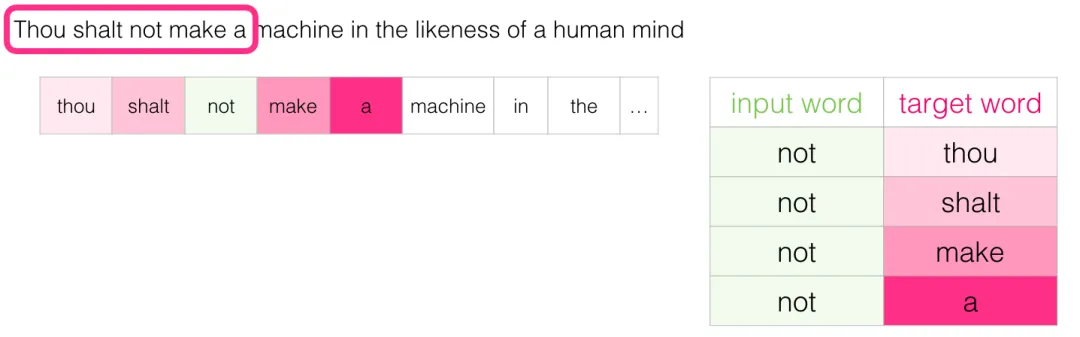
窗口滑到第一个位置,加入数据集:

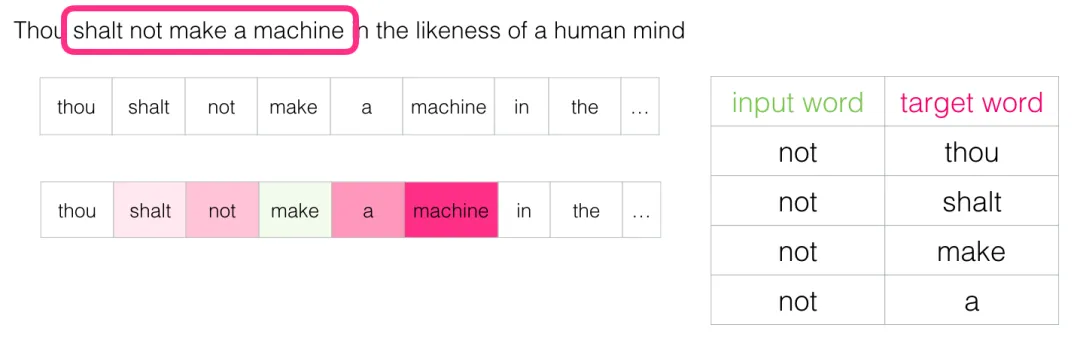
滑到下一个位置,又得到 4 条样本:

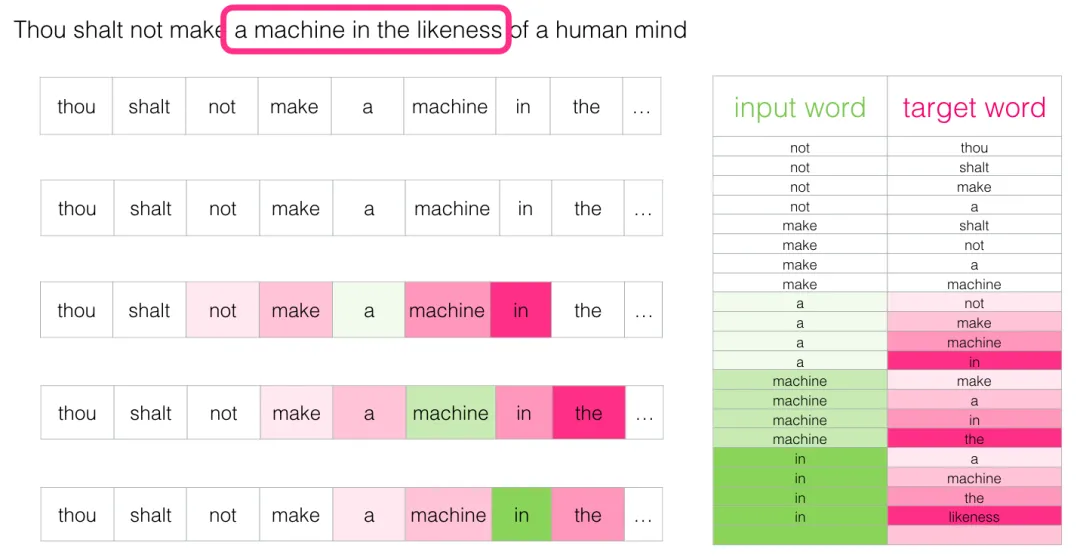
再滑几次,样本数已经相当可观:
8. 重新审视训练流程
“穆阿迪布学得很快,因为他的第一项训练是怎样去学。”——《沙丘》
有了 skipgram 数据集之后,看怎么用它训练一个最朴素的神经语言模型来预测邻居词。
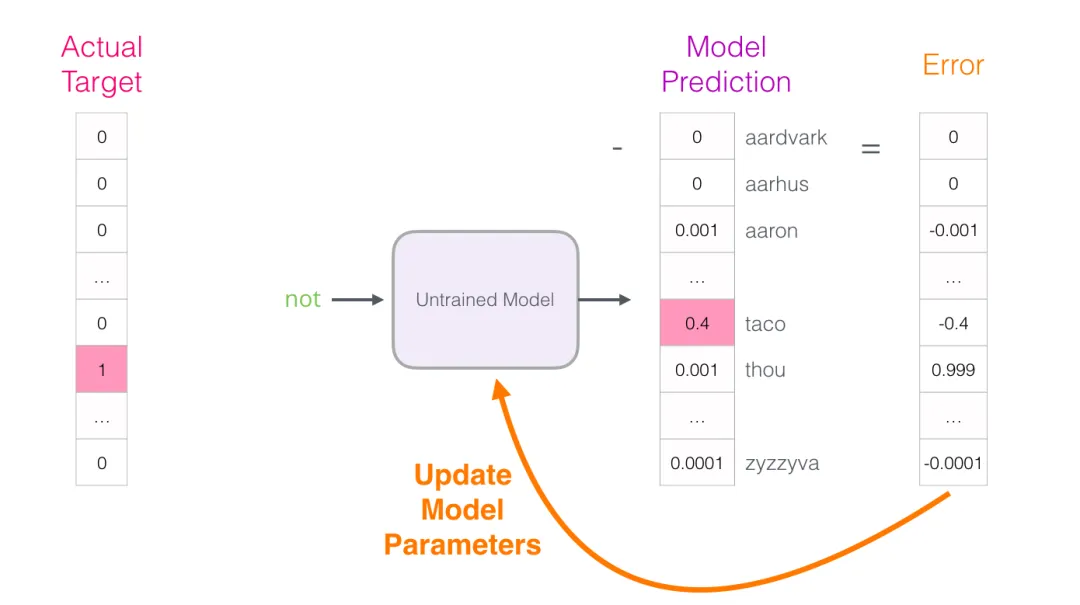
取数据集中第一条样本,把”输入词”喂给未训练的模型,让它预测”邻居词”:
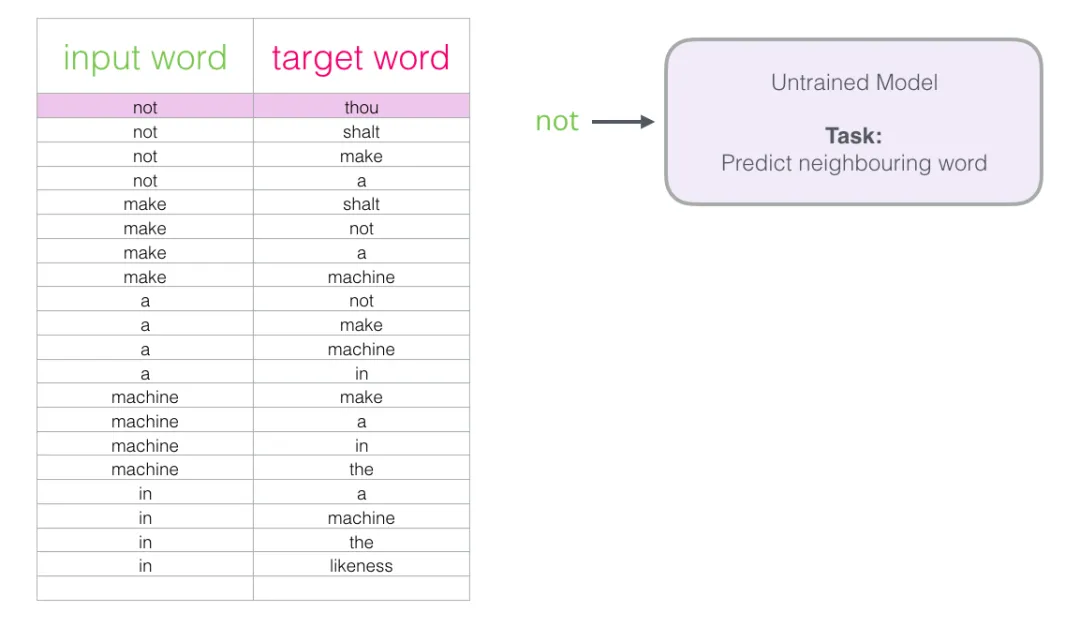
模型走完三步流程后,输出一个概率向量(词表中每个词都有一个概率)。模型未训练,预测肯定不准——但没关系,我们手上有正确答案:
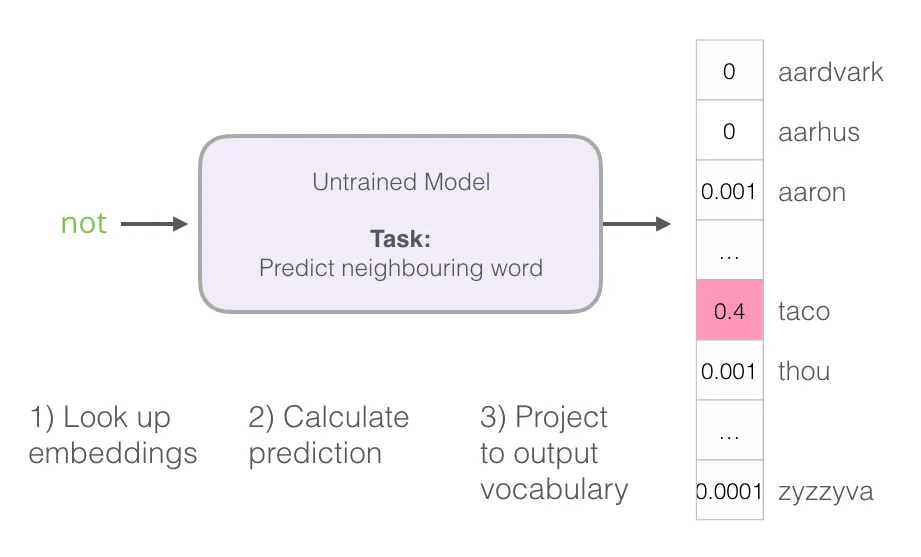
预测向量与目标向量相减,得到误差向量:
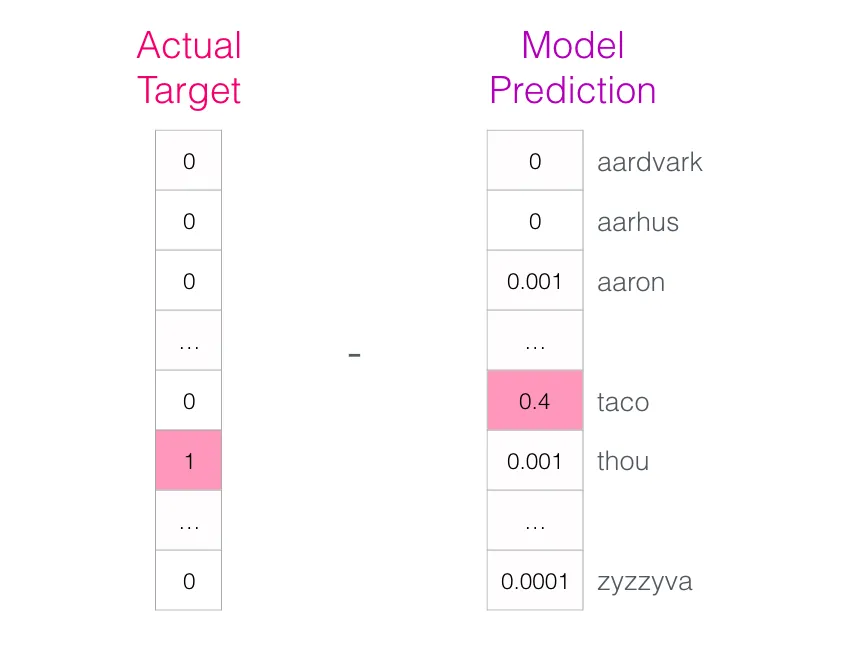
用这个误差更新模型参数,下一次它给同样的输入时就更可能给出正确答案。这就完成了一步训练。
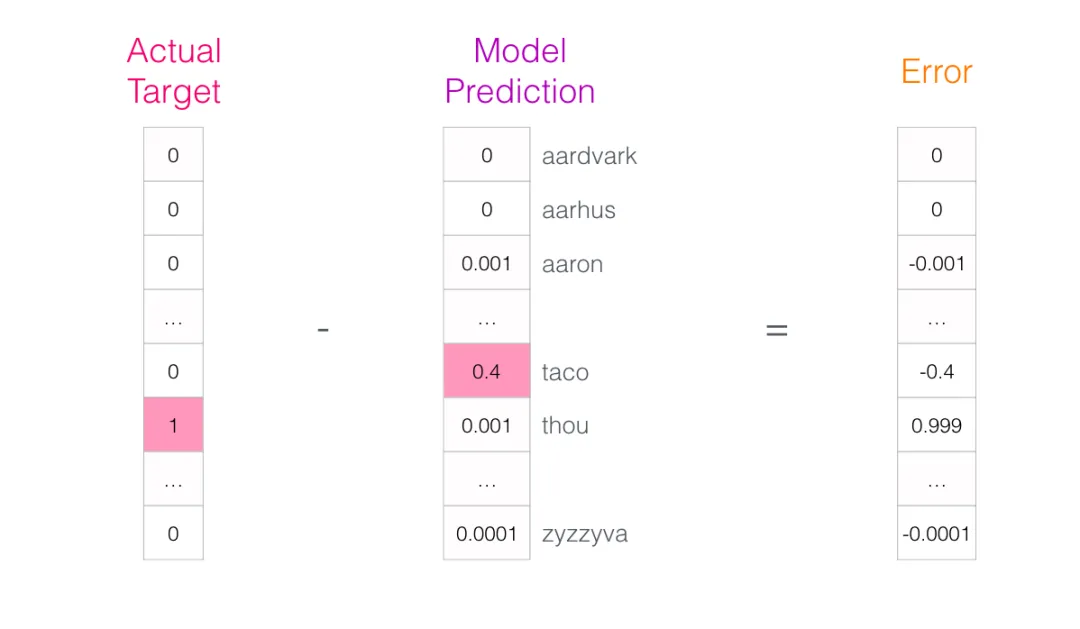
对数据集中所有样本依次执行同样过程,跑完一轮就是一个 epoch。再来若干 epoch,模型训练完成,从中抽出嵌入矩阵就可以用于下游任务。
这只是概念性的训练流程,真实的 word2vec 还做了两个关键改进。
9. 负采样(Negative Sampling)
“试图理解穆阿迪布而不去理解他的死敌哈克南家族,就像试图在不知何为黑暗的情况下看清光明——做不到。”——《沙丘》
回顾刚才神经语言模型的三步预测流程,第三步非常昂贵——它要在词表上做 softmax,词表往往几万到几十万词,而每条训练样本都要做一次(数据集动辄几千万到几亿条),整体开销吓人:
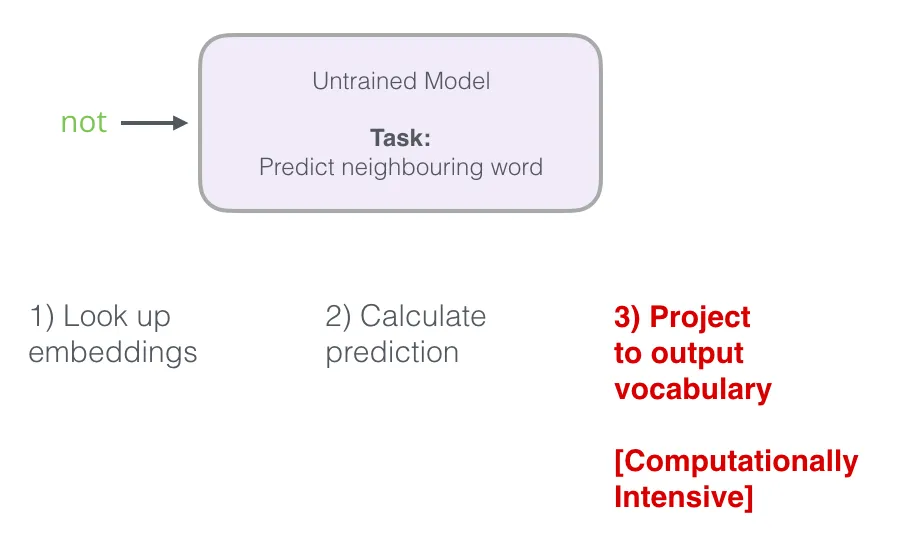
怎么提速?把目标拆成两步:
- 先专心生成高质量词嵌入
(不要管下一词预测); -
再用这些嵌入去训练真正的语言模型。
这篇文章只关心步骤 1。要既快又能学到好嵌入,关键是把模型的任务换掉:原来是”给输入词,预测一个邻居词”(多分类,词表那么大,慢);改成“给一对词,判断它们是不是邻居”——0 表示不是,1 表示是。
这个小改动让模型从神经网络降级为逻辑回归——计算量天差地别。
相应地,训练数据集结构也变了:原来”输入词 → 输出词”,现在变成”(输入词, 上下文词) → 0 或 1″。但麻烦来了:到目前为止,我们从语料里抽出来的所有样本都是”是邻居”,标签全是 1。这样训练出的模型很容易学到一个”懒办法”——不管输入什么都返回 1,准确率 100%,但学到的嵌入毫无意义。
所以必须给模型加一些负样本——明明不是邻居的词对,标签为 0。这样模型就被迫真正去学。
对每个正样本,我们再从词表里随机挑几个词作为”假上下文”,构造负样本:
-
输入词:和正样本相同; -
上下文词:从词表随机抽; -
标签:0。
这个思路源自 NCE(Noise-Contrastive Estimation,噪声对比估计)——通过把”真实信号(正样本)”与”噪声(随机抽样的负样本)”对比来训练模型。它在计算开销和统计效率之间取得了非常好的平衡。
10. Skipgram + 负采样(SGNS)
到这里,word2vec 的两个核心思想都已经讲完:
-
Skipgram:用中心词预测周围词,构造(中心词,邻居词)正样本; -
负采样:把”猜词”换成”判断是不是邻居”,并加入随机负样本。
把这两个思想合在一起,就是 Skipgram with Negative Sampling(SGNS)——也是 word2vec 实际使用的训练方案。
11. Word2vec 完整训练流程
“机器无法预见对人类而言重要的每一个问题。这是序列比特和不可分割的连续体之间的差别——我们拥有后者,机器只能困于前者。”——《沙丘:神帝》
下面把整个训练流程串起来。
预处理
首先确定词表大小(记为 vocab_size,比如 10,000)以及哪些词进词表。
初始化两张矩阵
训练开始时,建两张矩阵:
- Embedding 矩阵
:尺寸 vocab_size × embedding_size(embedding_size常用 300,前面例子里用过 50); - Context 矩阵
:尺寸同上。
两张矩阵都用随机值初始化。每张矩阵里都为词表中每个词存了一个嵌入向量——但它们扮演的角色不同:当一个词作为中心词输入时去 Embedding 矩阵里查;当它作为上下文词时去 Context 矩阵里查。
逐步训练
每一步训练都拿一个正样本及其若干负样本。比如第一组:
-
输入词(中心词): not -
正样本上下文词: thou(标签 1,真邻居) -
负样本上下文词: aaron、taco(标签 0,随机选的”假邻居”)
第一步:查嵌入。not 去 Embedding 矩阵查,thou / aaron / taco 去 Context 矩阵查。
第二步:把 not 的嵌入分别和三个上下文嵌入做点积。点积结果反映了两个嵌入的相似度。
第三步:点积本身可以是任意数值,得通过 sigmoid 把它压到 (0, 1) 区间,作为模型输出的”邻居概率”。
未训练时,sigmoid 后的”概率”很可能是错的(比如随机选的 taco 反而得分最高,aaron 最低)。这时拿出真实标签:
error = target - sigmoid_score
例如:
-
(not, thou) 标签 1,预测 0.45 → 误差 +0.55,应当增大它们的相似度; -
(not, aaron) 标签 0,预测 0.18 → 误差 -0.18,应当略微降低相似度; -
(not, taco) 标签 0,预测 0.78 → 误差 -0.78,应当大幅降低相似度。
第四步:用这些误差去更新 not / thou / aaron / taco 这 4 个词在两张矩阵中的嵌入,让下一次预测更接近目标。
这就完成了一步训练,参与的 4 个词的嵌入都向”更好”的方向走了一小步。
对所有正样本及其负样本重复这个过程,跑若干轮之后训练结束——Context 矩阵丢掉,Embedding 矩阵就是我们要的预训练词嵌入。
12. 窗口大小与负样本数量
word2vec 训练里有两个关键超参数。
窗口大小(window size)
不同任务适合不同的窗口。一个经验法则:
- 小窗口(2–15)
:相似度高的两个嵌入往往是可互换的词。注意:反义词也常常出现在相似的局部上下文里(比如 good和bad周围常常是同一类词),所以小窗口会把它们判断为高度相似——这未必是你想要的。 - 大窗口(15–50 甚至更多)
:相似度更多地反映”主题相关性”,而不是可互换性。
实际工程中,往往要根据具体任务的目标来选择并配合一些标注微调。Gensim 的默认窗口大小是 5(中心词前后各 5 个词)。
负样本数量(number of negative samples)
原 word2vec 论文给出的经验值是 5–20;当数据集足够大时,2–5 也够用。Gensim 默认是 5 个负样本。
13. 小结
“如果某事物超出了你的衡量标尺,那你面对的就是智能,而非自动化。”——《沙丘:神帝》
读到这里,你应该对词嵌入和 word2vec 算法有了直觉。当你之后看到论文里写 “skip-gram with negative sampling (SGNS)”——比如开头提到的那些推荐系统论文——也能很快意会其含义。
14. 扩展阅读
-
Distributed Representations of Words and Phrases and their Compositionality(Mikolov 等,word2vec 系列论文之一) -
Efficient Estimation of Word Representations in Vector Space(Mikolov 等,word2vec 经典论文) -
A Neural Probabilistic Language Model(Bengio 2003,神经语言模型奠基论文) - Speech and Language Processing
(Jurafsky & Martin),第 6 章覆盖 word2vec; - Neural Network Methods in Natural Language Processing
(Yoav Goldberg),值得一读的神经 NLP 教材; -
Chris McCormick 写过很多关于 word2vec 的好博客,并出版了《The Inner Workings of word2vec》电子书; -
想读源码?两个推荐:Gensim 的 Python 实现;Mikolov 的 原始 C 实现,或带 McCormick 详细注释的版本; -
Evaluating distributional models of compositional semantics -
Sebastian Ruder 的 On word embeddings, part 2 -
Dune(沙丘系列)——原文中的引言来源 🙂