 夜雨聆风
夜雨聆风





拆完 Claude 46万行源码后,我终于搞懂 AI 是怎么"记住"你的
同样是把记忆”写在纸上”,Anthropic 和 OpenClaw 走了两条完全相反的路。
你有没有这种错觉——跟 AI 聊久了,它好像越来越”懂你”?
上周随口说的口味偏好,今天它还记得;三个月前提过一个项目细节,它居然能翻出来当参考。
Claude Code 的完整源码意外泄露了我一度真的以为 AI 有记忆。直到上个月,——46 万行代码被摊在阳光下,其中就包含了 Anthropic 设计”AI 记忆”的全部秘密。
我花了一周时间把这段代码读完,又顺手翻遍了 OpenClaw 的 memory-core 源码。
结果发现了特别有意思的分野:
同样是让 AI”记住”用户,两家走了两条完全不同的路。
反思派一个是 🧠 :让 AI 自己当图书管理员,靠理解来判断什么该留。
算法派一个是 ⚙️ :把每一次搜索都量化成数据,靠分数和阈值来做决策。
更关键的是,这不仅是”怎么写”记忆的分歧,还是”怎么读”记忆的分歧。
今天这篇,把底层代码拆给你看。
—
📊 先上一张总览图
不想看长文的,先收藏这张图,5 秒钟抓住核心差异:
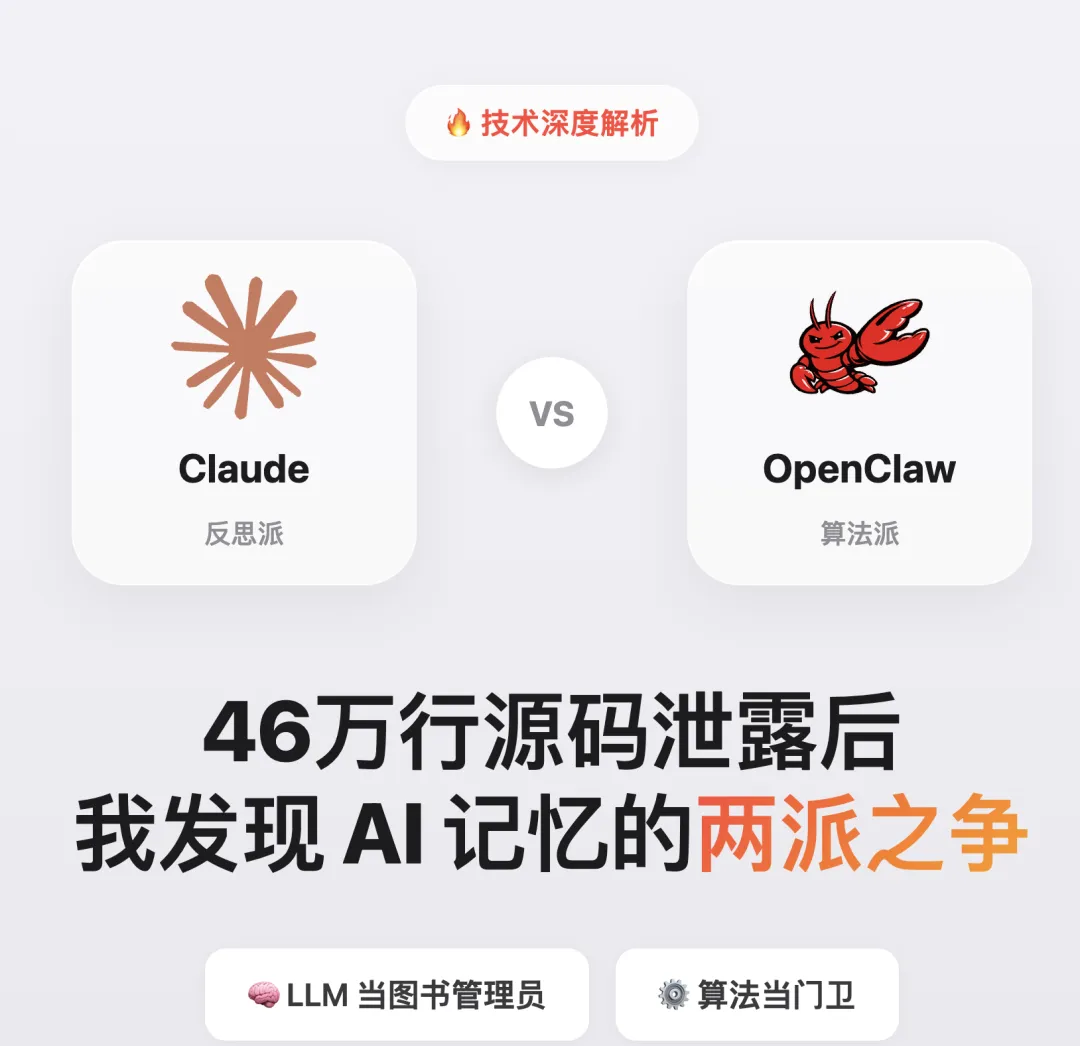
Claude Code💜 :LLM 自己写、自己整理,读的时候像查档案,只挑相关的翻。
OpenClaw🧡 :工具自动追踪搜索行为,算法决定谁能进长期记忆,读的时候像背课文,全文注入 prompt。
好,下面我们一层层拆开。
—
01 先说结论:AI 没有记忆,全是工程外挂
破除一个迷思:
任何说”AI 有记忆”的,都是修辞。
大语言模型本质是”无状态”的。你每次发消息,它都是一次性处理完你给的所有上下文,然后产出回复。模型本身并不”保存”你们的聊天记录。
外挂系统所以所谓的”记忆”,全都是——有人在模型外面搭了一套书架,把对话里的重要信息挑出来,写成文本文件,等下次聊天时再塞回 prompt 里。
Claude Code 和 OpenClaw 在这一点上达成了罕见共识:
所有能被记住的东西,都必须显式地写在磁盘上。没有隐藏状态。
但接下来就是巨大的分歧:
谁来写?什么时候写?什么值得记住?读的时候又怎么读?
让 LLM 自己写、自己整理,读的时候按需加载。Claude Code 的答案:
让工具自动追踪、让算法来晋升,读的时候直接注入全文。OpenClaw 的答案:
—
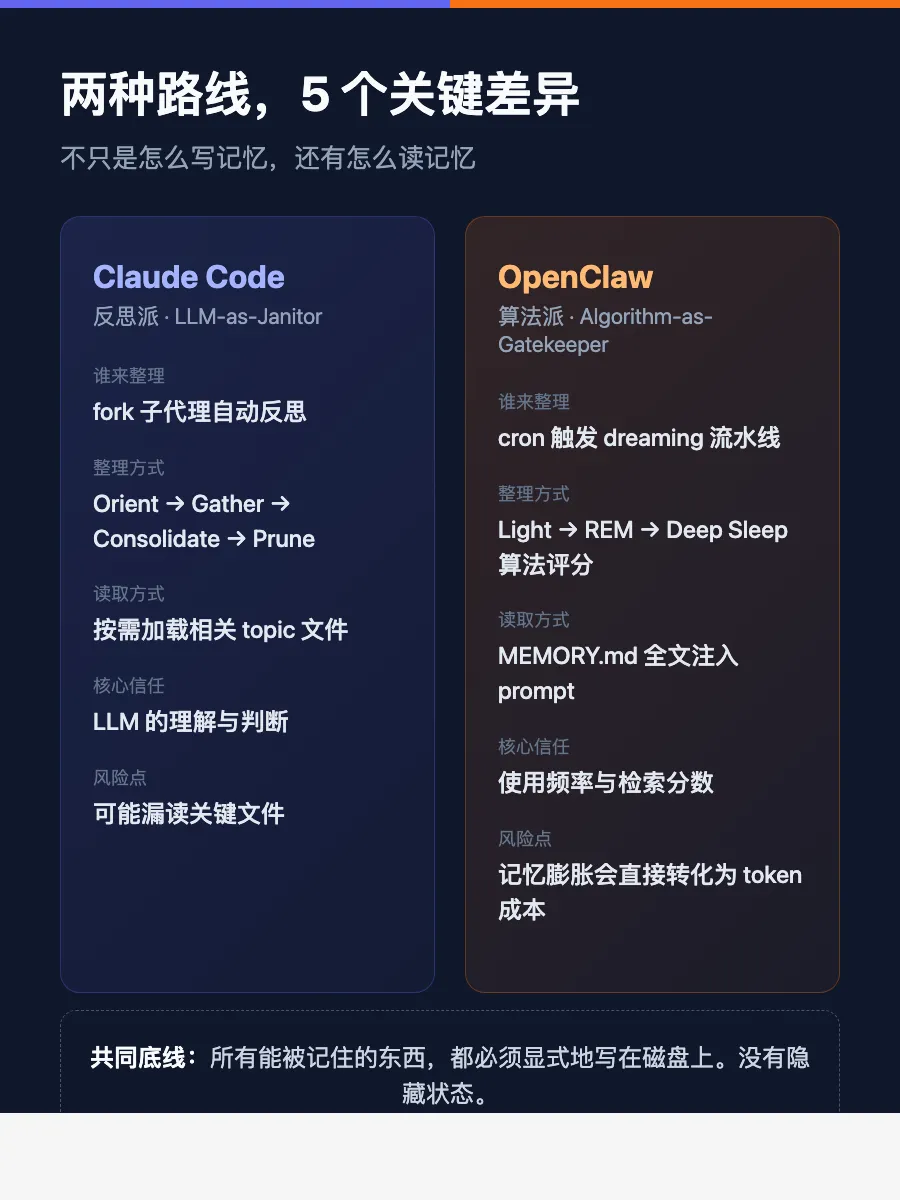
02 Claude Code 路线:fork 子代理 + 四阶段反思
Anthropic 是怎么做的?
📝 记忆写进去:每轮对话后自动触发
Claude Code 有一个后台钩子叫 `extractMemories`。每当你一轮对话结束(模型给出最终回复、不再调用工具)时,它就会悄悄启动。
fork 出一个子代理注意,这里不是主代理自己去写,而是 。
这个子代理是主对话的”完美副本”,能共享父对话的 prompt cache,所以运行成本极低。但它的权限被严格阉割:
·只能读(`Read`、`Grep`、`Glob`)
·Bash 只能跑只读命令(`ls`、`cat`、`grep`)
·只能在 auto-memory 目录内部操作`Edit` / `Write`
如果这一轮主代理自己已经动手写了记忆,后台 fork 就自动跳过,不会重复劳动。这个”互斥”设计很聪明。
预注入 manifest 是另一个提速技巧。子代理启动前,系统会先把已有记忆文件扫描一遍,生成目录清单直接塞进 prompt,省掉一轮 `ls`。
🔄 记忆整理:autoDream,四阶段”反思”流程
写进去只是第一步。记忆多了会变乱,于是有了整理机制 `autoDream`。
触发条件有三道闸:
1.时间闸:距离上次整理超过 24 小时
2.会话闸:这段时间新增了至少 5 个会话
3.锁闸:当前没有别的进程在整理
一旦触发,同样 fork 子代理,prompt 变成完整的四阶段指令:
Phase 1 – Orient(定位)
先 `ls` 记忆目录,读 `MEMORY.md`,快速浏览已有 topic 文件,了解记忆的”地形”。
Phase 2 – Gather(收集信号)
读 daily logs,检索最近会话的 transcript。如果需要特定上下文,就用 `grep` 去 JSONL 记录里找。
Phase 3 – Consolidate(整合)
把新信息合并进现有 topic 文件,避免重复。把”昨天””上周”转成绝对日期。发现旧记忆被证伪了,直接删掉或修正。
Phase 4 – Prune and Index(修剪索引)
维护 `MEMORY.md`。删掉过时指针,把超过 200 字符的冗长索引拆回 topic 文件,添加新指针。
硬性天花板而且 Anthropic 给 `MEMORY.md` 设了:最多 200 行,不超过 25KB。超过就要拆、要删。
LLM 自己当图书管理员整个流程的核心是:。它不是按照死规则跑,而是靠”理解”来决定哪些信息值得合并、哪些文件该删。
📖 记忆读出来:按需加载,像查档案
选择性加载相关的 topic 文件因为 `MEMORY.md` 只是一个轻量目录,真正读取时会根据当前对话上下文,,而不是一次性全塞进去。
好处很明显:
·成本低:不会因为记忆变多而线性涨 token
·干扰少:不相关的旧记忆不会污染当前对话
·灵活度高:LLM 自己决定”这轮该翻哪本书”
风险也在于:如果 LLM 判断失误,可能会漏掉一个看似无关、实则关键的旧记忆。
📁 文件布局:MEMORY.md 是索引,不是正文
“` ~/.claude/projects/<项目名>/memory/ ├── MEMORY.md← 索引(硬限制:200 行 / 25KB) ├── logs/YYYY/MM/…← 日常日志 └──
`MEMORY.md` 是一个超轻量目录,每一行都是指针:
“`
·[Title](file.md) — one-line hook
“`
加载快,不做大文件注入。真正的内容分散在各个 topic 文件里。这样做只有一个目的:
—
03 OpenClaw 路线:工具追踪 + 算法晋升
现在看 OpenClaw 是怎么做的。
📝 记忆写进去:没有自动 fork,但有”搜索追踪”
OpenClaw 不会自动 fork 子代理帮你写记忆。它给你的只有两个工具:
·`memory_search`:语义搜索 MEMORY.md 和 memory/*.md(还支持 `corpus=wiki` 搜索知识库)
·`memory_get`:按路径和行号安全读取片段
主代理显式调用 Write/Edit写记忆主要靠memory flush,或者在上下文压缩前触发提醒——系统会插入一个静默提示,催促 agent 把还没写进文件的重要信息赶紧存下来。
每次调用 `memory_search`,系统都会自动做 short-term recall tracking。但 OpenClaw 有一个非常特殊的机制:
只要你搜索了记忆,被 surface 出来的结果就会被量化记录到一个 JSON 数据库里。记录内容包括:
·query 本身
·结果的路径、行号、snippet、分数
·被召回过多少次(recallCount)
·有多少不同 query 招出过它(queryHashes)
·分别在哪几天被招出过(recallDays)
·自动提取的概念标签(conceptTags)
忠实地记录你的记忆被怎样使用过OpenClaw 不评判你的记忆”好不好”,但它会。
🔄 记忆整理:Dreaming,三阶段晋升流水线
可选插件功能,默认关闭OpenClaw 的 dreaming 是。开启后,系统会注册一个 cron job(默认每天凌晨 3 点),触发”梦境清扫”。
最关键的区别:
OpenClaw 的 dreaming,不是靠 LLM 反思来整理,而是靠算法评分决定谁能进长期记忆。
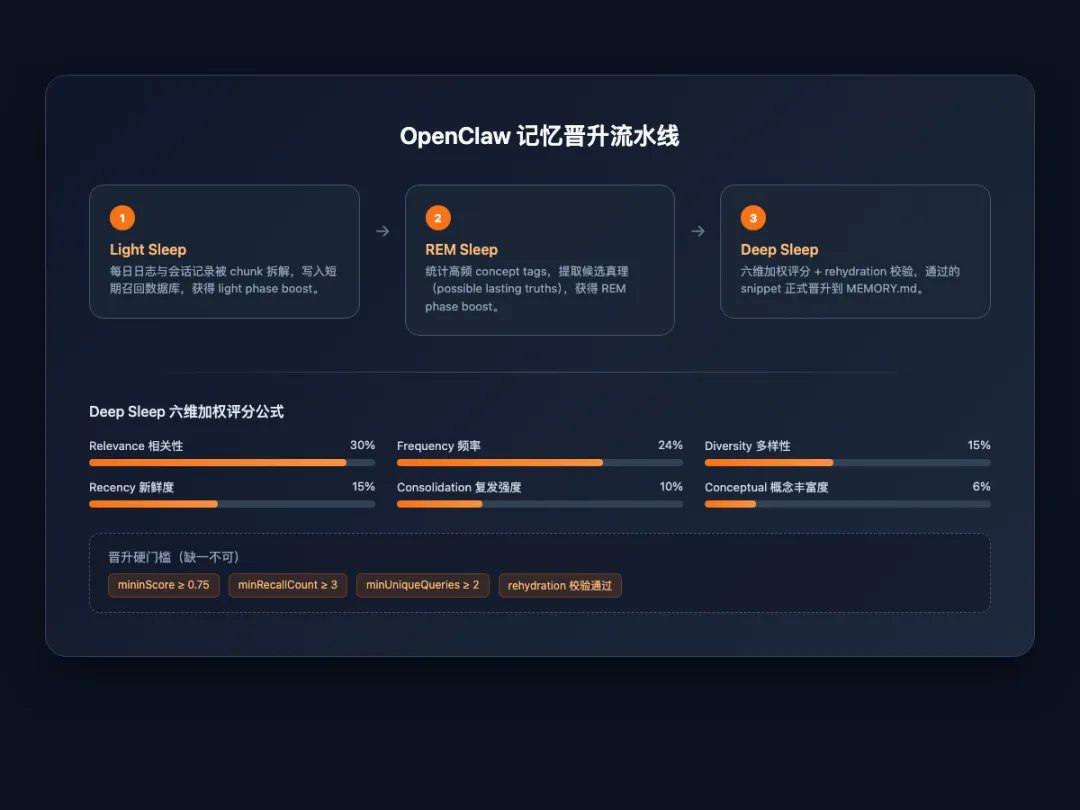
它分为三个阶段:Light Sleep、REM Sleep、Deep Sleep。
Light Sleep
把 `memory/YYYY-MM-DD.md` 和会话 transcript chunk 拆成 snippet,写入短期召回数据库,并打上 light phase signal。
REM Sleep
基于 conceptTags 做主题统计,计算哪些概念反复出现;再按 confidence 公式筛选高价值 snippet,标记为”possible lasting truths”,打上 REM phase signal。
Deep Sleep
六维加权分真正的决策层。每个候选 snippet 会被打一个:
|
信号 |
权重 |
含义 |
|
Frequency |
0.24 |
总信号次数 |
|
Relevance |
0.30 |
平均 retrieval score |
|
Diversity |
0.15 |
独立 query / 覆盖天数 |
|
Recency |
0.15 |
半衰期衰减新鲜度(默认 14 天) |
|
Consolidation |
0.10 |
多天复发的强度 |
|
Conceptual |
0.06 |
概念标签丰富度 |
再加上 light/REM phase signal 的额外 boost(最高约 0.08)。
晋升门槛非常刚硬:
·`minScore >= 0.75`
·`minRecallCount >= 3`
·`minUniqueQueries >= 2`
·可选 `maxAgeDays` 限制
rehydration而且,在真正写入 `MEMORY.md` 前,系统会做一次 :重新从源文件读取 snippet 对应的位置。如果原文已经被删改或找不到了,直接丢弃,防止把过时的东西晋升上去。
通过的候选会被 append 到 `MEMORY.md` 的 `## Promoted From Short-Term Memory` 区块,并标记 `promotedAt`。
🌙 Dream Diary:给人看的装饰品
每个 phase 结束后,如果配置了 subagent,OpenClaw 会调用子代理生成一段人类可读的”梦境日记”,写入 `DREAMS.md`。
不参与下一轮决策但这只是装饰文本——它。真正的决策权永远在 JSON store 和算法公式手里。
📖 记忆读出来:全文注入,像背课文
语义压缩OpenClaw 没有”按需加载”。每次对话开始时,系统会把 `MEMORY.md` 的完整内容直接注入到 system prompt 里。如果太长触发了长度限制,会通过尾部截断或处理,而不是像 Claude Code 那样只挑几本”相关的书”。
特点:
·确定性高:只要写进了 MEMORY.md,下次一定能被看到
·一致性强:不会出现”明明写过但 AI 忘了翻”
·成本上限明确:记忆膨胀会直接转化为 token 成本
📁 文件布局:MEMORY.md 是正文,直接注入
“`
完全相反`MEMORY.md` 的角色和 Claude Code 正文本身:它是,每次会话开头都会被全文塞进 prompt。
—
04 查档案 vs 背课文:两种读取策略
读到这里,两条路线的差异应该很清晰了:

Claude Code = 查档案式💜
`MEMORY.md` 是目录,AI 根据对话主题,只挑相关的 topic 文件读。
优点:成本低、干扰少 风险:可能漏读关键档案
OpenClaw = 背课文式🧡
`MEMORY.md` 是正文,每次对话直接全文注入 prompt。
优点:确定性高、不会漏读 风险:记忆膨胀 = token 成本上涨
你可以把它理解为:一个把记忆力省着用,一个把记忆力敞开了用。
—
05 谁更好?取决于你信任什么
没有标准答案。
Claude Code 更适合你,如果:
·记忆内容结构化程度高,需要频繁合并、去重、修枝
·你相信 LLM 的语义理解能力,愿意让它自己当图书管理员
·希望减少工程复杂度,不想维护 JSON store 和评分公式
·能接受后台 fork LLM 的潜在安全风险(虽然有沙箱)
OpenClaw 更适合你,如果:
·记忆内容非常庞杂,需要一套客观筛子防止 MEMORY.md 变垃圾堆
·你更信任可量化的规则,希望对”什么能进长期记忆”有完全可控的阈值
·需要可审计的决策链路,能向用户解释”为什么 AI 记住了这个”
·系统多 agent、多 workspace,需要跨会话统一调度
·对确定性有强需求,不希望整理过程引入不可预测的 LLM 行为
—
06 3 条可以直接拿走的行动建议

1️⃣ 设计记忆系统前先回答一个问题
你更信任 LLM 的整理能力,还是更信任可量化的评分规则?
想优雅、少维护 → 参考 Claude Code 路线。 想可控、可审计 → 参考 OpenClaw 路线。
2️⃣ 用 OpenClaw 发现 MEMORY.md 越来越冗长?打开 dreaming
把 `dreaming.enabled` 设为 `true`,让算法帮你做”梦境清扫”。高频高分 snippet 自动晋升,同时养成看 `DREAMS.md` 的习惯,观察机器在关注什么主题。
3️⃣ 参考 Claude Code 的 fork agent 模式,务必加沙箱
利用 shared cache 降低成本是必须的,但更要给后台子代理限定 `canUseTool` 沙箱。否则就是把文件系统权限交给了另一个 LLM,风险极高。
—
✍️ 写在最后
控制权和信任AI 记忆的战争,本质上是一场关于的战争。
你相信一个足够聪明的 LLM,能像一个贴心的私人助理一样,把所有文件整理得井井有条吗?
还是你相信只有冰冷的数字、明确的阈值和可追踪的日志,才能在大规模运行时不出乱子?
Claude Code 和 OpenClaw,分别站到了这两个答案的极端。但它们达成了一个底层共识:
再聪明的 AI,也得把记忆老老实实写在纸上。
因为只有这样,你才有机会知道它到底在想什么。