 夜雨聆风
夜雨聆风





工具|JS_URL_Extractor_Pro_v2.0发布

前阵子接了个活,要审计一个前端项目,代码是打包过的,乱七八糟的 chunk 文件十几二十个,里面藏着一堆 API 接口和资源路径,客户想要一份完整的接口清单,你总不能让人家一个个文件打开看吧。
最开始我用的老办法——开发者工具 Network 面板,点一遍流程,导出 HAR 文件。但问题很快就来了,有些接口是条件触发的,你不走到特定步骤它根本不请求;还有些资源是动态 import 的,第一次加载根本看不到;然后我试过在 VS Code 里全局搜索,/api、http、.js 来回搜,搜出来几百条,还得手动去重、过滤图片字体、整理格式……搞了两个小时,头都大了。
我就想,这活凭什么不能自动化?
于是就有了这个脚本
没什么复杂的架构,就是一个 Python 脚本,核心逻辑大概是这样:
1.读 JS 文件(本地的或远程的都行)2.用正则把里面像 URL 的字符串都抠出来3.过滤掉图片、字体这些一般不关心的资源4.把相对路径统一补上5./ 开头,方便后续使用6.输出成两个列表:带域名的和不带域名的
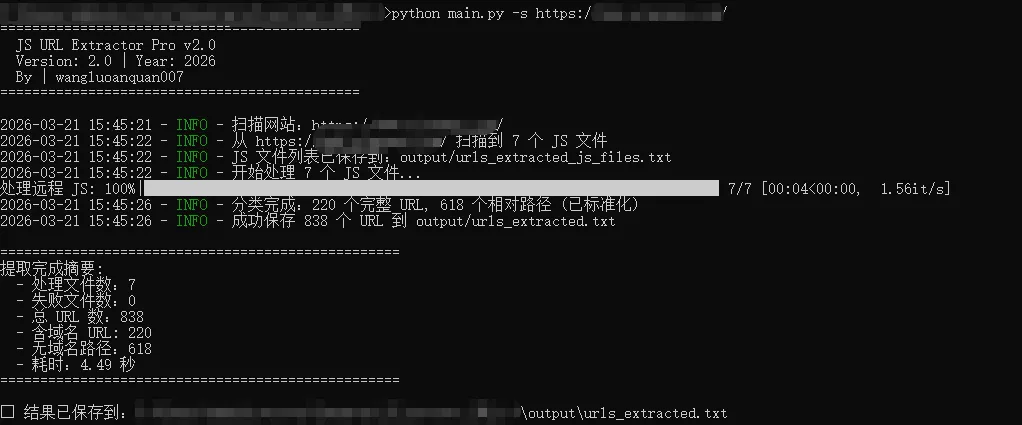
一、工具介绍
## ✨ 功能特性–
🌐 **网络模式**: 从目标网站下载 JS 文件并提取其中的 URL–
📁 **本地模式**: 扫描本地目录下的 JS 文件提取 URL–
🔗 **智能分类**: 自动区分含域名的完整 URL 和相对路径–
🧹 **去重过滤**: 自动去重并过滤无效 URL–
⚡ **多线程支持**: 可配置并发处理提高效率–
📝 **详细日志**: 彩色日志输出,支持保存到文件–
⚙️ **灵活配置**: YAML 配置文件支持
编辑 config.yaml 文件自定义:
-
网络请求超时和重试次数 -
并发工作线程数 -
URL 过滤规则 -
正则表达式模式 -
日志级别和输出
二、工具使用
参数说明
|
|
|
|
|---|---|---|
--url-file |
-u |
|
--dir |
-d |
|
--scan-site |
-s |
|
--output |
-o |
|
--config |
-c |
|
--verbose |
-v |
|
1.从 URL 文件提取
# 准备 URL 列表 (input/file.txt)https://example.com/js/app.jshttps://example.com/js/vendor.js# 运行提取python main.py -u input/file.txt -o output/urls.txt
2.扫描本地目录
python main.py -d ./js_files -o output/urls.txt3.扫描网站
python main.py -s https://example.com -o output/urls.txt4.混合模式
python main.py -u input/file.txt -d ./js_files -o output/urls.txt5.运行示例
# 基础用法python main.py -u input/file.txt -o output/result.txt# 扫描本地目录python main.py -d ./src/js -o output/result.txt# 扫描网站并提取python main.py -s https://target.com -o output/result.txt# 详细日志模式python main.py -u input/file.txt -v
三、工具获取
关注公众号后台回复“JUEP2.0”均可获取下载链接
|
免责声明: 本文章仅做网络安全技术研究使用!另利用网络安全007公众号所提供的所有信息进行违法犯罪或造成任何后果及损失,均由使用者自身承担负责,与网络安全007公众号无任何关系,也不为其负任何责任,请各位自重!公众号发表的一切文章如有侵权烦请私信联系告知,我们会立即删除并对您表达最诚挚的歉意!感谢您的理解!让我们一起为中国网络安全事业尽一份自己的绵薄之力! |
浅谈Nacos漏洞之超管权限后续利用
写作不易,分享快乐
期待你的 分享●点赞●在看●关注●收藏