本文是生成式人工智能合集的第八篇,我们来深入OpenClaw架构内部对其进行深度剖析,通过这个过程记录下我看到学到了什么,同样看看对于你是不是也有启发?
人工智能世界的发展实在是太快,各种新的概念层出不穷,很多东西来的快去的也快,同样可以预见OpenClaw的热度也会消退。近两个月,在经历了全民养虾以及大厂跟进部署的热潮,慢慢对其谈论的声音也小了很多。
很多人会将AI浪潮中影响意义深远的时刻定义为Moment。比如在2022年10月我们经历了ChatGPT Moment,在2025年1月经历了DeepSeek Moment,同样在2026年初随着OpenClaw的爆火,大家将其定义为OpenClaw Moment,下面我们就开始深入其内部来剖析下OpenClaw这只龙虾。
The AI that actually does things.
Clears your inbox, sends emails, manages your calendar, checks you in for flights.
All from WhatsApp, Telegram, or any chat app you already use.
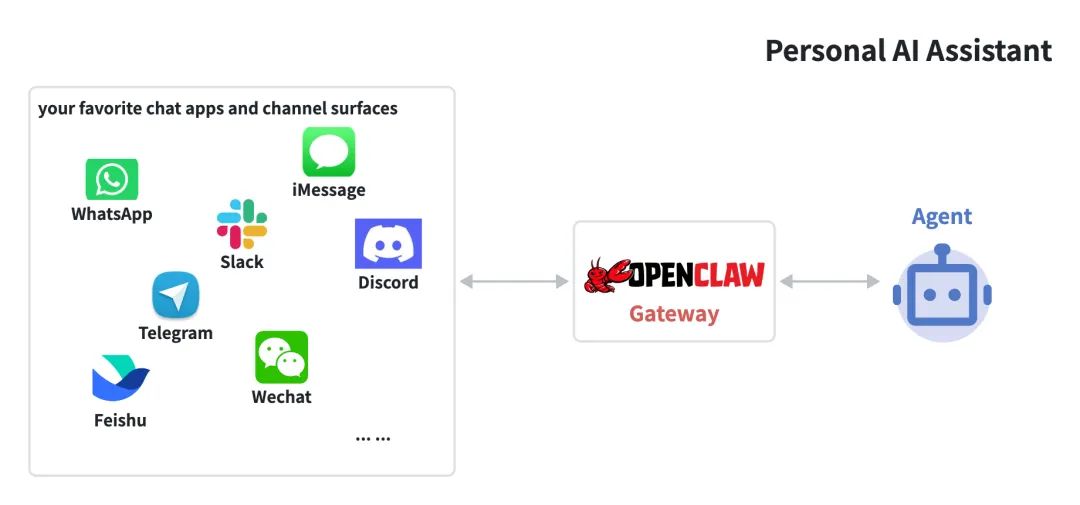
OpenClaw is a self-hosted gateway that connects your favorite chat apps and channel surfaces — built-in channels plus bundled or external channel plugins such as Discord, Google Chat, iMessage, Matrix, Microsoft Teams, Signal, Slack, Telegram, WhatsApp, Zalo, and more — to AI coding agents like Pi.
You run a single Gateway process on your own machine (or a server), and it becomes the bridge between your messaging apps and an always-available AI assistant.
官方的定义很直白,我们可以猜测出最初作者对OpenClaw的定位就是A Pocket AI Assistant。那OpenClaw就是一个本地运行的Gateway网关,通过其可以将你喜爱的聊天工具与Agent进行连接,使其对外提供的能力更像一个持久运行的个人AI助理,如下图所示:
也许这就是作者开发OpenClaw的动机,那OpenClaw真的就是一个Gateway么?随着对OpenClaw的不断深入剖析,可以看到其内部实现已经远远不是一个Self-host Gateway网关概念所能涵盖的,其设计理念更像是一个完备的AgentOS,下面我们一点点来看。
不知道大家有没有注意到官方定义中提到了AI coding agents like Pi,在开始深入OpenClaw之前,下面我们先看看Pi是什么?
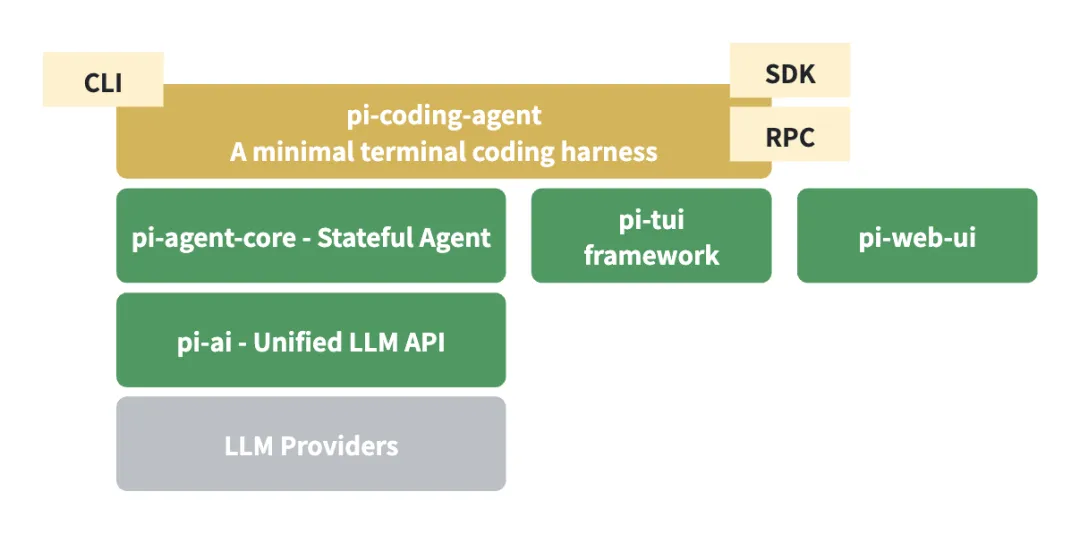
Pi是一个基于Typescript实现的AI Agent框架,包括以下核心packages:pi-ai、pi-agent-core、pi-coding-agent、pi-tui、pi-web-ui。
pi-ai是一个统一的大语言模型API调用库,支持自动发现可用models、配置不同providers、跟踪token使用与成本,并可在会话过程中实现上下文持久化及跨模型的无缝切换。
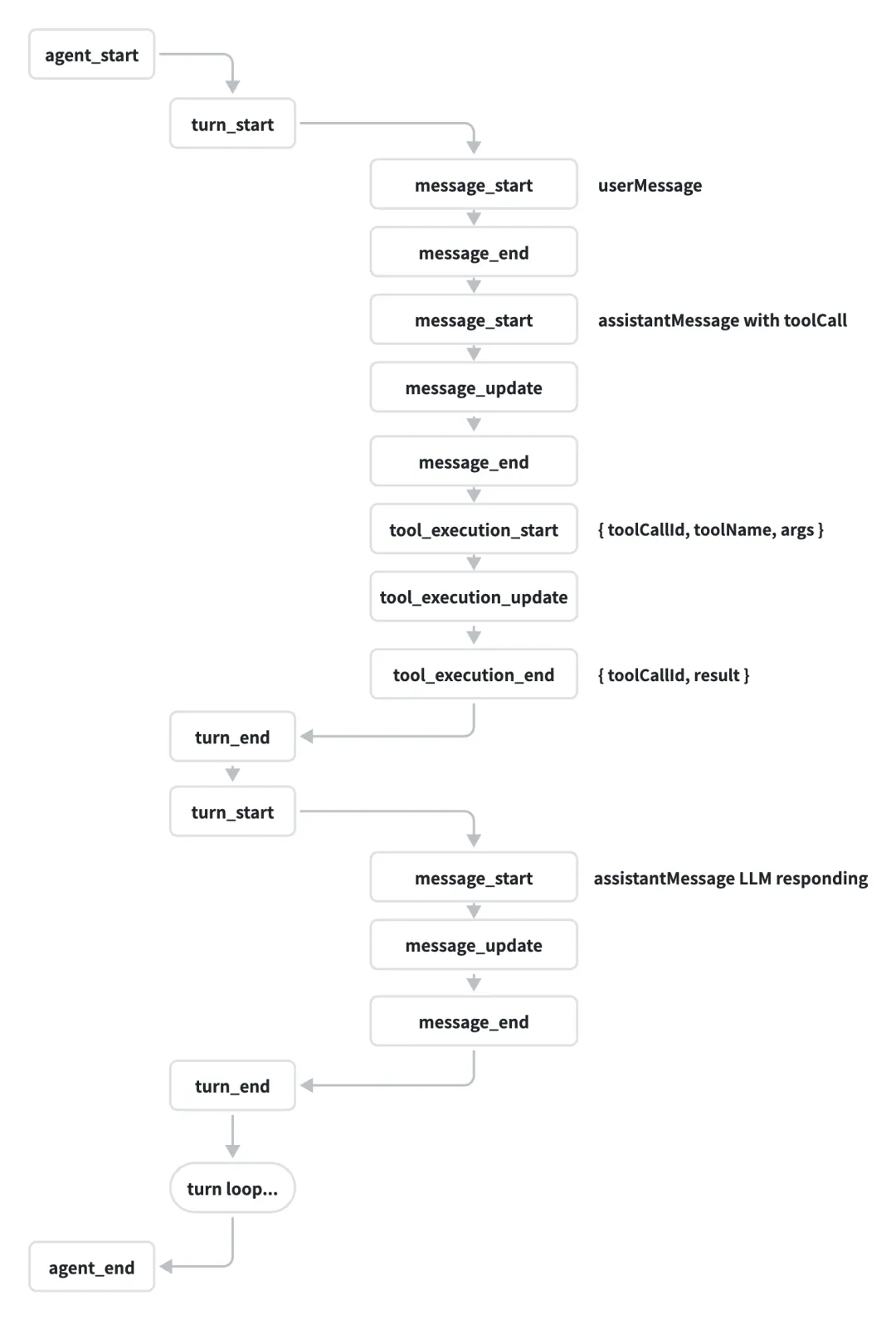
pi-agent-core一个完整的Agent Loop lifecycle定义如下所示:
pi-agent-core实现prompt方法用于消息发送,同时支持steering message和follow-up message,以此允许Agent在任务执行过程中对其进行干预:
-
steering message:用于在工具运行期间对Agent进行中断与干预,具体来说,在工具执行完成后的下一个turn中会立刻填充steering message,以此来中断或干预执行过程;
-
follow-up message:在Agent所有trun运行完成后,开启一个新的turn继续执行follow-up message。
pi-tui是一个轻量级Terminal UI框架,通过差分渲染和输出同步机制,实现无闪烁的交互式命令行CLI应用。基于pi-tui可以快速构建一个类claude code的Agent交互界面。
pi-web-ui是一组可复用的Web UI组件,基于mini-lit Web Components与Tailwind CSS v4实现,可用于构建基于pi-ai和pi-agent-core的AI web聊天界面。
pi-coding-agent是一个基于pi-ai、pi-agent-core、pi-tui实现的极简coding agent框架。
-
本质上其初衷实现的是一个开箱即用的coding agent CLI应用,类似claude code;
-
同时也可以作为一个Agent框架通过SDK或RPC的方式快速集成进其他应用。
所以,OpenClaw底层的Agent Runtime就是基于SDK方式对pi-coding-agent框架进行集成,并在其基础上扩展实现的。
在深入介绍pi-coding-agent之前我们需要先了解下Pi的设计理念。
Pi采用高度可扩展的设计理念,因此不会强制规定你的工作流程。许多其他Agent内置的功能,在Pi中都是非默认实现,但可以通过Extensions、Skills或安装第三方Pi Package来快速实现。这种方式让agent core保持极简,同时又能让你根据自身的场景需求自由定制Pi。
-
不内置MCP,因为实现方式不止一种,且浪费上下文tokens。
-
-
没有权限确认(permission confirm),可通过扩展实现符合你环境和安全需求的自定义确认流程。
-
没有计划模式(plan mode),你可以将计划写入文件,或通过扩展,或安装现成的包实现。
-
没有内置todo list,因为这类机制容易干扰模型,你可通过扩展自行实现。
-
从设计理念可以看出,Pi的设计目标是一个可扩展的极简Agent框架,那作者为什么会这样设计呢?从作者的一篇Blog:What I learned building an opinionated and minimal coding agent 中或许可以看出端倪。
在博客中,作者阐述自己喜欢使用简单轻量的coding agent进行工作。初期的claude code确实符合其工作流程,但是很快CC就变得像一艘宇宙飞船,其中80%的功能是自己平时根本用不上的。同时作者期望在工作中可以自主控制模型的上下文内容,并且为了能够感知模型的行为,期望Agent session可以采用一种人类友好的文档格式进行存储,这样可以方便清晰的查看交互内容并进行后续处理。
所以,当一个老头冲着claude code大吼大叫的时候,他会怎么做呢?(原文原话)
他会自己实现一个coding agent,并且同时会取一个Google搜索不到的名字,这样就永远不会有其他用户了…
(可以说,这个大叔是真的有趣,同时也解释了为什么这个框架叫做Pi [偷笑],可惜这个框架最终还是被有趣的Peter发现了,并集成进了OpenClaw…)
所以,作者的设计理念就是:如果我不需要,就不会支持,而我确实不需要很多东西,你需要请扩展,我可以帮你。
pi-coding-agent默认system prompt定义如下:
That’s it! 唯一还会被注入到system prompt底部的内容就是你的AGENTS.md文件,可用于长期记忆memory。
作者认为,很多事实已经证明所有前沿的大模型都经过了大量RL训练,所以它们天生理解什么是coding agent,所以我们并不需要长达几千甚至上万tokens的system prompt,而且作者在文中证明Pi确实可以工作的很好。
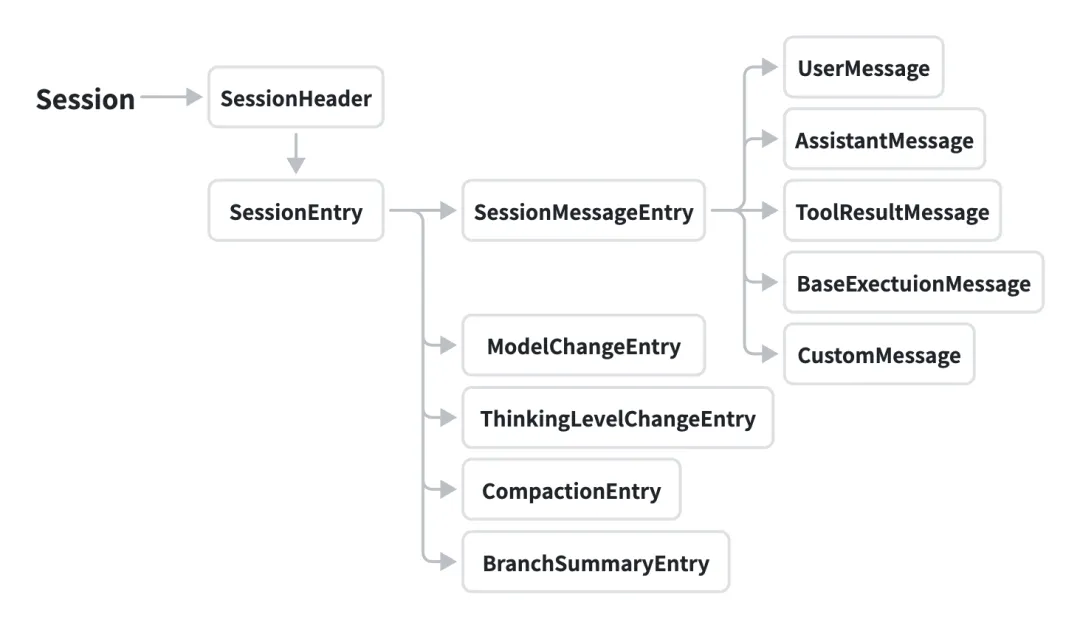
在pi-coding-agent中一个核心设计就是Pi框架对session的管理,如作者的期望,为了方便人类阅读,Pi的session信息都以JSONL(json line)文件的形式进行本地存储。Session文件定义如下图所示:
第一行是session header对象,其中定义了session的metadata信息,这部分不属于session tree,示例如下:
{"type":"session","version":3,"id":"uuid","timestamp":"2025-12-03T14:00:00.000Z","cwd":"/path/to/project"}
从第二行开始的每一行都是一个包含type字段的JSON对象,称为session entry。Session entry通过id和parentId字段连接可形成一个树状结构,这种设计结构可以方便的支持就地分支、压缩等操作而无需创建新的sessioin文件。Session entry具体包括以下类型:
-
SessionMessageEntry:对应conversation history中的每一条message记录;
-
ModelChangeEntry:用于记录session运行过程中的模型切换操作;
-
ThinkingLevelChangeEntry:用于记录session运行过程中的thinking/reasoning level切换操作;
-
CompactionEntry:上下文压缩时创建,用于记录压缩后的上下文summary摘要信息;
-
BranchSummaryEntry:当通过/tree操作进行分支切换时生成,该条目包含由LLM自动生成的摘要,概括左侧分支从当前节点回溯至公共祖先的内容,用于保留被中断路径中的上下文。
{"type":"message","id":"id1","parentId":"id0","timestamp":"2025-12-03T14:00:01.000Z","message":{"role":"user","content":"Hi."}}{"type":"message","id":"id2","parentId":"id1","timestamp":"2025-12-03T14:00:02.000Z","message":{"role":"assistant","content":[{"type":"text","text":"Hi!"}],"provider":"deepseek","model":"deepseek-v3.2","usage":{...},"stopReason":"stop"}}{"type":"message","id":"id3","parentId":"id2","timestamp":"2025-12-03T14:00:03.000Z","message":{"role":"toolResult","toolCallId":"too_call_id","toolName":"bash","content":[{"type":"text","text":"output"}],"isError":false}}
Session存储路径:~/.pi/agent/sessions/–<path>–/<timestamp>_<uuid>.jsonl。
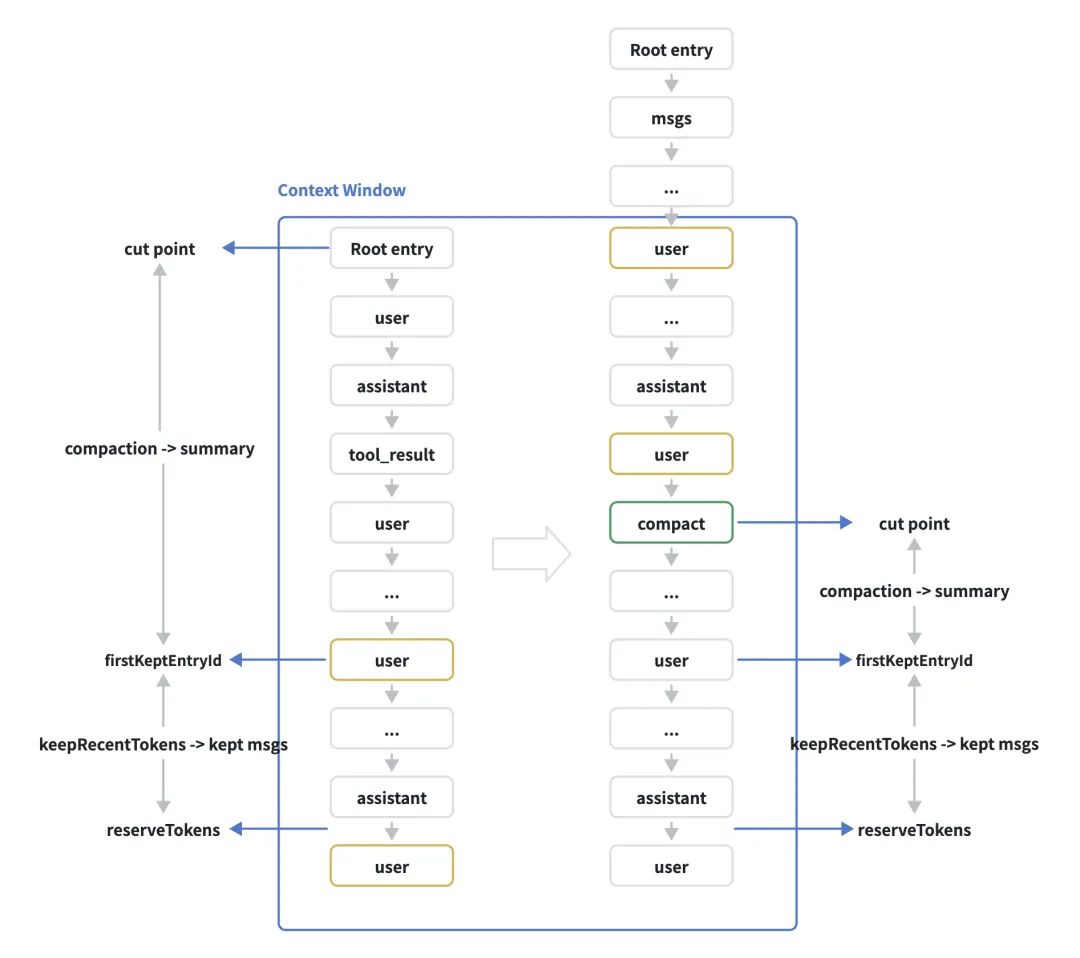
我们都知道大模型的context window有限,当session会话太长时,会塞满上下文窗口,同时也会造成token成本升高、响应延迟变高以及大模型理解能力下降问题。pi-coding-agent会采用summary摘要的方式对session历史进行压缩以此释放context空间。
pi-coding-agent中有两种触发摘要压缩的机制:
-
compaction:当上下文context超过设定阈值时或用户手动执行 /compact操作时触发;
-
branch summarization:当用户执行 /tree 操作进行分支切换时触发。
如上所述,在pi-coding-agent中在以下条件下会自动触发context compacion:
contextTokens > contextWindow – reserveTokens
其中,contextWindow是大模型定义的,不同的provider/model不同,reserveTokens是Pi中的配置项,用于定义context window保留空间大小,默认是16384 tokens。
-
查找fisrtKeptEntryId:从最新消息开始向上遍历,估算累计token数量,直到达到keepRecentTokens(配置定义,默认20k),通常fisrtKeptEntryId会在turn边界,而不会split turns;
-
寻找cut point:从firstKeptEntryId向上遍历,直到前一个保留边界(compaction entry或root entry);
-
生成summary:使用LLM进行结构化摘要生成;
-
追加compact entry:保存包含summary和firstKeptEntryId的compact entry;
-
加载context:重新reload加载上下文context。
{"type":"compaction","id":"id","parentId":"id_parent","timestamp":"2025-12-03T14:10:00.000Z","summary":"User discussed X, Y, Z...","firstKeptEntryId":"idxxx","tokensBefore":50000}
当使用/tree操作进行分支切换时,同样pi-coding-agent会摘要你离开的分支上的工作,并生成Branch Summary entry并添加新分支上,这个过程这里就不再赘述了。
{"type":"branch_summary","id":"id","parentId":"id_parent","timestamp":"2025-12-03T14:15:00.000Z","fromId":"idxxx","summary":"Branch explored approach A..."}
基于以上定义的seesion实现机制,pi-coding-agent在调用大模型前就可以快速的将历史消息信息注入到上下文context中,具体过程如下:
从当前的Leaf entry开始收集其路径上的所有entries;
-
如果是ChangeModelEntry或ChangeThinkingLevelEntry,对provider/model和thinking level进行设置;
-
-
-
然后提取从firstKeptEntryId到CompactionEntry之间的消息;
-
如果是BranchSummaryEntry或CustomMessageEntry,提取并按需转化成LLM Mesage;
Pi可以快速扩展,请根据你的场景构建Extensions,基于Extensions可以订阅lifecycle事件,注册LLM调用的自定义工具、自定义命令,以及自定义交互等。使用方式如下:
关于Pi的内容就介绍这么多。更多内容请参见github:https://github.com/badlogic/pi-mono
总体来说,Pi就是一个底层极简的Agent基础框架,同时设计时提供了高度灵活可扩展的机制,方便上层Agent基于其具体场景和定位按需进行功能扩展。同时作者也在不断阐述其看待Agent的观点:尽可能的精简设计,从而保证Agent的可控、可见性,作者也给出了一个coding agent的最小化设计实现。也许我们可以从这个角度看到,为什么OpenClaw选择了Pi作为Agent构建的起点,从这个角度我们可以将Pi看作是Agent Infra,在其上可以构建适合你自己的的Agent Runtime。
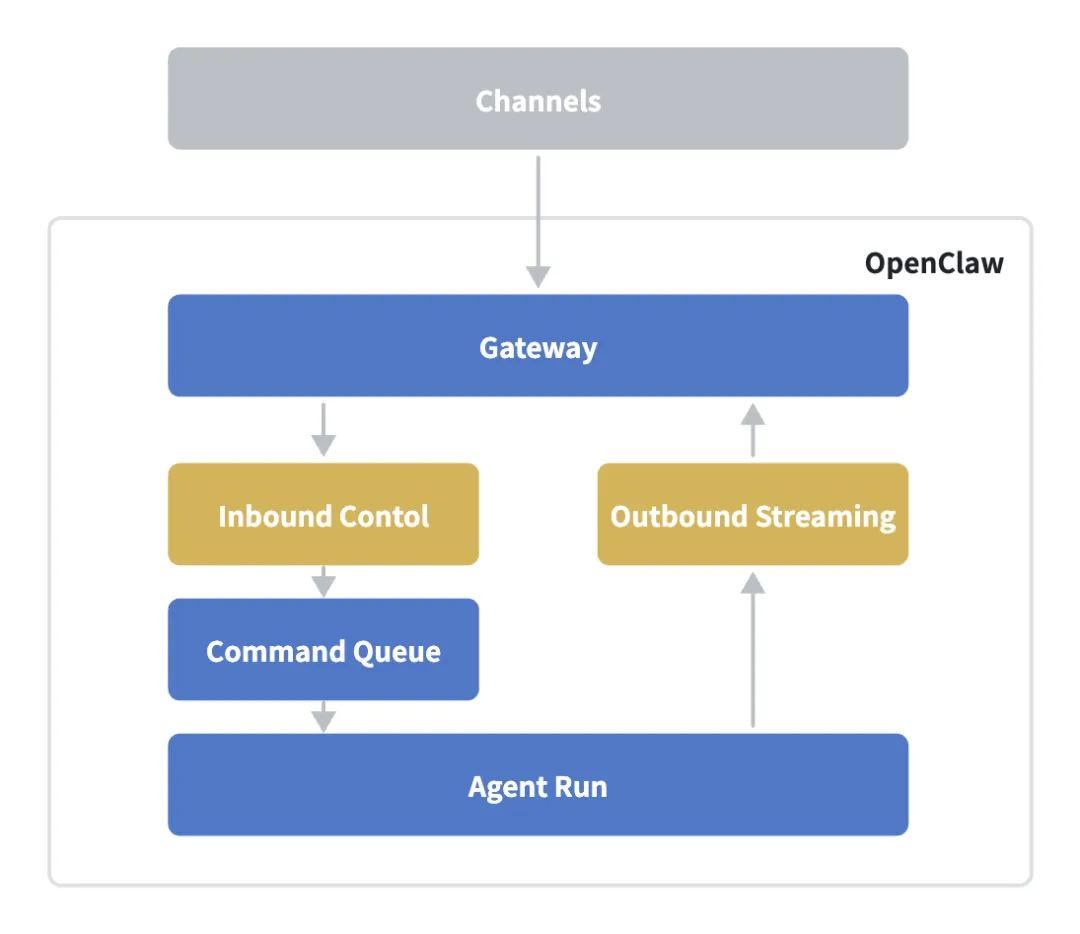
Gateway(网关)作为OpenClaw的统一”通信枢纽”(唯一入口 + 唯一出口 + Control Plane),所有的Client都需要连接到Gateway进行通信。Gateway核心功能包括:
-
管理所有接入Chat Apps或Channel Surface,这类Client统称为Channel;
-
管理所有Control Plane like WebUI、TUI、以及Mac APP,这类Client统称为Operator;
-
管理所有外部物理设备工具 like Phone、Computer or Headless等,这类Client统称为Node;
-
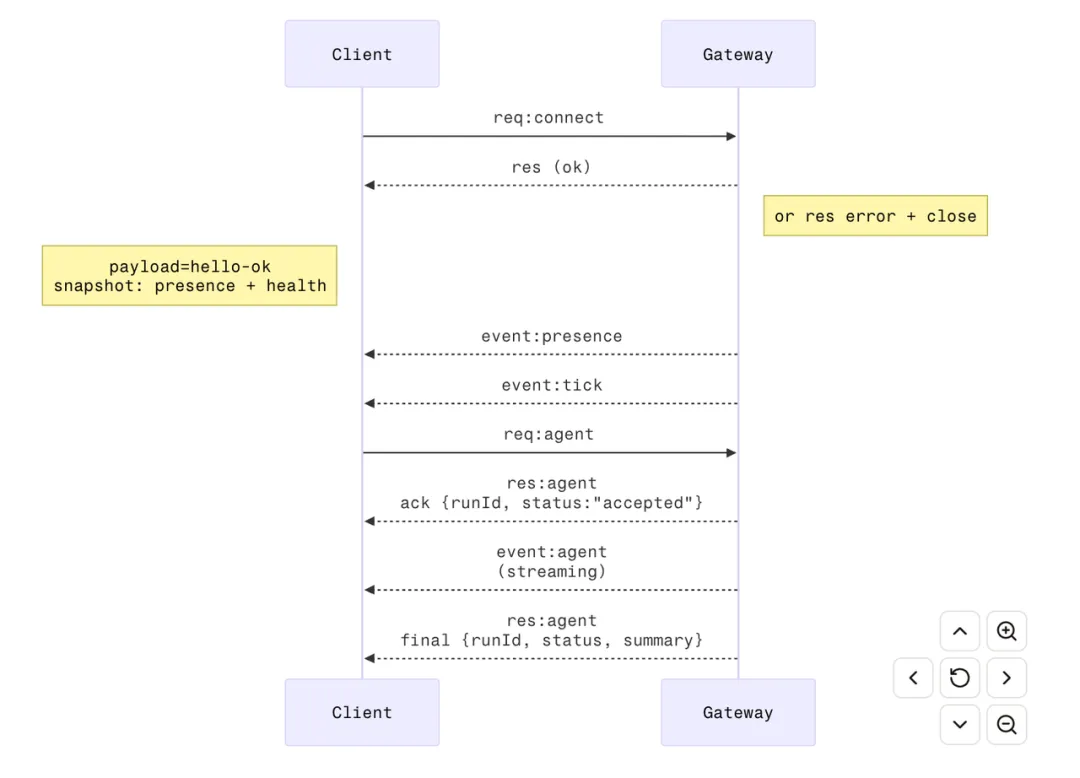
Gateway协议基于WebSocket建立长连接,实现客户端与服务端之间的全双工通信;消息负载采用JSON格式进行序列化传输。其交互过程如下图所示:
{ "type": "req", "id": "...", "method": "...", "params": {} }
{ "type": "res", "id": "...", "ok": true, "payload": {} }
{ "type": "event", "event": "agent", "payload": {} }
除此之外,针对Gateway通信的安全机制设计如下:
-
connect:client交互前必须经过connext建立连接,未建立连接的消息会直接丢弃;
-
auth:支持包括token/password、tailscale、trusted proxy等多种接入认证;
-
pairing:所有client connect后都会生成device identify,新client接入连接需要进行配对审批,Approve通过后颁发device token;
-
nonce:支持防重放和安全绑定,请求的签名必须匹配设备信息。
Agent Runtime指Agent真正执行时依赖的”运行时环境”,包括workspace工作区、session会话管理、context上下文管理、tools工具、skills技能、任务调度等底层机制。解决的问题包括:
-
-
-
Agent Context如何构造?包括system prompt、memory等;
-
-
-
我们可以将Agent Runtime理解为一个以workspace为核心,融合“Session + Context + Tools + Skills”的Agent执行环境。
Agent是OpenClaw系统中的第一等公民,默认系统中只有一个Agent命名为main,其工作目录是:~/.openclaw/workspace,可以通过agents.defaults.workspace字段进行自定义配置;如果在系统存在多个Agent,需要针对每个Agent配置一个独立的workspace。
Workspace是OpenClaw唯一默认的工作目录cwd,默认所有的操作都在这个目录下执行,如文件读写、工具执行等操作,当然没有严格的权限控制,这个只是Agent的逻辑边界,并非安全边界。
我们可以将workspace理解为Agent的工作目录 + 行为配置 + 记忆空间的文件集合,其内部包括如下类型文件:
-
工作输出:Agent执行任务生成内容文件,如代码实现文件等;
-
人格约束:Agent行为定义配置文件,如:SOUL.md、USER.md、AGENTS.md等;
-
记忆空间,Agent长期记忆文件,如MEMORY.md和memory/*.md等;
💡 注意:session对应任务的执行的日志,并不属于特定Agent的记忆,所以其存储并不在workspace中 。
我们可以将workspace理解为Agent的”持久化大脑”,决定了它是谁?记得什么?如何行动?以及做过了什么。作者建议基于git对workspace目录进行管理,这样可以方便对Agent的备份和迁移。
同时OpenClaw提供了sandbox配置,如果开启sandbox,这样每一个session会对应一个单独的workspace,这样可以防止主workspace被污染。
OpenClaw Session Manager基于Pi-coding-agent之上构建,所以其底层会话定义依然是基于人类可读的JSONL文件格式进行存储。针对OpenClaw,其Session Manager需要扩展实现以下功能:
-
各个Channel的消息隶属于哪个Session,如何进行路由?
-
-
-
在OpenClaw中Agent入口定义为外部的channels,在这样的产品形态下Session Manager需要决定每一个channel下的用户发送的消息和session的映射关系,即哪个消息应该路由到哪个session中?
针对私聊direct message(dm),OpenClaw默认全局共享一个session。这意味着所有channel的所有用户,如果连接到同一个Gateway,那么他们的session是混在一起的,意味着大家都能看到彼此的历史任务消息,当然针对本地部署的OpenClaw默认配置是没有问题的。同样针对共享OpenClaw的场景,也提供了多种配置方式:
-
main:默认配置,所有dm共享一个session;
-
-
per-channel-peer:每个channel + 用户一个session,官方推荐配置;
-
per-account-channel-peer:最细粒度。
针对群聊group chat,OpenClaw会为每个群聊维护一个单独的session。
同样针对系统定时cron任务,OpenClaw都会为每一次运行单独创建一个session。
OpenClaw的基于pi-coding-agent构建,其session文件定义同样基于jsonl文件进行本地存储。默认存储路径为:
~/.openclaw/agents/<agentId>/sessions/<sessionId>.jsonl
意味着不同Agent的session是完全隔离的,针对同一个Agent的不同session基于seesionId命名进行隔离。但是sessionId不是很直观,所以我们很难直接看出这是哪个session的存储文件,OpenClaw将session的映射关系的元数据存储在sessions.json文件中。
同时为了防止sessions目录下的session文件无限增长,OpenClaw支持session文件自动清理,通过配置pruneAfter和maxEntries来分别指定session文件保存多久以及最大保存多少条记录。
OpenClaw支持reset操作来对session进行重置,用来防止单个session过大,重置后session历史记录并不会立刻删除,会被重命名为<sessionId>.jsonl.reset.<timestamp>,OpenClaw中实现重置规则为:
-
默认每天凌晨4点会对session进行reset,意味这一个session的声明周期最长是一天;
-
同时可选的通过配置idleMinutes字段,这样session在idleMinutes分钟不活跃后会立刻reset;
-
同样我们可以手动执行/new或/reset操作来重置session。
OpenClaw session compaction同样基于pi-coding-agent之上进行扩展实现。对于session compaction大家应该已经不陌生了,其目的都是当上下文快要塞满的时候,通过对历史session进行摘要总结来释放上下文空间。我们可以将compaction理解为:在不丢失信息的前提下,在有限的context window下无限的执行任务。从这个角度来看,无限的压缩是不可能的,所以Agent需要在适当的时候reset,这也是为什么需要reset的原因。
关于Compaction的实现细节这里不赘述了,大家可以看下pi-coding-agent这部分的介绍,在OpenClaw的扩展设计中增加以下实现关键细节:
-
Compact后自动触发重试,这个过程对用户无感。
-
增加identifier policy对标识符进行特殊处理,避免compact后将关键ID修改或漏掉;
-
在压缩前,需要先做一个隐式操作,将需要长期记住的内容写入memory daily文件,防止重要的信息被summary吃掉,这个过程称为memory flush。
OpenClaw同时还提供了一组跨session操作的工具API,可以让OpenClaw实现跨session上下文的协作,这些API包括:session_list、session_history、session_send、session_spawn、session_status等。如果将session看作操作系统的进程,那么session_send就是IPC进程间的通信,session_spawn更像是fork一个子进程。Session tools让OpenClaw从只能在一个session上下文里执行任务,升级为可以跨session调度任务、创建子任务、进行多agent协作的调度AgentOS。
大家都知道,context可以理解为每次推理时被加载进context window的全部信息总和,是一种高成本、短生命周期的“临时工作记忆”。如果将Agent类比为CPU,那么context可以看作CPU的寄存器(register)或缓存(cache)。
-
-
Conversation History对话历史,也就是session中message信息;
-
Tool Calls + Results工具调用和结果,同样存储在session中;
-
Attachments:图片、音频、文件等多模态信息;
-
Compaction Summaries 上下文压缩后的摘要文本信息;
-
Provider Hidden Wrappers针对特定LLM Provider隐含注入的信息等。
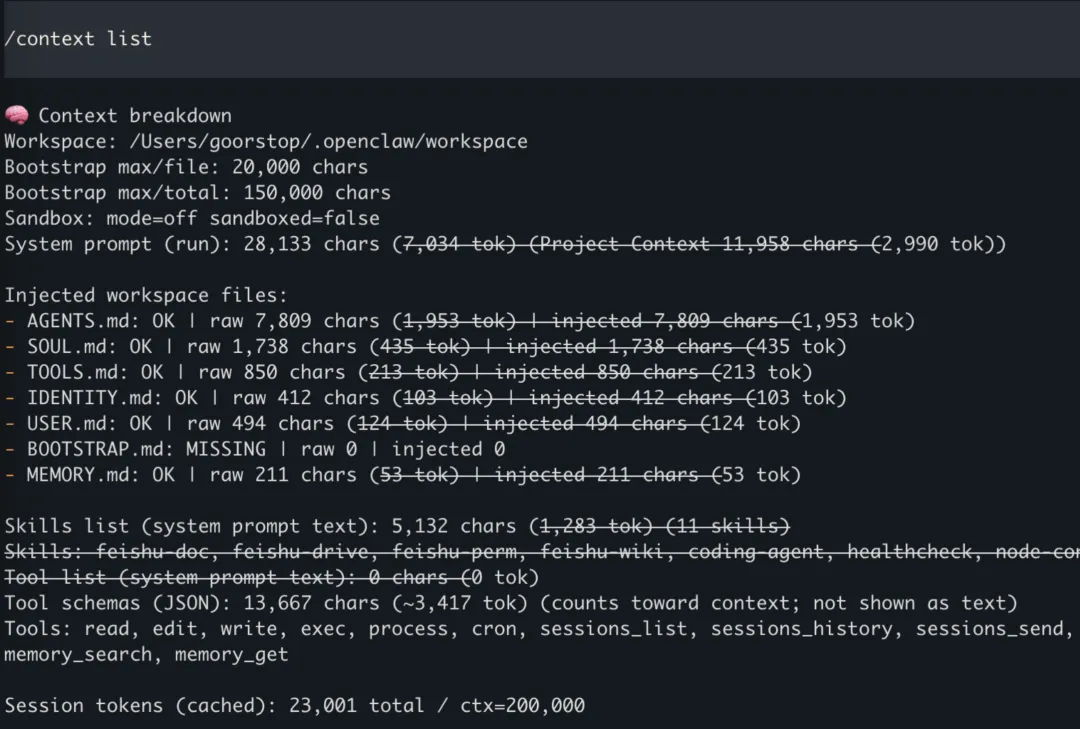
OpenClaw实现会实时跟踪并记录context空间的使用情况,可以通过/status、/context list或/context details等命令对context进行实时查看和分析。一般情况下context token占用最多的是以下信息:
-
Injected workspace files into System Prompt;
-
Conversation history from Session;
-
-
如果memory设计的不合理的话,同样会挤占context空间;
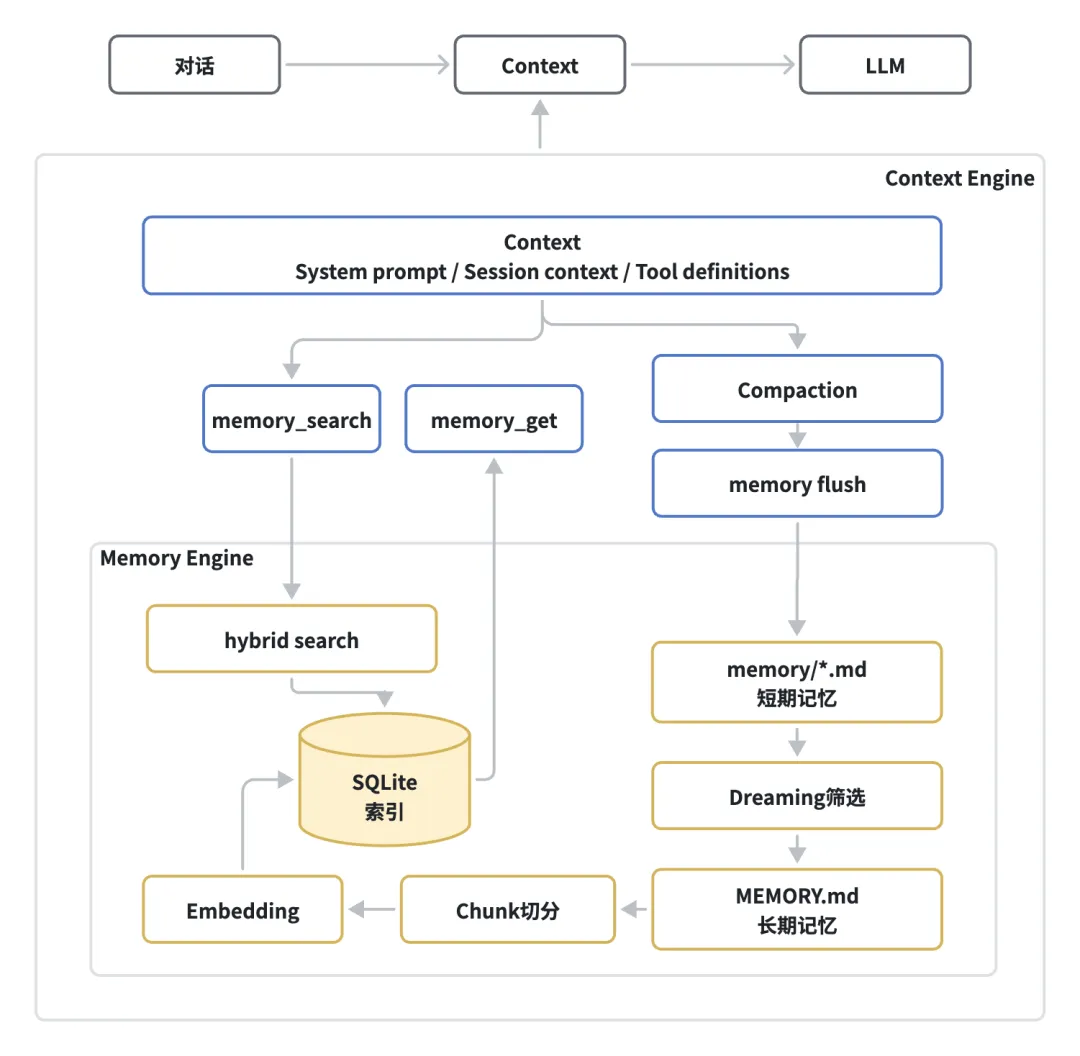
Context engine是OpenClaw真正用来决定每一轮context window到底塞入哪些context内容的调度器。在Agent运行过程中,context engine接口中定义包括以下5个关键阶段:
Bootstrap阶段在session首次启动时,用于初始化context engine引擎。
Ingest阶段在新消息到来添加到session中时,context engine可选的决定该消息是否需要持久化存储和索引。
Assemble阶段在每一轮模型调用前执行,context engine组装并返回全部的context内容,这是context engine必须且核心的实现逻辑。在assemble阶段,除了结构化的构建system prompt,基于rag检索相关记忆以外,还可以跨session以实现multi-agent上下文共享和隔离等高级特性。
Compact阶段当context window塞满时,context engine对session上下文进行压缩,从而释放context空间。可以基于标准的summary摘要实现,同时可替换为更高级的结构化无损压缩策略实现。
AfterTurn阶段在Agent的每一轮执行完成时,context engine可选执行持久化状态、触发后台自动的compaction或者更新记忆索引等操作。
OpenClaw默认提供了一个最基础的context engine实现:Legacy Engine,其内部实现逻辑如下:
-
Ingest:空操作,消息持久化直接由session manager处理;
-
Assemble:直接透传,委托给底层embeddedPiAgent assemble pipeline处理:
-
Compact:同样委托给底层embeddedPiAgent实现处理;
-
同时OpenClaw实现中将context engine抽象成一个可独立替换的模块,在配置中可以通过plugins.slots.contextEngine进行配置自定义实现。除了Legacy Engine以外,官方可选的context engine实现还有lossless-claw以实现无损压缩。同样,如果大家在使用中如果对于Context有特殊的需求,需要使用何时的context engine或自定义实现。
github:https://github.com/martian-engineering/lossless-claw
OpenClaw基于一个动态拼接的结构化定义来生成system prompt,其结构定义如下:
-
Tools:有哪些工具,怎么使用工具,工具执行约束等;
-
-
Memory Recall:在需要时获取memory,使用memory_search/get工具;
-
-
Current Date & Time:时区、日期和时间说明;
-
Safety:安全约束,注意只是软约束(Advisory);
-
CLI Reference:OpenClaw命令执行规范;
-
Document:OpenClaw文档本地存储路径及使用说明;
-
Project Context(editable):
-
AGENTS.md:维护Agent长期记忆和行为规范;
-
SOUL.md:制定Agent的人格/风格/边界;
-
IDENTITY.md:设置Agent的名字/vibe/emoji,即你是谁?
-
-
-
MEMORY.md:长期记忆存储,OpenClaw默认memory engine基于文件构建;
-
HEARTBEAT.md:定义一些简短的定期清单或提醒;
-
BOOTSTRAP.md:首次运行时,如果BOOTSTRAP.md存在,那就是你的出生证明。遵循它,弄清楚你是谁,然后删除它。你不会再需要它了。
-
-
Runtime信息:OS、Node、当前模型、repo路径等;
OpenClaw完整的system prompt定义请参见我的github代码库:https://github.com/goorstop-n/genai-tech-demo。
关于session压缩这部分内容在pi-coding-agent和OpenClaw session时已经介绍过了,这里只是为了结构统一,相关内容就不再赘述了。特别说明,OpenClaw提供ownsCompaction配置参数,context engine可以通过该参数控制要不要使用自定义Compaction实现机制。
在OpenClaw中,context优化实现中一个特殊的机制叫做session pruning剪枝,其主要目的是在不改变context session历史的前提下,对其中的tool result进行临时剪枝删除,注意session历史存储没有改变,这是和session compaction的本质区别。
大家都知道,tool result一般都比较大,同时作者任务,这些工具输出内容属于高噪声+大体积的context污染源,属于中间结果,对于大模型的理解来说意义不大,所以通过剪枝Pruning可以有效的进一步降低context的占用。
-
软裁剪:在pruning过程中保留工具输出的开头和结尾,中间用…替代;
-
硬清理:在pruning过程中将工具输出全部替换为占位符;
除了工具输出以外,OpenClaw同时还会对如图片、音频、视频等内容进行同样的剪枝处理,如将图片内容替换为:[image data removed – already processed by model]占位符。另外在实现中,为了保证上下文context的稳定,OpenClaw默认会保留最近3轮的完整session内容。
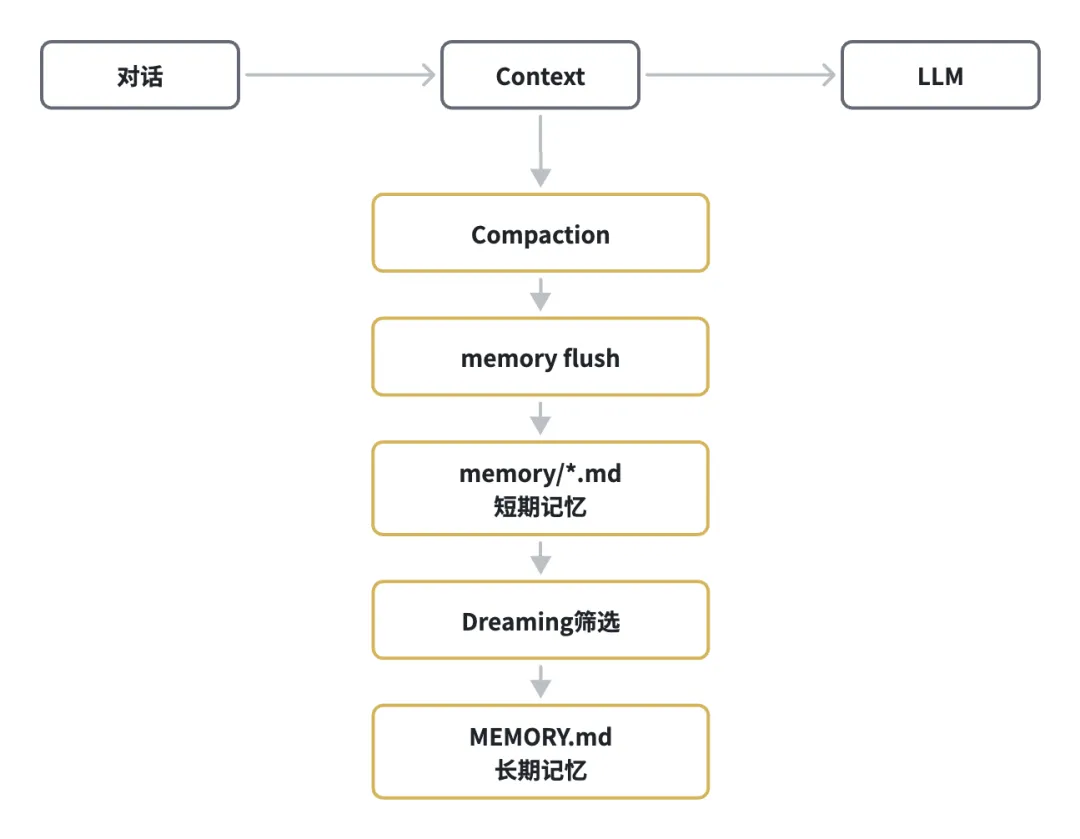
Memory engine记忆系统属于context engine的一部分,下面我们就来看看OpenClaw的记忆系统是如何设计和工作的,以此让agent可以长期记住关键信息而不会遗忘。
我们都知道模型LLM本身没有长期记忆,agent所有知道的东西都在context中,在context engine的执行过程中,需要不断的维护长期记忆long-term memory,并在任务执行时assemble或retrive到context中。
那首先第一个问题是:OpenClaw如何对记忆进行分层,有哪几个类别?
OpenClaw默认memory实现同样基于文件系统,设计将记忆文件拆分为以下三类:
-
短期/日志记忆Memory:用于记录当天发生的重要事情、临时上下文以及观察记录等,写入workspace/memory/YYYY-mm-dd*.md文件进行存储,每天一个文件,默认保留最近两天;
-
长期记忆Memory:用来存储用户偏好、重要决策以及稳定事实等信息,每次session开始时都会加载,存储在workspace/MEMORY.md文件;
-
梦境Dreaming Memory:用来记录自动总结、记忆筛选后的结果,可供人类审核,存储在workspace/DREAMS.md文件中。
OpenClaw Memory如何触发?主要有三种方式:用户触发、自动触发以及Dreaming记忆整理机制。
-
用户触发:比如在会话中用户明确提示:需要记住…等内容,这时Agent会触发写入MEMROY.md;
-
自动触发:一般的,在compaction上下文压缩之前,OpenClaw会自动触发一个隐藏步骤,提醒Agent把重要的信息写入memory文件;
-
Dreaming记忆整理机制:memory不是无脑存储,而是会经过收集、筛选、打分等过程后写入MEMORY.md,这部分会在下一节单独介绍。
OpenClaw memory什么时候读取?怎么加载?
OpenClaw提供两个memory核心工具,用于检索和加载memory,这部分内容会由context engine在system prompt中提供。
-
memory_search:memory检索,支持关键词匹配和语义理解;
-
memory_get:精确的读取某个memory文件或片段;
OpenClaw Memory engine实现同样基于插件体系,支持快速配置插件进行扩展。memory engine可选的实现有:
-
Built-in:默认实现,基于SQLite + Embedding本地检索系统;
-
QMD:本地增强检索系统,https://github.com/tobi/qmd
-
Honcho:基于用户建模的跨session记忆服务,https://github.com/plastic-labs/honcho
Memory engine的大致运行流程如下图所示:
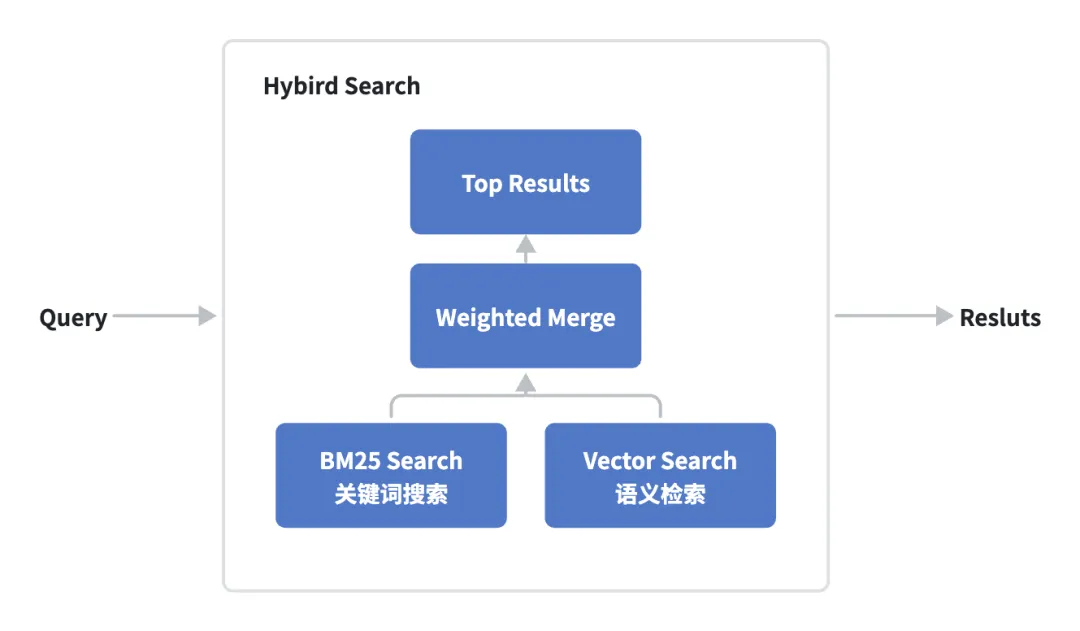
OpenClaw默认memory engine可以理解为基于SQLite构建的支持关键词/语义检索的轻量级混合检索系统,其底层基于记忆文件之上进行索引构建,每一个Agent对应一个SQLite数据库,数据库默认存储路径:~/.openclaw/memory/<agentId>.sqlite。同时为了支持开箱即用的用户体验,OpenClaw默认会基于系统中配置的Provider API Key自行决定embedding model并自动启动hybird search,这一点大家需要了解。
OpenClaw核心检索能力基于混合搜索实现,如下所示:
-
关键词检索(传统搜索):基于SQLite FTS5 + BM25算法实现;
-
向量搜索(语义搜索):基于Embedding向量化检索实现;
-
Hybrid Search(混合搜索):同时支持关键词检索+语义搜索。
-
自动更新:当memory记忆文件被修改后会自动重建索引;
-
配置变更:当embedding provider或索引chunk配置修改后,索引也会自动全量重建;
-
手动重建:用户主动执行openclaw memory index –force也会进行索引重建。
关于QMD和Honcho等更高级的memory engine实现,大家可以参考其对应的github自行了解,这里就不再深入介绍了。但是有一点需要注意,默认OpenClaw配置使用的是built-in memory engine,如果大家在OpenClaw使用过程中对于Memory有更高或特殊的要求,需要选用更适合你的memory engine。
OpenClaw实现支持Dreaming memory记忆机制(应该是在claude code源码泄露后,OpenClaw参考实现),Dreaming可以理解为一个人类化的记忆机制,其过程可以把静态聊过的东西,慢慢筛选、沉淀、最终形成真正重要的长期记忆。
Dreaming = 自动筛选 + 提纯 + 升级记忆。
Dreaming记忆机制模拟人类睡眠包括三个阶段:
该阶段会读取daily memory(memory/*.md)中记录的session片段以及recall记录,然后经过去重、合并相关内容,同时记录内容出现次数并形成短期候选记录,写入memory/.dreams文件;
-
REM(快速眼动阶段):寻找模式 / 主题 / 潜在关联;
该阶段会提取主题 / 习惯 / 隐含关系,输出dream diary,写入DREAMS.md文件,该文件主要目的是给人阅读,用来解释其记忆过程;
-
Deep(深度睡眠阶段):最终裁决,哪些记忆值得长期记住;
该阶段会对候选记录进行评分,包括;Frequency(频率)、Relevance(相关性)、Query diversity(多样性)、Recency(时效性)、Consolidation(重复性)、Concept richness(信息密度)等维度,最终判断哪些记录会写入MEMORY.md。
同样OpenClaw针对Dreaming机制提供自动、手动两种执行模式:
-
Live dreaming:配置自动运行执行,自动筛选记忆;
-
Grounded backfill:手动重放历史,openclaw memory rem-backfill –path ./memory。
在OpenClaw实现中有一个有意思的设计,称为Active Memory的主动记忆机制,其本质就是期望让memory recall从被动方式变为主动方式,在模型执行前都会主动检索记忆。
Active Memory实现时基于一个单独的sub-agent实现,这个agent会配置独立的快速模型、System Prompt,同样基于memory_search/get工具实现,并将recall的memory以如下方式插入到System Prompt中,以此来期望解决由于主System Prompt过于复杂带来的以下问题:
-
Memory recall不稳定,有时查,有时不查,同时其行为调试起来困难,不可控;
-
另外主System Prompt很复杂,memory recall多轮浪费tokens。
接下来我们来深入OpenClaw的调度队列实现,来看看OpenClaw作为一个AgentOS,那么任务是如何被调度执行的?
在具体介绍调度之前,我们需要讨论下OpenClaw运行时到底需要哪些资源?
-
Agent:计算资源,最终的任务需要分配到某个具体的agent上执行;
-
Context:临时上下文信息,agent执行时动态生成;
-
Memory:记忆资源,与agent一一对应,即多个Agent之间的memory是相互隔离的;
-
Tool:工具资源,agent执行时可调用的工具,用于与外部世界交互;
-
Config:配置资源,OpenClaw全局配置信息,默认存储~/.openclaw/openclaw.json;
-
Session:会话资源,OpenClaw自行管理session的lifecycle,其内部执行任务会共享底层session文件。
AgentSession(这个类在pi-coding-agent中定义)创建时需要指定agent、配置和工具,并在执行过程中管理context和memory,所以从OS的角度来看,AgentSession就是AgentOS中资源分配的最小单元,类似于操作系统中的进程,对应到底层的以此执行就是Agent run,是资源调度的最小单位,即操作系统的线程,一次完整的执行过程称为一个Agent loop。
那在OpenClaw运行过程中,如果在一个AgentSession中同时运行多个任务Agent run,那么会导致底层session文件共享资源的争抢,从而导致会话信息乱序,继而导致后续的上下文context错乱,所以OpenClaw在调度队列设计时采用两层队列:
-
Session调度队列:session内多个任务串行执行,一个session同一时刻只能有一个agent run在执行,后面的消息必须排队,以此解决上下文context一致性的问题;
-
全局调度队列:用于全局并发控制(限流),即整个系统中最多可以同时运行多少个agent run,所以所有的输入消息同时必须进入全局队列,默认main agent并发限制4,其他sub-agent并发限制8。
从这个角度来看,其实OpenClaw实现的是一个简单的支持多进程单线程调度模型的AgentOS。
在该调度模型下,那么OpenClaw支持哪些可选的调度策略呢?
-
collect(默认配置):后续的消息统一收集起来,合并成一个任务agent run进行处理;
-
follow-up:消息排队,然后逐条处理,即每条消息会触发一个agent run;
-
steer:在下一个turn开始时插入,会在下一个tools call边界生效,可以中断或改变当前流程。对于大部分的coding agent的默认策略,从这个角度来看,不同场景的Agent实现确实差别很大;
-
steer-backlog:既插入下一个turn,又保留一份follow-up,不常用;
-
interrupt:直接打断当前run,抢占式调度策略,不常用。
另外在实现时,针对IM场景用户可能会快速发送多个消息,OpenClaw会维护一个窗口统一作为一个消息发送处理,同时针对调度队列配置最多缓存多少条消息,以及当消息溢出后的溢出策略,这些大家都可以根据你的场景自定配置。
另外大家在使用中有没有发现,在发送消息后OpenClaw会迅速对消息进行表情回复,而不管消息是不是在排队,本身任务执行的过程也是异步的,这可以看作是一个交互体验优化。
下面我们简单聊下OpenClaw对multi-agent的支持,在前面介绍中,我们也提到过agent是OpenClaw系统的第一等公民,那么每一个agent都会有独占的工作目录、独立的人格以及完全隔离的运行状态和sessions。这样我们可以在一个OpenClaw中创建多个agent,比如我可以有一个工作助理、一个生活助手、还可以有一个家庭机器人等。
在OpenClaw中基于一个Binding机制来实现multi-agent的routing,具体我们可以通过openclaw agents命令创建多个agent,同时可以配置其binding关系,我们可以为某个peer、某个group、某个account或者某个channel bind一个独立的agent,如果没有binding匹配,这时会route到main agent处理。
Message Inbound & Outbound
最后我们再看下针对IM场景,OpenClaw针对消息Inbound和Outbound时都做了哪些优化?
-
消息去重(Dedupe):基于channel + account + peer + messageId维度构建一个缓存,来防止消息在短时间内由于网络抖动的重复发送;
-
防抖动(Debounce):针对IM用户习惯,会将连续的输入合并为一次消息,本质上是把用户行为转成合理的agent调度粒度,这个在上面已经提到过。
Outbound Streaming and Chunking
我们都知道当前大部分LLM API都支持streaming模式,即可以流式返回token进行渲染输出,以此来提升用户体验,针对ChatBot,我们可以直接将LLM token streaming给用户,因为chatbot的设计初衷就是支持token streaming。但是回到OpenClaw的场景,我们的输出端变成了IM即时聊天软件,可以说当前主流的IM默认都不支持streaming,其最小粒度为Message,即一个一个消息,同时需要考虑group群聊的特性,需要对agent的输出进行适配,这就是针对IM场景需要单独设计的难点。
在OpenClaw中,使用的Message Streaming/Chunking架构,其实现方式如下:
-
Block Streaming:LLM token streaming -> block -> message -> Channel,OpenClaw返回时需要将token streaming组装成一个一个block,然后作为IM的Message进行返回即block1 -> block2 -> block3…
-
Chunking(切块算法):block切分算法,需要综合考虑不同的channel限制(如:字符限制、行数限制、block大小限制等等)以及交互体验问题,同时避免一次发送大量消息影响用户体验或造成客户端崩溃等问题。
OpenClaw实现chunking遵循以下规则:
-
定义缓存buffer,当buffer < minChars时,token持续缓存,不发送;
-
当buffer >= maxChars时需要进行切分block,切分优先级:原子单元 > 段落 > 换行 > 句子 > 空格;
-
Human Delay & 合并发送:模拟人类节奏 block1 → pause → block2 → pause → block3…
这样可以将模型的输出适配到人类聊天体验中,这些实现细节确实是OpenClaw特有的,在基于IM作为入口之前大家可能完全不会考虑这些问题。
最后我们来介绍一个我觉得是OpenClaw中一个比较有意思的设计,我把它叫做:Node device as Tools,也许对于大家很有借鉴意义。
大家是不是还有印象,在开始介绍OpenClaw Gateway的时候,有一类Client被称为Node,我们可以外部设备定义成Node,通过Gateway Protocol协议进行接入,这样可以理解为OpenClaw就可以通过这些Node接入真实的物理世界,比如我们可以通过Node device进行拍照、录像等作为大模型的输入。
Node的本质是把真实设备变成OpenClaw可调用的工具,以此来扩展Agent的物理能力边界。任何物理设备都可以通过ws连接到Gateway,并暴露一组远程可调用的能力。其核心能力包括:
-
远程执行:这是OpenClaw实现“远程操控设备”的核心能力;
-
感知输入:截图、拍照、录屏、录像、GPS等多模态输入,相当于给Agent加上了“眼睛和传感器”;
-
UI/Canvas控制:打开网页、执行js、推送UI内容等,当然这部分可基于browser-use或compute-use tool实现;
-
设备&个人数据访问(Android):让Agent可以像人一样使用手机,可能权限很难绕过;
-
通知能力:主动推送notification、alert等。
个人理解这个能力可以不断的扩展,接入的node可以是一台电脑、一部手机、一个远程服务器,甚至可以是一个IPC Carema、一个机器人、一个机械臂等等,可以说在OpenClaw的畅想中,现在它可以通过Camera看,可通过Audio听,同时可以通过TTS说,在加上通过LLM可以很好的对多模态进行理解,大家可以脑洞大开看看可以有什么样好的应用场景。在OpenClaw的showcase中有一个人基于户外的IPC让OpenClaw自动捕捉漂亮的晚霞,确实很有意思。
甚至目前OpenClaw的版本已经支持包括Talk Mode(实时语音对话)和Voice Wake(基于语音唤醒)等能力,可以说作者Peter的想法确实很多,且不说这些粗糙的实现有没有意义 [偷笑]。
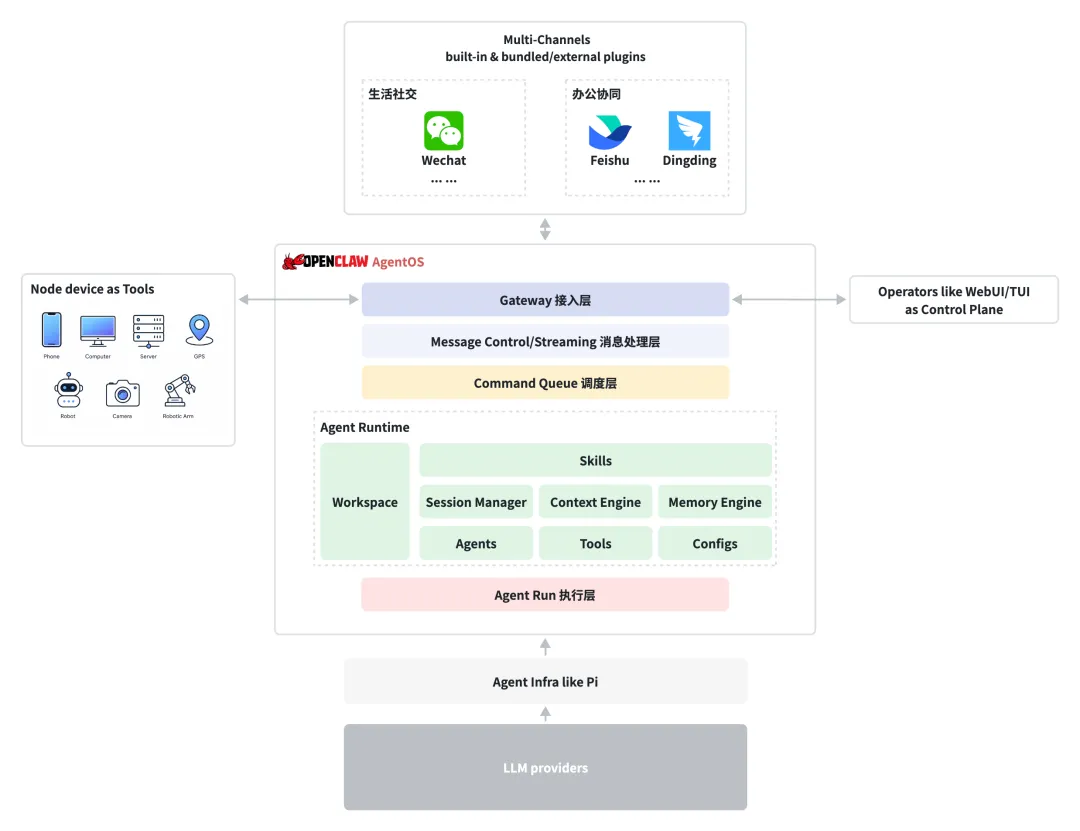
再深入了解OpenClaw之后,我们把所有内容重新整理到一张架构图来看看,可能下面这个样子:
大家可以再回到第一部分看看刚开始介绍OpenClaw时的样子,这个时候你还会把OpenClaw只是简单的认为是一个Gateway么?如今我们经常会将Agent框架设计定义为AgentOS,从这个角度来看,OpenClaw的架构确实很像是一个完整的AgentOS,这个框架未来会不会成为通用Agent的标准设计范式呢?
如果从这个角度来看,那么OpenClaw可以看作是一个支持多租户、多任务调度的AgentOS:
-
Agent类比于计算单元,Context、Memory类别于存储资源;
-
Agent Session类比于进程,Agent Run类比于线程;
-
-
外部物理设备统一抽象定义为工具Tool,除了Function Tools以外,还增加了Node Tools;
-
Skills就是未来AgentOS上运行的APP,即未来APP的用户是Agent而不是人类;突然想起来前段时间北京金谷园饺子馆上架了Skill技能,所以大家也快行动起来吧;
-
最后一点,未来AgentOS的主要入口可能就集中在生活社交或办公协同的IM软件中,毕竟我们现在的大部分沟通都发生在这里。
当然要让这个AgentOS可以很好的在我们的电脑上运行起来,除了自定义适合的配置以外,可能还需要OS本身的不断完善,所以,加油吧,养虾人。
最后简单来谈谈OpenClaw爆发的原因,可能是:
-
Not ChatBot,is an Open-source Autonomous AI Agent that DOSE THINES;
-
OpenClaw真动手,从其System Prompt设计可以去看看,很有意思;
-
数据不出域,完全自托管,A Pensonal Assistan;
-
最主要爆火的核心原因可能是Agent落地感,Local first本地部署,这样所有人都有尝试的冲动,这也是为什么那么多人排队装龙虾。
最后的最后,生成式人工智能这个合集内容会暂告一个段落,共8篇文章,其内容涵盖了从深度学习简介、生成式人工智能原理、Transformer、大模型训练、Agent框架、Agent Skills等内容,希望这条路径能够为你提供一个相对完整的认知框架,大家也可以沿着这个思路对感兴趣的内容继续深入学习了解。
 夜雨聆风
夜雨聆风