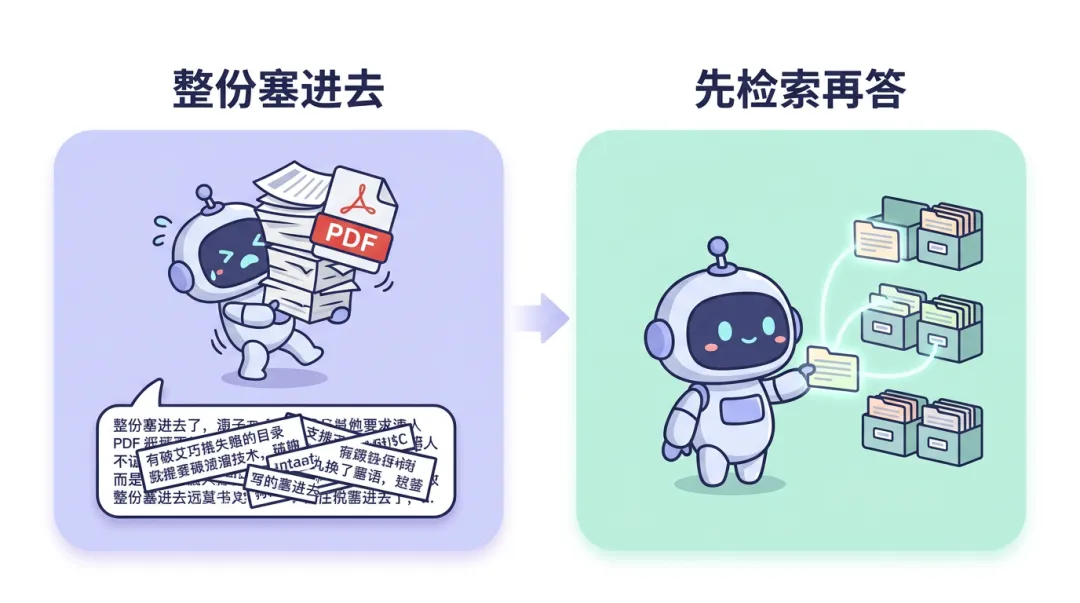
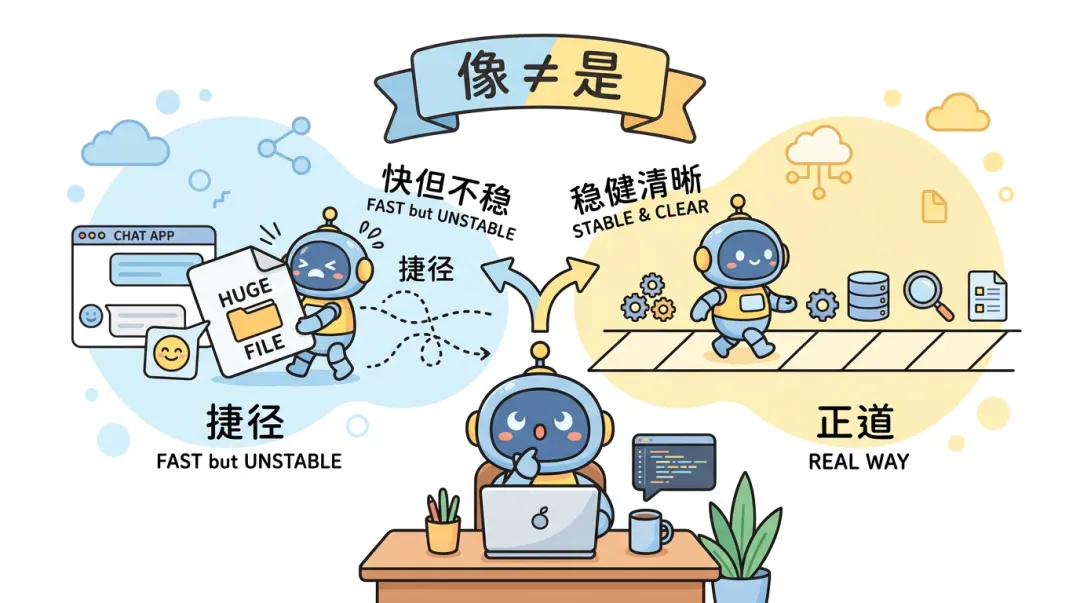
把文档丢给模型,并不等于做了 RAG,我觉得这个误会太常见了有一次聊天,对方说,他们公司「已经上 RAG 了」。我问了一句:具体怎么上的?他说:就是把产品手册 PDF 丢进对话框,让模型照着答。我当时没反驳。但我心里其实很清楚:如果只是把整份 PDF 一次性塞进当前对话里,这通常还不算工程里常说的那种 RAG。“如果只是把整份 PDF 一次性喂进当前对话里,这通常不算典型意义上的 RAG;如果只是把整份文档直接塞进当前上下文里,那更像长上下文注入,而不是典型 RAG。真正的 RAG,更关键的是系统会不会在回答前先检索,再生成。”这种方式,更像是一次性把资料塞给模型。有用,也能work。但它和「RAG」这个词背后那套东西,不是一回事。
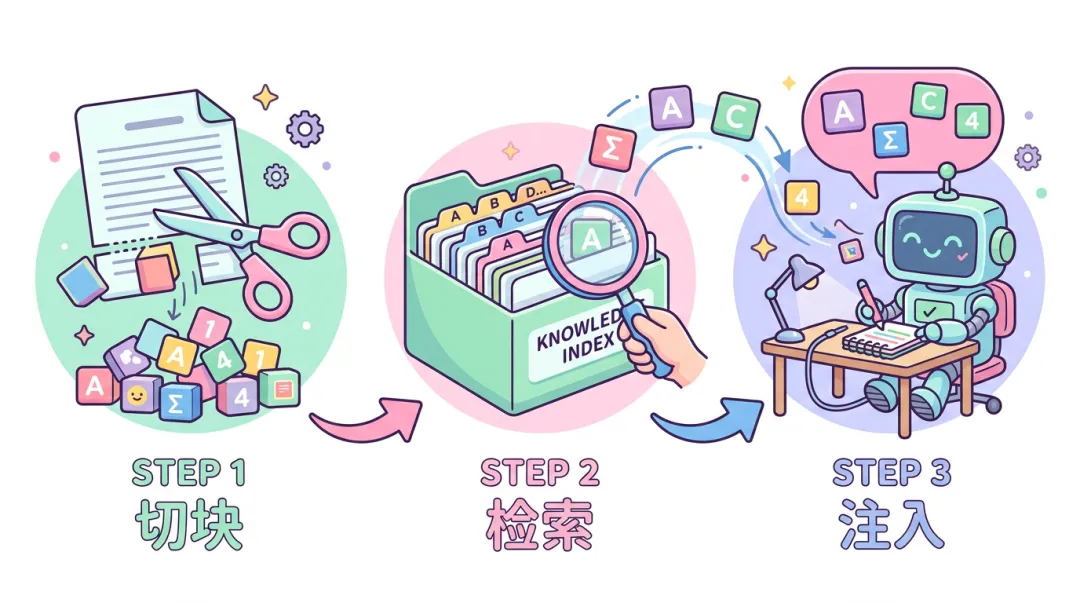
它不是「模型突然变聪明了」,也不是「模型把整本书都背下来了」。它更像:给模型一个「可以回头翻的抽屉」。每次回答前,先从抽屉里抽出几页最相关的纸,再动笔。如果你只是把整份 PDF 一次性贴进对话里,那确实也「增强」了上下文。但那往往是一次性的、手动的、不可复用的流程。和工程里常说的 RAG,还差着好几步。
 夜雨聆风
夜雨聆风