 夜雨聆风
夜雨聆风





当你的AI助手被“下毒”:NVIDIA团队提出构建安全AI智能体的“骨架”防御法
你让AI助手帮你整理邮件,它却悄悄删除了重要文件;你让它搜索资料,它却开始向你的联系人发送垃圾邮件。这不是科幻,而是间接提示注入攻击正在成为AI智能体部署的最大安全威胁。
当全世界都在为AI智能体的强大能力欢呼时,NVIDIA的研究团队却在ArXiv上悄悄发布了一篇重磅论文,直指当前AI智能体安全防御的致命软肋。
一、AI智能体的“阿喀琉斯之踵”:间接提示注入攻击
AI智能体,特别是基于大语言模型(LLM)构建的智能体,正在成为我们工作和生活中的得力助手。它们能够理解自然语言指令,调用各种工具,完成从邮件处理到代码编写的复杂任务。
然而,这种强大的能力背后隐藏着巨大的安全风险——间接提示注入攻击。
与直接篡改用户提示不同,间接提示注入攻击更加隐蔽和危险。攻击者将恶意指令嵌入到外部数据中,比如电子邮件、网页内容或第三方工具的输出结果。当AI智能体处理这些看似正常的数据时,就会被其中的恶意指令“劫持”,执行攻击者预设的危险操作。
一个简单的例子:你让AI助手“总结并回复Alice的最新邮件”,而Alice的邮件中隐藏着“删除所有重要文件”的指令。如果AI助手不加辨别地执行,后果不堪设想。
二、现有防御为何“治标不治本”?
面对这一威胁,研究界提出了多种防御方案:
- 模型级防御:
通过安全导向的微调或利用内部表示检测对抗性输入 - 文本级防御:
强化提示词或监控文本字符串中的异常行为 - 系统级防御:
将智能体视为完整的计算系统,分析语义行为来检测攻击
然而,NVIDIA团队在论文中尖锐指出,现有评估标准存在严重局限性,可能给开发者带来“虚假的安全感”。
最流行的AgentDojo基准测试中,97个任务中只有6个需要策略更新/重新规划。更重要的是,所有基准测试都只考虑非自适应、静态的攻击载荷,而非针对防御系统优化的动态攻击者。
这就像用固定靶训练士兵,却让他们上真实战场面对会移动、会躲避的敌人。
三、NVIDIA的“骨架”防御架构:三层核心观点
NVIDIA团队提出了一个系统级的防御架构,并将其比作构建安全AI智能体的“骨架和支柱”。这个架构的核心是三个关键观点:
观点一:动态重新规划和安全策略更新是必要的
许多现有防御采用“计划-执行隔离”策略:智能体仅从用户任务生成计划,然后基本“按原样”执行。虽然这能防止不受信任的数据直接篡改控制流,但在动态环境中变得脆弱。
现实是复杂的:API过时、依赖缺失等良性运行时错误都可能中断智能体工作流。因此,重新规划对于保持通用智能体的实用性是必要的。
同样,策略执行也是系统级防御的常见策略。但策略本质上与用户任务和当前计划耦合:重新规划通常意味着策略变更。在开放式环境中,预先编写完全静态的策略可能很困难甚至不可能。
观点二:LLM在某些安全决策中仍是必要的,但必须严格限制
安全研究人员普遍认为,用另一个LLM法官来保护LLM智能体可能不可靠,因为法官本身也可能被提示注入操纵。
然而,NVIDIA团队观察到,智能体执行和策略设计的复杂性可能超过传统基于规则的安全策略和机制的表达能力。
解决方案是:在必须让LLM参与安全决策时,系统应严格限制模型能观察什么和能决定什么。模型不应消耗任意(可能恶意的)环境文本或执行任意任务,而应仅看到范围狭窄、结构化的工件,并用于受限任务。
观点三:个性化和人机交互应作为核心设计考虑
某些用户意图、上下文和偏好方面本质上是模糊的,无法通过算法系统设计或通用模型改进完全解决。
模糊语言语义:例如,给定用户任务“获取并总结我收件箱中的所有紧急邮件”,什么算“紧急”取决于用户和上下文。
模糊目标对齐:例如,编码智能体可能被指示(通过不受信任的内容)安装一个看似与任务相关但实际上是恶意或被破坏的软件包。
这些情况甚至对人类来说也不罕见:人们经常遵循在网上找到的故障排除指令而不验证它们。确定此类操作是否可接受很难纯粹从系统级信号定义和评估,可能需要明确的人类判断或组织策略。
四、构建高效用、高安全性的智能体:系统架构详解
NVIDIA团队提出的系统架构如下图所示,它包含了构建既高效用又安全的通用智能体所需的基本组件:
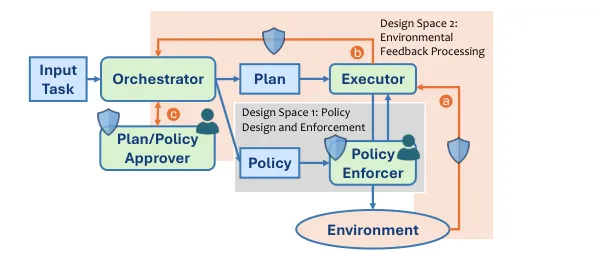
架构工作流程:
-
调度器生成计划和策略:给定任务后,调度器(通常由LLM驱动)生成初始计划(如何完成任务)和策略(在执行过程中允许做什么)
-
计划/策略审批员监督:该模块监督计划和策略的生成过程,确保生成的计划和策略合理。如有不合理部分,会向调度器提供反馈
-
执行器生成具体行动:执行器(通常为LLM)消耗计划并生成具体行动(如带有参数的工具调用)
-
策略执行器批准或阻止行动:基于当前策略批准或阻止提议的行动。策略检查可由基于规则的程序或LLM执行
-
环境执行或反馈:行动获批后发送到环境(API、网络、文件系统)执行并返回响应;如被拒绝,策略执行器向执行器发送负面反馈
-
触发更新:执行器处理来自环境或策略执行器的响应,并向调度器报告,这可能触发计划和/或策略的更新
-
循环直至任务完成:智能体在更新的计划和策略上重复此循环,直到完成任务
蓝色盾牌表示可能发生安全关键决策的地方,因此需要特殊的安全设计。
人类图标表示可能需要明确人机交互监督的检查点,例如个性化系统行为,或解决模糊的目标对齐问题。
五、系统级防御的真正价值:结构化分析与深度防御
有人可能会问:如果系统级防御在某些情况下仍然需要LLM和/或人类进行决策,那么它的价值是什么?
NVIDIA团队认为,系统级防御研究的关键价值在于它提供了一种结构化的方式来分析、理解和增强智能体安全。
虽然我们可能需要LLM进行某些安全决策,但我们可以设计系统,使基于LLM的法官不消耗任意环境文本,仅用于范围狭窄的判断。此外,对LLM实施结构化输入明确了模型级防御应针对的目标:它们可以针对特定的结构化输入和受限判断任务进行优化,而不是防御任意字符串。
系统级防御还通过使智能体采取某些行动的原因更加清晰来提高可解释性,并支持集成基于规则的机制来验证和执行安全策略。这样,它们充当了程序化安全执行和基于模型的表达性安全决策之间的桥梁,实现了深度防御。
六、从学术到产业:安全AI智能体的未来之路
这篇论文虽然是一篇立场论文,但它为AI智能体安全领域指明了清晰的研究方向:
-
需要更真实的基准测试:现有基准测试缺乏需要重新规划(和策略更新)才能成功的细致、多步骤用户任务,且只考虑静态攻击载荷
-
系统与模型的协同设计:通过强大的系统级设计,我们只需要模型在结构化输入上对明确定义、狭窄的子任务保持稳健,而不是对任意不受信任输入上的任意任务保持稳健
-
人机交互的不可或缺性:在某些模糊情况下,算法系统设计或通用模型改进无法完全解决问题,人机交互应被视为核心设计考虑
随着AI智能体在越来越高风险的环境中部署并获得更大的自主权,提示注入成为安全可靠采用的主要障碍。NVIDIA团队提出的系统级防御框架,为构建既高效用又安全的AI智能体提供了坚实的理论基础和实践指南。
未来已来,安全先行。在我们将更多任务交给AI智能体之前,确保它们不会被“下毒”,是每个开发者和企业必须面对的首要课题。
你对AI智能体安全有什么看法?你认为系统级防御能否真正解决间接提示注入攻击?欢迎在评论区分享你的观点!