 夜雨聆风
夜雨聆风





从 Claude Code 源码泄露看 Agent 架构收敛:模型战结束了,系统战刚开始
大家好,我是视界君。
2026 年 3 月 31 日,一个 npm 包的 source map 文件,意外将 Anthropic 旗舰产品 Claude Code 的 51.2 万行 TypeScript 源码 完整暴露在公众面前。
全球数千名开发者做了同一件事:把 Claude Code 的源码喂给 Claude 自己,让它解释自己。
几个小时之内,44 个功能开关被扒出,一个内含 18 个物种和抽卡机制的 Tamagotchi 宠物系统被曝光,”Tengu””Fennec””Penguin Mode” 等内部代号被公开。
今天,我们不聊claude code的代码拆解,相信大家基本都已经看过类似的文章了。我想聊一聊,由于这次claude code源码泄露,得以窥见其agent工程架构细节,当我们把Claude Code 的架构、OpenAI 开源的 Codex CLI、Google 开源的 Gemini CLI 放在一起对比时,会发现一件令人深思的事——
大家的核心架构,惊人地相似。
一、51.2 万行源码泄露:一场意外的公开课
泄露始末
简单说一下泄露事件,Anthropic 在发布 Claude Code v2.1.88 到 npm registry 时,一个本应被 .npmignore 排除的 source map 文件(约 59.8 MB)被意外打包进了发布包。安全研究员 Chaofan Shou 率先发现了这个问题并公开。
这不是一次简单的”源码泄露”。51.2 万行代码,约 1900 个文件——这是 Claude Code 整个客户端工程 的完整暴露:Agent 循环、工具系统、上下文管理、安全层、缓存系统、多智能体协调、终端渲染,全部一览无余。
Anthropic 确认泄露后表示,不涉及用户数据和凭证,属于员工操作失误。但这已经不重要了——整个 AI Agent 行业都拿到了一份”教科书”。
一个有趣的事实
Claude Code 的代码据说 100% 由 Claude 自己编写。也就是说,开发者们正在付费(按 token 计费)让 Claude 解释 Claude 自己写的代码,来理解 Anthropic 的产品。
二、三巨头架构对比:殊途同归
让我们把三个最具代表性的 AI 编程 CLI 工具放在一起:
核心架构对照表
|
|
|
|
|
|---|---|---|---|
| Agent 循环 |
|
|
|
| 工具系统 |
|
|
|
| 上下文管理 |
|
|
|
| 权限控制 |
|
|
|
| 多智能体 |
|
|
|
| 开源状态 |
|
|
|
看到了吗?
三个产品,三家公司,三个不同的技术路线——但核心架构几乎一模一样:
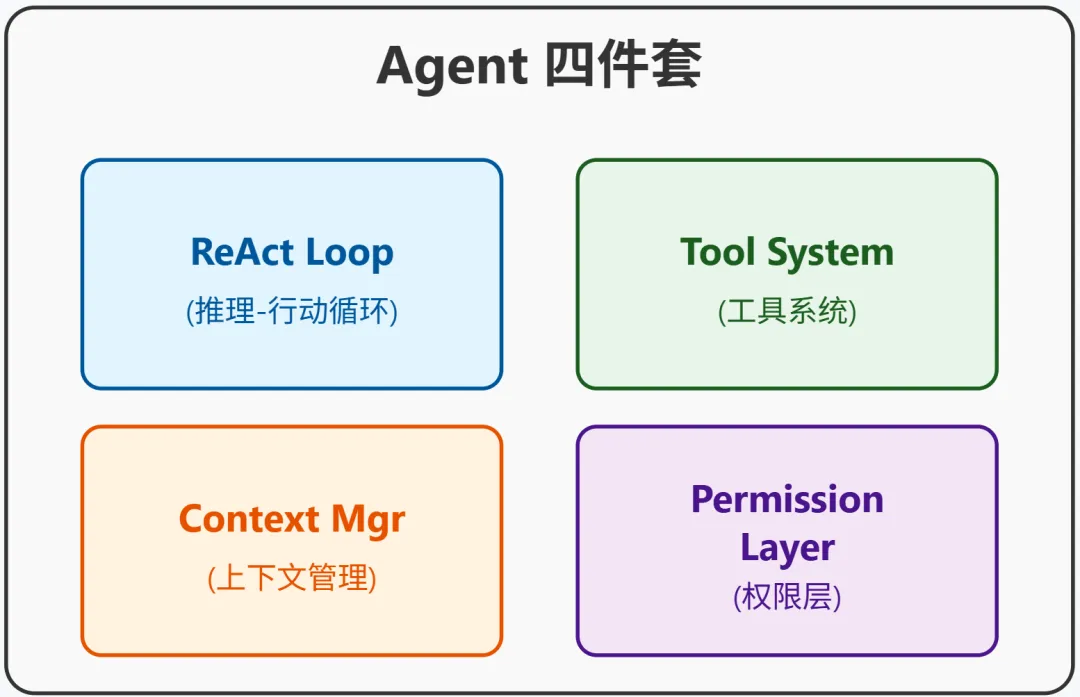
ReAct Loop + Tool System + Context Manager + Permission Layer——这就是 2026 年自主 Agent 的标准答案。
就像 Web 应用最终收敛到了 MVC 架构,就像移动应用最终收敛到了单页面 + API 调用模式,自主 Agent 正在收敛到这个”四件套”。
三、为什么架构会收敛?
设计空间的有限性
Agent 的根本任务是什么?让 LLM 持续思考和行动,直到目标达成。
这个任务定义了一个非常有限的解空间:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这不是巧合,这是 约束驱动的设计收敛。当你面对同样的约束条件,最优解的数量是有限的。
ReAct 循环:不叫 ReAct 也叫 ReAct
Claude Code 用的是 while True + stop_reason == "tool_use";Codex 用的是 Plan → Edit → Run → Observe → Repair → Repeat;Gemini CLI 用的是 ReAct Reasoning Loop。
名字不同,本质相同:
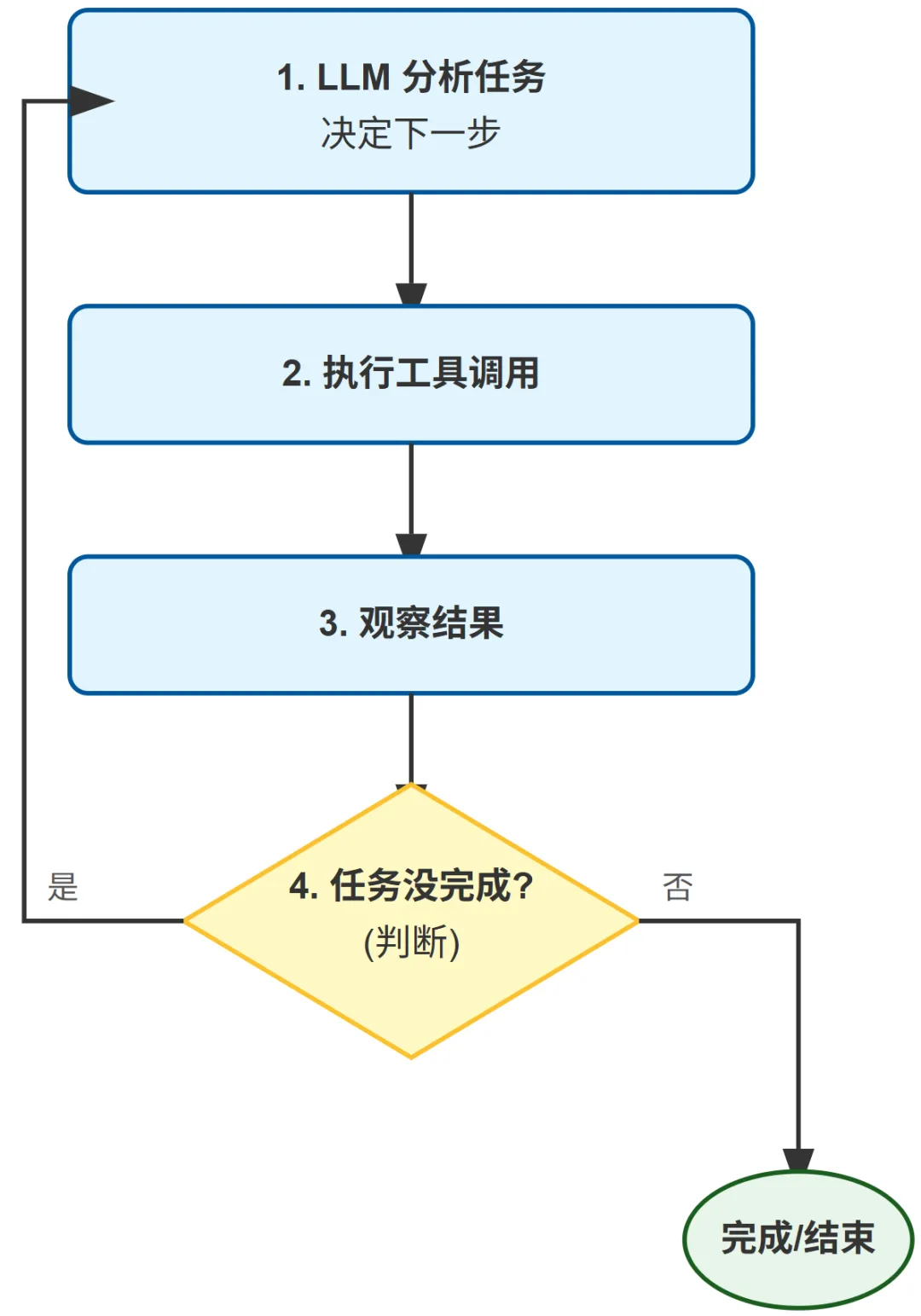
OpenAI 官方在 Unrolling the Codex Agent Loop 中详细描述了这个循环。Google 在 Gemini CLI 文档中展示了相同的模式。Anthropic 在泄露的源码中实现了相同的模式。
三条独立的进化路线,到达了同一个终点。
工具系统:从 bash 到专用工具的必然路径
三家的工具系统演进路径也高度一致:

Claude Code 有 read_file、write_file、edit_file、bash;Codex 有 Shell Tool + MCP 集成;Gemini CLI 有 Tool Calling Workflows。都在往同一个方向走。
四、如果架构相同,差异在哪里?
差异不在架构,在工程深度。
一组震撼的数据
Reddit 上有人做了一个测试:同一个 Opus 模型,在不同 Harness 上的表现差异巨大。
“Claude Code ranks 39th on terminal bench. Dead last for Opus among harnesses. Cursor’s harness gets the same Opus model from 77% to 93%.”
同一个模型,换个 Harness,性能差 16 个百分点。
这不是模型的问题,这是系统的问题。
Harness 工程深度的六个维度
从 Claude Code 泄露的源码中,我们可以看到真正的工程深度体现在哪里:
1. 缓存经济学
Claude Code 有一个专门的模块 promptCacheBreakDetection.ts,追踪 14 种不同的缓存失效向量,并使用”粘性锁存器”(Sticky Latch)机制防止模式切换打断已缓存的 prompt 前缀。
这不是性能优化,这是 计费优化。每次缓存失效都是真金白银。源码把缓存管理当作数据库查询规划一样严肃对待。
2. 记忆系统:渐进式披露
Claude Code 的记忆系统采用两层结构:
-
第一层: MEMORY.md索引(始终加载,约 200 tokens) -
第二层:完整记忆文件(按需加载,仅在索引匹配当前任务时获取)
本质上就是数据库索引的思路——维护一个小的快速查找结构,指向更大的数据。应用到 LLM 上下文窗口上,解决了”跨会话遗忘”问题,又不用预先加载所有记忆。
3. 安全加固:23 道防线
每次 bash 命令执行都要经过 23 项安全检查。包括零宽字符注入、Zsh 扩展技巧、路径遍历、注入模式等。这不是理论上的威胁模型,而是真实对抗性使用经验的积累。
4. 多智能体协调:Prompt 就是编排
Claude Code 的子智能体系统内部叫 “swarms”。令人惊讶的是,协调机制不是状态机、不是 DAG 执行器、不是编排框架——而是 自然语言 Prompt。
每个子智能体在隔离的上下文中运行,拥有特定的工具权限。编排者通过嵌入在 Prompt 中的指令来协调:质量标准、范围边界、冲突解决规则。
这传递了一个强烈信号:对于基于 LLM 的多智能体系统,传统的编排框架可能增加了不必要的复杂性。
5. 什么时候不用 LLM
Claude Code 检测用户挫败感用的是 正则表达式,不是 LLM 推理。
“wtf””so frustrating””this is broken”——简单模式匹配,触发后续响应的语气调整。不需要 API 调用。
这体现了一个核心工程原则:用最便宜、最快的工具解决问题。一个
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6. 渲染层:游戏引擎遇上了终端
Claude Code 的终端界面使用 React + Ink 构建,并采用了游戏引擎风格的渲染优化——Int32Array 缓冲区和基于补丁的更新,只在内容变化时重绘。团队声称这减少了 约 50 倍的 stringWidth 调用。
终端 UI 流式输出 LLM 内容的挑战,和游戏渲染循环高度相似:频繁的部分更新、可变长度内容、帧率敏感。这里用的是领域适配的工程方案,而不是把终端当附属品。
五、模型战结束,系统战开始
一个正在发生的历史转折
今天 Claude Code 能领先,是因为 Opus 的编程能力确实强。但模型的领先优势是有保质期的。
看看历史:
-
GPT-4 发布时领先竞品 6-12 个月 -
Claude 3.5 Sonnet 发布时领先 3-6 个月 -
Opus 4 发布时领先可能只有 1-3 个月
模型能力的差距正在以肉眼可见的速度缩小。一旦竞品的模型能力接近——而这个趋势已经在发生——竞争就会转向 Harness 层面。
Harness 工程的竞争维度
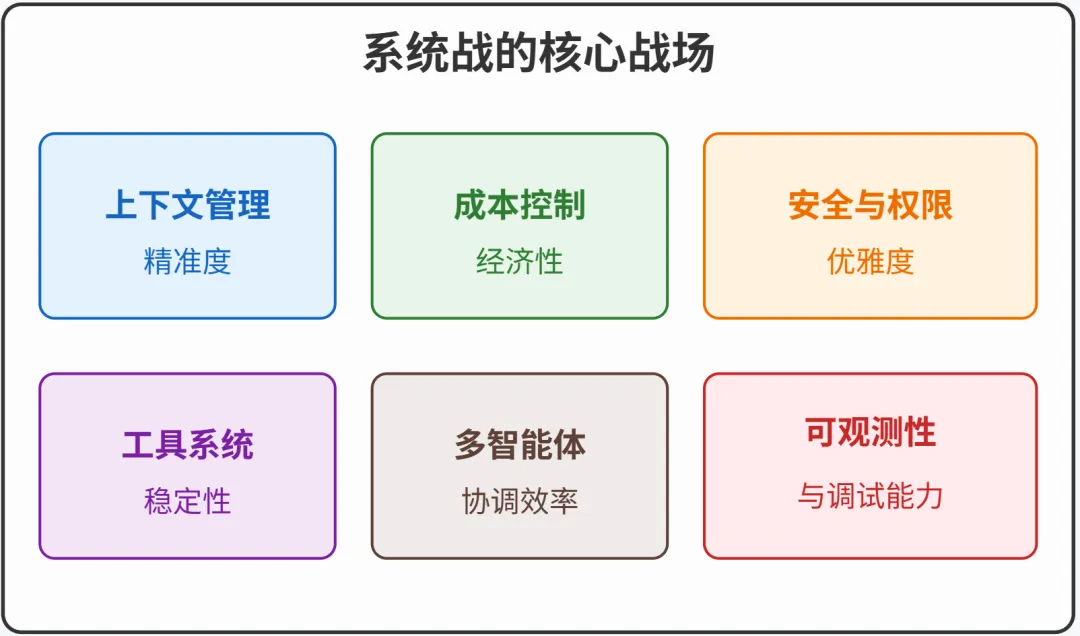
谁的上下文管理更精准——能在有限的 token 预算内保留最关键的信息?
谁的工具系统更稳定——能让模型可靠地调用正确的工具,减少无效轮次?
谁的权限设计更优雅——既能防止危险操作,又不会频繁打断正常工作流?
谁的成本控制更经济——能让用户用更少的 token 完成同样的任务?
这些问题的答案,才是下一个阶段竞争的焦点。
从”Prompt Engineering”到”Harness Engineering”
这个行业的工程范式正在经历第三次迁移:
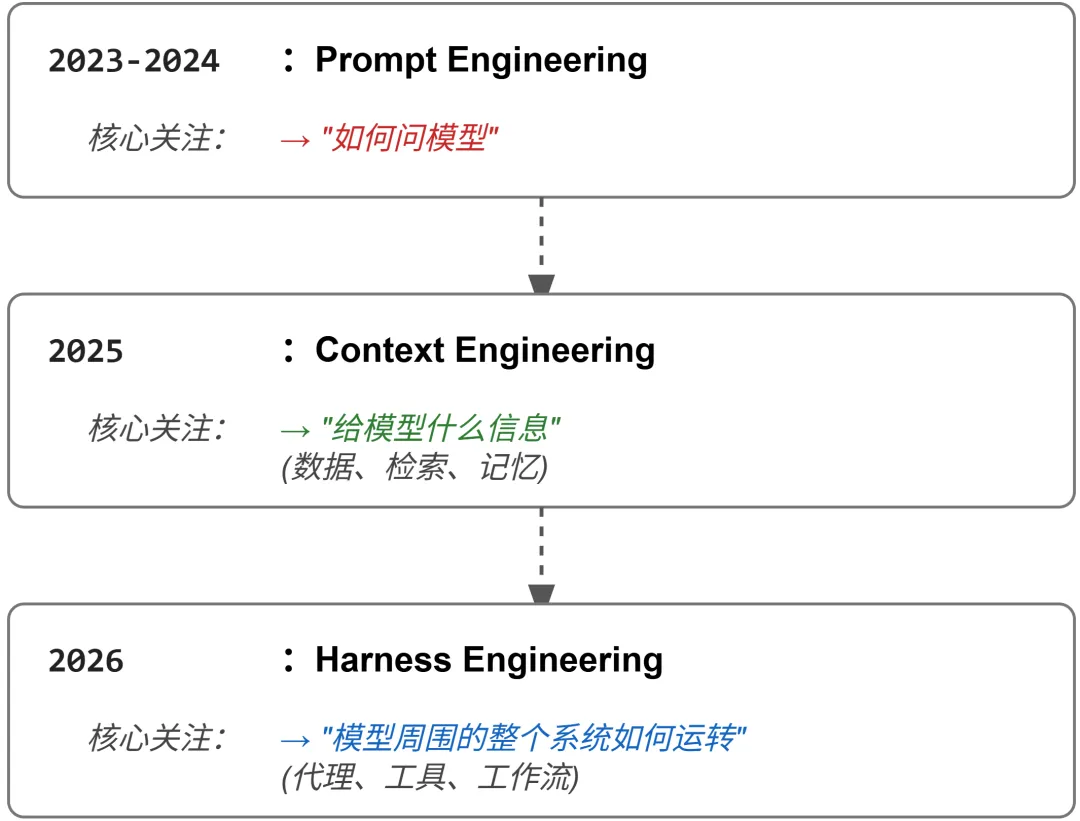
Prompt Engineering 是提问。Context Engineering 是蓝图。Harness Engineering 是施工——工具、权限、安全检查、成本控制、反馈循环、状态管理,让 Agent 可靠运转的一切。
Claude Code 的泄露源码就是一份活生生的 Harness Engineering 教科书。LLM API 调用是整个系统中最小的那个盒子。围绕它的一切——缓存、记忆、安全、成本、渲染、协调——才是真正的产品。
六、对 Agent 开发者的启示
1. 别再卷架构了,卷工程
Agent 的基本范式已经收敛。花时间发明新的架构模式,不如把现有的四件套打磨到极致。
一个 30 行的 Agent 循环 + 一个精心设计的工具系统 + 一个高效的上下文管理策略 + 一套合理的权限控制,足以构建一个生产级 Agent。
2. 系统思维比模型选择更重要
从 Claude Code 的源码中我们可以学到:真正的差异化来自系统设计的每个细节——缓存失效检测、记忆的渐进式加载、安全检查的全面性、渲染性能的优化。
这些不是”模型能解决的问题”。这是工程问题。
3. 用最简单的方案解决每个子问题
Claude Code 用正则检测情绪、用数据库索引思路管理记忆、用游戏引擎思路优化终端渲染。
不是所有问题都需要 LLM 来解决。一个好的 Harness,知道什么时候调用模型,什么时候用确定性代码。
4. 开源降低了门槛,但提高了天花板
Codex 和 Gemini CLI 已经开源。Claude Code 虽然闭源但已经泄露。这意味着所有人都拿到了”参考答案”。
但拥有答案和能写出答案之间,隔着一个 51.2 万行代码的工程鸿沟。开源降低了入门门槛,但要把这些模式做到生产级质量,需要的是工程深度,而不是架构创新。
总结
Claude Code 源码泄露这件事本身只是一个安全事故。但它意外揭示的行业真相,值得每一个 AI 从业者深思。
自主 Agent 的基本范式已经收敛。 ReAct Loop + Tool System + Context Manager + Permission Layer,这就是标准答案。Claude Code、Codex CLI、Gemini CLI,三条独立的进化路线,殊途同归。
竞争正在从”模型战”转向”系统战”。 模型的领先优势保质期越来越短。一旦模型能力趋同,真正的差异化来自 Harness 工程深度——缓存经济学、记忆系统、安全加固、成本控制、渲染优化。
模型是商品,Harness 是护城河。 51.2 万行泄露的代码告诉我们:LLM API 调用是系统中最简单的部分。围绕它的一切,才是真正的工程。
如果说 2024 年是 Agent 的”概念年”,2025 年是”模型年”,那么 2026 年正在成为 Agent 的 “工程年”。
对于 Agent 开发者来说,这是一个好消息:你不需要等待更好的模型。你只需要把现有的系统做得更深、更稳、更精细。
参考资料:
-
Everyone Analyzed Claude Code’s Features. Nobody Analyzed Its Architecture -
Claude Code’s Leaked Source: A Real-World Masterclass in Harness Engineering
-
Unrolling the Codex Agent Loop | OpenAI
-
Deconstructing Google Gemini-CLI: Source Code Analysis
-
Anthropic accidentally exposes source code for Claude Code – CNET
-
The Claude Code Leak: 10 Agentic AI Harness Patterns
-
Claude Code Source Leak: Production AI Architecture Patterns – HuggingFace
-
Comparing Claude Code, OpenAI Codex, and Google Gemini CLI – DeployHQ