内附下载|阿里云瑶池数据库10篇论文入选全球数据库顶会SIGMOD 2026
日前,数据库国际学术顶会 SIGMOD 2026 在印度班加罗尔举行, 阿里云瑶池数据库团队 共有 10 篇论文 被主会收录 。论文研究成果涵盖 数据库与AI协同、云原生数据存储架构、数据库智能化工具 等多个技术方向,系统研究了从底层硬件架构到上层智能应用的关键技术难题。多项突破性成果的集中入选,标志着阿里云在 Agentic AI 时代的数据库软件领域持续引领前沿技术革新。 ACM SIGMOD 是全球数据库领域最具影响力的国际性学术会议之一,作为数据库前沿研究的风向标,大会所收录的论文成果代表了行业内最高水平,论文录用率长期保持在 20% 左右。 SIGMOD 2026 阿里云数据库10篇入选论文概览 本次阿里云数据库入选的 10 篇论文,集中体现了瑶池数据库当前的核心技术方向——从大模型推理的数据基础设施到向量检索和 NL2SQL,从云原生分层存储到数据湖弹性缓存,从 SQL 可观测性到自动化 Bug 复现,覆盖了从底层硬件架构到上层智能应用的完整技术栈。 当大模型成为新的应用范式,数据库与 AI 的关系也从单向调用走向双向协作。一方面,数据库需要为大模型推理、向量检索、训练数据治理提供更强的基础设施支撑;另一方面,大模型也在反过来重塑人与数据交互的方式。这一方向的 5 篇论文,正是沿着这条主线层层展开——从支撑 LLM 推理的 KV Cache 内存架构,到面向 RAG 与智能体的分布式向量引擎,再到过程奖励驱动的 Text-to-SQL、数据库内的模型生命周期管理,以及面向大模型训练的海量文本数据对齐,勾勒出 AI 时代数据库的全新角色。
1、Beluga: A CXL-Based Memory Architecture for Scalable and Efficient LLM KVCache Management(Beluga:基于CXL交换机的大模型KV Cache内存架构)
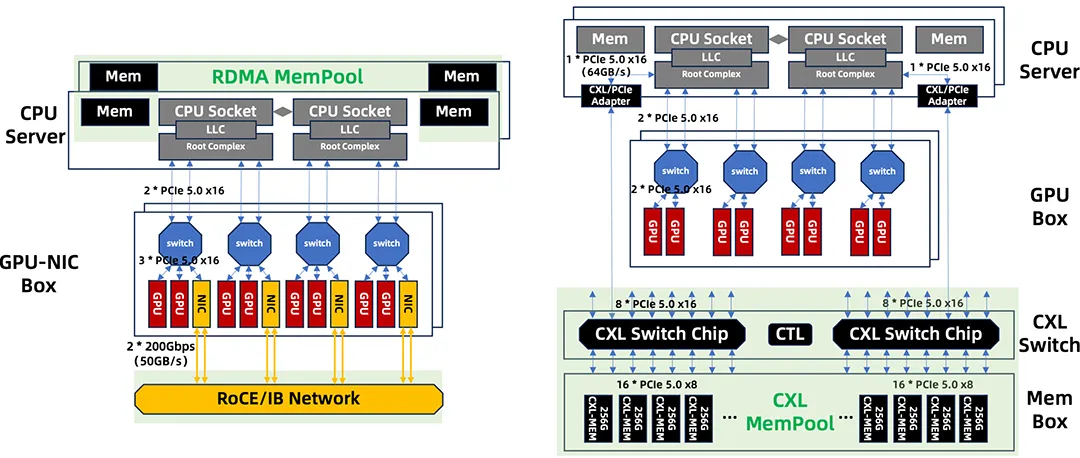
大语言模型的推理需要管理海量的 KV Cache,而 GPU 高带宽内存容量有限,主机 DRAM 也受限于 CPU 内存通道数。当前业界主要依靠 RDMA 远程内存池来扩展容量,但 RDMA 协议栈本身带来了较高的访问延迟、编程复杂度和同步开销。 论文提出了 业界首个将 GPU 集群与 CXL 2.0 交换机集成的共享内存架构 。GPU 和 CPU 通过 CXL fabric 以原生 load/store 语义直接访问大规模内存池,无需 RDMA 协议栈介入,编程模型极大简化。在此基础上实现的 Beluga-KVCache 集成至 vLLM 后,相比 基于 RDMA 的KVCache 内存池化方案, 写延迟降低7.0倍、读延迟降低6.3倍,端到端推理吞吐提升4.79倍 。 据了解,这是 CXL Switch 在 GPU 推理集群中的首个工程验证,为下一代 AI 推理基础设施的内存架构指明了方向。 🔗论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3786627
2、LindormVector: A Distributed Vector Engine on a Cloud-Native Multi-Model NoSQL Database(LindormVector:云原生多模数据库上的分布式向量引擎)
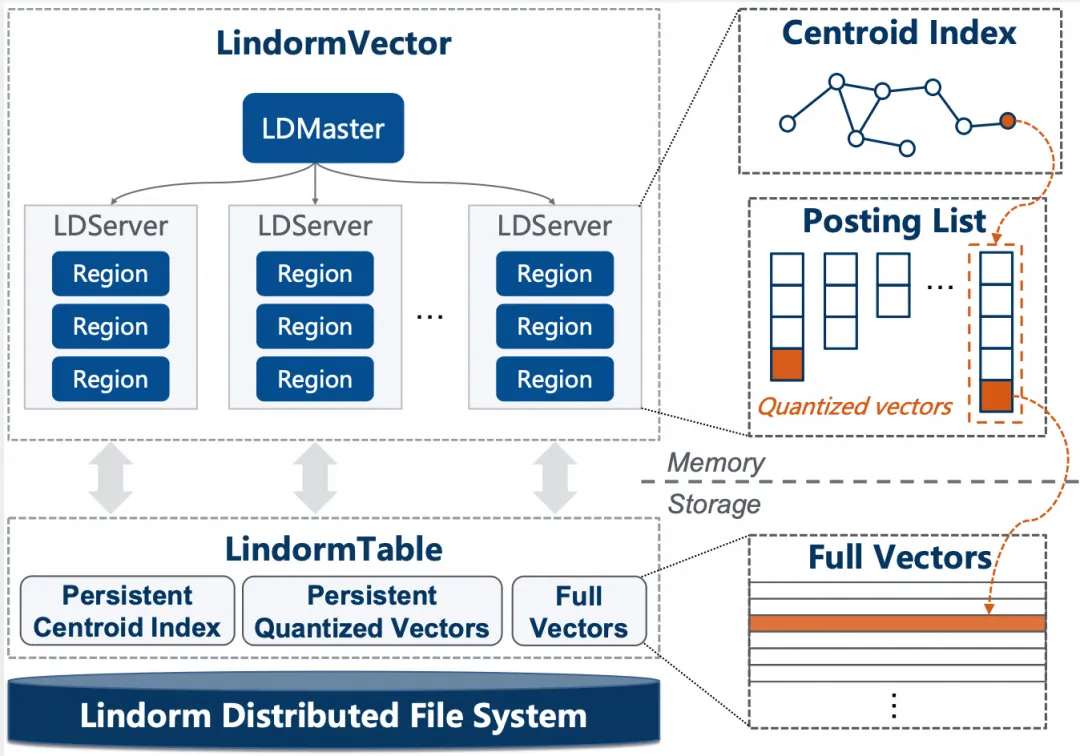
随着大模型与智能体应用快速发展,企业对向量数据库的需求已从简单的 TopK 检索,升级为大规模、高并发、低延迟、低成本的混合检索能力。数据库多模检索团队在论文中提出的 LindormVector,正是面向这一趋势打造的云原生分布式向量引擎。 LindormVector 构建于云原生多模数据库 Lindorm 之上,深度融合宽表、搜索、向量与标量过滤能力,支持向量、文本、结构化属性的一体化检索。系统采用高性能内存索引 HNSWv2 与低成本磁盘索引 IVFBQ,在保证高召回的同时显著降低存储开销,并通过分布式架构实现弹性扩展和高并发服务能力。 在真实云环境和公开基准测试中,LindormVector 展现出领先性能:在高召回率场景下实现毫秒级延迟和高吞吐,支撑大规模 RAG、AI 搜索、智能体长期记忆、自动驾驶数据管理等核心场景。其混合查询优化能力能够有效处理“向量+文本+标量过滤”的复杂业务需求,帮助企业从海量非结构化数据中快速发现价值。 🔗论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3788853.3803088
3、Reward-SQL: Boosting Text-to-SQL via Stepwise Execution-Aware Reasoning and Process-Supervised Rewards(Reward-SQL:过程奖励驱动的Text-to-SQL)
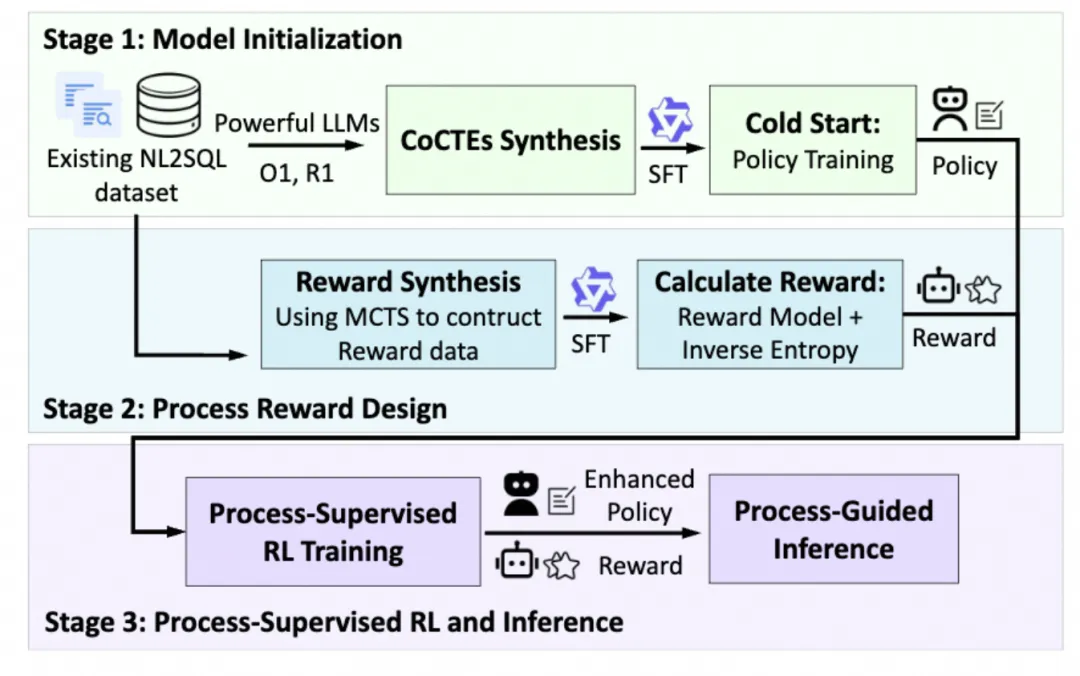
基于大语言模型的 Text-to-SQL 算法在 复杂查询场景 下仍面临两大瓶颈:推理过程缺乏与数据库的实时执行交互,模型只能在最终 SQL 执行后才发现错误;现有强化学习方法依赖稀疏的结果奖励,无法对中间推理步骤进行细粒度信用分配,导致复杂查询中的错误逐步累积。 该论文提出 CoCTE 推理框架,将复杂 SQL 分解为一系列可独立执行验证的 CTE 子查询,让每一步推理都能在数据库上得到真实反馈。在此基础上设计的过程奖励模型(PRM)通过 MCTS 自动生成轨迹分数,并集成至强化学习训练过程。实验表明, 8B 规模的 Reward-SQL 在 BIRD 上达到70.3%执行准确率,超越同等参数规模基线以及多个百亿参数量的闭源大模型,并在5个跨域数据集上展现出优秀的泛化能力 。
🔗论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3802105
4、NeurStore: Efficient In-database Deep Learning Model Management System(NeurStore:数据库内深度学习模型高效管理系统)
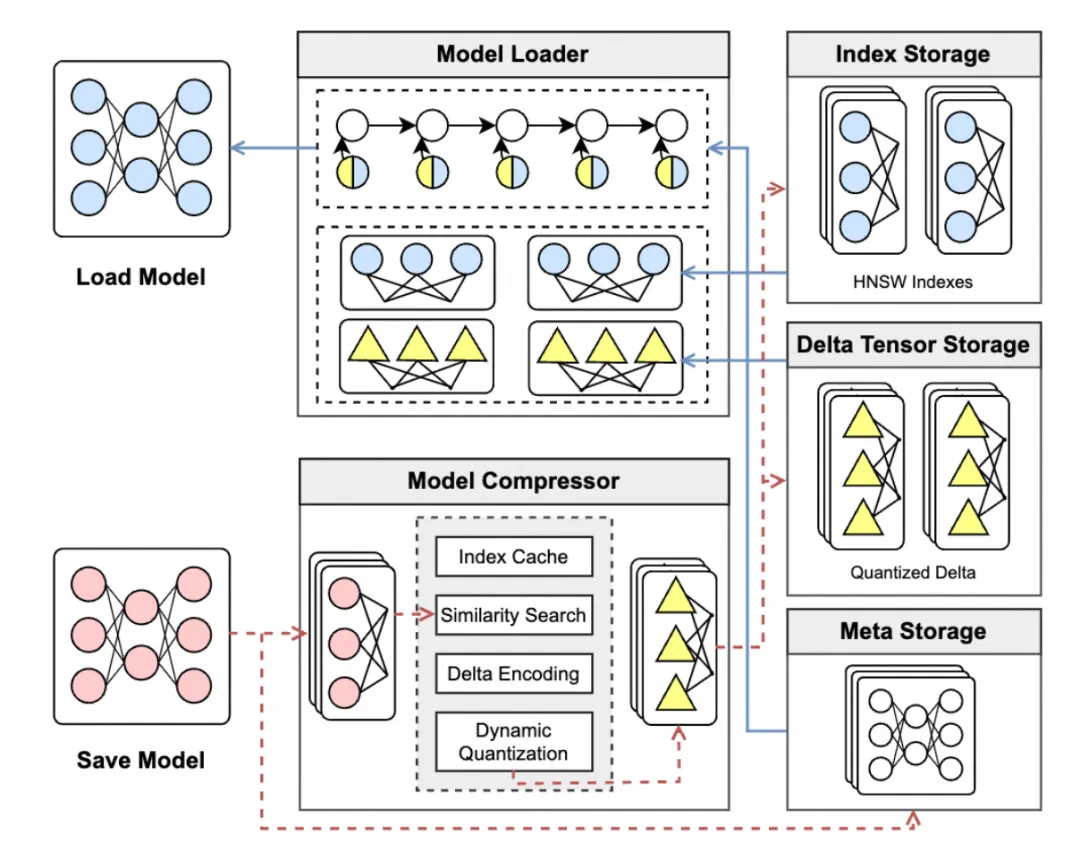
随着数据库内 AI 分析的快速发展,数据库系统需要管理的深度学习模型数量和规模持续增长。然而,现有系统通常将完整模型作为单体文件进行存储,或采用未充分考虑模型内部结构特征的通用压缩方法,导致大量相似参数被重复保存,带来较高的模型存储开销。论文提出了一个面向深度学习模型的高效数据库内模型管理系统,旨在提升模型的存储效率和使用性能。 NeurStore 将深度学习模型拆分为细粒度张量进行管理,识别和复用模型之间的相似张量,实现张量级去重;针对差分张量,进一步提出差分量化算法,在可控模型精度损失的前提下提升压缩率;同时设计压缩感知的模型加载机制,减少模型解压和加载带来的额外开销。与现有方法相比,NeurStore 能够实现更高的模型压缩率,并保持具有竞争力的模型加载吞吐量。
🔗论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3769809
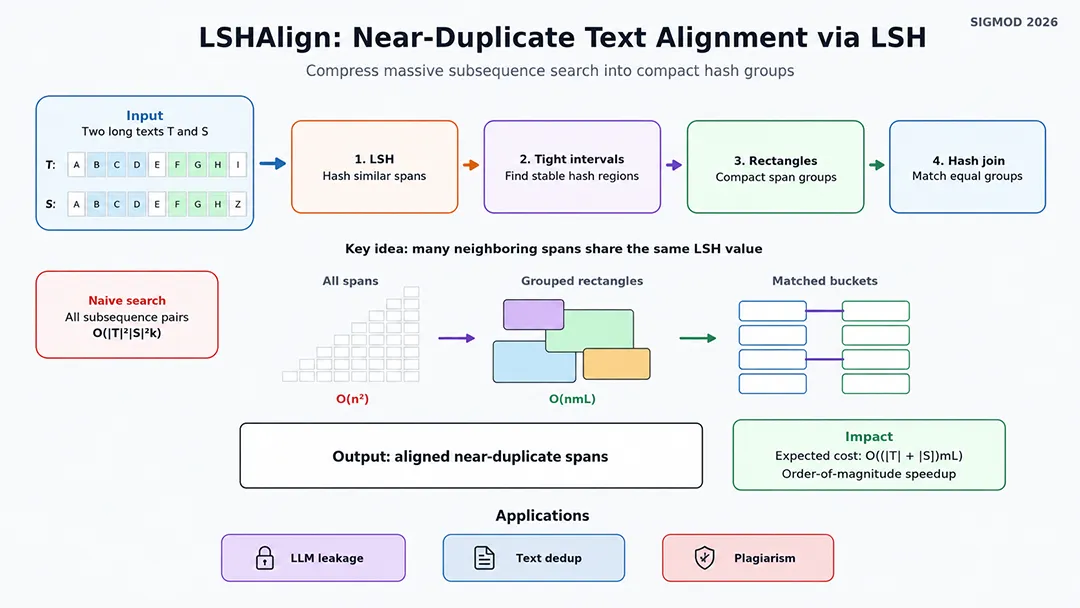
5、LSHAlign: All-Pair Near-Duplicate Text Alignment via Locality-Sensitive Hashing(LSHAlign:基于局部敏感哈希的大规模文本近似对齐)
随着大模型训练数据规模快速增长,如何在海量长文本中高效发现近重复片段,已成为LLM训练数据去重、数据治理中的关键问题。传统方法往往面向整篇文档相似度,难以准确定位长文本内部局部重复内容;而逐段比对又面临计算成本过高的问题。 论文针对这一挑战,提出了一种高效的长文本近重复片段对齐方法。该方法利用局部敏感哈希(LSH)快速发现潜在相似区域,并结合精细化对齐策略,在大规模文本集合中定位所有近重复子字符串对。相比暴力匹配或粗粒度文档去重方法,LSHAlign 能在保证较高准确性的同时显著降低计算开销。 LSHAlign 的提出,体现了数据管理技术在 AI 时代的新价值:从“管理结构化数据”走向“治理大规模非结构化训练数据”,为可信、高质量的大模型训练奠定基础。 🔗 论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3802083 云数据库的存储底座,正从单一介质演进为 DRAM、本地 NVMe、远程块存储与对象存储并存的多层异构架构。如何在这样的体系下同时兼顾成本、性能与稳定性,是云原生时代绕不开的命题。这一方向的 3 篇论文,分别从分层存储、解耦内存缓存与多租户 LSM-Tree 三个切面切入,把存储语义、内存资源与租户负载纳入统一的调度视野,为成本与性能的再平衡给出了可工程化落地的设计路径。
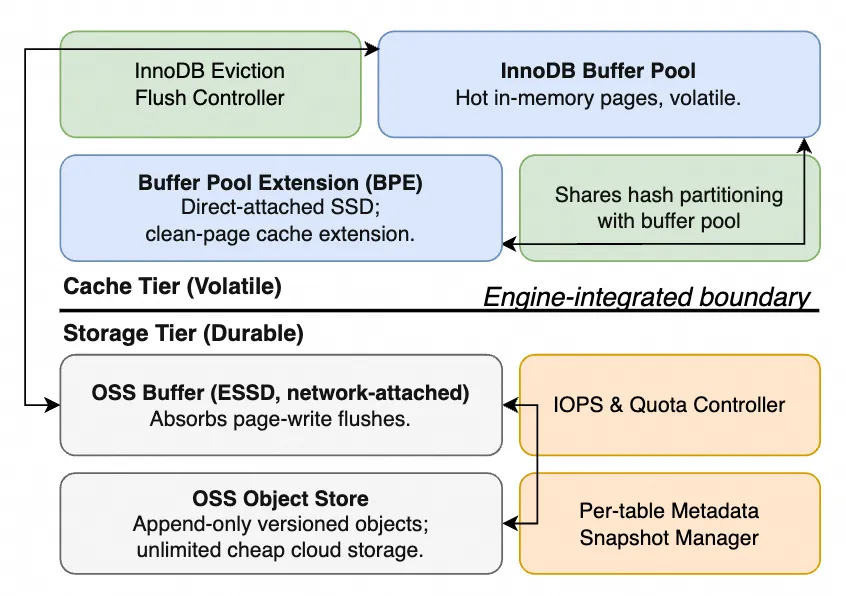
6、CloudJump III: Optimizing Cloud Databases for Tiered Storage(CloudJump III:面向分层存储的云数据库优化)
云数据库已从单一介质演进为 DRAM、本地 NVMe、远程 ESSD、对象存储 OSS 共存的多层异构架构,存储开销占比持续上升。传统块级或文件级分层方案缺乏对数据库语义的感知,DRAM 中的热页在外部追踪中常被识别为冷页,关键索引与元数据页易被过早驱逐,数据迁移与崩溃恢复、备份协议之间缺乏统一约束,在动态 OLTP 负载下难以提供稳定的性能与运维保障。 论文将分层能力下沉至数据库内核。系统在缓冲池淘汰与刷脏等控制点上,基于引擎可见的元数据完成页级放置决策,并在中间层进行写合并以降低写放大,同时通过快照版本协议将分层过程与 WAL、备份机制协同,保证崩溃一致性与零停机运维。 该方案已在阿里云 MySQL 兼容数据库的生产环境中规模化部署。实测表明,在快速层容量受限的情况下,系统吞吐接近全 SSD 配置,长尾延迟保持稳定,单位存储成本下的性能显著优于传统分层方案。 CloudJump III 为多租户云数据库在异构存储介质上的成本与性能平衡提供了可工程化的设计路径。 🔗 论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3788853.3803084
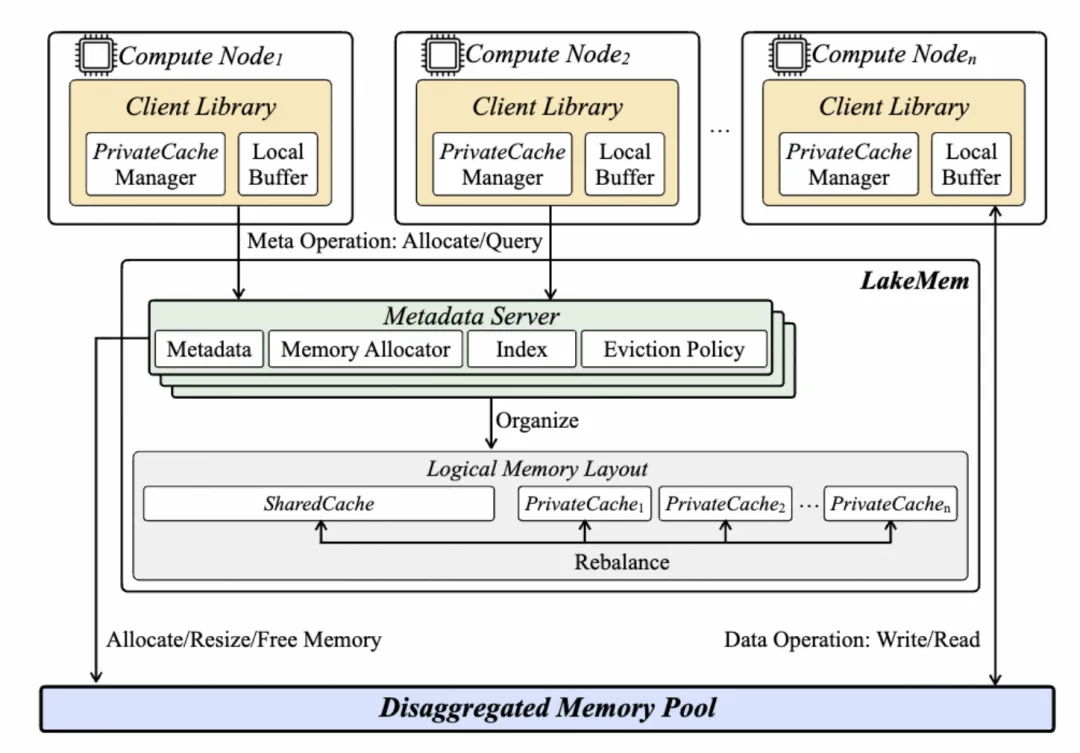
7、LakeMem: An Elastic Disaggregated-Memory Caching Layer for Analytical Processing Systems(LakeMem:面向分析系统的弹性解耦内存缓存层)
湖仓架构下的分析型负载既需要缓存大量基础表数据,也需要维护哈希表、Shuffle Buffer 等中间状态,而现有解耦内存缓存通常对不同数据一视同仁,难以充分利用其语义差异。 论文提出双路径缓存架构:Private Cache 以客户端为中心服务查询私有中间数据,Shared Cache 由服务端协调实现跨节点基础表复用,并通过动态再平衡机制自适应分配内存资源。 集成至DuckDB后,在内存受限场景下实现了2.0×到5.9×的查询加速。 🔗 论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3788853.3803100
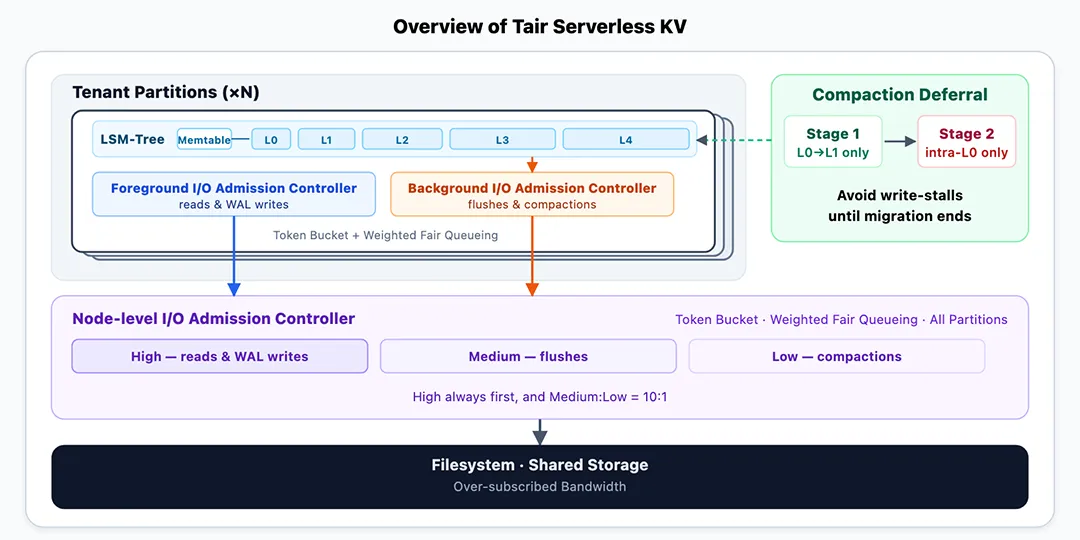
8、Making LSM-Tree-based Key-Value Store Practical and Efficient for Multi-Tenant Serverless Cloud Databases (Tair Serverless KV:基于 LSM树,稳定与高资源利用率兼得的 KV 服务)
基于 LSM-tree 的多租户云数据库中,Compaction 的异步特性可能导致低流量时段某租户磁盘带宽周期性突增,引发租户 SLA 保障与带宽高效复用之间的矛盾。传统方案往往无法兼顾二者,通常以牺牲资源复用为代价换取 SLA 稳定,导致承载密度降低、资源利用率低下。 Tair Serverless KV 在论文里通过两项创新解决这一难题: 两级 I/O 准入控制和两阶段 Compaction 延迟机制 。前者区分前台用户请求与后台 Compaction 流量,使后台可用磁盘带宽随实时前台负载动态调整,平滑 Compaction 对带宽的突发占用,从而支撑更高的带宽复用能力;后者利用 Compaction 的异步性,动态调度前后台资源,进一步提升资源弹性供给能力。 Tair 首次在 LSM-Tree 结构下实现租户 SLA 与资源高度复用的兼得:不仅保留了传统同步引擎的资源复用能力,更将磁盘带宽的共享理论边界从“静态资源隔离”拓展至“异步 Compaction 的时间片复用”新维度。 🔗 论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3786667 数据库的研发与运维,长期依赖工程师的经验积累与反复试错。随着系统规模和业务复杂度持续攀升,这种“人肉”模式正逼近效率与可靠性的极限。这一方向的 2 篇论文,尝试将静态程序分析与大模型推理相结合,分别破解“代码到 SQL 的可观测性”与“从社区报告自动复现 Bug”两道难题,让 SQL 治理与缺陷复现从经验驱动走向自动化、可追溯、可复用的工程能力。
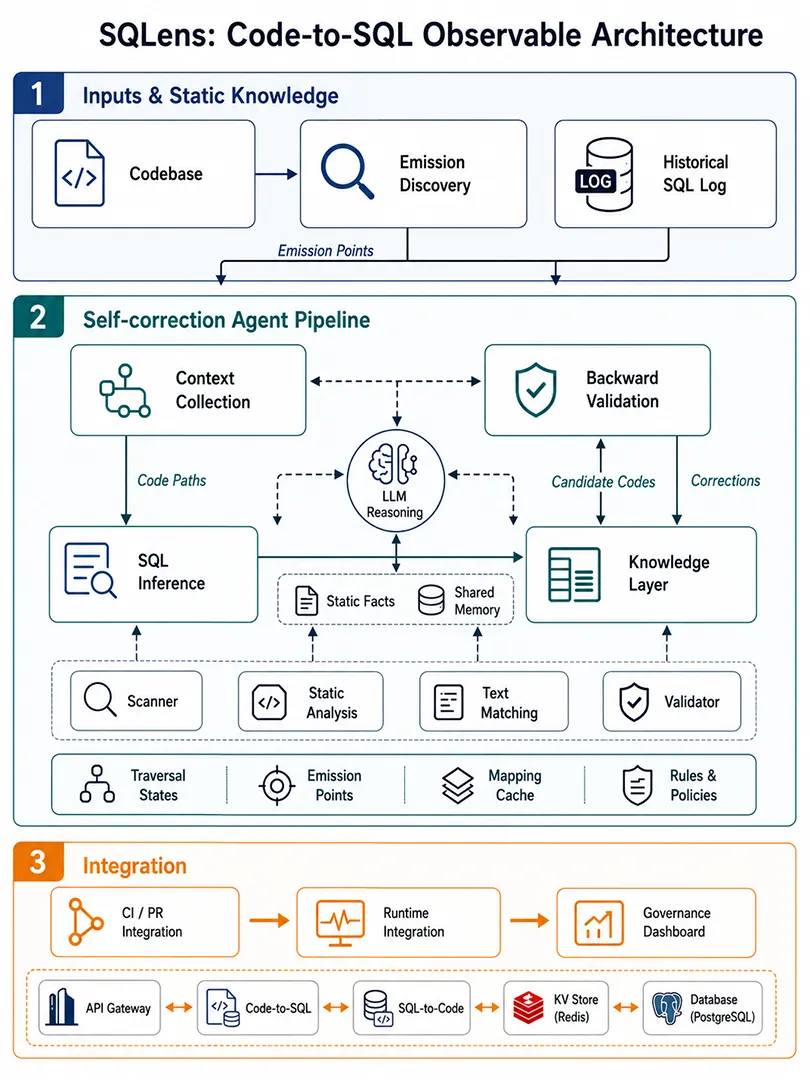
9、SQLens: Continuous Code-to-SQL Visibility in the Wild(SQLens:代码到SQL的持续可观测性)
在大规模微服务架构中,ORM、Query Builder 等层层抽象遮蔽了实际的数据库交互,使得开发者难以预判代码改动会如何影响实际执行的 SQL,运维人员也难以把慢查询追溯到具体业务代码,由此造成的性能回归、安全风险与故障定位成本居高不下。 论文以数据库调用点为入口,由协作式智能体沿控制流与数据流双向遍历,融合静态程序分析事实,重建 SQL 模板及参数绑定;再以线上 SQL 日志反向校验、自我纠错,将一次性的不可靠推理转化为可持续维护的高保真映射。所有结果沉淀于版本化知识层,同时支持“从代码到SQL”正向查询与反向溯源,并对语法、Schema 与安全进行多维校验。 SQLens 已在阿里巴巴集团生产部署,覆盖 Java/Ruby/Python 等异构技术栈,与 CI/CD 流水线、APM 链路、慢查询监控深度集成:PR 阶段提前预警风险 SQL 与注入隐患,线上快速定位问题代码归属,并基于真实负载给出索引建议,显著缩短 SQL 故障定位与修复时间,让 SQL 治理真正走向持续化、可审计、可追溯。
🔗 论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3788853.3803091
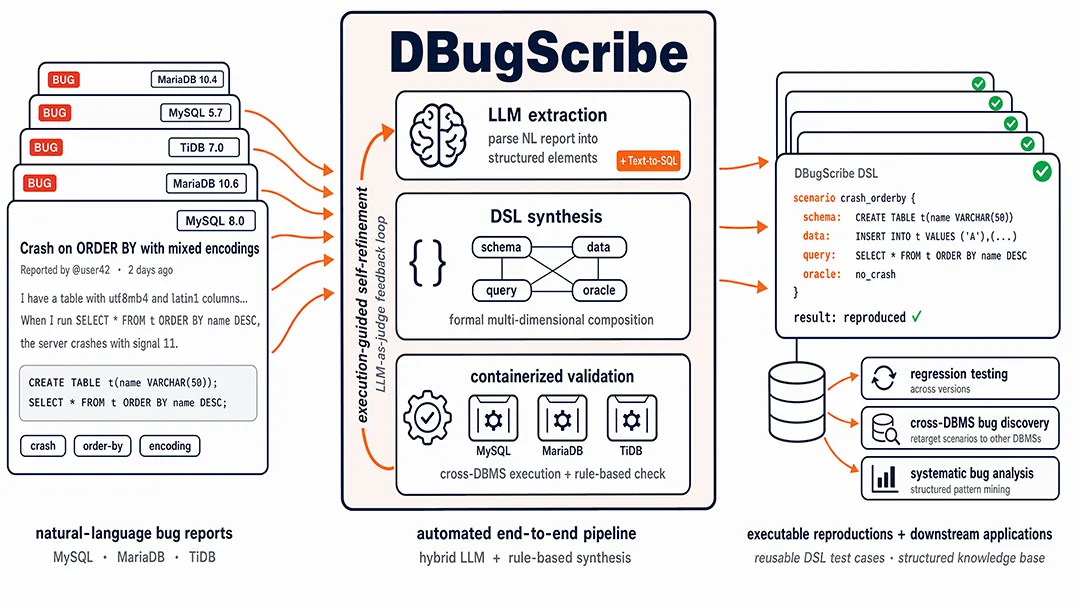
10、DBugScribe: Automatic Database Bug Reproduction from Community Reports(DBugScribe:从社区报告自动复现数据库 Bug)
MySQL、MariaDB 等主流数据库每天涌入大量自然语言 Bug 报告。要真正复现一个 Bug,需要同时重建配置、Schema、数据、操作序列与校验 Oracle 等多维状态,开发者往往耗费数小时反复试错,近半数报告甚至难以稳定复现,严重拖慢缺陷修复节奏。 本论文首次将”数据库 Bug 场景”建模为具有形式化语义的一等对象,提出一套可组合的领域特定语言(DSL),并通过 LLM 语义抽取、Text-to-SQL 增强 Oracle 合成与规则校验自我精化的混合方法,端到端地将自然语言报告自动编译为可执行、可验证的复现脚本。 在覆盖主流数据库、源自 8 个顶会测试工具的 218 个真实 Bug 报告上,DBugScribe 取得 72.9% 的自动复现成功率,平均每个报告仅需数分钟。更进一步,沉淀下来的 DSL 脚本被组织为结构化知识库,支撑跨版本回归与跨数据库 Bug 迁移测试,已额外发现 37 个新 Bug,其中包含一个MySQL 崩溃缺陷已被官方确认。 DBugScribe 让 Bug 复现从经验驱动迈向工程化、可复用的自动化能力,为数据库可靠性研究与工业级缺陷治理提供了新的基础设施。 🔗 论文下载地址:https://dl.acm.org/doi/epdf/10.1145/3802034 以上研究成果并非孤立的学术探索,而是深度扎根于阿里云瑶池数据库的产品体系。Beluga 的 CXL 内存池技术已进入工程验证阶段,LindormVector 作为 Lindorm 多模数据库的核心能力在生产环境大规模服务,CloudJump III 已部署于 PolarDB MySQL 版的分层存储引擎,SQLens 覆盖了阿里巴巴集团内部数千个微服务的 SQL 治理,Reward-SQL 的技术正在赋能瑶池的智能化数据开发体验。 从真实的生产问题出发,做系统性的前沿研究,再将成果回馈到产品迭代中——这种闭环是瑶池数据库持续产出高质量顶会论文的核心驱动力。从智算训练到智能运维,从向量检索到数据治理,阿里云持续将产业级技术难题与学术创新融合,为下一代云数据库基础设施的发展奠定基石。
 夜雨聆风
夜雨聆风