 夜雨聆风
夜雨聆风





Triton算子开发详解:调试工具-TritonViz

大模型 | 编译器 | Triton

GPU 编程是人工智能系统的关键部分,学习比较困难,需要理解大规模并行、内存层级的数据移动 等相关知识。Triton-Viz 提供了 GPU运算的可视化交互,包括并行、访存、性能指标。
GPU可以高效地处理 Tensor 的各种操作,需要大量的并行能力。GPU架构的设计,提供了成千上万的微内核,可以独立运行线程;线程分组成 warps,也就是线程聚合成更大的线程块。在最高层级上,这些线程块组合成多个 grids,这就是 GPU kernel 下发的单元块大小,也是用户自定义函数的入口。
GPU编程需要程序员管理线程、线程块、网格、GPU不同内存层级间的数据移动、能够使用 TensorCores。这些都需要理解复杂的架构细节,以充分利用GPU的能力。在 CPU 编程中,并行层级(线程、线程块、网格) 和 内存层级(全局内存、共享内存、局部内存)通过高度抽象对程序员不可见,但CUDA要求程序员显式地管理这些单元以发挥出 GPU 的能力。
🥝深度学习编程框架 PyTorch 也是高层抽象,隐藏了这些细节,性能较差。
🥝Triton 也提供了对 GPU 的高层抽象,使用GPU的能力。Triton GPU 函数使用了几乎标准的 Python 语法,比较容易学习。
🥝Triton 与 PyTorch 无缝集成。输入到 Triton 内核参数的 x_ptr, y_ptr, z_ptr 都是 PyTorch Tensor。Triton 自己的 tensors 和 标量,也与 PyTorch 非常类似。
🥝Triton 采用了基于 线程块的编程模型,最低的编程粒度是 Triton program (CUDA block),抽象隐藏了线程 和 线程束 warps。用户只需要指定 Triton 内核使用的 programs 的数量,就可以在 GPU 上并行执行这些 programs。Triton 会自动管理内存的使用和优化,比如 内存合并,向量化。
用户在编写 Triton 代码的时候,需要把原来串行执行的代码重构成并行执行的代码,指定 program instances 的数量,load 和 store 的时候设置 offset 和 masks。Triton-Viz 把这些操作变成可视化。下图的例子,显示的是2个加载操作,1个存储操作,访问输入 vector x, y, z (实际是 PyTorch tensors)。
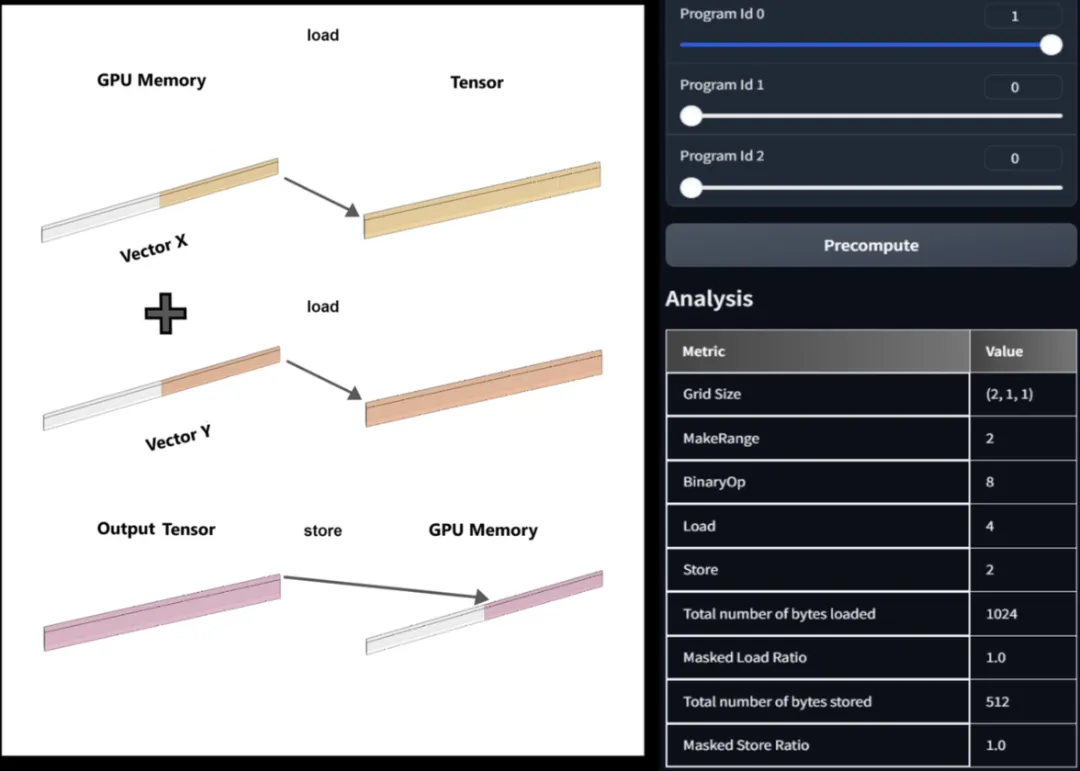
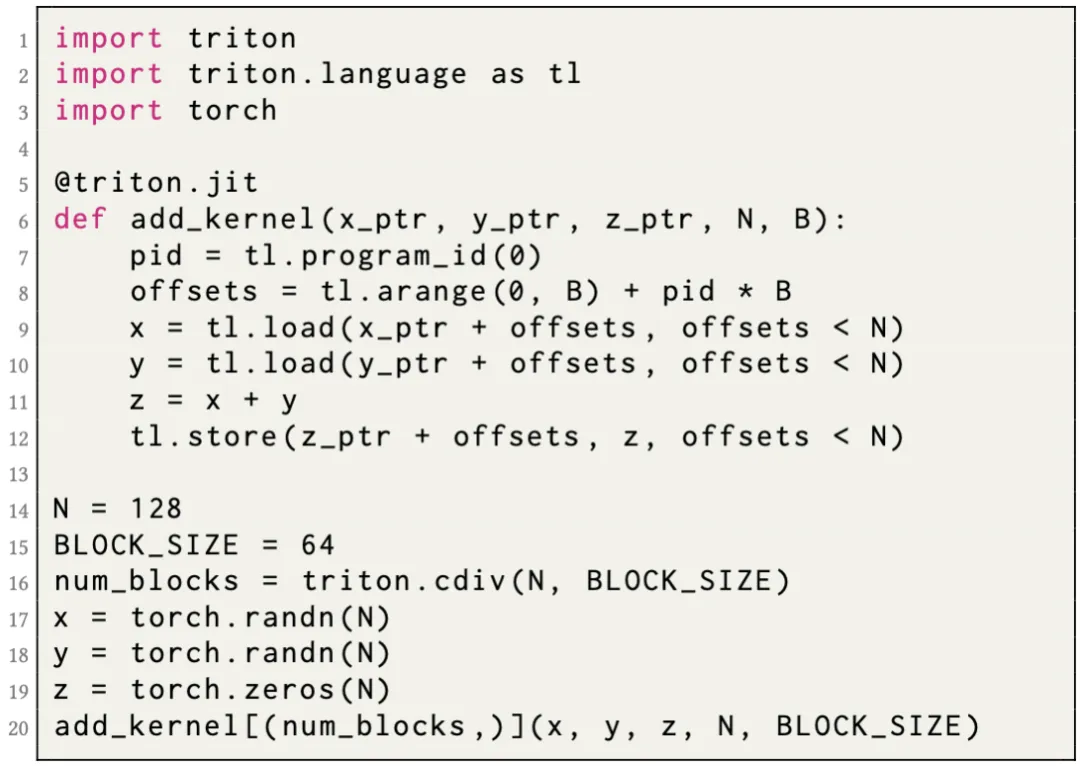
Triton vector add kernel :
使用 Triton-Viz 需要对源代码做2处修改:
🥝在内核函数上,添加装饰器 triton_viz.trace
装饰了 Triton kernel, 输入参数 client 运行 kernel 的 client,如果不设置的话,默认是 Tracer()。
def trace(client: Union[str, Client, None] = None, backend: str = "triton"):"""Create a trace object that can be used to run a kernel with instrumentation client(s).:param kernel: The kernel to run.:param client: A client to run with the kernel. Defaults to Tracer() if not specified."""
🥝调用 add_kernel 之后,使用 triton_viz.launch 函数
启动 Triton-Viz Flask server;
🍋🟩share 设置为 False 默认端口 5001,否则为 8000;
🍋🟩port 设置服务端口,默认为 None,根据 share 的设置的值来设置端口;
🍋🟩block 设置多线程是否同步,根据 share 的设置的值来确认设置 block 后是否同步,这里的多线程是设置运行 cloudflared 的内网穿透,用于临时共享;通常情况下,可能不会去共享,设置 share=False 即可。
def launch(share: bool = True, port: int | None = None, block: bool | None = None):"""Launch the Triton-Viz Flask server.:param block: Whether to block the caller when share=True. Defaults toTrue outside interactive sessions."""
具体代码修改如下所示:
import tritonimport triton.language as tlimport torchimport triton_viz@triton_viz.trace("tracer")@triton.jitdef add_kernel(x_ptr, y_ptr, z_ptr, N, B: tl.constexpr):pid = tl.program_id(0)offsets = tl.arange(0, B) + pid * Bmask = offsets < Nx = tl.load(x_ptr + offsets, mask=mask)y = tl.load(y_ptr + offsets, mask=mask)z = x + ytl.store(z_ptr + offsets, z, mask=mask)N = 128BLOCK_SIZE = 64num_blocks = triton.cdiv(N, BLOCK_SIZE)x = torch.arange(N, dtype=torch.float32)y = torch.arange(N, dtype=torch.float32)z = torch.zeros(N, dtype=torch.float32)add_kernel[(num_blocks,)](x, y, z, N, BLOCK_SIZE)triton_viz.launch(share=False, port=5001)
运行之后查看可视化数据
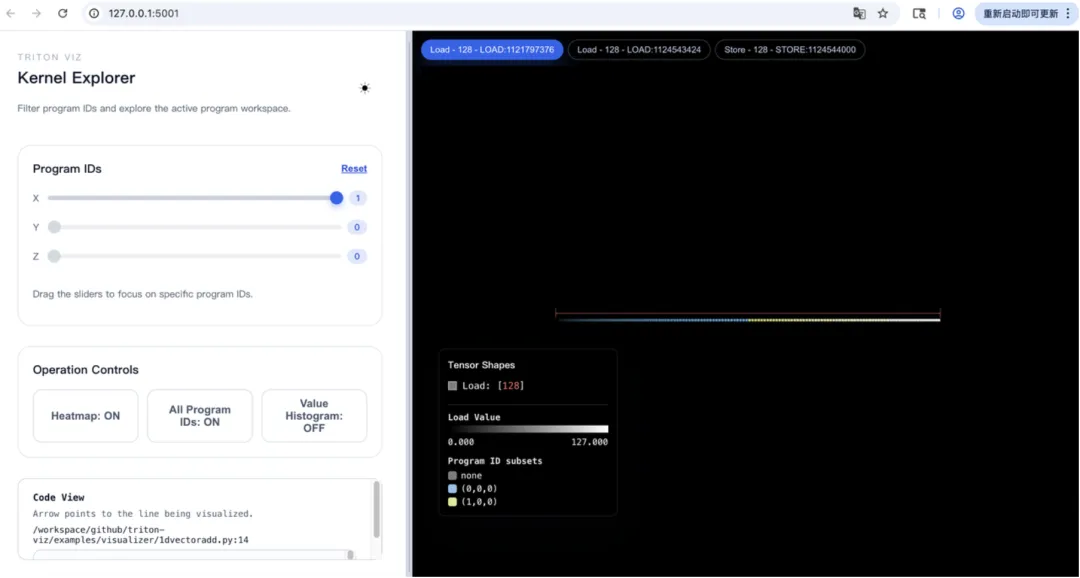
Triton-Viz 由 4部分组成,interpreter, Trace Collector, Trace Analyzer, Visualizer,如下图所示。interpreter 拦截 Triton Kernel 把它暴露给 callback。Trace Collector 设置 callbacks,functions 记录了tensors 或 scalars 的实际值。这些值会提供给 Trace Analyzer 分析访存和性能指标。最后 Visualizer 交互显示 trace data。interpreter 使用 numpy 函数在 CPU 上执行 Triton Kernel,不进行编译。
