 夜雨聆风
夜雨聆风





文档抽取系统:融合OCR与大模型语义理解能力,为合同管理场景下的结构化数据生成提供了一种可配置、低样本依赖的技术方案

-
微调(Fine-tuning)方式:在预训练LLM基础上,使用少量标注的合同数据(每份合同标注若干字段键值对)进行参数高效微调(LoRA、QLoRA)。微调后模型能够学习到“合同编号”、“签约日期”、“总金额”等字段在上下文中的表达模式。
-
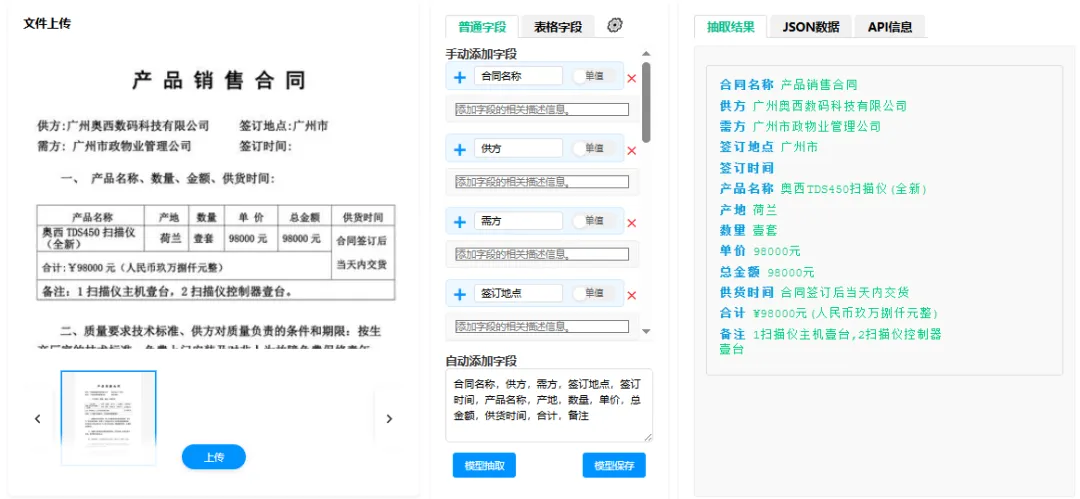
字段定义输入:用户通过界面指定要抽取的字段名称及自然语言描述(如“乙方开户银行:合同中的乙方收款银行账户所属银行名称”)。 -
样本标注:用户上传2-5份典型合同,并在可视化界面上框选或点选每个字段对应的文本位置。系统将位置坐标与OCR结果中的文本行关联,生成正例。 -
特征学习:系统利用标注样本提取字段周围的文本模式、关键词触发词、相对位置等特征。对于LLM方法,标注样本会被构造为few-shot示例嵌入提示;对于检索增强方法,系统可能构建字段相关的语义索引,以便在新文档中检索最相似的文本段。 -
抽取泛化:配置完成后,系统对未标注的批量合同执行自动化抽取,返回结构化JSON数据。
-
企业法务或采购部门需要从大量合同中提取“合同双方”、“签订日期”、“有效期”、“合同金额”、“付款条款”等核心字段,用于建立合同台账或触发后续业务流程(如付款审批、到期提醒)。文档抽取系统能够处理不同格式的合同——无论是标准采购订单还是松散格式的合作协议——统一输出结构化记录。
-
许多企业拥有存量纸质合同档案。通过批量扫描并应用抽取系统,可将历史合同转化为可检索、可分析的结构化数据库。在此基础上,合规部门可以设置规则(如金额超过阈值必须附有授权签字),系统自动抽取出关键字段后与规则进行比对,输出异常项供人工复核。
-
在并购尽职调查或审计场景中,可能需要同时审查主合同、补充协议、验收单等多份关联文档。抽取系统可以从各类文档中提取“项目名称”、“合同编号”、“变更金额”等关联键,通过实体链接技术建立文档间的对应关系,进而识别条款不一致、金额不匹配等风险。
-
跨国企业经常面对中英文或多语言合同。当LLM本身具备多语言理解能力时(如GPT系列、Claude、Qwen),文档抽取系统可直接抽取不同语言合同中的字段,无需单独训练语言模型。OCR层面需选择支持对应语言字库的识别引擎。