 夜雨聆风
夜雨聆风





高性能运动数据共享新解法!合成数据的应用考量


该文献是发表于Sports Medicine(IF=9.4)的《Synthetic Data for Sharing and Exploration in High‑Performance Sport: Considerations for Application》–高性能运动中用于共享和探索的合成数据:应用考量

论文创新点
01
1、首次系统探讨了基于顺序树算法的合成数据生成方法在高性能体育运动员监测数据中的应用。
2、通过多种模拟条件,揭示了合成数据生成模型与分析模型之间的一致性对数据可用性的关键影响。
3、提出了合成数据生成过程中需明确记录模型设定、变量关系及使用限制的建议,推动体育科学中开放科学与FAIR数据原则的实施。

研究背景
02
在体育科学中,尤其是高性能运动环境下,数据常被视为竞争优势,难以公开共享,限制了开放科学与FAIR数据原则的推广。合成数据作为一种替代性数据源,可在保护个体隐私的前提下模拟原始数据特征,促进数据共享与二次分析。本研究以职业足球运动员的负荷与伤病数据为例,探讨合成数据在体育科研中的应用潜力与挑战。
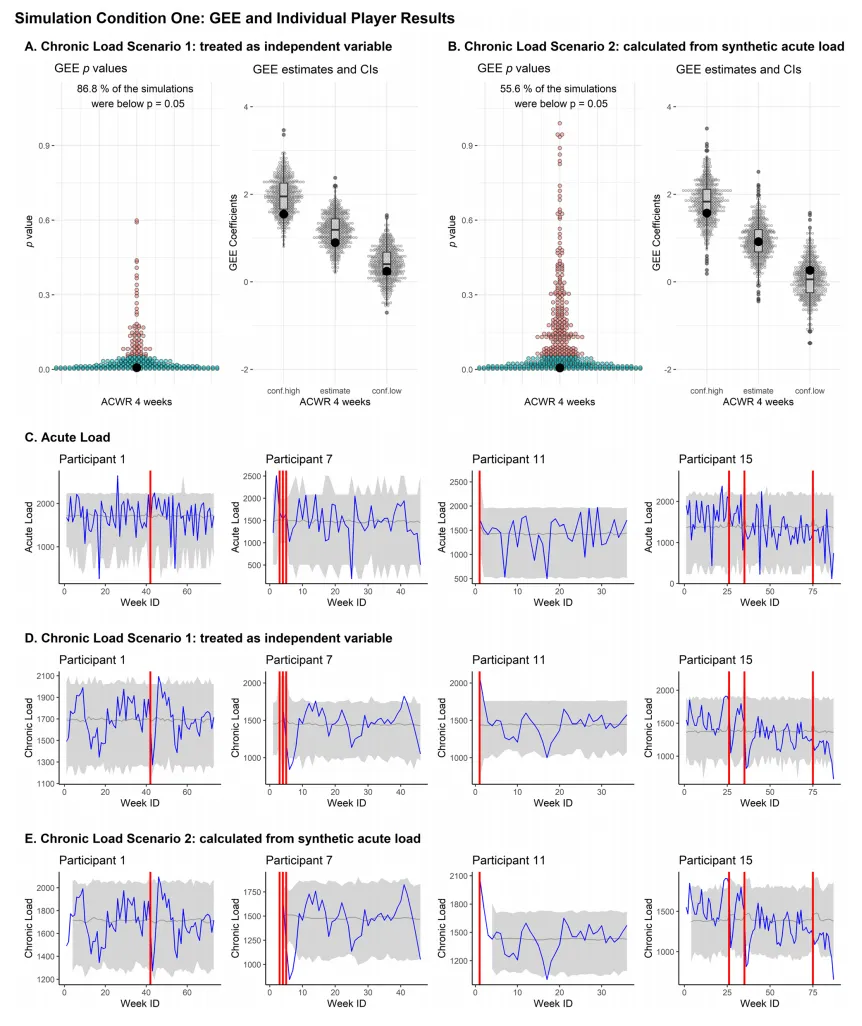

图1(Fig.1)模拟条件 1 的 GEE 结果与运动员个体数据:该图显示基础模拟条件下合成数据能精准复刻原研究 GEE 分析结果,但因未纳入时间预测变量,无法保留运动员个体训练负荷的纵向时间趋势,表现为负荷数据的置信区间极宽。
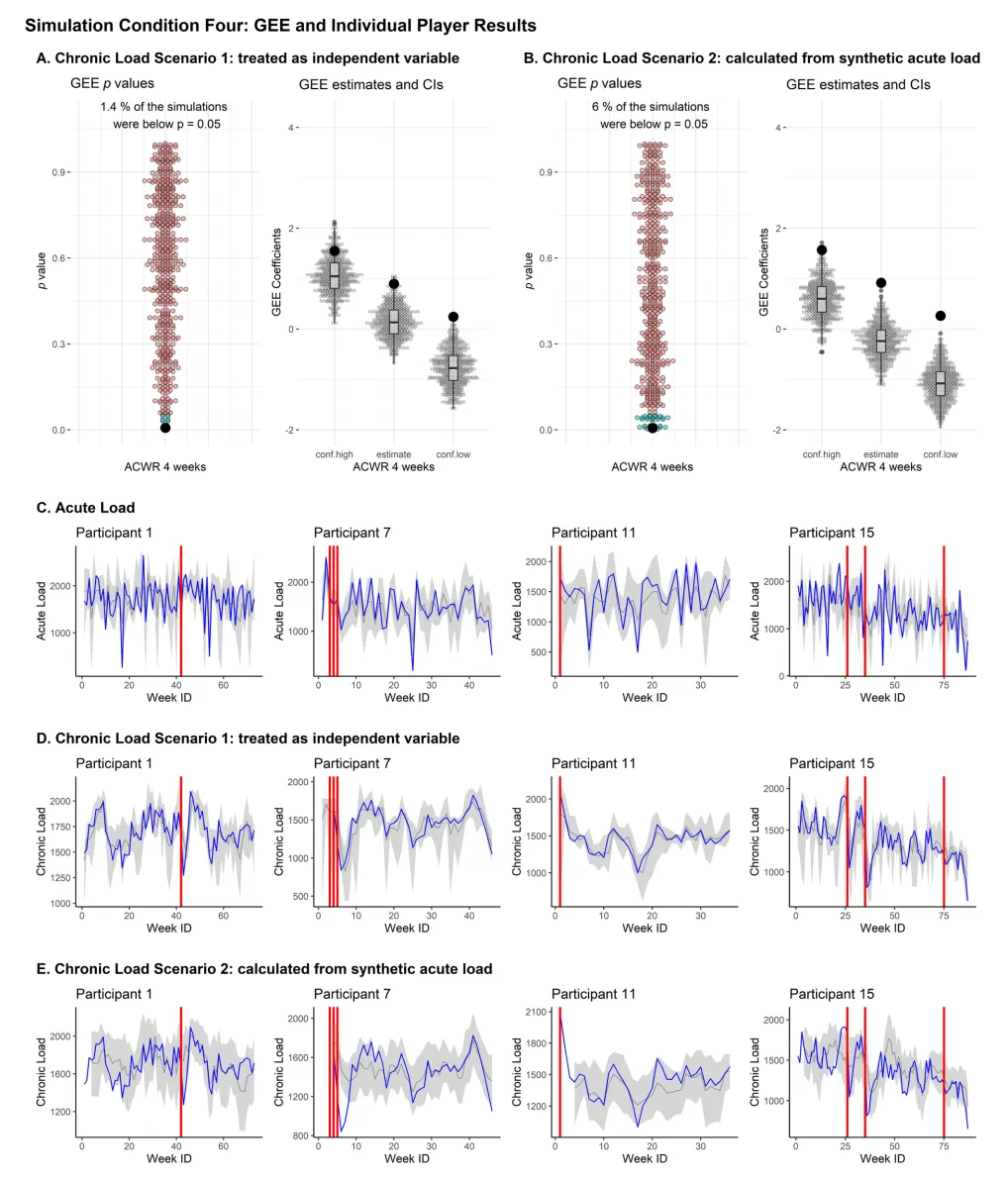

图 2(Fig.2)模拟条件 4 的 GEE 结果与运动员个体数据:该图显示当生成模型加入多个时间滞后变量后,合成数据能很好保留运动员个体训练负荷的纵向时间趋势(置信区间收窄),但GEE结果复现能力明显下降。

研究方法
03
1、数据来源
使用Fanchini等人(2018)发表的职业足球运动员数据集,包含34名球员、120周的训练负荷与伤病记录。
2、纳入标准
聚焦训练负荷与非接触性损伤的关联研究场景,纳入能反映运动员纵向监测特征的数值型、名义型、二分类变量;选取急性负荷、慢性负荷、伤病状态、球员ID和周次ID五个变量用于合成数据生成。
3、结局指标
全局效用(数据集整体相似性)与特定效用(原始研究结果的复现能力),同时记录计算时间、负荷变量的平均绝对误差。
4、分析方法
使用R语言中的synthpop包,基于分类与回归树(CART)方法,设置七种模拟条件,评估不同变量生成顺序与预测变量对合成数据质量的影响。

研究结果
04
在所有模拟条件下,合成数据均表现出较高的全局效用。然而,特定效用(即复现原始广义估计方程结果的能力)在生成模型与原始分析模型一致时最佳(模拟条件1)。随着时间预测变量的增加,虽然个体负荷趋势的复现能力提升,但GEE结果的复现能力下降。合成伤病变量时计算负担显著增加(单次生成超22分钟)。研究表明,合成数据的用途高度依赖于其生成过程中的模型设定与变量关系保留情况。
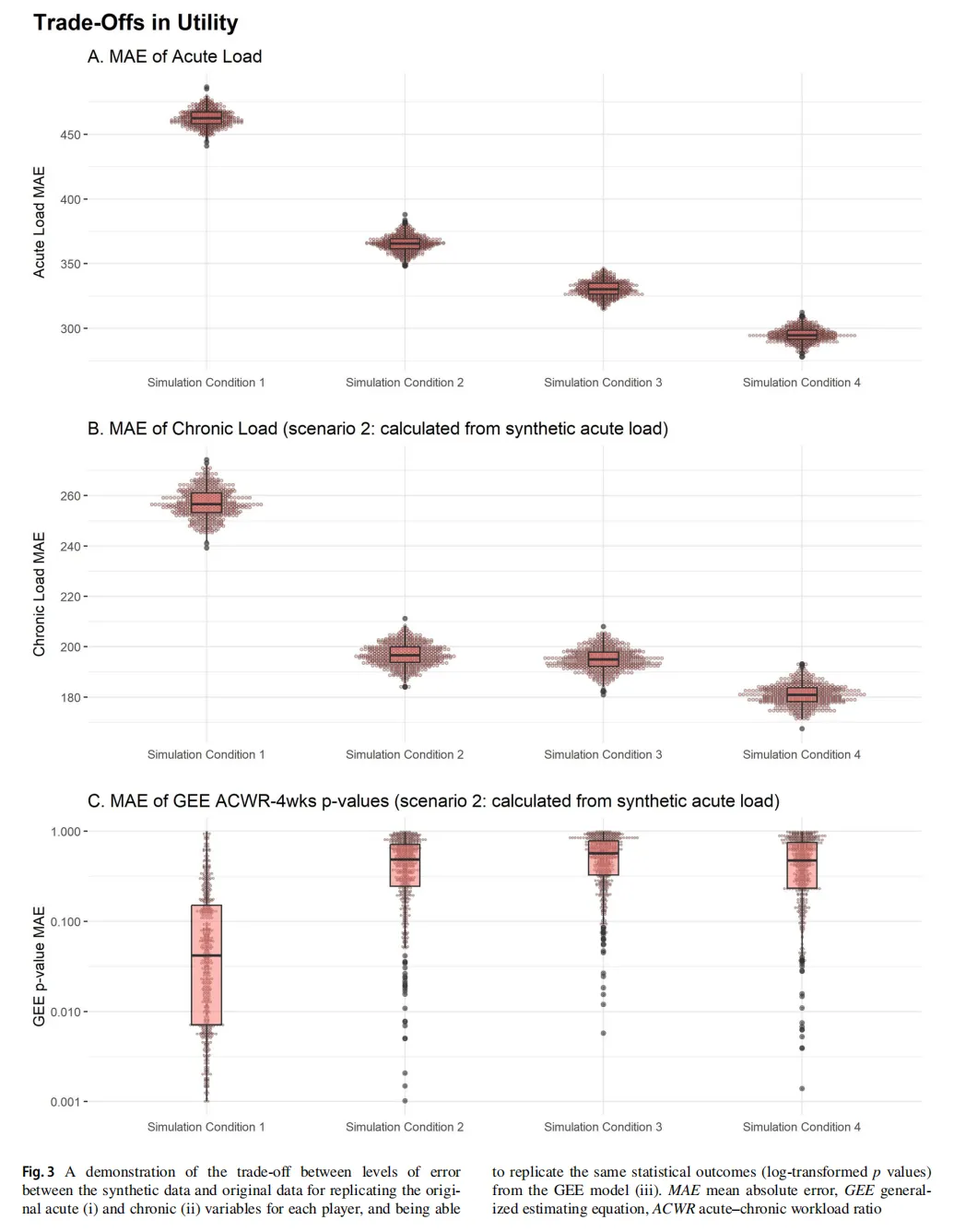
图3(Fig.3)效用间的权衡关系:该图直观呈现了合成数据生成过程中的核心权衡,随着生成模型中加入更多时间预测变量(从条件1到条件4),合成数据在复现个体负荷时间轨迹方面的精度不断提高(图3A、3B误差下降),但其在复现原始研究统计结果(GEE分析)方面的能力却不断下降(图3C误差上升)。
这一可视化结果直接支撑了文章的核心结论——合成数据的生成模型必须与其预期用途相匹配,揭示了生成模型与原始分析模型一致性对特定效用的关键影响。

研究结论
05
1、合成数据生成模型决定其适用场景
合成数据的可用性取决于其生成模型是否与原始分析模型一致。若仅用于复现原研究结果,生成模型应尽量贴近原分析模型;若用于探索性分析,则需保留更多原始数据特征(如时间趋势)。研究者应明确说明生成过程与使用限制。
2、生成合成数据需保留变量间数学确定性关系
对于存在确定性关系的变量(如慢性负荷由急性负荷计算得出),应优先从合成变量中推算,而非独立生成,以避免引入数学上的不合理性,确保后续分析的生物学与统计学合理性。研究人员需识别数据集中的变量关系类型,在生成过程中维护其内在逻辑,保障合成数据的数学合理性。
3、计算效率与模型复杂度需权衡
在合成具有高基数变量(如球员ID)或复杂时序结构的变量时,计算成本可能急剧上升。研究者应根据研究目标合理简化模型,或在效率与准确性之间做出明确权衡,并在文档中加以说明。
4、运动领域需建立合成数据的透明化管理体系
合成数据的公开和使用需配套完善的文档说明,应包含生成过程的详细信息(预测变量、模型框架、模拟条件)、效用评估指标及结果、数据使用的边界和局限性。同时需向开放科学社区提供生成代码和软件环境,且需平衡多数据集释放与运动员隐私保护的风险。
全文链接 Full text link
https://doi.org/10.1007/s40279-025-02221-6
