 夜雨聆风
夜雨聆风





告别规则维护:如何用“解析+语义”实现文档抽取的零样本适配?
-
OCR技术承担着将扫描件、照片或PDF中的视觉信息转换为可编辑文字的基础功能。中科逸视的OCR引擎采用基于CNN-Transformer混合架构的先进模型,具备以下核心能力: -
多语言、多字体、手写体识别:支持中、英、日、韩等多语言混合排版文本的精准识别,对相似字符(如“0”和“O”、“1”和“l”)的区分能力远超传统OCR。 -
表格结构重建:能够识别并还原文档中复杂表格的跨行列关系,确保表格数据的完整提取。 -
版面分析:自动识别并区分文档中的标题、段落、表格、图例、印章等不同区域,将非结构化的像素流转化为带有空间坐标的结构化数据块。
-
复杂场景适应:针对低分辨率、光照不均、倾斜、折痕、印章遮挡等复杂场景,文档抽取系统集成了自适应二值化、透视校正、去噪增强等预处理算法,确保在各种恶劣图像质量下仍能获得高精度识别结果。
-
领域知识注入:在海量真实业务文档(涵盖金融、医疗、物流、政务等垂直领域)上进行有监督微调,使模型学习到特定行业的语言模式、字段间的逻辑关系及行业术语的准确含义。 -
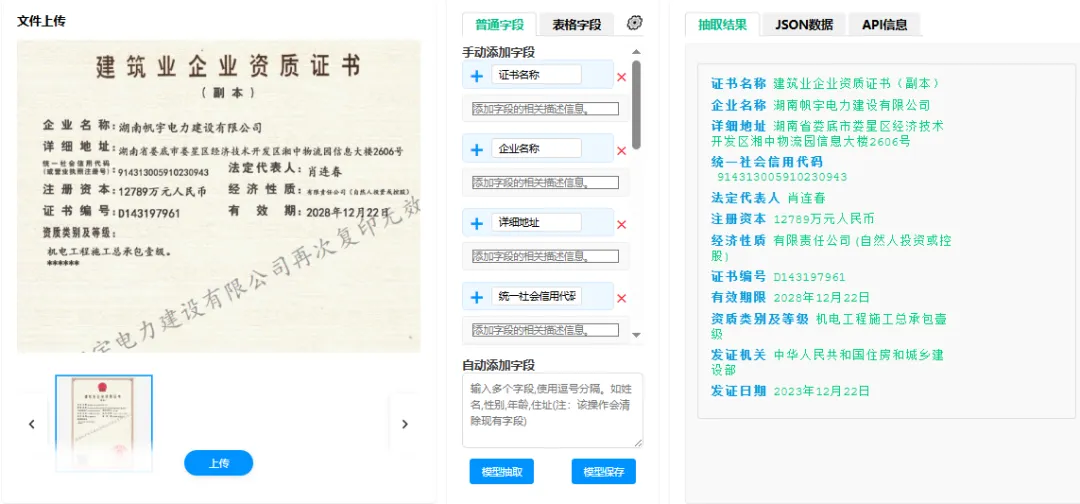
指令微调:设计统一的抽取指令模板(如“请从以下文档中提取:发票编号、开票日期、总金额”),使模型能够按照预设规则精准定位并抽取对应字段。
-
结构化输出约束:通过JSON格式强制输出,确保抽取结果可直接用于下游业务系统,实现从非结构化文本到结构化数据的无缝转换。 -
置信度传递与纠错:当OCR对某区域识别置信度较低时,系统将该信息传递至大模型,模型可结合上下文语义进行推测与纠错。
-
信贷审核:自动提取银行流水、纳税证明、资产证明中的关键财务指标,辅助风控模型进行自动化审批。 -
理赔处理:快速识别医疗发票、诊断书、事故报告中的赔付要素,缩短理赔周期,减少人工录入错误。
-
合同审查:从数百页的法律合同中自动提取签约方、金额、违约责任、管辖法院等关键条款,并比对标准模板发现风险点。 -
尽职调查:在海量的尽调材料中快速定位目标公司的股权结构、诉讼记录等敏感信息。
-
单证处理:自动化处理提单、装箱单、原产地证等国际贸易单据,实现通关信息的自动填报。 -
发票报销:集成OCR与语义理解,自动验真发票,提取金额、税号、商品明细,并自动匹配采购订单。
-
简历筛选:从不同格式、不同风格的简历中提取候选人的教育背景、工作经历、技能证书,建立标准化的人才库。