 夜雨聆风
夜雨聆风





2026 AI 编程 Agent 深度分析:从自动补全到自主软件交付
报告由 InfiniSynapse AI Agent 自动生成,基于对 Cursor、OpenAI、Anthropic、GitHub/Microsoft 官方数据的深度调研与交叉验证。
链接: https://app.infinisynapse.com/tasks?taskId=96eb6c58-a324-440c-89fa-e16c66b40a3b&share=1
摘要
Cursor 的 Developer Habits Report 是目前公开可见、粒度最细的 AI 辅助软件开发遥测快照之一。数据表明,行业正从「自动补全式加速」转向更深的 Agent 工作流。报告基于真实开发者行为数据,可归纳为六大发现:(1) 马太效应——AI 红利高度集中于 1% 超级开发者;(2) 模型经济学——不同模型成本差异可达近 9 倍;(3) 巨型 PR——单次变更体量持续攀升;(4) 编码加速——人均产出在 18 个月内翻倍;(5) 上下文崛起——Token 消耗以读为主;(6) 自动化加深——无人工 diff 的自动接受率快速上升。
对 OpenAI Codex 、 Claude Code 、 GitHub Copilot 的交叉调研确认了同一方向的市场变化,但各产品的公开证据形态差异很大:
核心结论是:AI 编程工具正在收敛于 Agent 式软件交付,但没有单一公开指标能公平排名各产品。 Cursor 遥测展示 Agent 用法如何改变开发者行为; Copilot 研究展示可测的生产力与企业工作流效应; Claude Code 展示终端原生 Agent 工作流的快速 monetization 与用量增长; Codex 展示委派式云/CLI/IDE 编程任务的兴起。 SWE-bench Verified 、 Terminal-Bench 等 benchmark 应与生产遥测分开解读。
方法论与证据分级
本报告综合四类证据:
可比性规则
各产品暴露的分母不同:
因此本报告避免单一排行榜,仅在兼容族内比较:生产遥测、对照研究、 benchmark 、成本/定价、工作流能力。
1. Cursor :纵向遥测锚点
Cursor 2026 春季报告基于聚合的产品与工程数据: Agent 用法、 token 消耗、被接受的 AI diff 、已合并 PR 活动。多数时间序列图表使用 7/28/30 天 滚动均值,并排除 Privacy Mode 或零数据留存 opt-out 用户。
1.1 马太效应: AI 红利高度集中于 1% 超级开发者
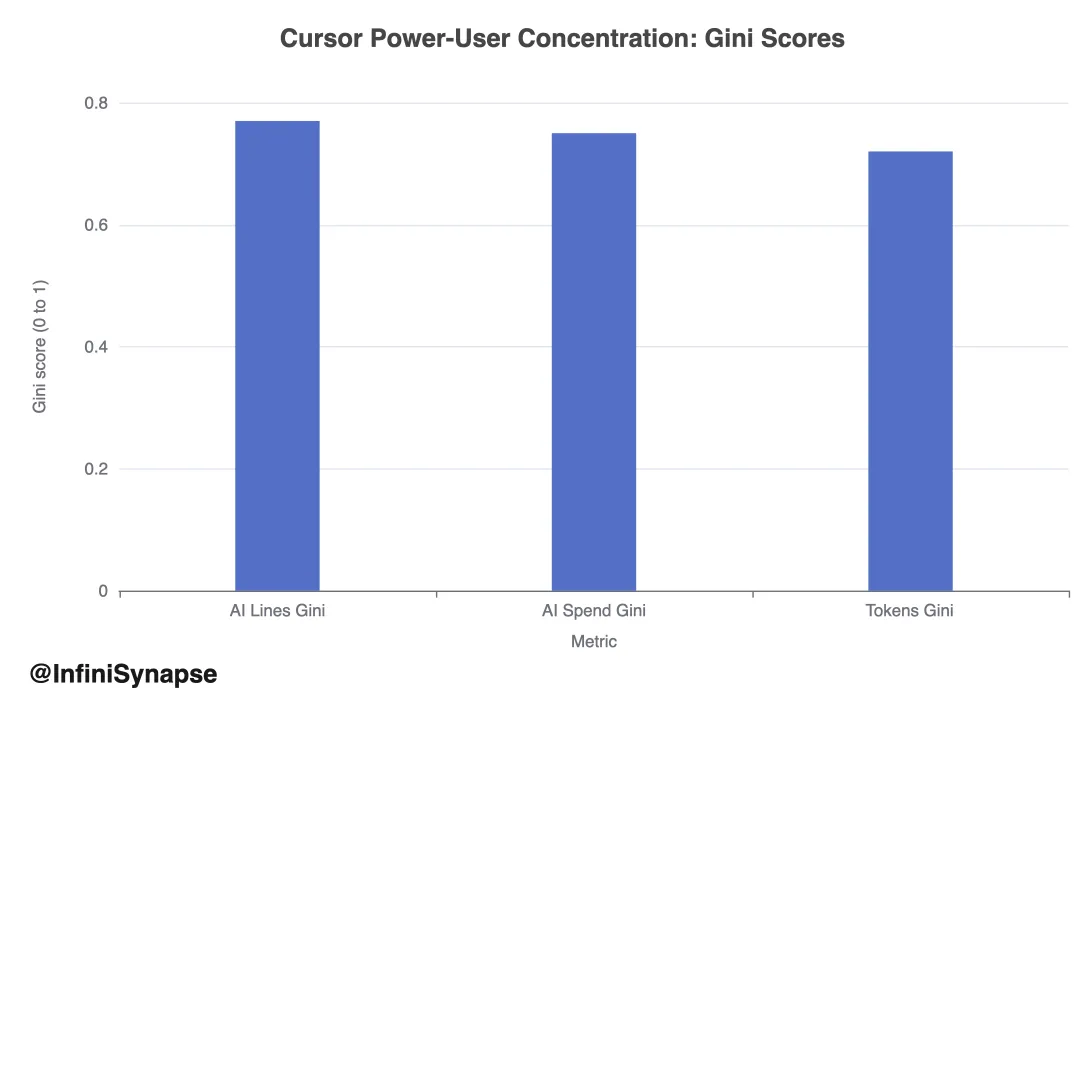
解读。 AI 编程生产力分布极不均匀。 Top 1% 用户似乎将 Agent 工具转化为远大于 median 开发者的绝对产出增益,支持「超级用户差距」论题:委派、审查、定范围、与 Agent 迭代的能力,可能成为工程组织内的重要分化因素。
1.2 模型经济学:成本差异与质量前沿
Cursor 报告在 request cost 、 accepted-line 效率与 CursorBench 分数上 benchmark 各模型家族。成本 spread 很大:
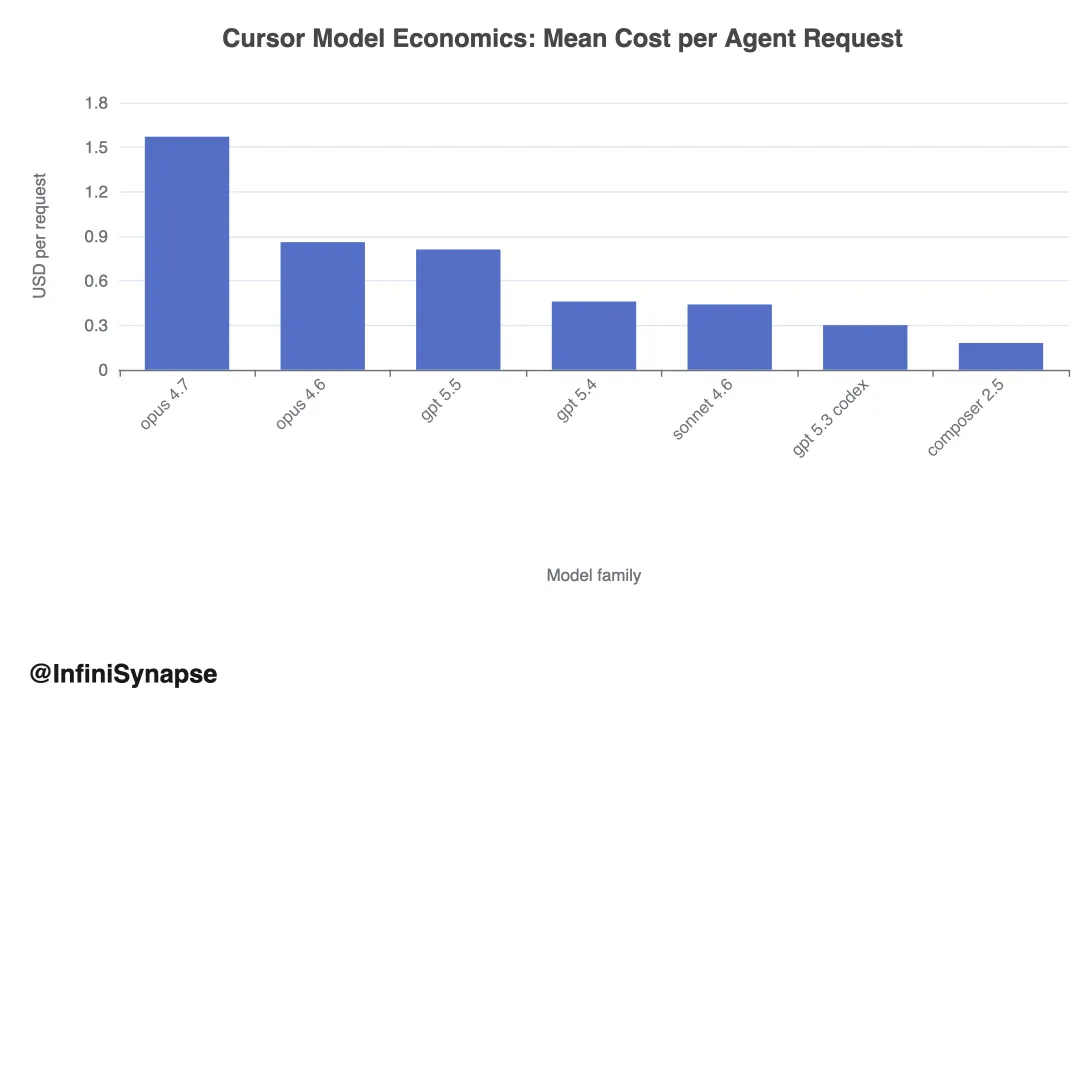
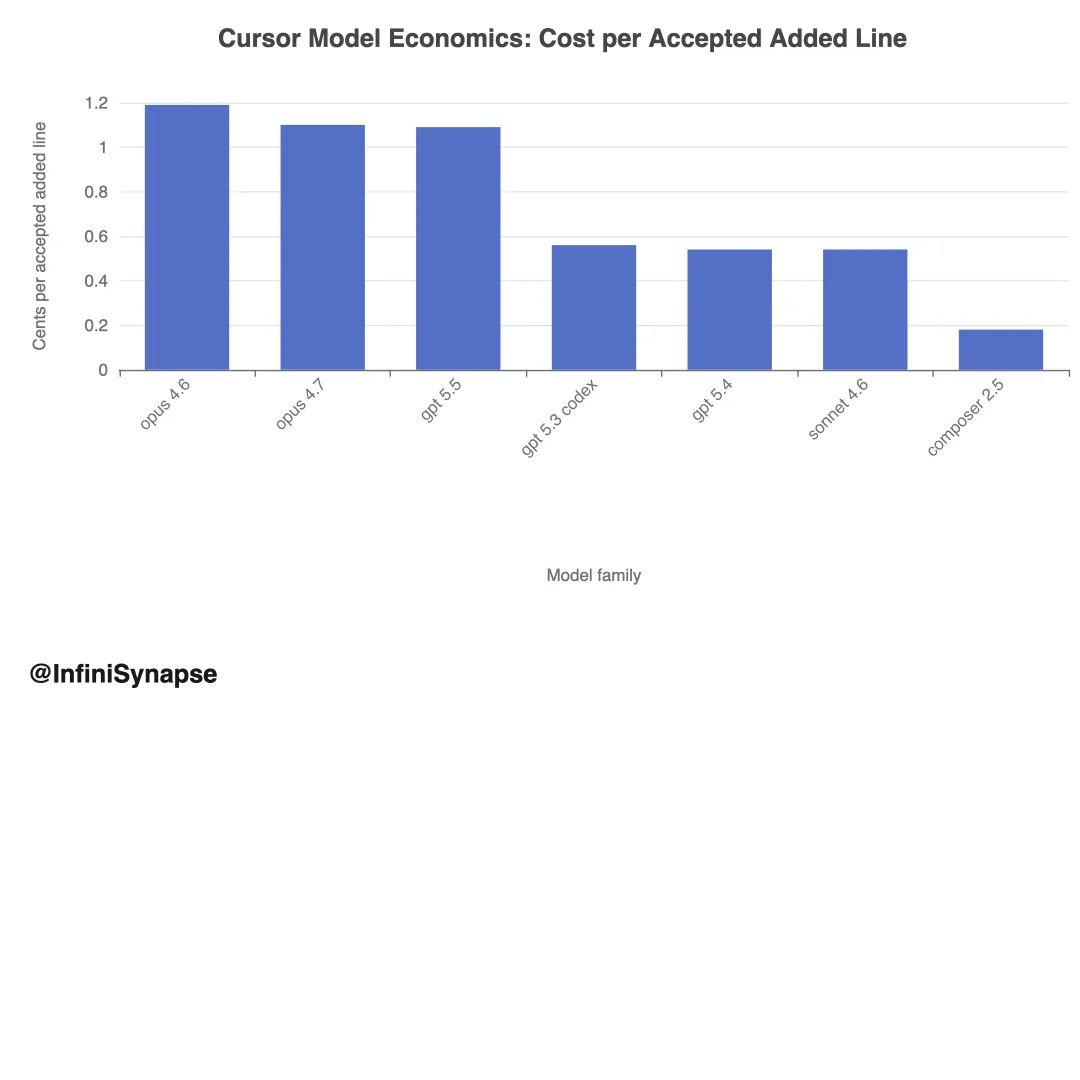
accepted-line 视角相对 request cost 缩小差距,说明部分高成本模型通过每次请求产出更多 accepted code 部分补偿。但排名仍取决于买方关心 request cost 、 accepted-line cost 还是 benchmark 质量。
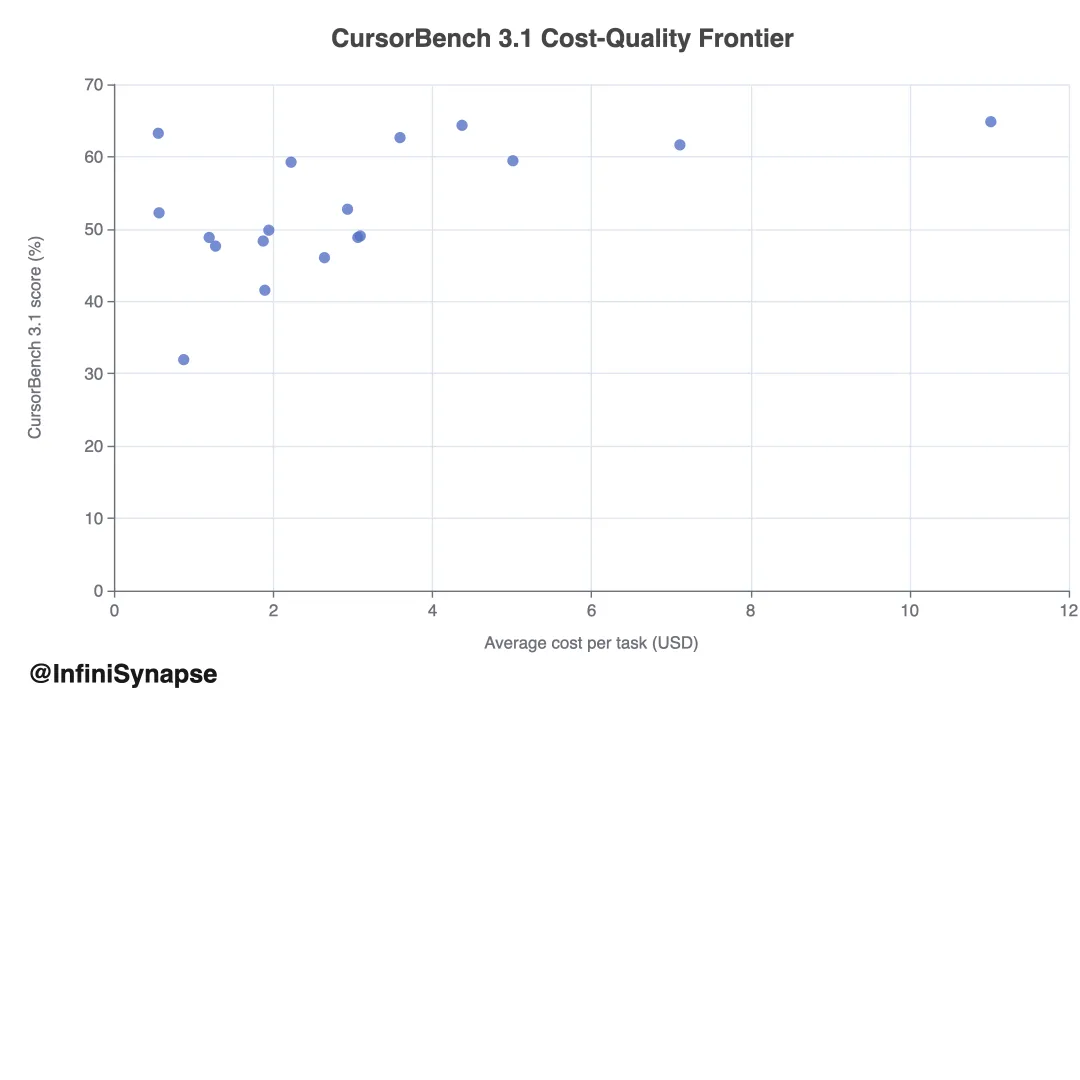
示例。 Composer 2.5 平均每任务 $0.55、 CursorBench 3.1 63.20%; Opus 4.7 Max 64.80% 但 $11.02/任务。边际质量增益可能极贵,最佳企业选择因任务关键性而异。
1.3 巨型 PR 规模持续扩大
解读。 开发者正在借助 AI 承担更大规模的单次工作单元。 PR 体量上升既是 Agent 能力增强的信号,也会放大 code review 与合并风险——组织需要相应的 review 流程与 CI 策略来匹配。
1.4 编码速度持续加速
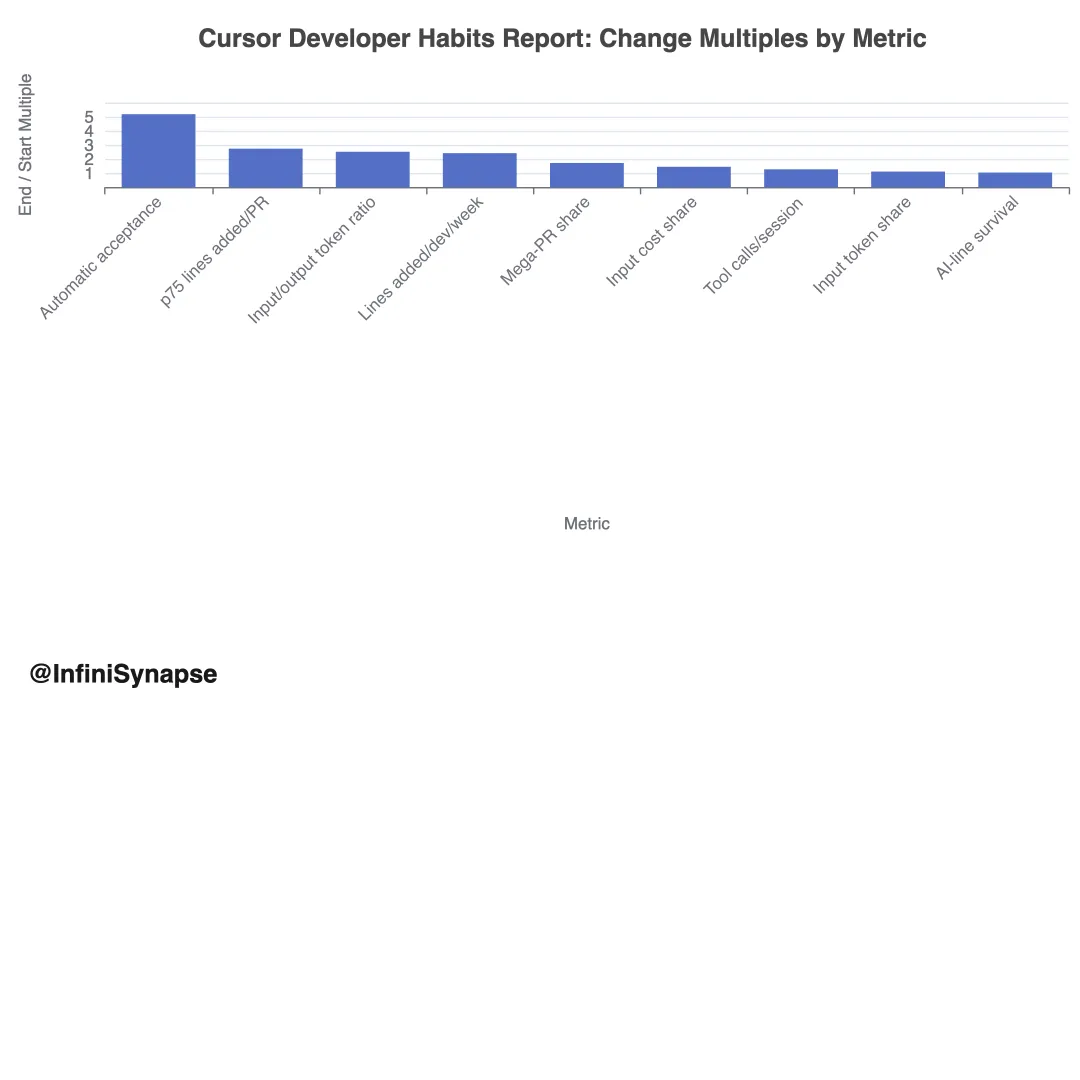
解读。 不到 18 个月内人均产出接近翻倍,且增速仍在加快。但「新增行数」仍是 imperfect 的生产力指标,可能反映有用工作、样板代码、 churn 、生成测试或大型迁移。
1.5 Agent 会话深度提升
解读。 Agent 正在承担越来越复杂的工作,涉及更多文件读写、代码搜索、 Shell 命令执行等操作——会话变深,而非 merely 补全变快。
1.6 AI 代码存活率提升
解读。 AI 生成代码被接受后,短期内被回滚或删改的比例在下降,意味着 Agent 产出正以更高比例留在真实代码库中。
1.7 上下文的崛起
解读。 Agent 编程 increasingly 「先读后写」。 Agent 需要仓库上下文、用户意图、文件历史、依赖信息、测试输出与工作流状态。 output token 不再是唯一 material 成本驱动; input context 、缓存策略与 context-window 管理成为产品经济学核心。
1.8 自动化加速
解读。 越来越多改动在无需单独人工 diff 步骤的情况下被直接接受, Automation agents 、安全审查自动化与 SDK runs 等系统级自动化曲线同步上升——AI 辅助正从个体工具向平台级工作流演进。
2. GitHub Copilot :最强的公开生产力研究基础
Copilot 缺少 Cursor 式纵向遥测报告,但有 unusually 强的公开研究证据。
2.1 对照生产力实验
2022 对照实验招募 95 名专业开发者实现 JavaScript HTTP 服务器。 Copilot 组快 55.00%(平均 1.18 vs 2.68 小时),完成率 78.00% vs 70.00%。结果强但窄:单一任务类型、单一语言、实验环境。
2.2 Accenture 企业遥测
解读。 Copilot 证据在遥测 + 对照/企业研究设计结合处最强。30.00% 建议接受有意义,但不应等同于 Cursor 80.58% 的 accepted AI-line 60 分钟存活率——前者测 accepted suggestions ,后者测已 accepted AI 行的短期 persistence 。
2.3 Copilot coding agent :工作流证据强于 benchmark 证据
官方材料描述 coding agent 可研究仓库、规划、改文件、在 GitHub Actions 环境跑测试/linter 、开 PR 、迭代反馈。但未找到官方 verified Copilot coding-agent SWE-bench 分数,本报告不 chart Copilot SWE-bench 。
3. Claude Code :快速 monetization 、清晰成本、强 Agent 工作流
Anthropic Claude Code 公开数据在 adoption 、成本、 benchmark 与企业就绪上最强。
3.1 Adoption 与用量增长
Series F 公告: Claude Code 已产生 >$500M run-rate 收入,全面发布后三个月用量 >10x。这是 striking 商业化信号,但不等于 active developer 数、 accepted-code volume 或生产力增益。
3.2 成本透明度
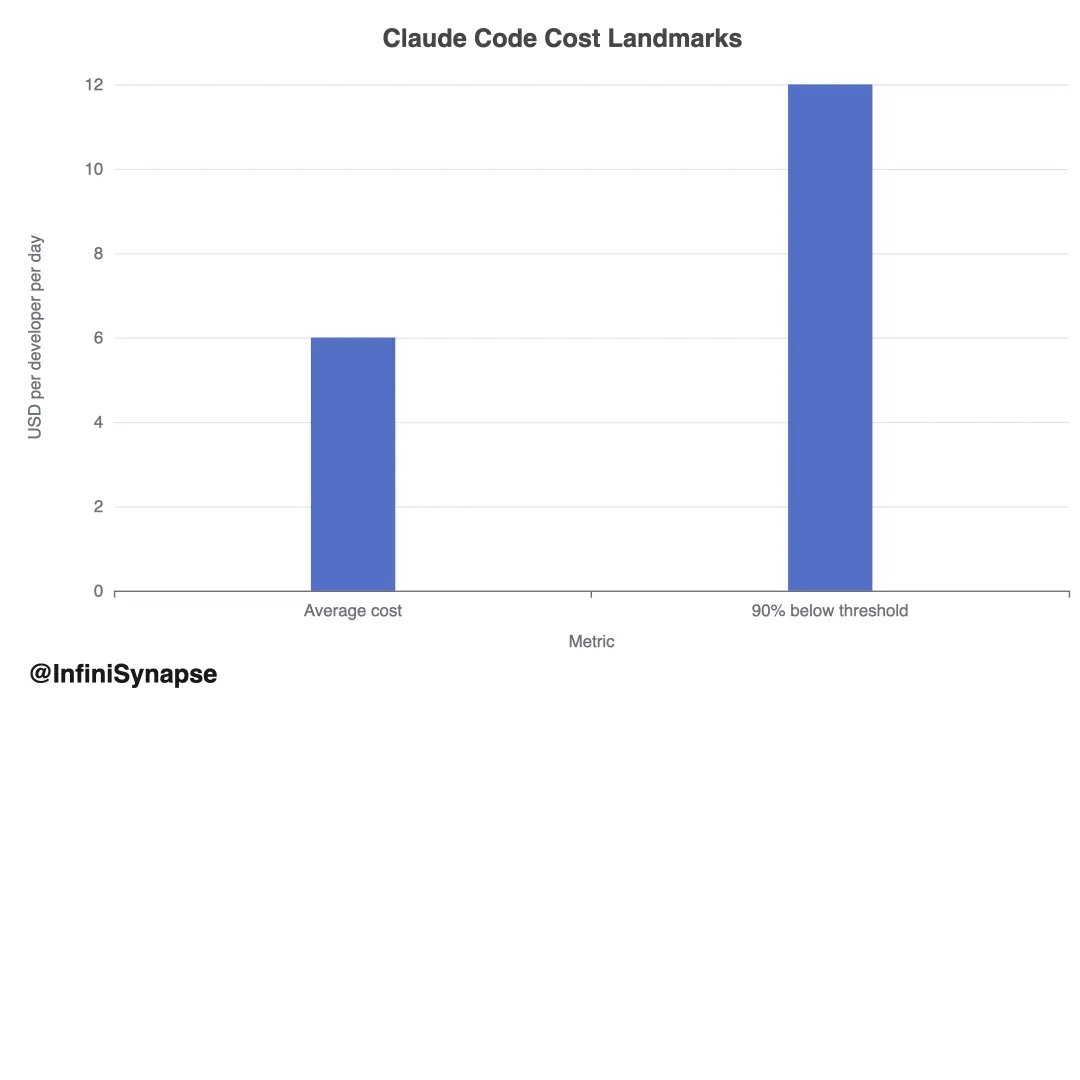
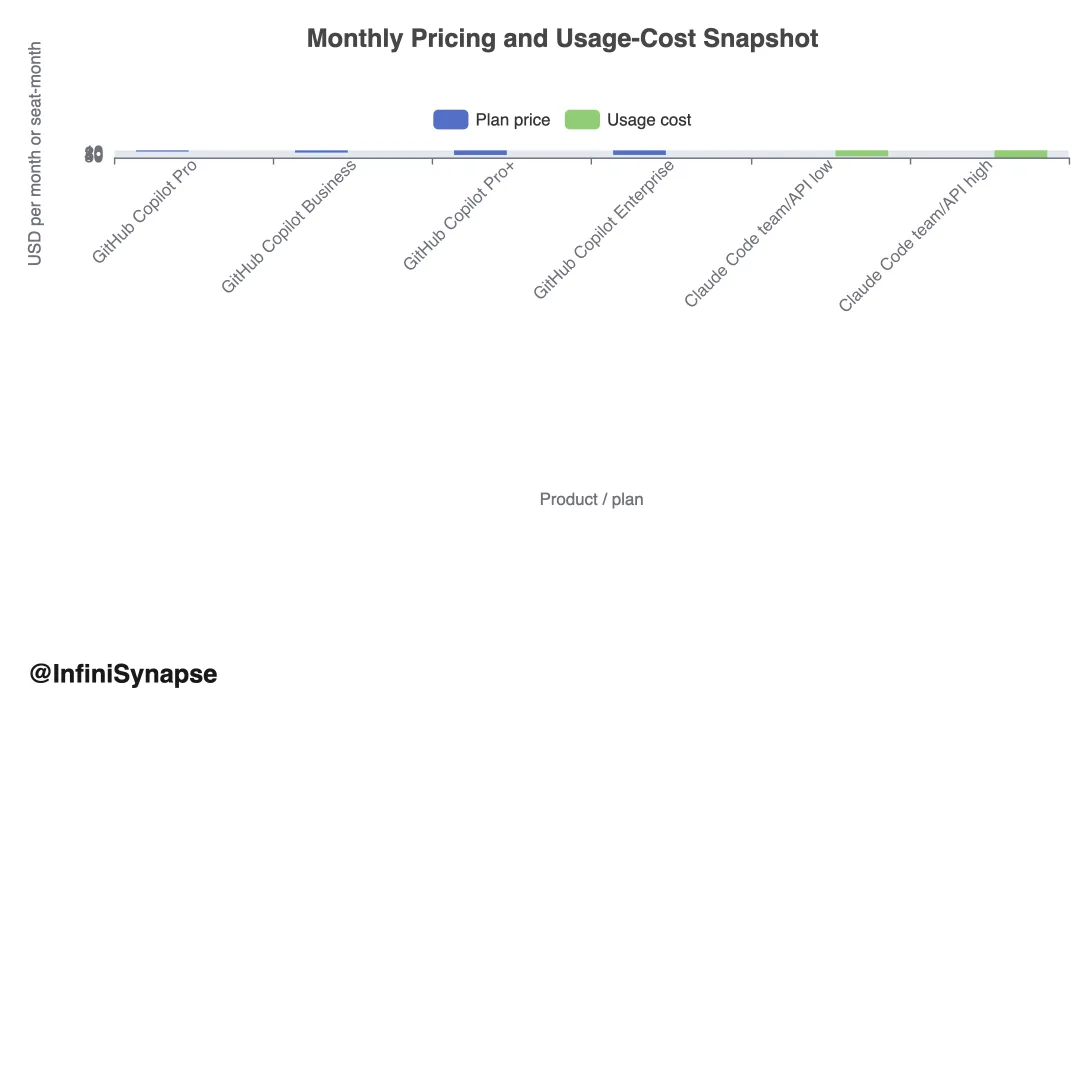
解读。 Claude Code 定价 best 理解为 usage-based ,非 mere 订阅价。平均日成本对许多团队 manageable ,但自动化与并行 session 可 materially 改变 spend 。
3.3 生产力数据多为 case-study 证据
Anthropic 发布内部与客户生产力增益示例。有用但应视为 case-study ,非 generalized 遥测。与 Cursor 可比的 accepted-code / retained-code 聚合未找到。
4. OpenAI Codex :异步任务 Agent 与工作流平台
官方文档: Codex 为 ChatGPT 各计划内的编程 Agent ,可写代码、解释陌生代码库、审查、调试并自动化重构、测试、迁移、 setup 等重复工作流。
4.1 Adoption 与 benchmark 信号
公开 adoption 信号含媒体报道的公司声明与开源/package 代理:
openai/codex stars 87,055、 forks 12,741(调研快照)不等同于 DAU 或 accepted production code 。下载、 stars 、 npm installs 可能含 CI 、重装、镜像或 curiosity adoption 。
4.2 Codex benchmark 证据
因此 Codex benchmark 作为 capability 证据展示,非 production-productivity 证据。
5. Benchmark 能力快照:有用,但不是遥测
SWE-bench Verified 、 Terminal-Bench 在受控条件下评估 issue 解析或终端任务完成,不直接测 accepted code 、 retained code 、 PR 合并率、开发者满意度或生产 defect rate 。
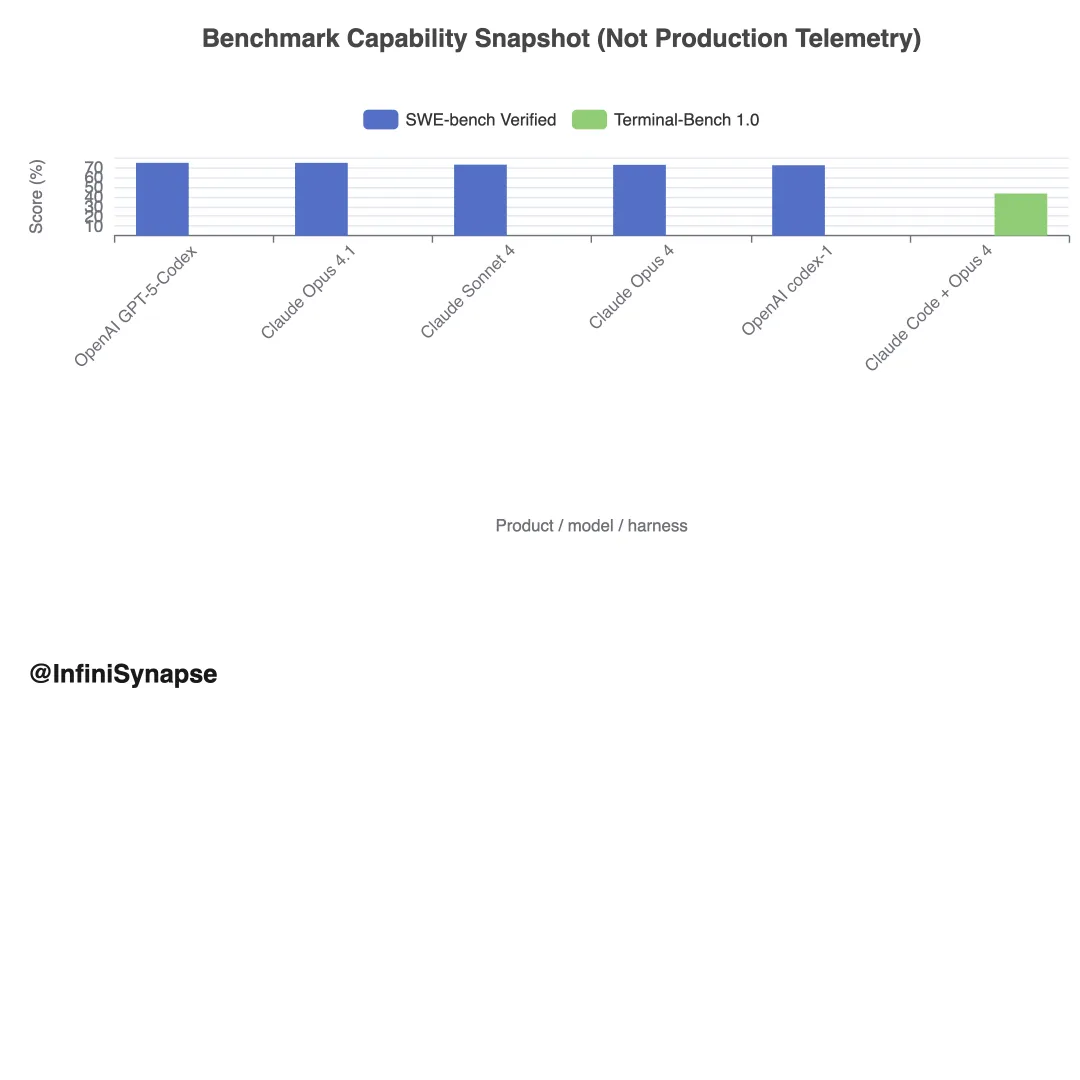
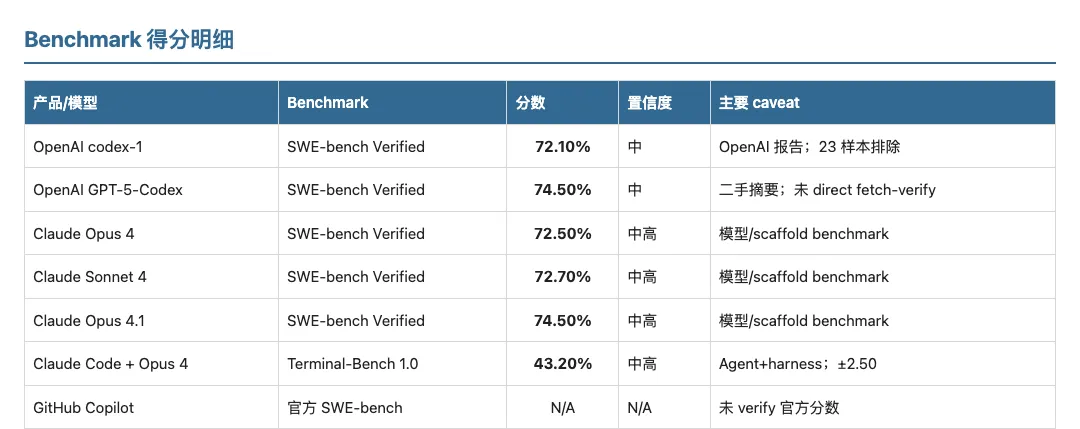
结论。 Benchmark 最适合受控条件下比较 Agent 能力,不应与 Cursor 生产遥测或 Copilot 企业研究结果混在同一排行榜。
6. 定价与成本:订阅价不是全部
6.1 GitHub Copilot 计划定价
6.2 Claude Code 用量成本
平均 $6/开发者/天; Team/API + Sonnet 4 约 $50–60/开发者/月。
6.3 OpenAI Codex API 参考定价
codex-mini-latest 报告 $1.50/1M input 、$6.00/1M output , prompt caching 75% 折扣。 ChatGPT 内 Codex primarily plan-based , API token 价不应视为 total user cost 。
定价结论。 企业应按完成任务、 accepted line 、 merged PR 、避免的 review cycle 、测试通过或 CI repair 归一化成本。 seat 价 alone 遗漏 token/context 成本与 Agent 自动化深度效应。
7. 工作流与自动化对比
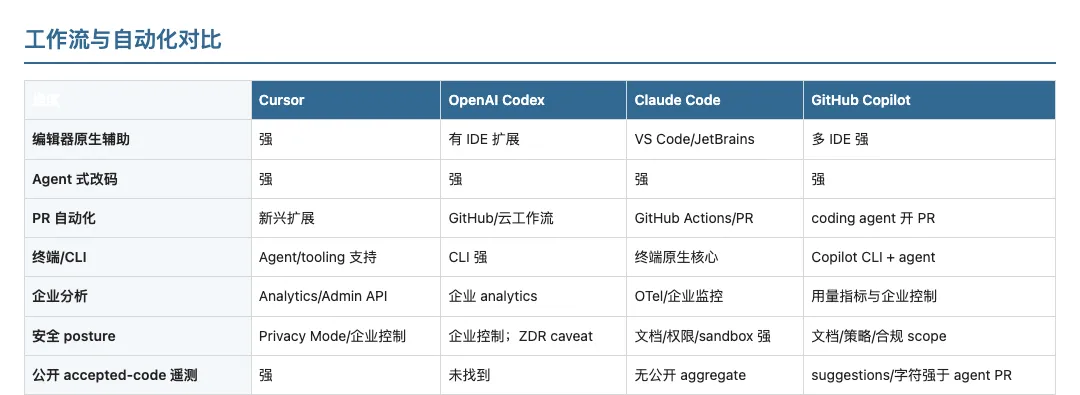
解读。 市场从孤立 IDE completion 移向集成软件交付系统:代码库搜索、规划、改文件、跑测试、生成 PR 、 review 、 CI repair 、自动化 hook 。差异化可能从 mere 模型质量转向 Agent harness 质量、 context 管理、企业治理、可观测性与工作流 fit 。
8. 战略启示
8.1 对工程负责人
AI coding-agent adoption 应多层测量:
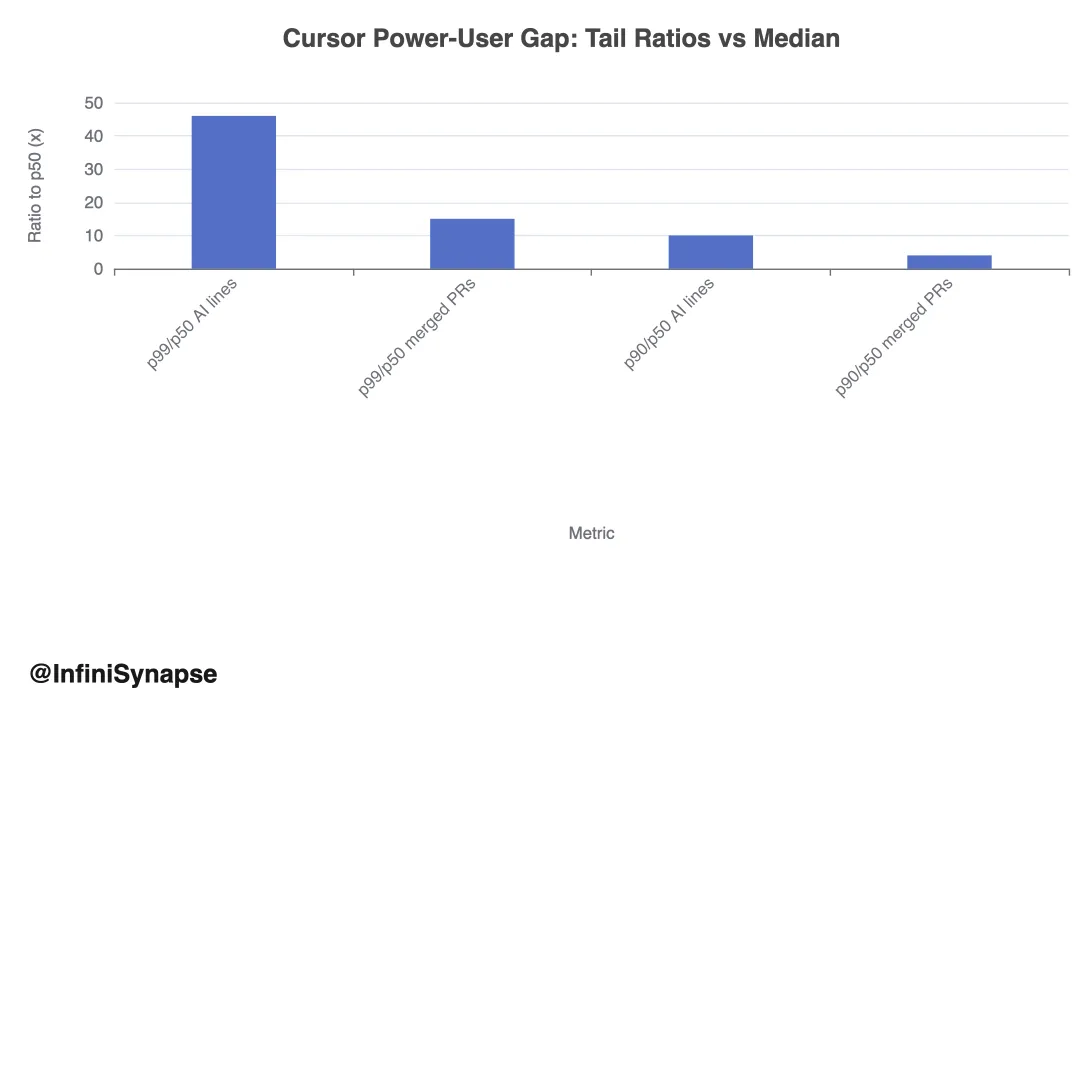
Cursor 报告说明 distribution 为何重要: P99/P50 达 AI 行 46x、 merged PR 15x。 rollout 不测 tail 可能隐藏 exceptional productivity 与 adoption gap 。
8.2 对平台团队
input/context token 与 cache-read 上升意味着应优化:仓库索引与检索、 prompt/instruction 管理、 cache 复用与 context compaction 、测试 harness 集成、安全 tool 权限、 Agent 决策可审计性。模型选择应 dynamic——Cursor 成本-质量前沿表明便宜模型对许多任务 optimal ,贵的高推理模式留给复杂/高风险/高价值工作。
8.3 对安全与治理团队
合规与 privacy 不保证生成代码安全。 GitHub responsible-AI 材料强调 review 、测试、 lint 、 SAST 、 SCA 、人工判断。 Agent 工作流新增风险: prompt injection 、 tool 误用、 secret 暴露、未 review 依赖变更、过度信任 generated diff 。
推荐治理控制:
9. 局限性
10. 结论
公开证据支持两点:
组织 adopting 这些工具, practical 建议不是基于单一 benchmark 或 marketing 指标选择,而是 measured rollout ,跟踪 accepted work 、 retained work 、 review burden 、 CI 质量、安全发现、每 outcome 成本与 P50/P90/P99 收益分布。