夜雨聆风
夜雨聆风





AI视频行业深度报告:技术跃迁驱动内容革命,把握产业变革新机遇(59页报告)
如需报告请联系客服或扫码获取更多报告
1 视频生成的前世今生:从GAN走向DiT,通往AGI的重要路径
1.1 视频生成:融合多模态信息能力,决定AIGC技术上限
视频同时融合文本、图像、音频等多模态信息,天然具备更高的复杂性与表达力,代表着AIGC产业能力上限。视频需处理空间、时间、因果与交互等高维结构,并要求将文字、图像、音频等模态映射到同一表征空间,其复杂性要求模型必须具备对真实世界的综合理解与推演能力:
1)空间:视频需理解物体形状、位置关系、遮挡与深度等三维结构;
2)时间:视频要求模型在连续帧中保持状态演化一致性,学习动力学规律与行为轨迹;
3)因果与交互:视频呈现对象间的作用、反应与事件链条,迫使模型掌握因果机制和多实体交互规则。当前文本、图片、音乐等模态生成技术已相对成熟,视频仍是行业技术短板,其突破将对AIGC的产业应用前景起到决定性作用。

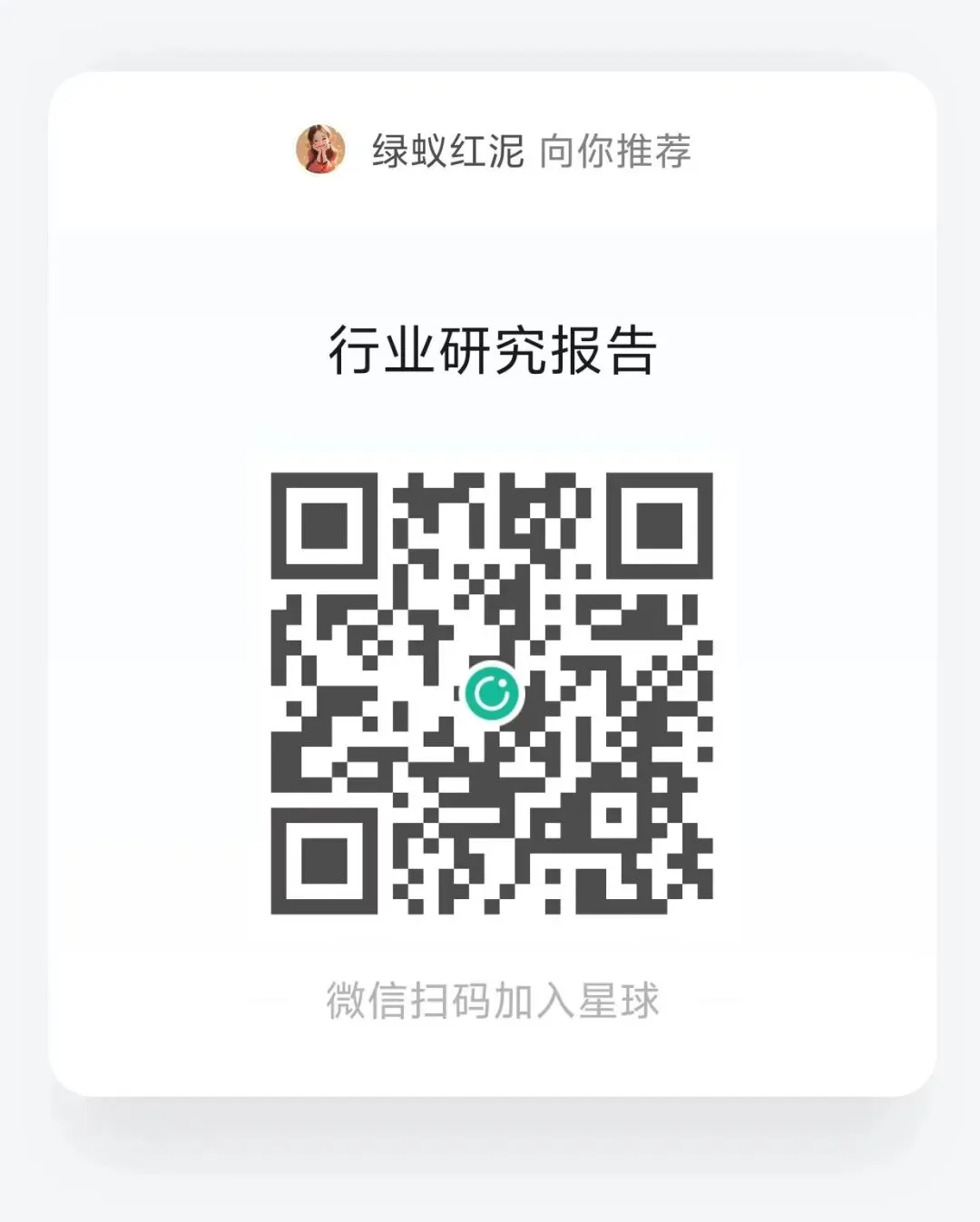
1.2 发展历程:从早期分化逐步走向共识,产业进入高速发展期
AI视频生成技术自2010年代中后期逐步起步,经历了多个关键架构的迭代升级。视频生成技术最早可追溯至20世纪90年代的图像序列拼接方法,其开启了将静态帧合成为动态视频的早期尝试,但真正的AI模型化探索始于2014年GAN的提出。2017年,Transformer架构的引入为模型带来了更强的时序建模与语义表达能力,但仍存在计算资源受限、生成质量不稳定等问题。因而在2020年后,部分开源社区尝试将扩散模型应用于视频生成,试图跳出Transformer架构限制,行业技术路线一度呈现分歧。直至2022年,Diffusion与Transformer的融合思路逐步成型,叠加2024年OpenAI发布的Sora验证了DiT架构在视频生成中的可行性与效果,行业迎来关键转折点,主流厂商全面向DiT路径演进,视频生成自此进入快速发展阶段。
GAN–VAE阶段(2014-2016):确立“视频可被端到端生成”的技术方向,是后续技术跃迁的理论起点。视频生成技术最早可追溯至2016年UC Berkeley提出的VGAN,该模型首次将生成式对抗网络(GAN)引入视频生成任务,并通过空间–时间卷积结构实现低分辨率短时动态序列的合成。同年,京都大学与东京大学提出的TGAN将视频生成分解为时间潜变量序列与图像生成器协同工作的方式,实现捕捉跨帧运动信息。在此基础上,2018年NVIDIA团队提出MoCoGAN,将视频内容与运动显式解耦,分别建模并通过对抗学习生成一致动作序列,从而实现了更具可控性的基础视频生成框架。但该阶段的模型多基于GAN的对抗式重建能力+VAE的连续潜空间表达,受限于模型架构限制,应用范围仅限于简单场景(如数字、基础动作),生成分辨率与时长均较低。

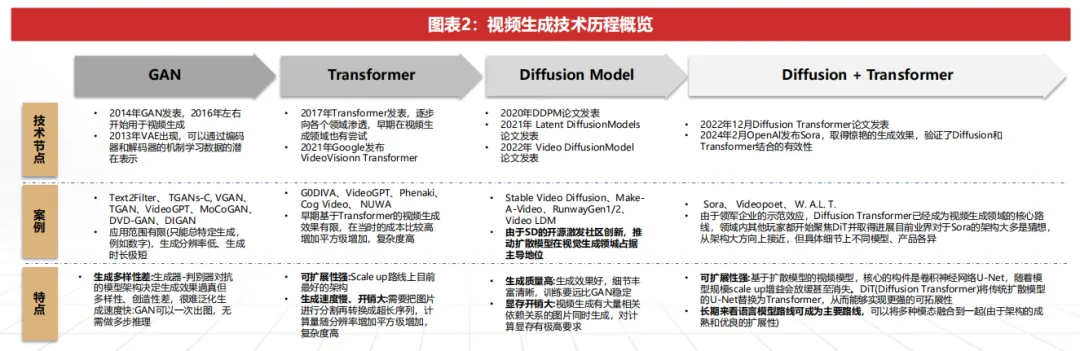
Transformer表征阶段(2017–2021):时空表征能力显著提升,为视频生成真正可用奠定底层基础,但生成质量、成本化能力均属过渡期。2017年Transformer论文发表后,该架构快速渗透至各类序列建模场景,并在视频生成任务中开启探索。自2021年Google推出Video Vision Transformer(ViViT)起,GODIVA、VideoGPT、Phenaki、CogVideo、NUWA 等视频模型相继出现。相较于GAN系列,Transformer具备明确的概率密度建模能力、收敛过程更稳定,并能够有效捕捉跨帧长程依赖,在生成时序一致、衔接自然的动态内容上更具优势。但由于其计算复杂度随空间与时间token数呈平方级增长,分辨率与时长提升将带来指数级的算力压力,导致该阶段模型在生成效果上仍受限制,其产业价值主要体现在从“能生成”迈向“能理解再生成”。
Diffusion扩散模型阶段(2020–2023):实现高质量短视频生成,但受限于时长与物理一致性,存在技术上限。扩散模型(Diffusion)通过“逐步加噪—逆向去噪”的显式概率建模范式,解决了GAN在训练稳定性和可控性上的核心缺陷,为高质量视觉生成奠定了基础。2022年,Meta发布Make-A-Video,其可根据自然语言生成约5秒短视频,是推动视频生成技术进入商业化探索阶段的早期代表之一。但传统扩散模型的去噪网络基于U-Net,其本质是一种以局部卷积为主的二维图像编码器,
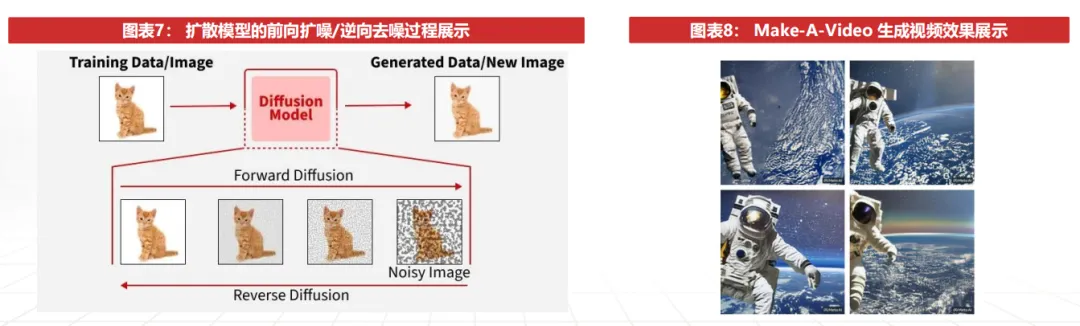
DiT扩散模型阶段(2024至今):在Sora推动下进入商业化周期,形成视频生成的主导技术路线。DiT的核心思想是以Transformer结构取代传统扩散模型中的U-Net作为去噪网络。2024年2月,OpenAI发布Sora,首次在工业级规模上验证了Diffusion+Transformer结合的有效性:在更长时长、更高分辨率、更复杂场景物理一致性以及更强的帧间连贯性上实现突破。
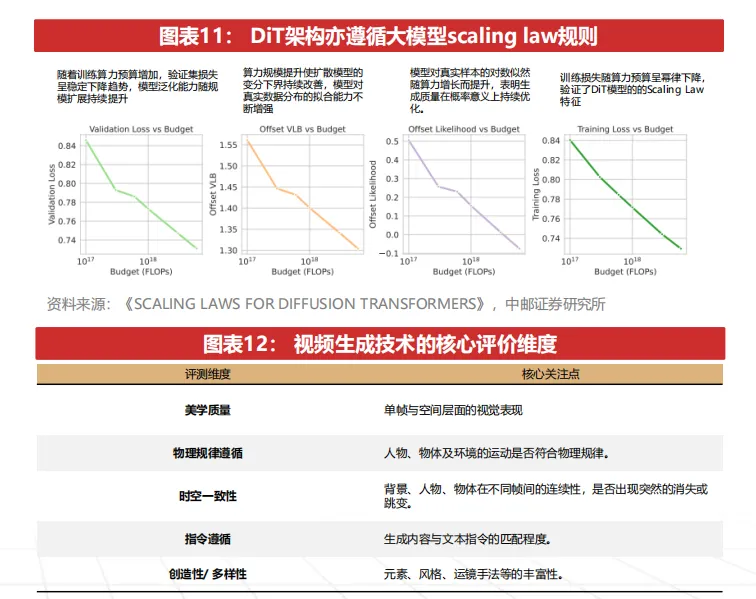
DiT架构融合了diffusion与Transformer的双重能力,推动视频技术进入高速迭代期。DiT 在继承扩散模型生成稳定性、训练可控性等基础优势的同时,引入了Transformer的推理能力、长程依赖建模能力与多模态统一表示能力,具体来看:
①DiT遵循Scaling Law,画面表现等能力提升形成外推性。传统扩散视频模型受限于卷积结构的局部建模特性,技术进展呈现不连续的断点式突破。而DiT架构通过引入Transformer,使视频模型能够遵循Scaling Law,生成能力可随参数规模、数据体量与训练算力提升而持续增强。近两年主流厂商在此基础上持续扩大模型规模并优化训练策略,使视频生成在分辨率、细节刻画及光影一致性等方面较早期模型显著改善;
②融
③多模态融合能力增强,实现音画一体化发展。基于Transformer的统一token表达与自注意力机制,文本、图像、视频与音频等多模态信息可在同一语义空间内对齐与协同生成,推动视频生成技术由早期“无声视频生成”逐步向“音画一体化生成”演进。
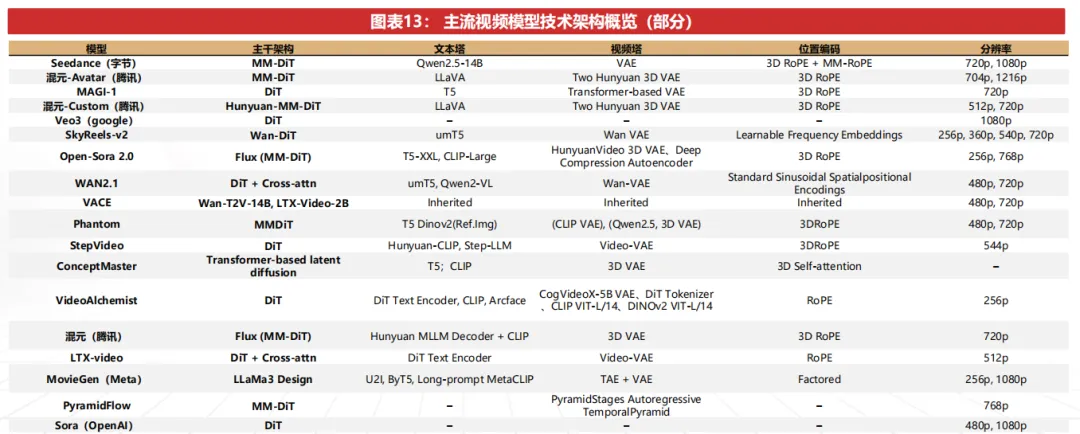
目前业内主流视频厂商模型均已向DiT架构收敛。Sora 发布之后,字节、Google、腾讯等主流厂商以及各类开源项目亦在向DiT框架迁移。尽管各家主干架构技术仍有差异,但路线本质上均是在DiT架构内的技术演进。
2 技术进展:短视频生成已近专业水准,长视频或迎重要变革节点
2.1 技术进展:美学、多模态化能力表现优异,物理性、生成时长是主要瓶颈
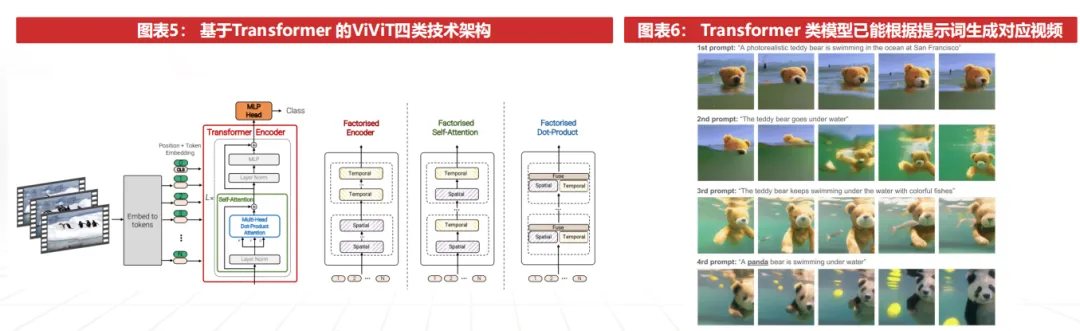
1)美学质量方面:当前AI视频生成模型已能够根据提示直接生成包含多人物主体、动作、背景与光影的完整动态画面,短片段生成能力已接近专业影视制作水准
主流视频生成模型普遍已支持1080p及以上分辨率,部分模型可生成4K及以上画面;帧率方面,多数模型可稳定支持24fps,部分已提升至30fps。以Sora 2为例,其在拟真性、风格表达以及复杂场景生成方面已取得显著进展,整体水平
1)真实性方面,人物表情与动作连续性提升,同时在光影关系、纹理细节与景深层次等环境维度表现愈发成熟,整体画面真实感明显,已接近工业级CG制作能力;
2)风格层面,模型可覆盖写实、动漫等多种视觉风格,能够适配悬疑、科幻等不同题材与叙事氛围的创作需求;
3)复杂人物主体及多镜头连续叙事能力方面,模型已能够在同一场景中生成多人物、多动作的协同表现,并支持多镜头角度切换下的连续叙事。

2)多模态方面:从“无声”向“视听”阶段全面演进,路径收敛或将推动技术加速迭代
AI视频音效生成技术主要分为一体化生成和后期分离生成两类技术路径。
1)原生音视频一体生成:采用多模态联合训练架构,在视频合成过程中同步生成高保真音频流,一步到位生成带有音效的视频;2)后期分离式生成:采用解耦式的跨模态推理框架,将音频生成剥离为一道独立工序。该类模型通过对视频帧序列进行时序特征提取与事件识别,驱动合成物理属性匹配、情感语义一致的音效轨迹。
从技术路径看,一体化音画生成在技术原理上具备天然优势,但实现门槛较高;分离式方案则因更强的可行性,长期占据行业主流。一体化路径将音效直接嵌入视频生成的底层流程,在统一时间轴与语义空间内完成联合建模,因而能够实现物理事件与声音的高精度对齐,相比分离式具备先天技术优势。但由于一体化生成壁垒较高,行业早期较多侧重分离式研究。典型产品包括2024年Pika、Google推出的Sound Effects与V2A系统,以及2025年国内厂商可灵、腾讯发布的Kling-Foley、HunyuanVideo-Foley 等。但严格意义上讲,由于分离式音频生成并未纳入视频生成的统一建模过程,本质仍是独立音频模块,并不代表视频模型本身已具备了多模态生成能力。