 夜雨聆风
夜雨聆风





告别文档乱成麻!软件公司用 Obsidian+Codex 搭 AI 知识库,效率翻倍(可直接落地)

一、为什么软件公司急需专属知识库?
几乎所有软件公司,都会陷入同一个知识管理死循环:
-
项目做完,经验清零:定制开发、外包项目结束后,踩坑记录、技术方案、BUG解决方案随人员离职流失
-
文档散落各处:聊天记录、本地文件、网盘、Git文档混杂,需要时根本找不到
-
新人上手极慢:没有标准化沉淀,全靠老员工口口相传,培训成本极高
-
重复造轮子:相同技术问题、方案设计、交付bug,不同项目反复踩坑
-
资料无法复用:售前方案、需求模板、技术组件、测试规范,无法快速复用迭代
很多团队尝试用飞书文档、Confluence搭建知识库,最终都沦为摆设型存档库:只存不用、杂乱无章、无人维护、越积越乱。
传统知识库的致命问题:需要人主动整理、主动复盘、主动归类,违背人性。
而今天给大家分享的 Obsidian + Codex AI 企业级知识库方案,彻底解决这个痛点:人负责创造内容,AI 负责全部整理、归类、关联、沉淀、复盘,完美适配软件公司标准化产品、定制开发、外包交付全业务场景。
二、 核心原理:双工具各司其职,打造团队第二大脑
这套方案无需服务器、无需复杂部署、数据本地可控、全程AI自动化,是目前软件公司性价比最高、落地最快、复用性最强的知识管理方案。
🔹 Obsidian:企业知识的专属存储载体
作为纯本地Markdown知识库,承担团队所有知识的底座:
-
存储项目文档、技术资产、需求方案、故障记录、复盘总结
-
支持双向链接、知识图谱,让零散知识形成关联体系
-
纯文件存储,不绑定平台、不锁数据,可随时备份迁移
🔹 Codex AI:知识库的智能运维管家
OpenAI官方AI代理,可直接读写本地知识库文件夹,实现全自动智能化运维:
-
自动归类所有零散文档,规范目录结构
-
自动打标准标签、生成内容摘要、建立双向关联链接
-
自动合并重复内容、清理无效文档与死链接
-
自动复盘项目、汇总BUG故障、沉淀可复用资产
-
自动脱敏客户信息、报价、密钥等涉密内容
一句话总结:Obsidian装知识,Codex活知识。
三、软件公司专属知识库架构(直接复刻即用)
准备工作:
1)安装 Obsidian
-
官网下载:https://obsidian.md/,完成安装。 -
新建保险库 (Vault),比如命名为 SoftDevBrain,选择本地文件夹存放(建议纯英文路径,避免中文乱码)。 -
必备社区插件(设置 → 第三方插件,关闭安全模式后安装): -
- Templates:笔记模板管理
- Dataview:数据视图、统计仪表盘
- Web Clipper:网页剪藏收集素材
- Tag Pane:标签管理
2)安装Codex
前面的文章已经说过如何安装以及接入国产大模型,在此就不赘述了,可以访问官网直接下载:https://openai.com/zh-Hans-CN/codex/
摒弃通用杂乱结构,针对软件研发、产品、售前、交付、测试全团队设计,适配标准化产品、定制项目、外包项目三大核心业务。
1、根目录命名:SoftDevBrain(软件研发智慧库)
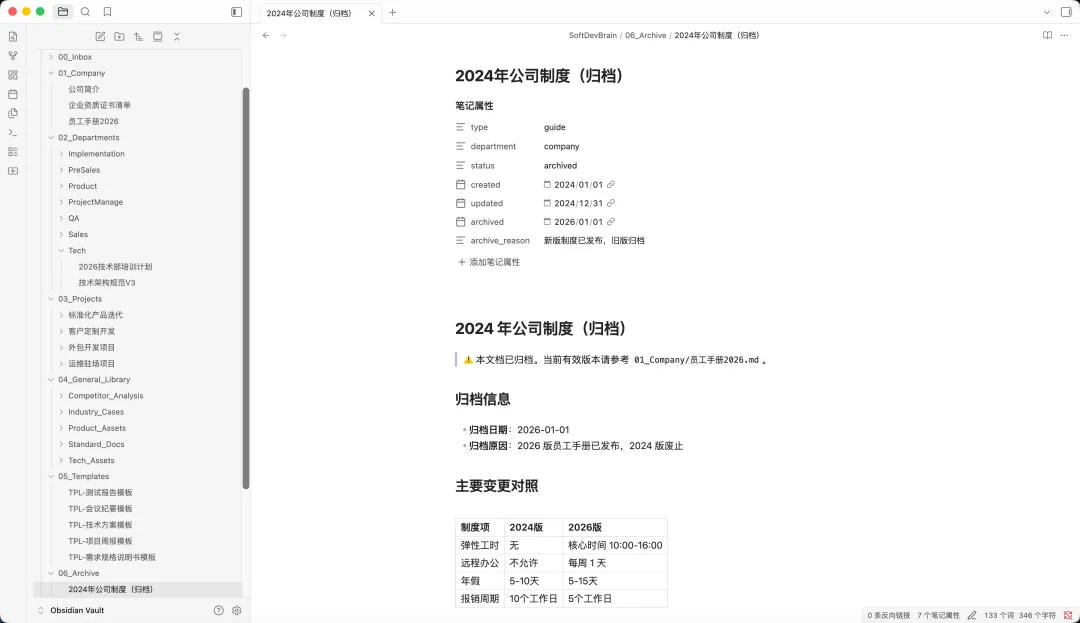
SoftDevBrain/├── COMPANY_RULES.md # 全局规范 + Codex 约束规则├── 00_Inbox # 全员收件箱:临时需求、会议纪要、沟通记录、资料草稿├── 01_Company # 公司公共资料│ ├── 组织制度│ ├── 企业资质 & 证书│ ├── 对外宣传资料│ └── 通用行政文档├── 02_Departments # 部门专属知识库│ ├── Tech # 技术部:架构、源码、接口、故障、运维、技术调研│ ├── Product # 产品部:标准化产品、需求、原型、迭代规划│ ├── Sales # 销售部:客户线索、跟进记录、报价、商务谈判│ ├── PreSales # 售前部:方案、PPT、案例、技术应答│ ├── ProjectManage # 项目管理:排期、里程碑、风险、周报月报│ ├── Implementation # 实施/交付部:部署、上线、现场问题、验收资料│ └── QA # 测试部:用例、BUG、测试报告、回归记录├── 03_Projects # 项目库(核心,按独立项目隔离)│ ├── 标准化产品迭代项目│ ├── 客户定制开发项目│ ├── 外包开发项目│ └── 运维驻场项目├── 04_General_Library # 通用资产库(全团队复用核心沉淀)│ ├── Product_Assets # 标准化产品资产│ │ ├── 产品手册│ │ ├── 功能清单│ │ ├── 版本迭代记录│ │ └── 操作教程│ ├── Tech_Assets # 技术资产(全公司通用)│ │ ├── 技术选型│ │ ├── 公共组件/框架│ │ ├── 编码规范│ │ ├── 中间件部署文档│ │ └── 通用接口方案│ ├── Industry_Cases # 行业解决方案 & 落地案例│ ├── Standard_Docs # 通用合同、协议、授权函、标准文书│ └── Competitor_Analysis # 竞品调研、行业产品对比├── 05_Templates # 全公司统一模板库├── 06_Archive # 归档区│ ├── 已结项项目│ ├── 旧版本文档/废弃方案│ ├── 历史BUG&故障归档│ └── 离职人员资料└── 07_Admin # 运维管理区├── Auto_Script # Codex 自动化脚本├── Backup_Log # 备份日志└── Tag_List.md # 全局标签规范2、全局规则文件COMPANY_RULES.md
# 通用软件公司知识库 使用规范 & Codex 处理规则## 一、文件命名规范(强制统一)格式:`YYYY-MM-DD - [部门/项目/分类] - 标题.md`示例:2026-06-08 - Tech - 微服务架构设计.md2026-06-08 - PreSales - XX客户项目方案.md2026-06-08 - Project - XX系统定制开发周报.md## 二、目录使用权责1. **00_Inbox**:所有临时内容、沟通记录、需求草稿、BUG记录、外部资料,必须先存入此处,禁止直接写入正式目录。2. **01_Company**:公司资质、制度、宣传材料,全员可读,仅行政/管理员编辑。3. **02_Departments**:各部门独立知识资产,跨部门仅查阅,无修改权限。4. **03_Projects**:按单个项目建独立文件夹,存放立项、需求、开发、测试、实施、验收全生命周期资料,项目成员专属维护。5. **04_General_Library**:全公司可复用资产,包括产品资料、技术组件、行业案例、标准合同,鼓励全员沉淀、复用。6. **05_Templates**:公司统一模板,对外输出、内部流程文档必须套用。7. **06_Archive**:完结项目、过期文档、废弃方案统一归档,仅查询不日常编辑。8. **07_Admin**:脚本、日志、标签规范,由知识库管理员维护。## 三、标签体系规则统一格式:`#分类-模块-文档类型`,所有文档必须打标签。## 四、Codex AI 强制处理规则1. 执行操作前优先阅读本规则,严格遵循目录、命名、标签规范。2. 区分**标准化产品、定制项目、外包项目**三大类型,精准分类归档。3. 自动生成80~120字摘要,为关联文档建立双向链接,方便溯源查阅。4. 客户信息、商务报价、核心源码密钥、涉密需求自动脱敏处理。5. 重复文档、冗余内容自动合并,空文件、无效链接定期清理。6. 可复用的方案、代码逻辑、流程文档,主动归集到 `04_General_Library`。7. 无法判定归属的内容,保留在 00_Inbox 并标注【待人工审核】。8. 项目结项后,自动梳理可复用资产,再迁移至归档目录。## 五、安全与协作规范1. 核心技术架构、未公开产品规划、客户涉密资料,严格限制访问权限。2. 全库基于私有 Git 做版本管理,所有修改留痕,支持回溯。3. 每周执行全库备份,日志统一存入 07_Admin/Backup_Log。4. 版本迭代、需求变更、BUG 修复全程记录,保证项目可追溯。3、全局标签页07_Admin/Tag_List.md
# 通用软件知识库 统一标签清单## 一、项目类型标签#标准化产品 #定制开发项目 #外包项目 #运维项目## 二、部门标签#技术部 #产品部 #销售部 #售前部 #项目管理部 #实施部 #测试部## 三、内容模块标签#需求 #原型 #架构设计 #编码规范 #组件 #接口 #部署 #运维#BUG #测试用例 #测试报告 #故障复盘#方案文档 #PPT文案 #报价单 #合同协议 #客户档案#项目周报 #里程碑 #风险记录 #项目复盘#行业案例 #竞品分析 #技术调研## 组合使用示例#定制项目-技术-接口文档#标准化产品-产品-迭代规划#外包项目-测试-BUG记录#售前-方案-行业案例知识图谱: 核心设计亮点

-
00_Inbox统一入口:所有会议纪要、需求草稿、BUG记录、客户沟通记录,无需分类,全部丢入此处,AI自动处理
-
04_通用资产库:从所有项目中沉淀可复用模板、组件、方案,彻底杜绝重复造轮子
-
项目完全隔离:不同客户、不同项目资料独立存放,权限可控、互不干扰
-
全流程闭环:从线索需求→研发交付→项目复盘→资产沉淀,形成完整知识闭环
四、全团队标准化工作流(每日落地流程)
这套工作流适配软件公司所有岗位,零学习成本,AI全程自动化。
1. 收集阶段:全员无脑存入
所有零散内容,无需整理、无需分类,统一放入 00_Inbox:
-
产品:零散需求、原型备注、迭代想法
-
技术:踩坑记录、接口问题、部署报错
-
售前:客户需求、沟通纪要、方案草稿
-
交付:现场问题、验收要点、实施日志
-
测试:BUG记录、测试疑问、回归问题
2. 自动化整理:AI全权接管
每日定时执行Codex指令,自动完成所有繁琐工作:
-
自动区分标准化产品/定制项目/外包项目,精准分类归档
-
自动匹配公司统一标签,生成规范摘要
-
自动关联同类文档、建立双向链接,构建知识图谱
-
自动脱敏报价、客户隐私、密钥等涉密信息
-
合并重复内容,清理无效空文档、死链接
3. 资产沉淀:项目结项自动萃取
项目结束后,AI自动梳理:
-
提取可复用技术组件、解决方案、需求模板
-
沉淀BUG高频问题与规避方案
-
将通用资产归入公共库,项目原始资料归档备份
4. 复用查询:全员随时调用
新人接手、新项目启动、客户答疑,直接让AI检索知识库:
-
查询同类项目解决方案
-
汇总历史故障与修复方案
-
快速生成标准化需求、方案、周报文档
自动化脚本:
1、Windows 脚本 07_Admin/Auto_Script/Auto_Run.bat
@echo offecho 开始执行通用软件知识库自动整理...cd /d "%~dp0\..\"codex -c "处理00_Inbox所有内容,区分标准化产品、定制项目、外包项目分类归档;按标签规范打标、生成摘要、建立双向链接;客户信息、报价、密钥等涉密内容脱敏;合并重复文档,无法归类内容标注【待审核】,严格遵守COMPANY_RULES.md"echo 整理完成,记录日志echo 执行时间:%date% %time% >> "07_Admin/Backup_Log/Run_Log.txt"pause
2、Mac/Linux 脚本 07_Admin/Auto_Script/auto_run.sh
#!/bin/bashecho "===== 软件知识库自动整理启动 ====="cd "$(dirname "$0")/../"codex -c "处理00_Inbox所有内容,区分标准化产品、定制项目、外包项目分类归档;按标签规范打标、生成摘要、建立双向链接;客户信息、报价、密钥等涉密内容脱敏;合并重复文档,无法归类内容标注【待审核】,严格遵守COMPANY_RULES.md"echo "$(date) 自动整理执行完毕" >> 07_Admin/Backup_Log/Run_Log.txt
执行授权:chmod +x auto_run.sh
五、软件公司高频AI指令(直接复制即用)
适配售前、产品、技术、交付、管理全场景,无需手动调整,严格匹配公司知识库规范。
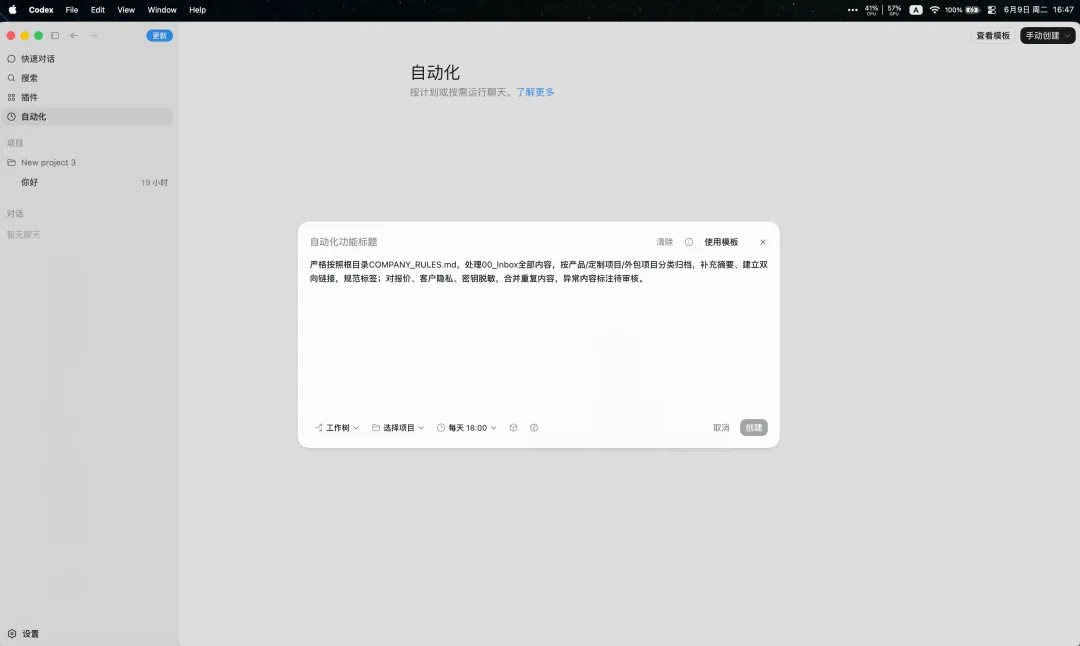
✅ 每日自动整理(全员通用)
严格按照根目录COMPANY_RULES.md,处理00_Inbox全部内容,按标准化产品、定制项目、外包项目分类归档,补充摘要、建立双向链接,规范标签;对报价、客户隐私、密钥脱敏,合并重复内容,异常内容标注待审核。✅ 售前方案自动生成
基于Inbox内客户需求资料,套用05_Templates/项目方案模板生成完整解决方案;自动关联04_General_Library内同类行业案例、标准方案、产品手册,优化内容并补充风险说明。✅ 需求文档标准化梳理
整理当前项目零散需求、沟通记录,套用需求文档模板统一格式化;梳理功能清单、非功能要求,关联原型与评审记录,归类至对应项目目录。✅ 批量故障/BUG分析
统计近30天所有BUG、线上故障,按项目/模块分类,梳理高频问题TOP5,分析共性根因,并给出编码、流程、测试环节的优化建议。✅ 项目结项资产归集
对指定项目文件夹做结项梳理,提取可复用组件、方案、流程、模板,迁移至04_General_Library;剩余全部文档整理后移入06_Archive,生成简短结项总结。场景 1:自动归类零散文档,规范目录结构
提示词模板:
请扫描 /Users/gaoguosheng/Documents/Obsidian Vault/SoftDevBrain/00_Inbox/ 目录下的所有 .md 文件,根据 COMPANY_RULES.md 中的目录规范,执行以下操作:1. 读取每个文件,分析其 frontmatter(department、type、project 字段)和正文内容2. 按以下规则归类:- 属于特定部门的 → 移入 02_Departments/{部门名}/- 属于特定项目的 → 移入 03_Projects/{项目类型}/{项目名}/- 属于公司级公共资料的 → 移入 01_Company/- 是可复用资产的 → 移入 04_General_Library/对应子目录- 是模板的 → 移入 05_Templates/3. 对于无法自动归类的文件,列出清单并给出建议归类方案,等待我确认后再执行4. 生成一份归类报告,包含:原路径 → 新路径的映射表5. 操作前先给出变更预览,我确认后再执行
进阶版(全自动 + 智能判断):
请对 00_Inbox/ 下的所有文件进行智能分类:- 用 NLP 分析正文语义,判断文档类型(需求文档/技术方案/会议纪要/周报/报告/规范)- 自动补充或修正 frontmatter 中的 type 和 department 字段- 对于缺少 project 字段的项目文档,根据内容推断项目名称并补全- 文件命名不符合 YYYY-MM-DD_标题 格式的,自动重命名- 将归类的文件移动到正确的目录- 生成变更日志:变更了什么、为什么这样归类、有哪些不确定项先输出分析报告,不要直接执行,我确认后再操作。
场景 2:自动打标准标签、生成摘要、建立双向链接
提示词模板:
请扫描以下目录中所有缺少完整 frontmatter 的 .md 文件(目标目录可以是整个知识库或指定子目录):目标目录:/Users/gaoguosheng/Documents/Obsidian Vault/SoftDevBrain/对于每个文件,执行以下操作:1. 【标签补全】根据文件内容和目录位置,自动补充或修正 frontmatter:- type: 根据文档内容语义判断(guide/spec/case/template/meeting/report)- department: 根据所在目录或内容判断- status: 根据文档时效性判断(draft/active/archived)- project: 如果内容明确关联某个项目则填写- 缺少 created/updated/author 的也一并补全2. 【内容摘要】在正文开头(frontmatter 之后、原标题之下)添加一段 AI 生成的摘要:> **📋 AI 摘要**:{50-100字的中文摘要,概括核心内容}3. 【双向链接】在文档末尾添加 ## 🔗 相关文档 区块:- 通过内容相似度分析,列出知识库中相关的 3-5 篇文档- 使用 Obsidian 双向链接语法 [[文档名]]- 同时在目标文档的末尾也添加反向链接4. 生成一份处理报告,列出每个文件的变更详情先处理 3 个文件作为示例,让我确认效果后再批量执行。
场景 3:自动合并重复内容、清理无效文档与死链接
提示词模板:
请对整个知识库执行重复内容检测和清理:1. 【重复内容检测】- 遍历所有 .md 文件,计算文档间的文本相似度(余弦相似度/Jaccard)- 标记相似度 > 70% 的文档对- 对于高度重复的文档,分析:* 哪个版本更新(比较 updated 字段)* 哪个内容更完整(比较字数、结构完整性)* 哪个位于更合适的目录- 给出合并建议:保留哪个、归档哪个、是否需要手动审阅2. 【死链接检测】- 扫描所有文档中的 Obsidian 双向链接 [[xxx]] 语法- 检查目标文件是否存在- 列出所有无效链接(目标文件不存在)- 对于无效链接,尝试智能匹配最相似的现有文档并建议替换3. 【无效文档标记】- 标记 status: archived 且超过 2 年的文档- 标记内容过短(< 50 字)的非模板文档- 标记只有标题没有正文的"僵尸文档"4. 输出清理方案报告,分类为:- 🟢 可安全自动处理的- 🟡 需要确认的- 🔴 必须人工审阅的仅输出报告,不要执行任何修改。
场景 4:自动复盘项目、汇总 BUG 故障、沉淀可复用资产
提示词模板:
请对 03_Projects/ 下的所有项目执行自动复盘分析:1. 【项目健康度评估】- 分析每个项目最近的周报/月报/测试报告- 提取关键指标:进度偏差、Bug数量趋势、风险项- 生成项目健康度评分(红/黄/绿)2. 【BUG 故障汇总】- 扫描所有 QA 和项目目录下的测试报告、Bug统计- 按严重程度(P0/P1/P2/P3)分类汇总- 按模块/功能点聚类,识别高频故障区域- 生成 TOP 10 高频 Bug 列表及修复状态3. 【可复用资产沉淀】- 从项目文档中识别以下可复用内容:* 技术解决方案 → 建议沉淀到 04_General_Library/Tech_Assets/* 行业经验总结 → 建议沉淀到 04_General_Library/Industry_Cases/* 合同/协议模板 → 建议沉淀到 04_General_Library/Standard_Docs/* 竞品信息 → 建议沉淀到 04_General_Library/Competitor_Analysis/- 为每个可沉淀内容生成一份结构化摘要- 建议目标路径和文件名4. 生成一份综合运维复盘报告,保存到 07_Admin/复盘报告_YYYY-MM-DD.md先输出分析结果,我确认后再执行文件创建/移动操作。
场景 5:自动脱敏客户信息、报价、密钥等涉密内容
提示词模板:
请扫描整个知识库中标记了 🔒 confidential 或可能包含涉密信息的文档,执行以下敏感信息检测:1. 【敏感信息检测规则】- 客户全名/公司名(非公开案例中出现的)- 手机号(1[3-9]\d{9})- 身份证号(\d{17}[\dXx])- 邮箱地址(xxx@xxx.xxx)- 报价金额/合同金额(金额数字 + "万/元" 上下文)- API Key / Token / 密码 / Access Secret- 内网 IP / 服务器地址- 银行账号2. 【脱敏处理】对检测到的敏感信息,按以下规则替换:- 客户名 → "客户A"/"某三甲医院" 等泛化名称- 手机号 → "138****1234"- 邮箱 → "xxx@***.com"- 金额 → "[涉密金额]"- 密钥 → "[已脱敏]"- IP → "10.x.x.x"3. 【标记处理】- 在文档 frontmatter 中添加 tags: ["🔒 confidential"]- 在脱敏处用 <!-- 原始值: xxx --> 添加 HTML 注释(仅内部可见)4. 生成脱敏报告,列出:- 文件名 + 检测到的敏感信息类型- 脱敏前后的对比- 是否有遗漏的敏感信息需要人工确认先对 00_Inbox/ 目录执行,确认效果后再扩展到全库。
一键全自动:
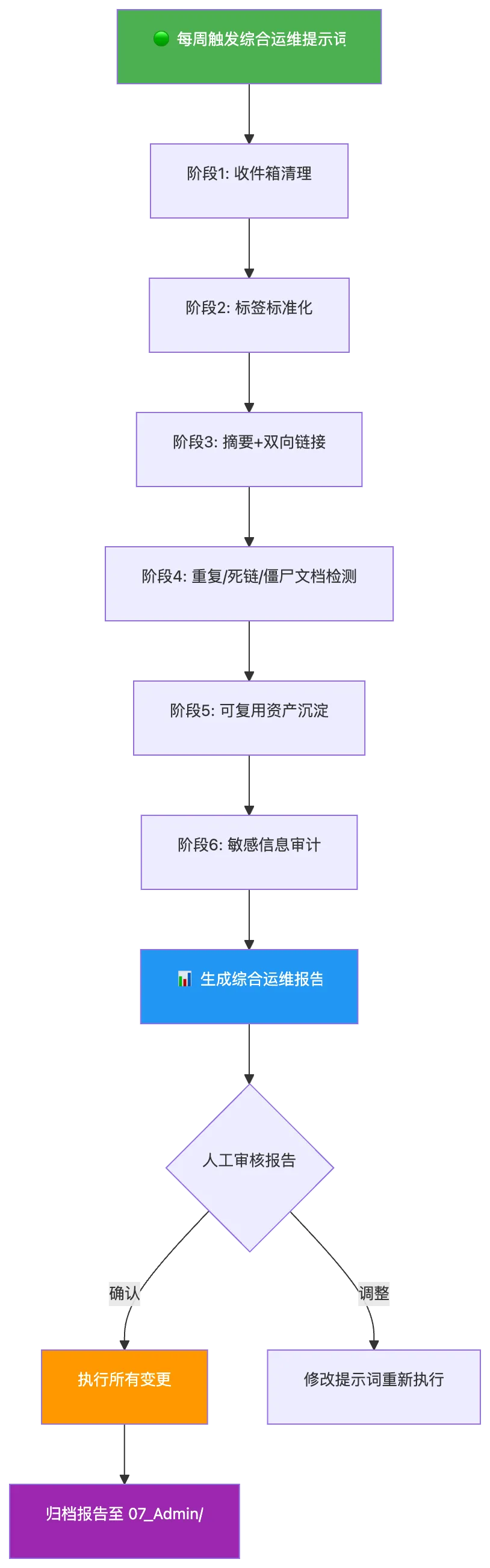
提示词模板:
你是一个知识库运维专家 AI。请对 /Users/gaoguosheng/Documents/Obsidian Vault/SoftDevBrain/执行全面的自动化运维任务,严格遵守 COMPANY_RULES.md 中的规范。请按以下顺序分阶段执行,每个阶段完成后输出报告并等待我确认:## 阶段 1:收件箱清理- 扫描 00_Inbox/ 中的所有文件- 智能分类并移动到正确目录- 报告:归类映射表## 阶段 2:标签与元数据标准化- 扫描全库缺少/不规范的 frontmatter- 自动补全 type/department/status/project/created/updated/author- 报告:修改清单## 阶段 3:内容增强- 为每个文件生成 AI 摘要(50-100字)- 建立双向关联链接 [[相关文档]]- 报告:新增链接清单## 阶段 4:质量检测- 检测重复内容(相似度 > 70%)- 检测死链接 [[不存在的文档]]- 检测僵尸文档(内容 < 50字)- 报告:质量问题清单## 阶段 5:资产沉淀- 识别可复用内容- 建议沉淀到 04_General_Library/ 的路径- 报告:资产沉淀建议## 阶段 6:安全审计- 检测敏感信息(手机/邮箱/金额/密钥)- 建议脱敏处理方案- 报告:敏感信息清单## 最终输出生成一份综合运维报告,保存到 07_Admin/综合运维报告_YYYY-MM-DD.md每个阶段先输出预览,确认后再执行。遇到不确定的情况标注 🟡 等待人工决策。
六、配套标准化模板(覆盖软件公司全场景)
我们已为软件公司配齐全套落地模板,统一团队输出标准:
-
项目解决方案模板
-
软件需求规格说明书模板
-
BUG/问题跟踪单模板
-
项目周报/月报模板
-
项目复盘模板
-
技术故障复盘模板
-
会议纪要模板
所有模板强制AI自动套用,彻底解决文档格式混乱、内容残缺的问题。
模板 1:项目方案模板.md
# 项目解决方案**客户名称**:**项目类型**:□标准化产品 □定制开发 □外包开发**编制日期**:## 一、项目背景与客户需求## 二、现状分析与痛点## 三、总体建设目标## 四、系统整体架构## 五、核心功能模块说明## 六、技术路线与选型## 七、项目实施计划 & 里程碑## 八、交付内容与标准## 九、售后服务与运维保障## 十、风险分析与应对措施参考案例/模板:[[ ]]标签:
模板 2:需求文档模板.md
# 软件需求规格说明书**归属项目/产品**:**版本**:**编写人**:**日期**:## 一、引言1.1 项目概述1.2 编写目的1.3 读者对象## 二、整体业务描述## 三、功能需求(模块+功能点+交互规则)## 四、非功能需求(性能、安全、兼容性、并发)## 五、接口需求## 六、约束与依赖## 七、需求变更记录关联原型/评审记录:[[ ]]标签:
模板 3:BUG / 问题记录单.md
# BUG/问题跟踪单**所属系统/项目**:**发现人**:**发现时间**:**严重等级**:□致命 □严重 □一般 □建议## 一、问题描述## 二、复现步骤## 三、预期结果 & 实际结果## 四、环境信息## 五、原因分析## 六、修复方案 & 修复人## 七、测试验证结果## 八、优化建议关联故障文档:[[ ]]标签:
模板 4:项目周报模板.md
# 项目周报**项目名称**:**汇报周期**:**汇报人**:## 一、本周工作完成情况## 二、下周工作计划## 三、当前进度 & 里程碑状态## 四、现存问题 & 风险## 五、需要协调的资源关联项目文档:[[ ]]标签:
模板 5:项目复盘模板.md
# 项目复盘报告**项目名称**:**项目周期**:**参与人员**:## 一、目标回顾与达成情况## 二、做得好的地方 & 可复用经验## 三、存在问题 & 根本原因## 四、改进措施(流程/技术/沟通)## 五、资产沉淀(组件、方案、模板)标签:
模板 6:技术故障复盘模板.md
沿用此前通用版本即可,适配线上故障、环境问题、代码 BUG 复盘。
模板 7:会议纪要模板.md
通用版本不变,适配需求评审、项目例会、技术评审、商务沟通。
七、这套知识库,能给公司带来什么?
1. 降低人力成本,告别经验流失
所有项目经验、技术踩坑、交付技巧全部沉淀,不再依赖核心老员工,新人上手效率提升50%以上。
2. 杜绝重复造轮子,大幅提效
通用组件、标准方案、问题解决方案一键复用,新项目无需从零搭建,研发、售前、交付效率大幅提升。
3. 文档标准化,提升项目专业性
所有输出文档统一模板、统一规范,方案、需求、复盘、报告专业度统一,提升客户信任度。
4. 项目全程可追溯,规避交付风险
需求变更、问题修复、迭代记录全程留痕,解决交付扯皮、责任不清、验收无依据等问题。
5. AI全自动运维,零维护成本
无需专人整理维护,AI每日自动归档、清理、复盘、沉淀,彻底解放人力。
八、落地总结
对软件公司而言,最大的资产不是代码,不是项目,而是可复用的团队知识。
传统知识库是「资料仓库」,只存不用、死气沉沉;
Obsidian + Codex 知识库是「智能大脑」,自动生长、持续迭代、全员复用。
适合所有软件研发、定制开发、外包交付、SaaS产品团队,小团队快速落地,大团队标准化管控,是目前软件行业性价比最高、落地性最强的知识管理解决方案。
今天就分享到这里,喜欢动手的小伙伴赶紧试试吧!