 夜雨聆风
夜雨聆风





基于深度学习实现跌倒检测(附源码)
点击下方卡片,关注“机器视觉与AI深度学习”
视觉/图像重磅干货,第一时间送达!

为什么是 GRU
门控循环单元 ( GRU ) 网络是一种循环神经网络,旨在高效处理顺序数据。与 LSTM 不同,GRU 的架构更简单,消除了存储单元,只使用两个门(更新和重置)。这使它们更快、更轻量,非常适合我们的情况,因为我们需要实时处理动作而不影响性能。此外,对于跌倒检测等短序列,GRU 的表现通常与 LSTM 一样好,提供了更高效的解决方案而不牺牲准确性。
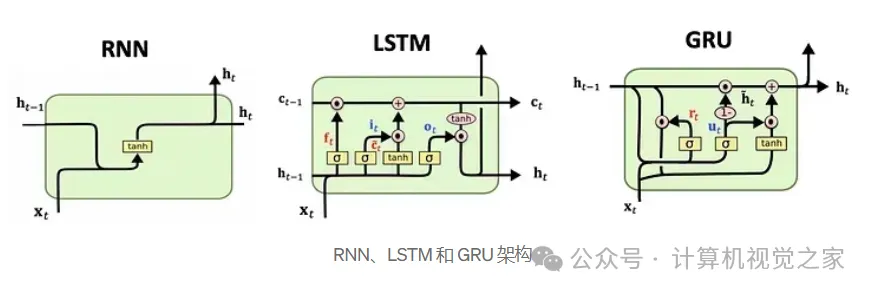
为了使用 GRU 识别动作,我们将每个动作表示为一系列单独的姿势 – 我们的基本单位。每个姿势都由与身体关节相对应的关键点列表组成。由于人类运动通常遵循平滑的轨迹,因此 GRU 学会捕捉时间模式而无需存储复杂状态,使其成为这项任务的更有效选择。
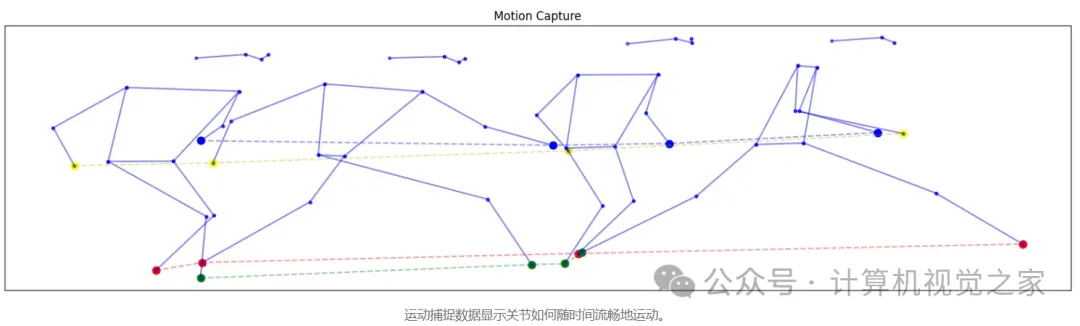
构建数据集
为了构建数据集,我使用了YouTuber Kevin Parry的视频《50 Ways to Fall》。使用FFmpeg,我将视频分成三个部分:跌倒、正常时刻和完整视频。对于训练,我只使用了跌倒和正常运动部分,以确保数据集更加平衡。您可以在以下链接下载预处理和分类后的数据:
https://www.youtube.com/channel/UCzgkpehSWuFTQx9E8NkBqzw使用YOLOv11 Pose模型进行姿势提取,该模型检测人体的17个关键点,提供有关关节位置和运动的详细信息。

我没有使用整个序列作为单个数据点,而是选择使用较小的子序列。人类动作识别通常只需要几个连续的帧(1 到 10 帧之间)即可有效。在这种情况下,我使用了20 帧的序列长度。
如果视频少于20 帧,我们会通过复制最后检测到的姿势来填充序列。如果视频较长,我们只取最后 20 帧,以便更好地捕捉跌倒的最后阶段,这对于检测最为重要。
import osimport cv2import numpy as npfrom ultralytics import YOLOdef extract_keypoints_from_video(video_path: str, model, sequence_length: int = 10, save: bool = False, output_path: str = 'keypoints.npy'):num_keypoints = 17 * 2 # Número de keypoints (17 puntos * 2 coordenadas x, y)if not os.path.exists(video_path):raise FileNotFoundError(f'El archivo de video {video_path} no existe')cap = cv2.VideoCapture(video_path)keypoints_buffer = []while True:ret, frame = cap.read()if not ret:break # Video terminadoresults = model(frame)[0]if len(results.keypoints.xy) > 0:keypoints = results.keypoints.xy[0].numpy().flatten()if keypoints.shape[0] != num_keypoints:keypoints = np.pad(keypoints, (0, num_keypoints - keypoints.shape[0]))else:# Si no se detectan keypoints, usar ceroskeypoints = np.zeros(num_keypoints, dtype=np.float32)keypoints_buffer.append(keypoints)cap.release()# Manejar casos donde el video es más corto o más largo que sequence_lengthif len(keypoints_buffer) < sequence_length:# Si el video es más corto, repetir el último frame hasta completar sequence_lengthlast_frame = keypoints_buffer[-1]while len(keypoints_buffer) < sequence_length:keypoints_buffer.append(last_frame)elif len(keypoints_buffer) > sequence_length:# Si el video es más largo, tomar solo los últimos sequence_length frameskeypoints_buffer = keypoints_buffer[-sequence_length:]keypoints_buffer = np.array(keypoints_buffer, dtype=np.float32)if save:np.save(output_path, keypoints_buffer)print(f'Guardado en {output_path}')return keypoints_buffer
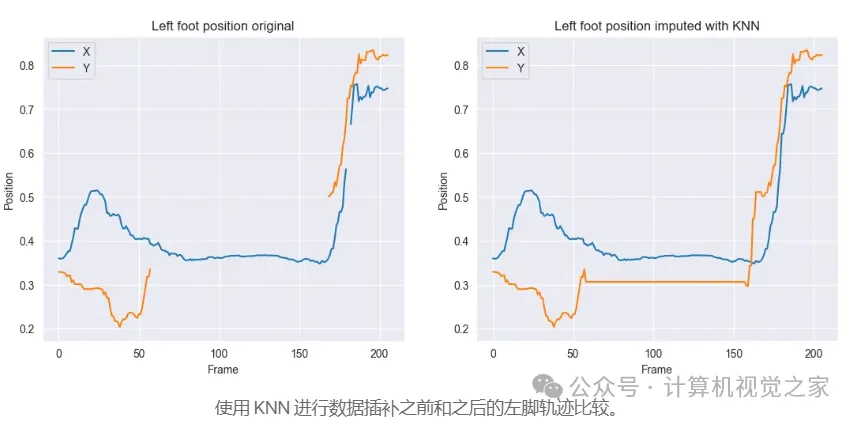
提取姿势数据时的一个常见问题是无法检测某些身体部位。最初,这些缺失关键点的 (x, y) 坐标设置为0,然后在后期处理期间替换为NaN。然而,GRU 无法处理 NaN 值,而留下零会通过引入误导性信息对模型性能产生负面影响。
为了解决这个问题,我选择使用具有5 个最近邻居的K-Nearest Neighbors (KNN) 来填补缺失值。这种方法有助于适应非线性运动轨迹,提供更一致的输入数据并提高模型的准确性。
构建 GRU 模型
利用预处理后的数据,我们现在可以构建基于 GRU 的模型,将动作分为两类:“跌倒”或“不跌倒”。我们选择基于 GRU 的架构而不是 LSTM,因为 GRU 的计算效率更高,并且可以更好地处理短序列而不会丢失重要信息。
为了实现,我们使用了 PyTorch 并定义了一个顺序模型。第一层是 GRU,它处理从YOLO Pose中提取的关键点序列。然后,我们应用批量归一化来稳定训练,然后是具有 ReLU 激活的密集层,以捕获更复杂的模式。此外,我们在输出层中加入了 dropout 以减少过度拟合,并加入了 sigmoid 激活,因为这是一个二元分类问题。
import torchimport torch.nn as nnclass FallDetectionGRU(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size, dropout_prob=0.5):super(FallDetectionGRU, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layers# Capa GRU (en vez de LSTM)self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout_prob if num_layers > 1 else 0)# Batch Normalizationself.bn = nn.BatchNorm1d(hidden_size)# Capas fully connected adicionalesself.fc1 = nn.Linear(hidden_size, hidden_size // 2)self.fc2 = nn.Linear(hidden_size // 2, hidden_size // 4)self.fc3 = nn.Linear(hidden_size // 4, output_size)# Dropout para regularizaciónself.dropout = nn.Dropout(dropout_prob)# Funciones de activaciónself.relu = nn.ReLU()self.sigmoid = nn.Sigmoid()# Inicialización de pesosself._init_weights()def _init_weights(self):"""Inicialización de pesos para mejorar la convergencia."""for name, param in self.gru.named_parameters():if 'weight_ih' in name or 'weight_hh' in name:nn.init.xavier_uniform_(param.data)elif 'bias' in name:param.data.fill_(0)for m in self.modules():if isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')m.bias.data.fill_(0.01)def forward(self, x):# Inicializar estado oculto (sin c0)h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)# Pasar a través de la GRUout, _ = self.gru(x, h0)# Tomar la salida del último paso de tiempoout = out[:, -1, :]# Batch Normalizationout = self.bn(out)# Capas fully connected con activaciones y dropoutout = self.fc1(out)out = self.relu(out)out = self.dropout(out)out = self.fc2(out)out = self.relu(out)out = self.dropout(out)out = self.fc3(out)# Aplicar sigmoide para obtener probabilidadesout = self.sigmoid(out)return out
模型训练
对于训练,我使用BCELoss(二元交叉熵损失)作为损失函数,它非常适合这类二元分类问题。由于模型的输出是概率(经过S 型激活后),BCELoss 有助于最大限度地减少跌倒分类中的不确定性。
作为优化器,我选择了AdamW ,这是Adam的一个带有权重衰减的变体。与标准 Adam 不同,AdamW 将 L2 正则化与梯度更新分离,使其在深度网络中更能抵抗过度拟合。此外,它比 SGD 更高效,因为它可以动态调整每个参数的学习率,从而加速收敛。
为了防止过拟合,我实施了提前停止,耐心等待 10 个时期。如果验证损失在连续迭代中停止改善,则训练会自动停止。这有助于防止过度拟合并消除不必要的训练时间。此外,根据最低验证损失保存最佳模型,确保最终版本最适用于新数据。
import torchimport torch.nn as nnimport torch.optim as optimdef train_model(model, train_loader, val_loader, num_epochs=200, learning_rate=0.0001,weight_decay=1e-4, patience=10, device="cuda" if torch.cuda.is_available() else "cpu"):"""Entrena un modelo de detección de caídas usando GRU.Args:model (torch.nn.Module): Modelo a entrenar.train_loader (DataLoader): DataLoader para los datos de entrenamiento.val_loader (DataLoader): DataLoader para los datos de validación.num_epochs (int): Número de épocas de entrenamiento.learning_rate (float): Tasa de aprendizaje.weight_decay (float): Parámetro de regularización L2.patience (int): Número de épocas sin mejora antes de early stopping.device (str): Dispositivo a usar ("cuda" o "cpu").Returns:model: Modelo entrenado.history: Diccionario con métricas de entrenamiento y validación."""model.to(device)criterion = nn.BCELoss() # Binary Cross Entropy Lossoptimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)# Listas para almacenar métricashistory = {"train_loss": [], "val_loss": [], "train_acc": [], "val_acc": []}best_val_loss = float("inf")patience_counter = 0best_model = Nonefor epoch in range(num_epochs):model.train()train_loss, correct, total = 0, 0, 0for batch_X, batch_y in train_loader:batch_X, batch_y = batch_X.to(device), batch_y.to(device)optimizer.zero_grad()outputs = model(batch_X).squeeze()loss = criterion(outputs, batch_y)loss.backward()optimizer.step()train_loss += loss.item()predicted = (outputs >= 0.5).float()correct += (predicted == batch_y).sum().item()total += batch_y.size(0)avg_train_loss = train_loss / len(train_loader)train_accuracy = correct / totalhistory["train_loss"].append(avg_train_loss)history["train_acc"].append(train_accuracy)# Evaluación en validaciónmodel.eval()val_loss, correct, total = 0, 0, 0with torch.no_grad():for batch_X, batch_y in val_loader:batch_X, batch_y = batch_X.to(device), batch_y.to(device)outputs = model(batch_X).squeeze()loss = criterion(outputs, batch_y)val_loss += loss.item()predicted = (outputs >= 0.5).float()correct += (predicted == batch_y).sum().item()total += batch_y.size(0)avg_val_loss = val_loss / len(val_loader)val_accuracy = correct / totalhistory["val_loss"].append(avg_val_loss)history["val_acc"].append(val_accuracy)# Guardar el mejor modeloif avg_val_loss < best_val_loss:best_val_loss = avg_val_lossbest_model = model.state_dict()patience_counter = 0else:patience_counter += 1# Early Stoppingif patience_counter >= patience:print(f"⏹️ Early stopping en la época {epoch + 1}")breakif (epoch + 1) % 5 == 0:print(f'Epoch {epoch + 1}: 'f'Train Loss: {avg_train_loss:.4f}, Train Acc: {train_accuracy:.4f} | 'f'Val Loss: {avg_val_loss:.4f}, Val Acc: {val_accuracy:.4f}')# Restaurar el mejor modeloif best_model:model.load_state_dict(best_model)print("✔️ Modelo restaurado al mejor estado guardado.")return model, history
为了优化基于 GRU 的模型的性能,我对几个关键的超参数进行了微调,包括 epoch 的数量、批量大小和学习率。
由于实施了提前停止,因此epoch 的数量并不是一个关键因素,因此将其设置为300 epoch。关于批大小,我测试了8、16、32 和 64,发现8在模型收敛中提供了更大的稳定性。0.0005的学习率确保了稳定的训练。
为了增强泛化能力并防止过度拟合,我采用了1e-6的权重衰减,在不影响性能的情况下调节模型的权重。最后,使用了0.6的dropout率来减少对特定模式的依赖,从而提高了模型对新数据进行泛化的能力。
from src.models import FallDetectionGRUfrom src.training import train_modelbatch_size = 8train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)model = FallDetectionGRU(input_size=34,hidden_size=64,num_layers=2,output_size=1,dropout_prob=0.6)trained_model, history = train_model(model,train_loader,val_loader,num_epochs=300,learning_rate=.0005,weight_decay=1e-6,patience=15)
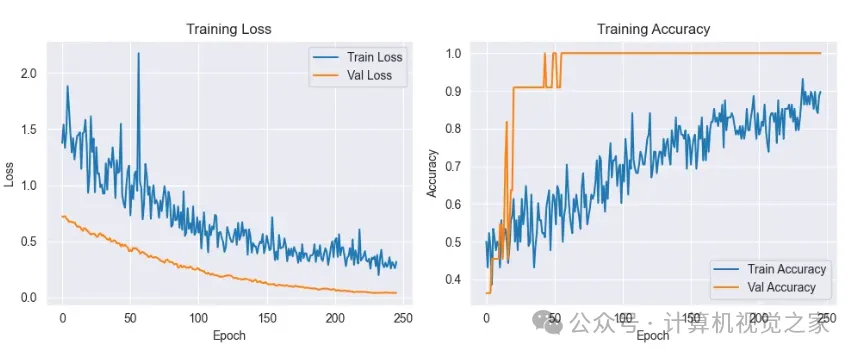
该模型实际运行的一些示例:



测试结果
测试集的结果是积极的,对可用数据的分类准确。但需要注意的是,使用的数据集很小,没有涵盖各种场景或姿势,这可能会影响模型推广到新情况的能力。
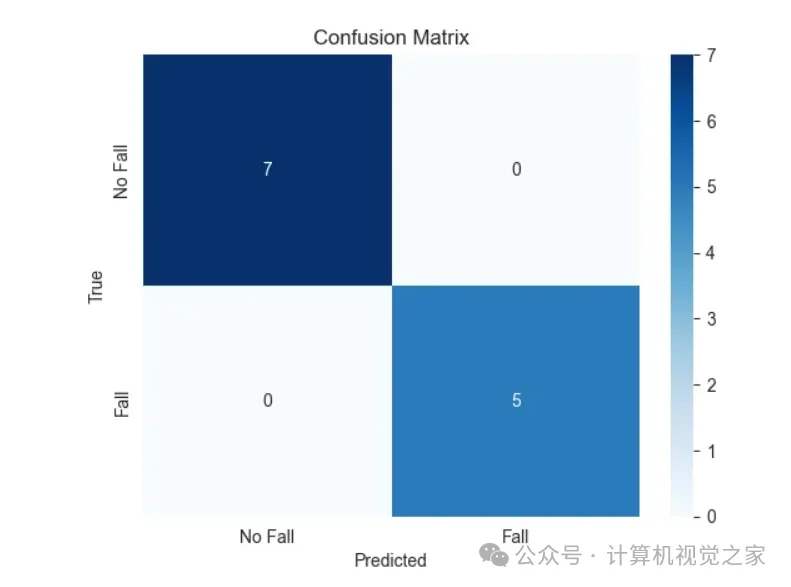
混淆矩阵 GRU 测试
为了排除过拟合,我使用外部数据集中的视频测试了该模型,例如GMDCSA24:视频中人体跌倒检测的数据集。跌倒检测非常准确,可以正确识别跌倒视频和相关姿势。但是,在某些情况下,它会产生误报,在没有发生跌倒的场景中检测到跌倒,例如弯腰捡起物体、在地板上做俯卧撑或躺在床上。

应用场景
跌倒检测在各种场景中都有多种应用,可以提供关键帮助。一些示例包括:
-
老年人护理:能够自动监控行动不便的个人,一旦发生跌倒,即可向家人或医疗服务部门发出警报。
-
医院和康复中心:帮助监督有跌倒风险的患者,减少房间或走廊内的事故。
-
在危险环境中的工人:例如建筑或采矿,及时检测到跌倒可以防止致命事故。
-
孩子们在游乐场上摔倒和受伤的情况很常见。
在危急情况下,快速跌倒检测可以及时干预,避免造成严重甚至致命的后果。
源码下载:
https://github.com/Erik172/fall-detection-deep-learning?source=post_page-----2941db4c95a3---------------------------------------
—THE END—

觉得有用,麻烦给个赞和在看