夜雨聆风
夜雨聆风





AI模型迭代聚焦工程能力,AI应用落地锚定高ROI场景(50页报告)
如需报告请联系客服或扫码获取更多报告
二、数据中心建设:电力容量面临限制,追求每瓦特产出效率
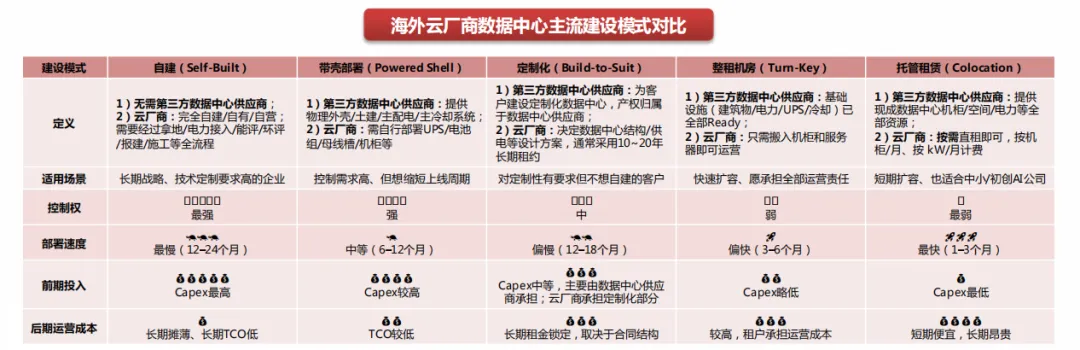
2.1 数据中心建设模式:自建/租赁等多种方式共建,通用性/灵活性成为建设共识
第一梯队云厂商主要采取自建模式,第二梯队云厂商带壳部署或租赁占比较多。1)微软:自建+租赁。微软在25Q3的349亿美元资本支出中,有111亿美元是用于大型数据中心站点的融资租赁。2)亚马逊:自建+带壳部署。3)谷歌:自建为主。谷歌于25Q3业绩会表示,多数数据中心均由自己建造,公司对其进行优化,确保以最高效的方式完成。4)甲骨文:带壳部署、租赁为主。公司将资本开支主要用于设备,而非建筑;建筑由合作伙伴建成后收取租金;公司不拥有土地或建筑物,而是拥有设备,并对设备进行优化。5)Coreweave:带壳部署、租赁为主。截至25Q3,公司任何单一数据中心供应商在签约电力组合中的占比都不超过20%,同时,公司已启动自建数据中心计划,以提升运营自主性并加快扩张。6)Nebius:定制化/租赁+自建同时存在。Nebius新泽西数据中心委托合作伙伴按照制定的规格和设计建造;同时公司正逐步减少租赁或共址机房的比例,更多转向自建设施。
数据中心通用性成为云厂建设共识,以保证在不同计算任务之间灵活切换。目前,多数海外云厂商均强调,在建设数据中心时,目标是建立一个通用的、能支持多代技术和多种模型的超大规模计算业务,而非为单一技术或单一客户过度投资,以适应不同代际的GPU、满足更灵活的功率和冷却要求,同时能够在训练和推理工作负载之间灵活切换。根据SemiAnalysis信息,2024年中,微软基于风险与回报的考量,实施数据中心建设的“大暂停”,截至24Q2,微软在海外云厂商数据中心预租总量中的占比一度超过60%,而自25Q3开始,微软逐步停止租赁活动,其他超大云厂商的预租规模大幅增加,25Q4微软预租容量占比下降至25%。微软于2024年中开启的数据中心“大暂停”调整,代表着海外云厂商在FOMO capex和ROI capex之间的战略平衡,并强调数据中心是为多类模型、多代硬件设计,而非为单一模型、某一代硬件建设,基础设施需要灵活地跨越多方面要求。

2.2 数据中心建设目标:电力容量成为核心瓶颈,追求最大化每瓦特产出效率
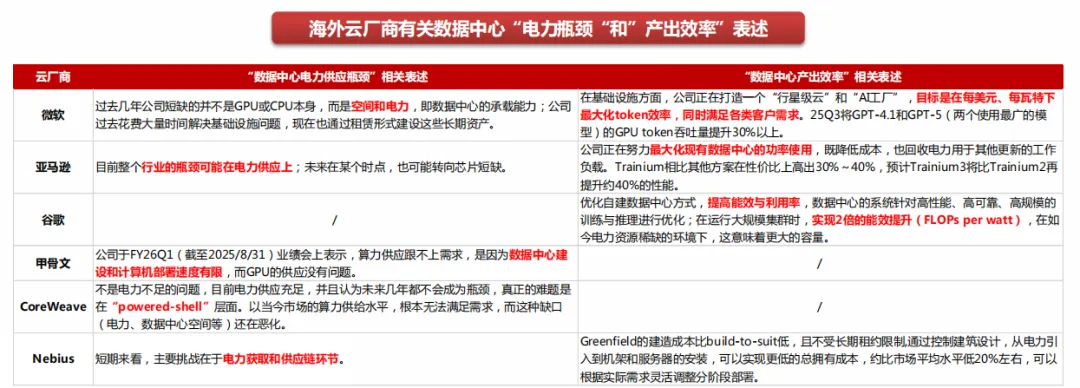
电力供应成为核心瓶颈,追求最大化每瓦特产出效率。当前,海外云厂商普遍表态当前数据中心的建设瓶颈主要在于空间和电力供应,从具体环节上看,电力瓶颈主要在于供电外壳(Powered-shell)层面。通常,云厂商在规划建设某一数据中心时,需要率先确定支持该数据中心的电力容量,然后再对数据中心内部的各类IT设备进行配置。因此,在电力容量限制下,海外云厂商均开始强调最大化现有数据中心的功率使用、最大化每瓦特下的tokens产出效率,数据中心建设将针对芯片、存储、网络等硬件环节,以及软件栈和系统架构进行全面优化,以提高数据中心能效和算力利用率。
数据中心软硬件协同优化,帕累托前沿曲线加速上移。2025年,英伟达多次强调AI工厂的帕累托前沿曲线(Pareto Frontier)以及数据中心的极致协同设计(Extrem Co-Design)。AI工厂的帕累托前沿曲线揭示出数据中心在特定功率下的吞吐量与延迟之间的平衡,在该曲线上,改善一个目标意味着牺牲另一个目标,即”低延迟时吞吐量下降、高吞吐量时延迟上升”。数据中心的极致协同设计方面,包括芯片、计算系统、软件、模型架构、应用程序等各个环节,从而使得AI工厂在晶体管数量仅扩张2倍的情况下,仍然能够获得tokens产出效率10倍性能的提升。根据英伟达GTC大会,算力、存储、带宽、软件和架构等多维度的升级与优化,将推动帕累托前沿曲线向右上方推进,帮助AI工厂或数据中心实现收入的更大化。

算力芯片持续迭代,每瓦特产出效率大幅提升。
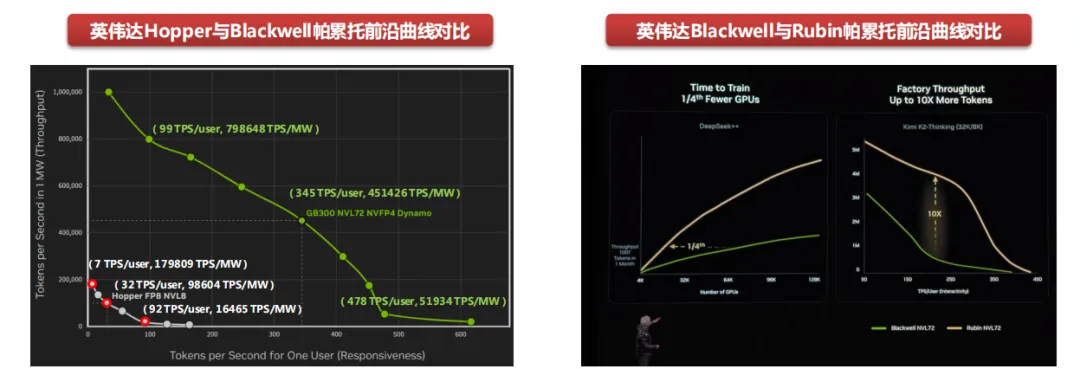
英伟达Hopper VS Blackwell:根据英伟达官网信息,在1兆瓦功率限定下,若保持AI大模型为每位用户提供每秒90多个Tokens的生成速度,那么由Hopper系列芯片构建的数据中心每秒可以产生1.6万个Tokens,由GB300构建的数据中心每秒则能产出近80万个Tokens,实现约50倍增长,数据中心在芯片、存储、软件和架构等多维优化下,使得每瓦特下的Tokens产出效率实现大幅提升。
英伟达Blackwell VS Rubin:根据2026年1月英伟达CES大会,Rubin系列产出效率有望在Blackwell基础上再提升10倍。
算力芯片持续迭代,能效对比提升明显。
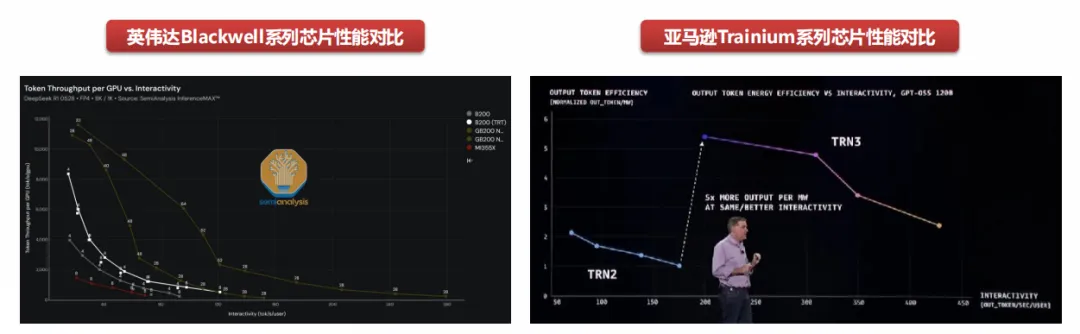
英伟达Blackwell VS AMD MI355:根据SemiAnalysis基于其专有测试,得出Blackwell系列服务器在系统级创新和特定应用场景配置下,相较AMD的MI355系列芯片,能够带来较大数量级的性能提升。
亚马逊Trainium 2 VS Trainium 3:2025年12月2日,亚马逊正式推出新一代AI训练芯片Trainium 3,并预告下一代Trainium 4的开发计划。Trainium 3是AWS首款采用3nm制程的AI芯片,专为下一代智能体、推理和视频生成应用App提供最佳Tokens经济效益而设 计。根据AWS官方 数据,搭载Trainium 3芯片的Trn3 UltraServer系统在性 能上实现显 著提升,Amazon EC2 Trn3在能效比上每兆瓦所处理的token数量达前代产品的5倍。
三、模型能力演进:研究端产品端并进,工程化能力继续增强
3.1 模型侧:AI模型算力需求持续,研究端与产品端并进
AI大模型竞争持续,演进方向聚焦四大能力。
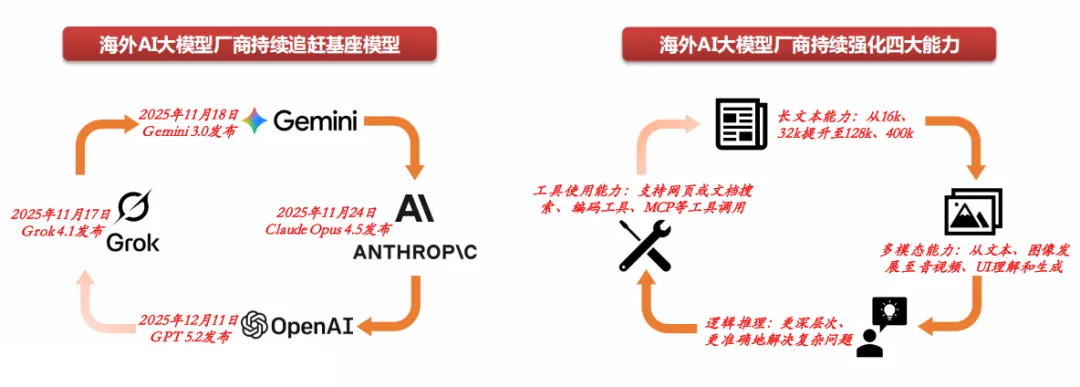
当前,AI基础大模型竞争已进入高强度、快迭代阶段,2025年11月至12月,Grok 4.1、Gemini 3.0、Claude Opus 4.5、GPT-5.2相继发布,模型竞争形成追赶态势,反映头部大模型厂商在算力投入、模型训练与工程化能力上持续加码;未来,基座大模型与特定领域的持续优化仍是主要竞争方向。从模型能力上看,大模型迭代主要围绕
长文本、多模态、逻辑推理、工具使用
四大能力,追求更长的上下文以满足个性化记忆,多模态能力从文本和图像扩展至音视频理解生成能力,推理能力则向更深层次与更高准确率演进,同时,通过工具调用、结合MCP等机制强化未来AI大模型在具体任务上的执行能力。
训练算力:主流模型厂商继续进行预训练,同时关注持续学习和强化学习。
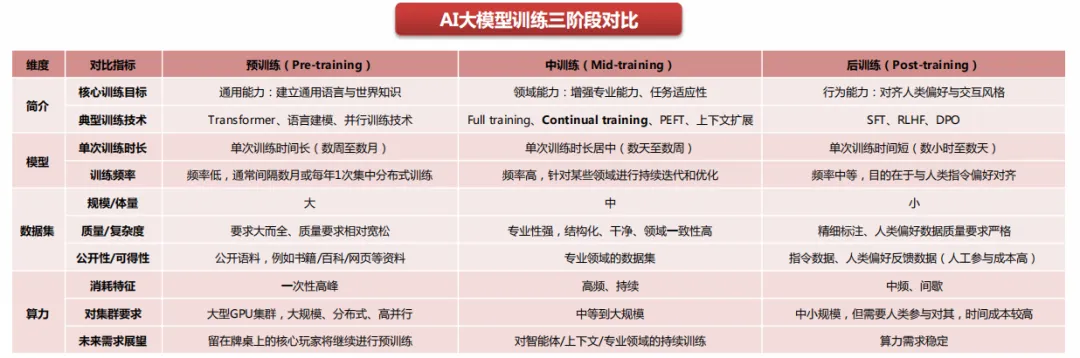
2024年,大模型厂商在预训练环节投入算力较高;2025年,大模型竞争格局收敛,主流厂商基于此前的基座模型进行持续打磨,算力消耗逐步向后训练的强化学习倾斜;2026年,训练算力需求有望持续增长,核心玩家将继续预训练,强化学习仍会持续,持续学习有望盛行。
1)预训练:随着竞争格局逐步收敛,留在牌桌上的模型厂商未来仍将继续预训练,探索更高效的模型架构和训练配方,预训练算力需求有望持续。
2)中训练:中期训练可用于延长模型知识的截止日期、提升特定领域的能力、或为高计算量的强化学习做准备。通常,在高度专业化的科学领域中,中训练能够使模型在后训练后达到更高的智能水平。
3)后训练:后训练阶段的典型技术为强化学习,主要针对多模态和长文本能力再训练、对智能体产品进行打磨与适配、与人类偏好对齐,未来AI大模型对中训练及后训练阶段的算力需求有望稳健增长。
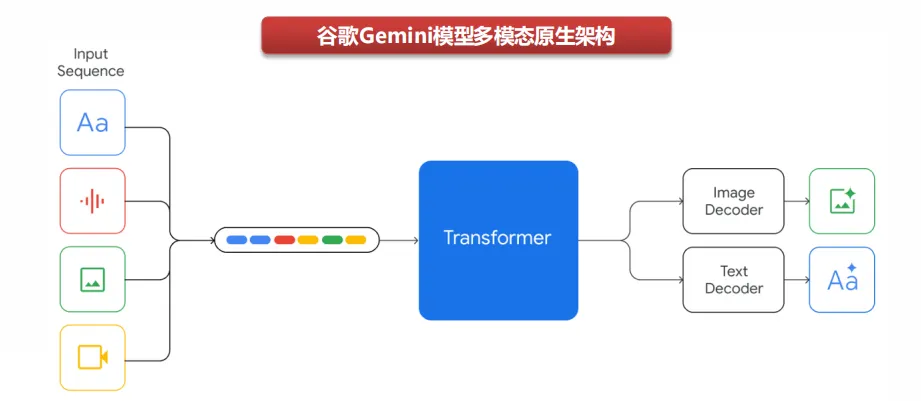
模型架构:原生多模态对训练算力及模型结构要求更高,但也许更符合第一性原理。1)多模态堆叠:过去,大语言模型和扩散模型原本设计为单模态模型,而后经过修改或扩展,逐步具备处理其他模态的能力,多模态堆叠成为主流方法。2)多模态原生:2023年12月,谷歌发布Gemini大模型,支持原生多模态,从一开始就对多模态进行统一的预训练,再用额外的多模态数据进行微调和对齐,使Gemini系列模型可以互通和推理多种模态信息。其中,谷歌Gemini 3模型被明确描述为“原生多模态+ 稀疏MoE Transformer”架构,能够统一处理文本/图像/音频/视频和百万tokens长上下文,但在产品层面仍然通过工具/检索/IDE等模块处理任务,形成“原生多模态大脑+模块化外骨骼”的工程形态。此外,部分海外AI实验室仍在探索除Transformer之外的模型架构,但在更优美的模型架构出现之前,Transformer仍有较多工程化能力的提升空间。