 夜雨聆风
夜雨聆风





你的下一个 AI 助手,可能藏在手机里离线跑 Gemma 4
谷歌发布 Gemma 4 那天,官方博客里有一句话值得被放大打印出来贴在墙上:
“The 2B model offers best-in-class performance for its size and is optimized for on-device use.”
On-device use。设备端运行。翻译得直白一点:在你的手机上跑,不需要联网的那种。
这句话放在一篇充斥着技术参数的公告里并不显眼,但它才是 Gemma 4 身上最有想象空间的那条线索。过去半个月,开发者们已经把 E2B 和 E4B 这两个移动端量化版本塞进了手机,各种实测数据陆续浮出水面。今天我们不聊参数内卷,就聊聊这些实测结果到底说了什么,以及它离你手里的那台手机还有多远。
一、Gemma 4 带来了什么,官方是这么说的
先花一点篇幅,把谷歌官方博客里的核心信息梳理清楚。Gemma 4 这次发布了多个版本,包括面向移动端优化的 E2B 和 E4B 量化版,以及更大规模的 26B 和 31B 版本。
官方给出的关键能力升级有三项:
多模态。Gemma 系列第一次支持视觉输入。以前你拍张照片问 AI 上面写了什么,照片得先上传到服务器。现在不用了,模型就在手机里,图片从摄像头到芯片再到输出答案,全程不需要离开你的设备。
128K 上下文窗口。博客的措辞是”process and reason over extensive information”。大约 200 页 PDF 的量,一次扔进去,它能从头读到尾。
工具调用。“Function calling enables Gemma 4 to interact with external tools and APIs.”AI 不只是聊天,还能伸手操作你手机里的其他工具——设闹钟、写备忘录、查地图,理论上都可以通过一句离线指令完成。
博客还提到,谷歌与MediaPipe合作优化了移动端和 IoT 设备的运行效率,模型在TPU上训练,同时支持NVIDIA H100。开源的权重第一时间登上了 Hugging Face、Ollama、Keras 和 PyTorch。
谷歌官方也公布了一组基准测试数据,把几个版本的底牌亮了出来:
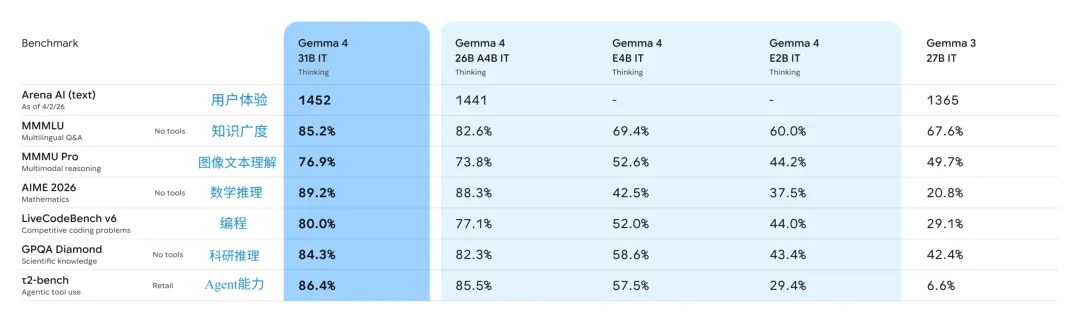
从这张表里能读出几件事:E2B 和 E4B 这两个为移动端准备的量化版本,在多语言问答(MMMLU)上分别拿到 60% 和 69.4% 的分数,与上一代 Gemma 3 的 27B 版本(67.6%)互有高低。但在数学推理(AIME 2026)和科学知识(GPQA Diamond)这类硬核任务上,小尺寸模型和 31B 大哥之间的差距肉眼可见。
这其实很诚实。谷歌没打算让你在手机里跑一个爱因斯坦,它想给你的是一把随身携带的瑞士军刀——不重,但关键时刻能顶上用场。
以上是官方给出的承诺。下面我们看看这些承诺落到手机上,到底兑现了几分。
二、实测来了:Gemma 4 在手机上的真实样子
承载这次实测体验的,是谷歌自己推出的一个 App——AI Edge Gallery。它在 iOS 和 Android 应用商店都能下载,下载之后在 App 内选择 Gemma 4 的 E2B 或 E4B 模型,等模型文件下载完成,就可以关掉 Wi-Fi 和蜂窝数据,开始真正的离线对话了。
先说最直观的体感。
速度:不快,但够用
在搭载骁龙 8 Gen 3 的安卓旗舰机上,E4B 模型的推理速度大约在每秒10 个 token左右。什么概念?一句话三五秒能出完,聊天节奏跟正常打字差不多,不会让你产生“它是不是卡死了”的焦虑。iPhone 15 Pro 上的速度略快一些,社区反馈在18-22 token/秒之间。如果你用的是中端机型,速度会明显下降,但依然能跑。
多模态:能用,而且真的离线
这是 Gemma 4 最让人惊喜的部分。打开 AI Edge Gallery 里的Ask Image功能,对着杂志封面拍一张,它能准确读出标题和主要文字;对着地铁站出口指示图拍一张,它能告诉你应该往哪个方向走。整个过程在飞行模式下完成,照片没有上传到任何地方。
当然,它的图像理解能力还没到云端大模型那种“看懂梗图笑点”的水平。复杂 OCR 会有遗漏,画面细节丰富时偶尔会抓不住重点。但作为一个完全离线运行的小模型,这个表现已经足够让人们对它的实用性产生期待。
短板:轻量不意味着“不占地方”
实测中暴露的第一个问题是内存占用。官方说移动端模型轻量,但 E4B 在 4-bit 量化后依然需要大约5-6GB 的运行内存。这意味着如果你的手机是 8GB RAM 以下的中低端机型,后台多开几个 App 再切回来,模型可能已经被系统杀掉了。根据 AI Edge Gallery 应用在商店页面的说明,安卓设备需运行 Android 12 及以上系统,并建议至少 6GB RAM;iPhone 端则需要 15 Pro 或更新机型。
第二个问题是推理能力。从官方公布的基准测试就能看出,E2B 和 E4B 在数学、编程、科学知识等需要深度推理的任务上,与旗舰版本差距明显。它擅长的是信息提取、格式转换、简单问答,而不是多步推理和复杂计算。你用它是为了离线总结文档、识别图片文字、记录语音转文字,这些它能干。但如果你指望它帮你解一道奥数题,那还是联网用 Gemini 吧。
第三个问题是使用连续性。在 AI Edge Gallery 里,语音转录功能目前只支持 30 秒以内的音频;每次返回主界面或切换应用,模型有概率需要重新加载,那十几秒的等待时间相当消磨耐心。
三、Gemma 4 想做的,不是手机里的“最强模型”
把这些优缺点拼在一起,Gemma 4 的轮廓就清晰了。
它不是来挑战云端大模型的。它不拼写诗,不拼奥数,不拼长程逻辑推理。它拼的是“没网也能用”和“数据不出手机”。
这两件事听起来朴实,但落地到具体场景里,价值是实在的。飞机起飞前最后五分钟,你想查一下落地城市的天气和接机口信息,Gemma 4 能在离线状态下帮你从之前保存的行程单 PDF 里把信息抓出来。深夜写日记,不想把私人情绪喂给云端服务器,开飞行模式对着 Gemma 4 说一段话,它能帮你转成文字并提炼要点。出国旅游没买流量包,对着餐厅菜单拍一张,它能告诉你哪几道菜不含过敏原。
这些场景都不是科幻,是 AI Edge Gallery 里已经能跑通的体验。Gemma 4 的使命不是成为最聪明的那个,而是成为最常在线的那个——在没有信号的地下室、在流量告急的旅途、在一切你不想把数据交出去的时刻,它是那个依然醒着的助手。
四、现在,你可以这样摸到它
如果你读到这里,对“手机里跑一个离线 AI”这件事产生了兴趣,下面三条路径供你选。
零门槛体验:AI Edge Gallery
在 iOS App Store 或 Google Play 搜索“AI Edge Gallery”,下载后进入 Settings 下载 Gemma 4 E2B 或 E4B 模型。下载完成后关闭网络,在 Ask Image 里拍张照片,或者在 AI Chat 里聊几句,感受一下离线 AI 的真实响应速度。
电脑端本地运行:Ollama
终端输入ollama run gemma4:2b,模型会自动下载。关掉 Wi-Fi,和它对话,体验和手机端类似的离线交互。
手机端集成:MediaPipe 示例
关注 Google AI Edge 的官方 GitHub,后续会有更完善的移动端集成示例放出。开发者可以把它嵌入自己的应用,普通用户则需要再等一等,等第一批内嵌 Gemma 4 的 App 上架。
写在最后
Gemma 4 的移动端首秀,算不上完美。它有内存焦虑,有推理短板,有交互上的毛刺。但它在做一件正确的事:把 AI 从云端的笼子里放出来,让它住进你的手机里。
这件事的意义,或许要等到某一天,你在地下三层的停车场里,对着手机问了一句“刚才那个车位号是多少”,而它在断网状态下准确回答了你——那一刻你会突然意识到,AI 已经不是某个需要付费订阅的云端服务了,它变成了手机里一个安静的、随时可用的本地功能。
Gemma 4 在努力让 AI 变成手机的下一代“基础能力”。
参考资料
Google Official Blog:Gemma 4: Bringing developer-first, lightweight models to the community
Google AI Edge Gallery 官方应用实测
Hugging Face 社区gemma-4-2b模型页开发者评测
Arm 官方博客:Accelerating Gemma 4 on Arm CPUs