 夜雨聆风
夜雨聆风





一条命令搞定文档知识图谱!这个开源工具让你轻松提取结构化知识
前言
平时面对长篇大论的非结构化文档,想要提取出清晰的实体关系和核心信息,光靠手写提示词和解析代码实属心累。

今天给大家介绍一个实用的开源工具——Hyper-Extract,一条命令就能把文档转化为结构化的知识图谱,值得一试。
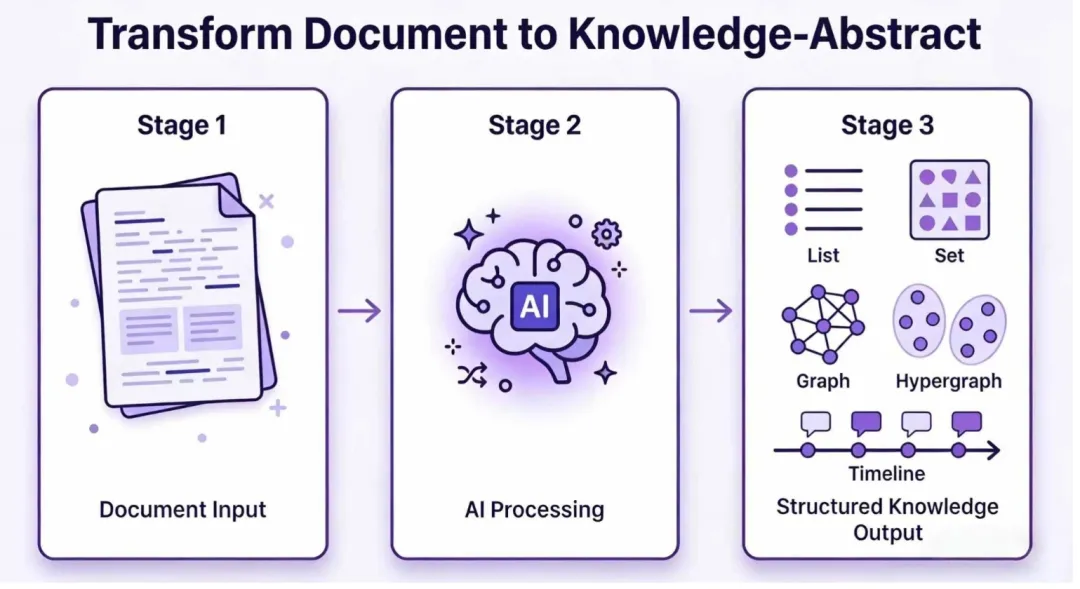
核心功能亮点
1. 预设模板丰富,覆盖多领域
内置80多个预设模板,覆盖金融、法律、医疗、中医、工业等6个领域。不用写代码,用YAML配置文件就能定义提取规则,上手门槛极低。
2. 多种知识结构输出
支持8种知识结构输出,除了常见的知识图谱,还能生成超图、时空图等高阶结构。这样的功能在同类工具中几乎找不到。
3. 增量更新,自动化扩展
支持增量更新,后续补充新文档时,知识会自动扩展演化,不用每次从头来。这对需要持续积累知识的场景非常友好。
适用场景
如果你经常需要从大量文档中梳理:
-
人物关系 -
事件脉络 -
专业知识体系
那么这个工具绝对值得试试。
项目地址:http://github.com/yifanfeng97/Hyper-Extract[1]
延伸思考:信息阶层的力量
看知识图谱时,你有没有注意到一些规律?
在深入分析之前,其实还有一个更底层的概念——「信息阶层」。
信息阶层 = 按重要程度有序排列内容
人的大脑有个特点:结构不可见时,认知成本会变成3倍。因此,整理的本质不只是让页面看起来整洁,而是让思维更加清晰。
把重要信息放在最显眼的位置,次要信息逐层递进,这不仅是视觉设计,更是一种认知优化。
结语
无论是用工具提取结构化知识,还是用「信息阶层」优化内容呈现,核心都是——让复杂信息变得易于理解。
希望今天的分享对你有帮助!如果你觉得有用,欢迎转发给需要的朋友。
引用链接
[1]http://github.com/yifanfeng97/Hyper-Extract