 夜雨聆风
夜雨聆风





从 Claude Code 泄露源码中,我提炼出了 Agent 的 Harness 工程密码
Anthropic 因工程失误意外泄露了 Claude Code 约 60%~70% 的源码。我花了两周开发了一个名为 ebook-from-source 的 skill ,从中提炼出 Agent Harness 工程设计的核心原则,并指导 AI 写了一本书——《从 Claude Code 源码提炼的 Harness 工程模式》。
这本书使用 mdbook 构建,O’Reilly 动物书风格封面并加版画风格插画,8 篇 16 章,共 160 页。(私信公众号输入“harness”可下载全书)

本文告诉你:我如何用 Harness 工程方法控制 AI 写书,为什么 Harness 工程比模型本身更重要,以及你能从中学到什么。
一场意外泄露,打开了一个黑盒
2026 年 4 月,Anthropic 官方 npm 包里意外留下了一个 60MB 的未压缩调试文件。约 2000 个源文件、约 51 万行 TypeScript 代码——Claude Code v2.1.88 的完整核心逻辑、系统提示词、工具定义,全部暴露在阳光下。
事件持续了大约 24 小时。被发现后立刻下架,但代码已经在 GitHub 社区广泛传播。
讽刺吗?一个以 AI 安全为使命的公司,因为工程失误泄露了自己的核心代码。但比讽刺更有意思的是一个发现:Claude Code 的竞争力不在”魔法 AI”,而在工程架构。
源码揭示了一个比例:Claude Code 的成功密码是60% 模型能力 + 40% 精密工程。那 60% 来自 Claude 模型本身,任何人花 API 费用就能获得。而那 40%——提示词分层缓存、5 种上下文压缩策略、四层权限护栏、Feature Flag 驱动的自我精简才是真正的工程密码。
那 40% 是可以学习、复制、迁移的。
这就是我写这本书的原因。

什么是 Harness 工程?
先打个比方。
你有一匹千里马。它跑得快,聪明,能识别路况。但如果你直接把它放到旷野里说”去送信”,它可能跑去吃草了,可能跑到一半迷路了,可能被路边的野花吸引忘了任务。
你需要马具,缰绳控制方向,马鞍固定骑手,马蹄铁保护脚掌,笼头约束行为。有了这些,千里马才能稳定、安全地完成任务。

Harness(马具)就是围绕 AI 模型搭建的运行框架。它包括:
- 提示词结构:怎么告诉模型”你是谁、你能做什么”
- 工具配置:模型能用哪些工具、每个工具有什么限制
- 上下文管理:对话太长时怎么压缩、保留什么、丢弃什么
- 权限护栏:哪些操作需要用户确认、哪些可以自动执行
- 多智能体协作:任务太复杂时怎么分派给多个 AI 协作完成
- 反馈循环:模型输出不对时怎么纠正、怎么防止重复犯错
裸调 API 只有 10 行代码,Claude Code 有 51 万行。多出来的那些,就是 Harness。
这不是纸上谈兵。过去一年,Anthropic 用三智能体架构(规划器 + 生成器 + 评估器)在 6 小时内构建出复古游戏制作器;OpenAI 用 Codex 在 5 个月写出 100 万行代码。路径不同,但规律一致:
一个伟大的模型配一个糟糕的 Harness = 糟糕的体验。一个好的模型配一个伟大的 Harness = 极致的体验。
怎么从源码中提炼工程模式?
我不逐行读代码,而是从源码中识别核心子系统,对每个子系统回答七个问题:解决什么问题、核心数据结构、控制流、并发模型、状态存储、错误处理、精巧设计。每个子系统收束为一条可迁移的工程原则。
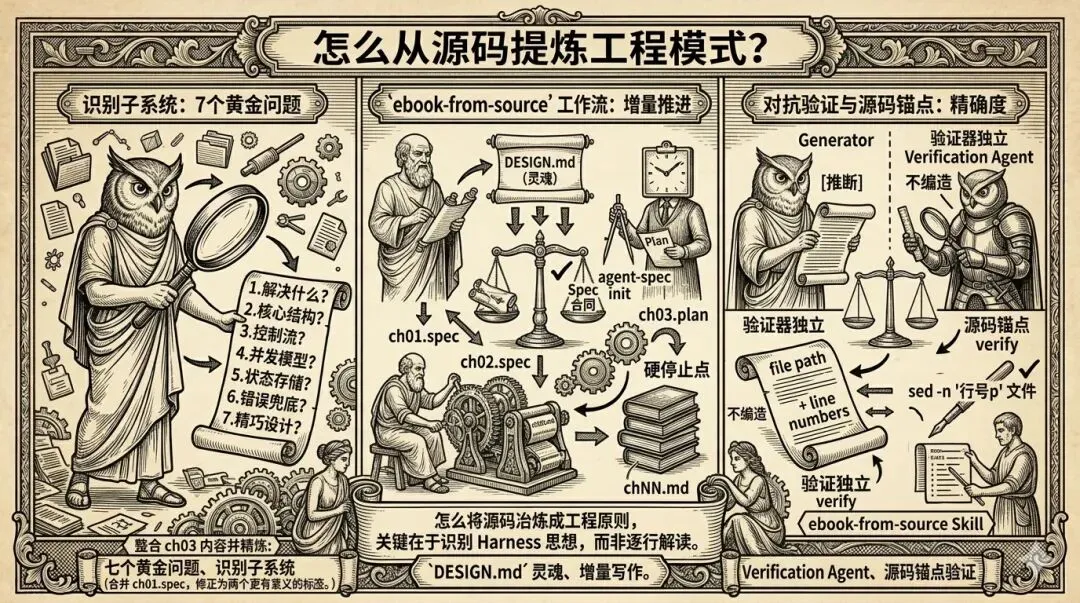
驱动整个写作流程的是一个名为ebook-from-source的 Skill,它背后的 Harness 工程实践体现了五大核心模式。
任务分解 + 增量推进。直接让 AI”写一本书”,它会一口气冲刺到上下文爆掉然后草草收尾。解法是拆成 7 个阶段:环境准备→聊出 DESIGN.md→写章节 Spec→估算排序→制定写作 Plan→AI 正式写作→总检构建。每个阶段硬停止,必须输出产物、等待确认后才能继续。
生成器 + 评估器分离。AI 自我评估总给好评,这是系统性偏差。解法是把生成和评估拆给两个独立 Agent:阶段 A 用外部 CLI 工具agent-spec按验收标准打分,最多 3 轮;阶段 B 做 7 维度自检,每维度 0-10 分,≥8 分通过。验证者没有写文件权限,只能审查不能”顺手改改”。
上下文重置。16 章内容装不进一个上下文窗口。方案是每章启动全新 Agent,通过文件交接状态——DESIGN.md 是全局不变量,specs 是章节合同,plans 是路线图,已完成章节是增量产物。Agent 从文件读取而非依赖对话记忆。
源码锚点。写作前每节必须关联源码锚点,并用sed -n确认锚点存在,把”凭记忆写”变成”读源码写”。
仓库即知识库。所有知识编码进仓库,SKILL.md 作为索引按需加载具体参考文件,避免一次性烧掉上下文窗口。
这五大模式要可靠运行,还需要设定几条铁律作为 guardrails:一次只执行一个阶段、每阶段必须等用户确认、不得跳过中间阶段、进入阶段前必须声明、产物必须写入硬盘等。
随着模型改进和功能提升,铁律也会随之减少。
如果你也想从某个开源项目中提炼知识,这套方法都可以直接复用。关键不是工具本身,而是背后的 Harness 设计思想:约束是乘法因子,一旦编码为规则,就在所有地方同时生效。
全书内容与各章导读
全书按系统架构自上而下组织,8 篇 16 章。以下是每章的核心问题和关键洞察。
第一篇:全景
第 1 章:当模型遇见 Harness
这一章是全书的地图。Claude Code 的 51 万行代码不是为了增强模型能力,而是为了管理模型能力的边界。源码揭示了一个三层架构:交互层(CLI 入口、TUI 界面、103 个斜杠命令)→Harness 控制层(9 个子系统:启动、核心循环、提示词管理、工具编排、上下文管理、权限护栏、任务编排、多智能体、辅助系统)→模型层(Anthropic API 流式通信、多提供商支持)。三层之间的依赖方向是单向的,反向不存在直接依赖。
核心洞察:模型能生成 Bash 命令,但 Harness 决定是否允许执行。模型能读任何文件,但 Harness 决定是否需要确认。这就是 Harness 工程的核心问题——什么交给模型,什么交给代码。
第二篇:启动与循环

第 2 章:点火序列
启动不是成本,是投资。Claude Code 在 ~200ms 内并行完成所有 I/O 准备:性能打点、MDM 子进程、Keychain 预获取等,确保模型调用时永远不会等 I/O。
更值得关注的是 89 个 Feature Flag。每一个 Flag 都是对”模型在某方面还不够好”的显式断言。比如KAIROSFlag 控制助手模式——只有当模型能力达到某个阈值时才启用。
核心洞察:Feature Flag 不是功能开关,而是模型能力的计时器。每个 Flag 都在等模型变得足够好的那一天。
第 3 章:永不停歇的循环
Agent 对话不是无状态管道,而是有状态的状态机。QueryEngine用三层守卫防止模型在循环中失控:maxTurns防无限循环、maxBudgetUsd防费用爆炸、blocking_limit防死锁。
核心洞察:守卫的豁免比守卫本身更重要。错误的终止比不终止危害更大——如果你的 Agent 在修 bug 时被强制中断,可能比让它继续更糟。
第 4 章:单轮执行的艺术
每次 API 调用都经过 4 层串行控制流水线:提示词构建 → 自动压缩检查 → 流式工具分区执行 → 后采样 Hooks。最精妙的是StreamingToolExecutor,它实时判断每个工具调用是只读还是写操作,只读的并行执行,写的必须排队。
核心洞察:并发安全性不是一个全局开关,而是逐工具、逐调用的实时决策。想象一个厨房:切菜可以多人同时干,但炒菜只能一个个来。
第三篇:上下文工程

第 5 章:提示词的分层构建
系统提示词不是一整块文本,而是按变化频率分段。静态内容(系统身份、工具列表)在前,可缓存;动态内容(用户记忆、MCP 指令)在后,不缓存。一条分界线SYSTEM_PROMPT_DYNAMIC_BOUNDARY决定了哪些内容可以复用缓存,哪些必须重新发送。
核心洞察:Prompt Cache 不是”能缓存就缓存”,而是按成本结构精确控制缓存边界。多缓存一个字节可能省 0.001 美元,但破坏缓存命中率可能多花 1 美元。
第 6 章:按需加载的智慧
Claude Code 有 50+ 个技能(Skills),但不会全部塞进上下文窗口。它只注入每个技能的元数据摘要(占窗口 1%),模型通过”先发现后执行”的两步调用按需拉取全文。
核心洞察:把上下文管理的决策权从 Harness 转交给模型。Harness 不决定”你需要什么”,只提供目录让模型自己选。就像图书馆不会把所有书堆到你桌上,而是给你一个索引卡片。
第四篇:工具编排

第 7 章:最小工具基座
54 个工具共用一套 7 字段的统一接口,buildTool工厂统一约束所有工具行为。所有安全默认值集中在TOOL_DEFAULTS——工具默认不允许执行,开发者必须显式开启。
核心洞察:Fail-closed 设计——当不确定是否安全时,默认拒绝。就像消防门,平时锁着,只有紧急时才开。如果你误锁了,最多不方便;如果你误开了,可能是灾难。
第 8 章:先规划后执行
Plan Mode 不是通过提示词告诉模型”请先规划”,而是物理撤销写文件权限——模型在规划模式下根本无法写文件,只能读和思考。这不是劝导,是不可绕过的约束。
核心洞察:能用权限编码的约束,绝不用提示词实现。提示词可以被忽略,权限不存在就无法违反。
第五篇:护栏与扩展
第 9 章:渐进式安全
安全不是开/关两个状态,而是 5 个精确档位的连续谱系:从最严格的每次都确认,到最宽松的自动批准所有操作。最精妙的是auto模式,它让 Claude 监督 Claude。4 层纵深防御确保即使 AI 分类器被绕过,硬编码的守卫仍能兜底。
核心洞察:AI 分类器不是安全的全部,而是安全的最外层。真正的安全靠的是”即使 AI 失效也不会出事”的硬编码守卫。就像自动驾驶——AI 负责日常驾驶,但安全带和气囊不依赖 AI。
第 10 章:Harness 的神经末梢
Hooks 系统在 27 个生命周期时机点留了扩展接口。比如你可以写一个 Hook:每次模型执行 Bash 命令前,先发给你的安全审核服务审批。
核心洞察:好的扩展点设计是双向的——外部代码不仅能观察 Harness 在做什么,还能改变 Harness 的决策。如果只能看不能改,Hook 就退化为日志系统。
第六篇:记忆管理
第 11 章:上下文的五把剪刀
Claude Code 并存 5 种压缩策略,听起来冗余,其实每种针对不同的失控场景:
| 压缩策略 | 针对的问题 | 比喻 |
|---|---|---|
| Snip | 删掉可折叠的上下文块 | 扔掉包装纸 |
| Micro | 压缩单个工具的冗长输出 | 做摘要笔记 |
| Collapse | 旧工具结果过期了 | 过期文件归档 |
| AutoCompact | 对话历史全部摘要 | 把一本书缩成一段 |
| Cache Micro | 缓存过期触发微压缩 | 刷新过期的便签 |
核心洞察:按”轻到重”排序执行。轻量级策略释放足够 token 时,重量级的不触发。就像看病——先试食疗,不行吃药,最后才手术。
第 12 章:隔离与交接
当主 Agent 派生子 Agent 时,”清空”与”继承”同时发生。对话历史从空开始(隔离噪音),但 5 个关键参数逐字相同(保持缓存命中)。就像你换了一台新电脑,但浏览器书签和密码都同步过来了。
核心洞察:上下文隔离 ≠ 缓存失效。清空历史时不应该破坏缓存。这要求系统提示词、工具列表等”骨架”必须完全一致——哪怕多一个空格,缓存就全部失效。
第七篇:多智能体

第 13 章:生成器与评估器
模型不能自己验证自己,它有系统性的”合理化偏差”(”代码看起来对”、”大概没问题”、”太耗时了”)。Claude Code 的解法是 GAN 式的生成/验证分离:一个 Agent 写代码,另一个独立的 Agent 审查。
最精妙的是验证者的提示词用 “RECOGNIZE YOUR OWN RATIONALIZATIONS” 直接对抗模型的偷懒借口。而且验证者没有写文件权限,不是”请你不要改文件”,而是”你根本改不了”。
核心洞察:能力隔离优于角色隔离。提示词可以被违反,工具不存在就不可违反。你告诉 AI “请仔细检查”,不如直接把它的笔没收。
第 14 章:并行世界
并行不是单一能力,而是按隔离程度分层的能力:
| 层级 | 隔离程度 | 适用场景 |
|---|---|---|
| in-process | 共享内存 | 低风险的只读任务 |
| tmux | 进程隔离 | 中等风险的后台任务 |
| remote | 网络隔离 | 高风险的不信任代码 |
核心洞察:不是所有并行都需要最大隔离。就像出门——去楼下便利店不需要锁保险箱,去海外旅行才需要。按任务的风险等级匹配隔离级别。
第八篇:演进

第 15 章:脚手架会消失
89 个 Feature Flag 中的每一个都在等待模型变得足够好的那一天。Flag 关闭时,代码不是被注释掉,而是通过编译时死代码消除(DCE)物理消失,连 Flag 名称的字符串都不留。
核心洞察:Harness 的最高目标不是建得更好,而是让自己变得不需要。就像脚手架建楼时必须,楼建成后必须拆。
第 16 章:7 条通用原则
全书归结为 7 条可迁移原则:”什么交给模型,什么交给代码?”
- 能力边界硬编码,行为指导软编码——用工具禁用而非提示词约束
- 补偿措施分层,轻量先行,重量托底——5 种压缩策略按深度排序
- 缓存是约束,不是优化——5 个参数逐字相同才能命中
- 对抗优于自评——验证者的角色是破坏者而非确认者
- 并行按隔离分层——不是所有场景都需要最大隔离
- 每个补偿措施都有拆除计划——补偿是临时的,不是永久的
- 记忆只存不可推导的信息——代码架构可从仓库获得,用户偏好不可推导

这本书对 AI Agent 设计意味着什么
读完这 16 章,我想从一个架构师的视角,谈谈这些原则对 AI Agent 设计的深层意义。

Claude Code 的设计哲学贯穿一个词:fail-closed。默认拒绝,默认不信任,默认最高安全级别。
这和传统软件很不一样。传统软件的默认值通常是”开启”。功能越多越好,权限越宽松越好。但 Agent 不一样,因为模型的行为是不可预测的。你永远不知道模型会不会在某个边缘情况下生成一条rm -rf /的命令。
所以好的 Agent 架构是”悲观”的:先假设最坏情况,再逐步放开。每个权限都需要开发者显式开启,每个工具都从最严格的安全默认值开始。
AI 系统的核心复杂度在”控制”而非”智能”
代码中真正调用 Claude API 的逻辑只有几千行。剩下 99% 都在解决控制问题:什么时候该停止、怎么压缩上下文、如何防止失控、出错后怎么恢复。
这意味着:如果你在构建 Agent 应用,你应该把 80% 的精力花在控制架构上,而不是提示词工程上。一个精巧的提示词换不来一个可靠的状态机;但一个可靠的控制流水线可以让普通的提示词也能稳定工作。
模型在进步,Harness 在缩小
89 个 Feature Flag 是 Anthropic 工程师对”模型当前能力不足”的 89 个具体标注。随着模型变强,这些 Flag 一个个关闭,代码一段段消失。
这对架构师的启示是:设计 Harness 时,要为它的消亡做准备。不要把补偿措施硬编码为永久行为。用 Flag 标记每一个”因为模型不够好而存在”的代码路径,这样当模型进步时,你可以精确地拆除脚手架,而不是维护一个越来越臃肿的系统。
“模型即上下文管理者”是范式转换
传统思路是 Harness 决定给模型看什么。50 个 Skill 全塞进提示词,能用多少算多少。Claude Code 反过来:只给摘要(1% 窗口),让模型自己决定要不要加载全文。
这是一个范式转换:从”Harness 管上下文”到”模型管上下文”。它的前提是模型足够聪明,能判断自己需要什么。当你构建 Agent 时,想想哪些决策可以交给模型——你可能会发现 Harness 可以比想象中更轻。
可迁移的不是代码,是决策框架
这本书不教你复制 Claude Code 的实现,它用的是 TypeScript + Bun + Ink,你可能用 Python + FastAPI。但”什么交给模型,什么交给代码”这个决策框架是通用的。
无论你用什么技术栈,这 7 个问题都值得回答:
- 你的 Agent 的守卫有几层?每层防什么?
- 你的上下文压缩策略有几种?它们按什么顺序执行?
- 你的权限是开/关二选一,还是连续谱系?
- 你的验证者是同一个模型还是独立的?
- 你的 Feature Flag 有几个?它们在等什么?
- 你的 Hook 扩展点是双向的吗?
- 你的记忆系统存的是”不可推导的信息”吗?
回答了这 7 个问题,你的 Harness 设计就有了骨架。
我的 AI 应用需要什么控制架构
我写这本书的目的,不是让你去复制 Claude Code。
我想做的是提供一套思维工具。当你面对”我的 AI 应用需要什么控制架构”这个问题时,有一套可参考的决策框架,而不是凭直觉拼凑。
这 51 万行代码中最有价值的东西,不是某个具体的算法或技巧,而是 Anthropic 工程师在面对”模型能做什么、不能做什么”这个不确定性时,做出的每一个具体决策。这些决策藏在源码的每一个默认值、每一个 Flag、每一个分界线里。
Harness 是模型能力的历史快照。89 个 Feature Flag 都在等模型变得足够好的那一天。你的 Harness 也应该如此。
参考资料:
Claude Code’s Entire Source Code Got Leaked via a Sourcemap
https://github.com/yasasbanukaofficial/claude-code
Harness design for long-running application development — Anthropic Engineering
https://www.anthropic.com/
engineering/harness-design-long-running-apps
Effective harnesses for long-running agents — Anthropic Engineering
https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
My AI Adoption Journey — Mitchell Hashimoto
https://mitchellh.com/writing/my-ai-adoption-journey*
I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed. — Can Bölük
https://blog.can.ac/2026/02/12/the-harness-problem/
延伸阅读:
10分钟读懂陌生源码:用 Claude & OpenClaw Skill实现项目架构分析工作流
一文读懂大热的 Harness 工程:同样的模型和代码,换个“架子”成功率倍增
私信公众号输入“harness”下载全书。
#Anthropic #ClaudeCode #源码分析 #AI #Agent #Harness #控制架构 #软件工程 #LLM #智能体