 夜雨聆风
夜雨聆风





人力资源数据管理:实用指南
您只有点击关注上面⬆️“HR时间”公众号并设了星标⭐️,才能及时接收最新推送

人力资源数据管理的成熟度决定了你的人员数据是成为战略资产还是日常的挫折。大多数组织已经收集了大量劳动力数据,但当这些数据管理不善时,后果会立即且代价高昂。
当人力资源数据得到妥善管理时,报告速度更快,决策更加清晰,人力资源也从解释差异转向塑造结果。
 什么是人力资源数据管理?
什么是人力资源数据管理?
人力资源数据管理是组织在整个人力资源生命周期中,从招聘和入职到员工发展、薪酬和离职流程中,收集、组织、存储、更新、保护和使用劳动力相关信息的结构化方式。
这种方法的核心是一个记录系统:核心员工数据的官方真实来源,如个人信息、职位信息和雇佣状态。治理规则、数据质量检查、访问控制、集成和审计追踪确保你依赖的数据保持准确、可靠、安全,并且在所有其他人力资源工具和系统中都能使用。
人力资源数据管理包括制定数据标准、定义谁可以访问或更改数据、进行质量检查、管理系统集成、维护审计追踪以及处理数据保留和删除,这不仅仅是买HRIS或搭建仪表盘。工具很重要,但流程和纪律更为重要。
在实际层面上,人力资源数据管理建立在3个简单的支柱之上:
质量:数据准确、完整且最新。
控制:明确规定谁可以看到和更改什么内容。
用途:数据被积极用于报告、洞察和决策。
稳健的数据管理是有影响力的人力资源数据战略的基础。
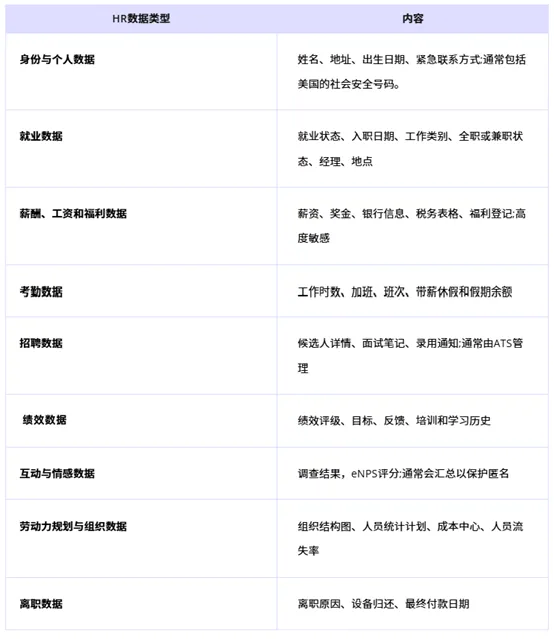
 人力资源数据类型
人力资源数据类型
人力资源处理各种数据,涵盖从基本员工和工资信息到员工参与度、绩效和劳动力规划数据。
以下是常见人力资源数据类型的概述:
 关键人力资源数据管理挑战
关键人力资源数据管理挑战
即使有现代人力资源系统,许多组织仍难以一致管理人力资源数据。所有权、定义和流程的空白会带来问题,拖慢决策并削弱对数据的信任。
1、数据孤岛
你的人力资源团队可能同时使用多个工具——人力资源信息系统、工资系统、福利平台、员工排班软件和自动员工系统(ATS)。
每个系统可能存储同一员工记录的略有不同版本,当HRIS中的编制与工资不匹配,或者新员工出现在招聘系统中但不在核心人力资源平台时,对数据的信心迅速流失。你不专注于洞察,而是花时间对账和解释差异。
2、定义不一致
简单的问题往往会带来令人困惑的答案。具体算是人数?承包商包括在内吗?员工何时被视为在职或被解雇?员工流动是如何计算的?
如果你们组织没有就明确定义达成一致,不同团队会用相同的底层数据产生不同的结果。你最终只能为数字辩护,而不是用它们来指导劳动力决策。
3、数据质量问题
你可能会遇到重复的员工记录、缺少必填字段、过时的职位名称或报告行,以及自由文本字段的不一致使用。这些问题往往随着时间悄然积累,尤其是在数据录入规则松散或无人明确负责数据质量时。当问题在报告中显现时,修复起来可能既困难又耗时。
4、积分与同步失败
许多人力资源环境依赖于系统之间的集成,如果你依赖平面文件导入、定时批处理更新或脆弱的API,数据很容易不同步。你可能会手动重新输入信息以保持系统对齐,集成失败往往在工资单、审计或领导层报告中暴露漏洞和错误后才被发现。
5、变革管理与用户行为
即使是最好的人力资源数据管理软件,如果人们不信任它也会遇到困难。如果系统感觉缓慢、混乱或不可靠,人力资源团队可能会回归使用电子表格或个人追踪器。随着时间推移,这些阴影系统成为非正式的真相来源。强化了核心系统不可依赖的信念,即使真正的问题是使用不一致和数据纪律性差。
6、隐私与保留风险
你负责管理组织中一些最敏感的数据——个人信息、银行信息、税务数据以及与福利相关的记录。如果保留和删除规则不明确,数据往往会被“以防万一”被保留得比必要的时间更长。这增加了隐私风险,使合规变得复杂,也使得对审计或数据访问请求的响应更加困难。
7、合并、收购与重组
在合并、收购或重大重组期间,人力资源数据管理变得尤为复杂。你可能需要合并不同的人力资源数据库,映射职位代码和等级,协调职位类别,并协调薪酬结构。这项工作通常在紧迫的时间表下完成,使用了从未设计成能完美拼接的遗留数据。
8、人工智能与分析风险
如果你使用分析或人工智能驱动的工具,数据问题会变得更加危险,而非减轻。低质量的数据仍然可以产生精致的仪表盘和看起来自信的预测,真正的风险在于虚假的确定性——基于看似可信但建立在错误或不一致输入上的洞察。
 确保人力资源数据管理稳健的10个步骤
确保人力资源数据管理稳健的10个步骤
扎实的人力资源数据管理通过明确的所有权、明确的标准和一致的流程构建,以下步骤概述了人力资源领导者如何建立这些基础:
1、选择你的记录系统
你需要一个正式负责核心员工数据的地方,没有这些,每个系统都在争夺“正确”的标准。实际上,关于记录系统的混淆是导致数据错误和不信任的最大来源之一。
要做:确定哪个系统是身份、就业状态、职位数据和报告线的记录系统。明确说明哪些字段属于该领域,哪些系统是下游消费者,这样当数字不匹配时,你就能有一个明确的锚点。
不要:让工资、人力资源信息系统和ATS各自维护同一核心数据的各自版本,保证了对账工作、报告延迟以及关于哪个数字正确的持续争论。
2、标准化你的数据定义
如果定义不清楚,无论数据看起来多么干净,都会被质疑。当同一指标因制定者不同而变化时,领导者很快就会失去信心。
要做:为关键术语如人数、活跃员工、人员流动、全职员工和经理写下简单且共享的定义,将这些定义在人力资源、财务和领导层报告中保持一致,使所有人都遵循相同的逻辑。
不要:允许团队为方便而自行创建定义,这会导致报告冲突、数字解释浪费时间,以及基于不一致假设的决策。
3、创建明确的数据所有权
当问责制可见时,数据质量会提升。当所有权不明确时,问题就会挥之不去,因为没人觉得自己有责任去解决。
要做:为每个数据域分配清晰的所有者。例如,人力资源负责工作架构和报告行,工资部门负责薪酬元素,IT部门负责访问控制。明确谁批准变更,谁来解决错误。
不要:把数据当作每个人的责任,通常意味着当数据退化时没有人介入。
4、设定最低数据标准
并非所有数据都必须完美,但有些数据必须达到基线才能使用。
要做:定义哪些字段是强制的、经过验证并定期审查的。优先处理影响薪酬、合规、劳动力报告和系统访问的数据,这些标准起到护栏的作用,而非官僚主义。
不要:允许关键字段为可选或格式不一致,这里的小漏洞很快演变成工资错误、访问问题和不可靠的报告。
5、清理重复字段和遗留字段
旧数据结构悄悄地破坏了新的报告和分析,它们在原本的用途消失后,仍然带来噪音和混乱。
要做:定期审查字段和记录,删除未使用字段,合并重复的员工记录,并在自由文本出现的地方标准化数值。需要历史参考时,归档而非删除。
不要:保留遗留字段,仅仅因为它们存在。如果没人能解释一个领域到底是干什么的,那已经在制造风险和混乱。
6、按角色控制访问
访问应当跟随责任感,而非资历或便利,权限过剩的系统是导致错误和泄露的常见原因。
要做:设置基于角色的访问权限,让员工只能查看或编辑他们真正需要完成工作的内容。在职位变动、晋升或离职后审查访问权限,以避免权限蔓延。
不要:发放管理员权限以解决短期问题,这增加了隐私风险,也使后续追踪错误变得更困难。
7、让集成变得枯燥且可靠
可靠的数据流远比巧妙的自动化更为重要,大多数人力资源数据问题都出现在系统之间的接缝处。
要做:记录数据如何在系统间传输,包括哪个系统发送更新以及哪个系统接收更新。监控集成并快速修复故障,避免错误悄无声息地积累。
不要:依赖手动上传、平板文件交换或无监控同步,这些同步会无声无息地失败并随时间漂移。
8、建立一个简单的数据质量例程
数据质量的提升是通过定期关注,而不是英雄式的清理。
要做:安排轻量级检查,检查缺失字段、过时的经理、错误的职位代码和明显异常,让这些检查成为正常人力资源作的一部分,而不是特别项目。
不要:等待审计、工资错误或领导层审查时,才能发现数据问题。到那时,修复速度会变慢,也更具破坏性。
9、设定保留和删除规则
数据保存时间过长会导致不必要的暴露和复杂性。
要做:定义每个人力资源数据类别保留的时间以及何时被删除或匿名化,持续应用这些规则,并记录决策,使其有理有据。
不要:保留敏感的个人或财务数据“以防万一”,这增加了隐私风险,却不增加业务价值。
10、培训用户并锁定习惯
大多数人力资源数据问题源自日常行为,而非系统故障。
要做:培训你的人力资源团队成员和其他数据用户,了解数据准确性为何重要,他们的行为如何影响下游流程,以及“好”数据在实际作中是什么样子,通过入职培训和定期复习来强化期望。
不要:假设一次训练就足够了,或者人们会自然而然地遵守规则,无需强化。
在决策日益依赖证据的环境中,妥善管理的人力资源数据是至关重要的基础设施。人力资源数据管理使员工数据得以被使用,而非持续被质疑。
当数据准确、治理良好且持续维护时,人力资源团队花费的时间减少对账和纠正错误,更多时间支持重要决策,这也降低了合规风险,提高了运营效率,加快并提升了报告的可靠性。
随着时间推移,强有力的人力资源数据管理能够在组织内部建立信任。领导者知道他们可以依赖数据,员工遇到的工资和福利问题更少,人力资源也能在不失去对数据控制的情况下扩展。
 ”和“
”和“ ”,“
”,“ ”给更多的人,欢迎“
”给更多的人,欢迎“ ”写留言。
”写留言。

* 本文系作者个人观点
THE END

本文经授权发布,不代表”HR时间”立场,如有疑问请联系原作者

欢迎关注公众号
获取更多精彩

欢迎添加个人微信
共同探讨学习

