 夜雨聆风
夜雨聆风





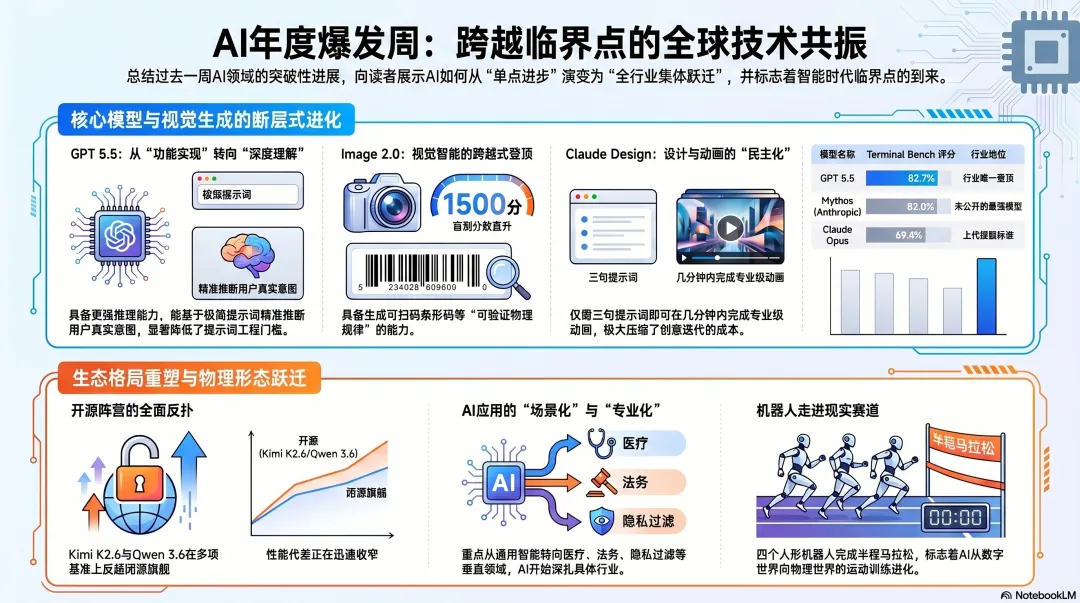
AI年度最大飞跃就在这一周:我亲测后的5个反直觉发现
AI年度最大飞跃就在这一周:我亲测后的5个反直觉发现
我从来没有在一周内被这么多AI重磅消息追着跑过。
GPT 5.5封神、Image 2.0彻底终结Nano Banana的统治、Claude Design让动画变得”廉价”、开源阵营追上闭源SOTA、Mythos被偷出实验室、四个人形机器人在半马里跑进一小时——这不是几条孤立的更新,这是一次集体跃迁。
我用整整一周把它们一个一个挨个测了一遍。越测我越确认一件事:所谓”年度最大飞跃”,从来不是某一个模型的功劳,而是这一周里整个行业的同频共振。
下面是我亲手把玩之后的5个反直觉发现,每一个都在颠覆我过去半年的判断。
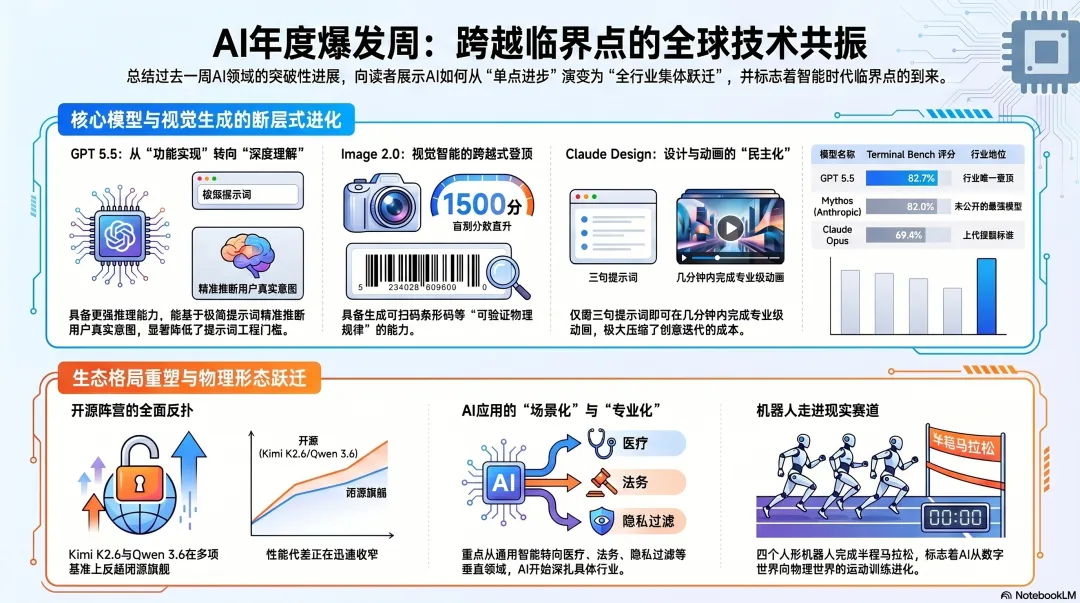
GPT 5.5:从”会做”到”懂你”的临界点
我先用GPT 5.4试了一句最普通的提示词:”帮我做一个变得更健康的计划”。
它给出的,是一份你随便扔给谁都通用的模板:睡眠、饮食、运动、减压。看得出努力,但也看得出敷衍。
我把同样的提示词扔给了GPT 5.5,结果完全两样。它在回答里精准说出:”你历史上的核心营养问题不是吃太多垃圾,而是经常跳过早午饭、白天蛋白质摄入不足、把所有热量堆在晚饭“——这话简直是在说我本人。它甚至识别出我每周三录视频、周四剪片的节奏,把训练日排在周二、周三、周五,把周一和周四改成”轻活动日”,连出差时的简化版方案都顺手给出来了。
旧模型解决”会不会”,新模型解决”懂不懂你”。
我意识到一件事:不是我突然变得更会写提示词,而是模型开始能用更少的信息推断我真正要的是什么。
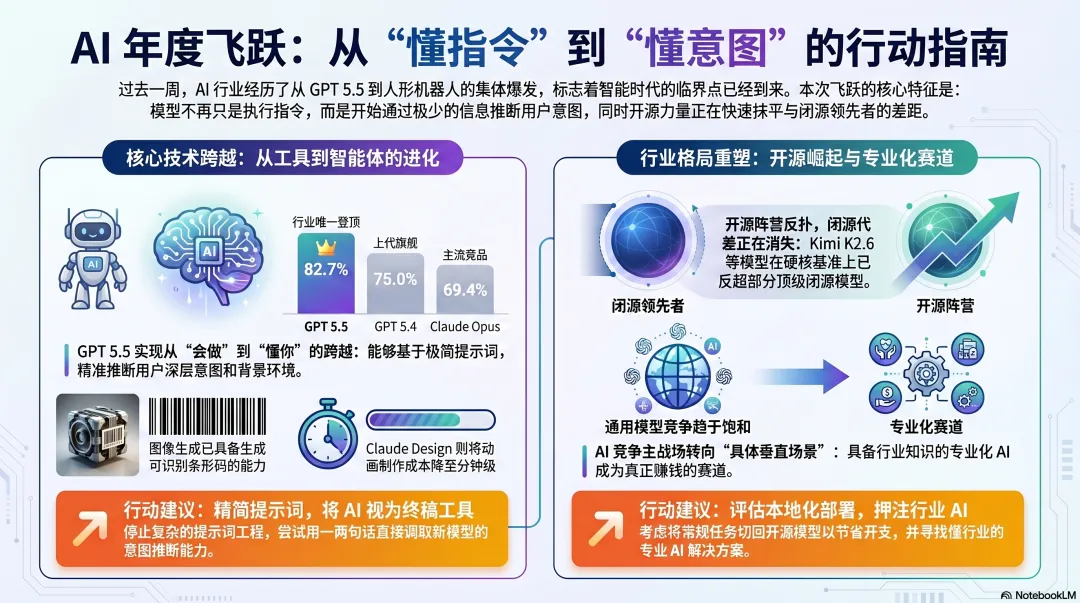
数据上看更夸张。GPT 5.5在Terminal Bench上拿到了82.7%,而上一代GPT 5.4只有75%、Claude Opus 69.4%。更值得玩味的是,Anthropic之前说”太危险不能放出来”的Mythos,在同一个基准上拿到的是82%——也就是说,OpenAI正大光明发布的模型,已经在这一项上超过了Anthropic不敢释放的那个。在Artificial Analysis的综合智能指数上,GPT 5.5 extra high也第一次单独登顶,把之前三模型并列的”前三”格局打破了。
价格也翻了一倍——百万输入Token从$2.5涨到$5,输出从$15涨到$30。但官方反复强调它”完成同样任务消耗的Token更少”。我的实测结果是:短提示词下,5.5一次到位的概率明显高出一档。这意味着对长期重度使用者,单次贵了,总账单未必更贵。
行动建议:把过去精雕细琢的长提示词收起来,先用一两句话试一遍5.5——你会发现自己写过的很多提示词工程,其实只是给老模型打的补丁。新模型对”少即是多”的理解能力,正在让”提示词工程师”这个岗位重新被定义。

GPT Image 2.0:图像生成这件事,可能真的快被解决了
LM Arena的盲测分数最有说服力。在Image 2.0出来之前,Nano Banana长期霸榜,分数1271;其他主流图像模型都挤在1100-1200区间。
Image 2.0直接拉到了1500。这不是渐进,这是一次断层式跨越。
我特别测试了它的”密集文字渲染”能力。让它生成一张”包含人体主要骨骼标注的解剖图”,它居然真的画对了大部分关键骨头的位置——这种用世界知识填补提示词空白的能力,让它从”绘图工具”变成了”视觉智能体”。我又让它生成”一份90年代怀旧风的拼贴海报”,它自动把Game Boy、PS2、Blink 182专辑封面、Monster能量饮料这些符号一股脑塞进去,没有任何一项是我提示词里写过的。
最让我震撼的不是我自己的测试,而是Riley Brown的一次实验:他让模型画一本《从优秀到卓越》的书,要求封面条形码必须能扫出真实的购买链接。模型画出来了,他用手机扫一下,真的跳到了那本书的页面。他把条形码下方的ISBN涂黑再扫一次,结果还是同一本书——说明模型生成的不是数字,是真正可识别的条形码图案。
当一个图像模型能生成”可被现实世界验证”的内容时,它就不再只是图像模型了。
类似的案例还有很多:Riley Goodside让它画了一个32×48的迷宫并自己解出来;Mark让它生成了一张满是密集报纸文字的版面,每一行都连贯可读;Justine Moore用它做出了一组色彩张力极强的漫画分镜——而这些都只是一次提示词的输出。
行动建议:如果你过去把AI图像当”草图工具”,现在请把它当”印刷级输出工具”重新评估一遍工作流。海报、信息图、封面、漫画分镜、产品宣传单页,能省的钱比你想的多得多。
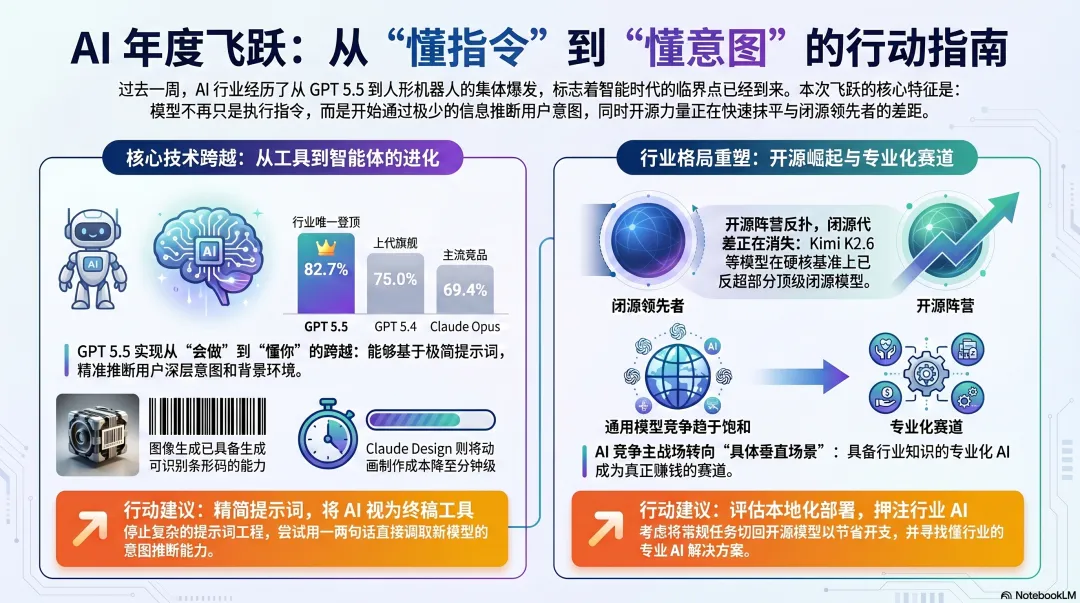
Claude Design:我用三句话搞定了After Effects级动画
Claude Design是这周最被低估的发布。所有人都在看模型,几乎没人注意到它给Pro/Max用户开放了一个全新的Tab。
我亲手测了一下:第一句让它”在地图上高亮拉斯维加斯并放大”,第二句让它”生成一组NAB历年AI相关展位的柱状图动画”,第三句让它”在画面中央动画浮现’AI, the defining story of NAB 2026′”。
它真的在两三分钟内做完了。如果用After Effects,这种活我以前至少要外包出去做两小时。它支持原型设计、幻灯片、单页文档、营销物料、产品Mockup几乎所有需要”视觉初稿”的场景。
它的局限也很明显:动画风格非常统一——几乎所有人用Claude Design做出来的东西都长得像同一个UI模板。你能立刻认出这是Claude做的。但对内部演示、Pitch Deck、社媒短视频这种快出快销的场景,统一风格反而是优点——风险被控住了,下限被锁住了。
更值得关注的是Anthropic同步推出的Live Artifacts。它会把仪表盘和数据源连起来——CSV更新一下,仪表盘自动刷新。我连了Figma测了下,逻辑确实通了,只是我自己用Figma太少没什么好看的东西。但只要把它接上Gmail、Calendar、Drive,它就能自动告诉你”今天哪些事情该处理”。
行动建议:把Claude Design当作”动效草稿机”,快速出演示用,对外发布前再让设计师在它的基础上微调。这一次AI抢走的是初稿,不是终稿;抢走的是迭代成本,不是审美决策。
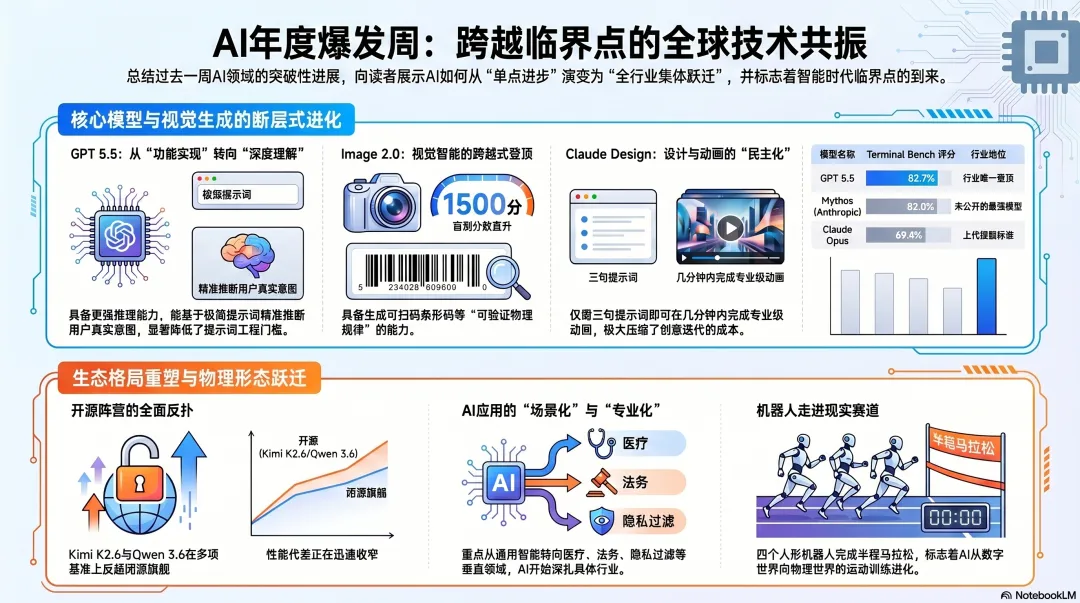
开源阵营反扑:Kimi K2.6与Qwen 3.6追上闭源SOTA
这周阿里和Kimi一起放了大招。
Qwen 3.6 Max Preview是阿里第一次走闭源路线的旗舰模型;同时开源的还有Qwen 3.6 27B。Kimi K2.6则更狠——支持300个并行子代理、长链路编码、运动密集型前端(WebGL、Three.js、Shader)全面强化。
更关键的是,Kimi K2.6在Deep Search和Humanity’s Last Exam这些硬核基准上击败了Opus 4.6和GPT 5.4 extra high。一个开源模型在多项关键基准上反超上一周的闭源SOTA——这件事在两年前是不可能发生的。
Google DeepMind同时端上来了Deep Research Max——一个面向自主研究的Agent模型,几乎横扫了所有研究类基准。把这三家放在一起看,你会发现一个事实:这一周里,Anthropic没出新模型,OpenAI出了一个,但开源/亚洲阵营一口气出了三个。
闭源模型在跑,开源模型在追,差距正以”代差”为单位被收窄。
行动建议:严肃评估开源模型在你工作流中的位置。从前你用闭源是因为”差距值得付费”,现在差距正在缩到”边际不再值得”的临界点。把推理跑回本地,每月省下的API账单可能会让你重新算账。

专业化AI与Mythos泄露:这一周最容易被忽略的两条主线
这一周还有两件事,被GPT 5.5的光芒遮住了,但其实更有信号意义。
第一件是专业化模型的批量登场。OpenAI放出了Privacy Filter——一个专门做PII(个人可识别信息)打码的小模型,完全开源、可本地部署,敏感数据连机器都不用离开。这在合规、医疗、法务行业是核弹级利好。同一周还有ChatGPT for Clinicians,免费开放给美国持证临床医生。Anthropic也在Claude里接入了AllTrails、Instacart、TurboTax等一批连接器,并把Claude直接塞进了Microsoft Word。Microsoft Copilot则在Word/Excel/PowerPoint里全面智能体化,可以多步执行原生应用动作。AI正在停止讨论”通用智能”,开始讨论”具体场景”。
第二件是Mythos泄露事件。Anthropic之前说Mythos”太危险不能释放”,结果这一周被未授权用户搞到了访问权限。Sam Altman在Core Memory播客里阴阳了一句:”这显然是绝佳的营销——我们造了一颗炸弹,要把它扔到你头上,但我们卖你一个一亿美金的避难所,前提是我们看上你这个客户“。我看完笑出声,但又有点不安:当一家公司把”危险”作为护城河营销时,反而会让真正想用它做坏事的人加倍想得到它——结果它们真的拿到了。
通用模型的故事讲完了,专业模型的故事才刚开始;而把”危险”当成卖点的故事,会反过来吞噬讲故事的人。
行动建议:把目光从”哪个模型更聪明”挪到”哪个模型更懂我的行业”。前者已经卷到天花板,后者刚刚起跑——这才是接下来一年真正能赚到钱的赛道。
机器人跑完半马:硅基世界的”赛季前热身”
这周中国举办了一场半程马拉松,四个人形机器人跑进了一小时。我反复看了完赛镜头,速度是真实速度,不是快放。
当然也有跑反方向的、被胶带绊倒的、半路自爆的、还有一颗长着两条腿的脑袋。整场比赛拍下来很像一场荒诞喜剧。但重点不是它们今天跑得多稳——重点是它们已经和人类同一条赛道上完赛。
五年前我们在讨论它能不能站起来,今天我们在讨论它跑多快。
行动建议:别再用”科幻片”滤镜看人形机器人。它已经从demo进入运动数据集,下一步就是工业场景的”跑第一公里”。这场半马不是终点,是它的赛季前热身。再过两年回头看,这一周很可能是我们记住的那个”分水岭”。
写在最后:年度最大飞跃,正在我们眼前发生
回到一开始那个问题——为什么我说这一周是年度最大飞跃?
不是因为某个模型分数破了纪录,而是因为这一周里,模型变聪明、图像被解决、动画被民主化、开源追上闭源、专业模型起跑、人形机器人完赛、Mythos泄露引爆讨论——七条主线同时往前跨了一大步。
真正的临界点,从来都不是某一个产品的发布会,而是一周之内你后知后觉地发现:周围的一切都不一样了。
如果你这一周也像我一样隐约感觉到了那种”加速感”,请相信你的直觉。这种感觉过去三年里我只有过两次:一次是ChatGPT刚出的时候,一次就是这一周。
如果这篇梳理帮你把这一周的信号串起来了,请帮我点赞、在看、转发给那个一直在迷茫AI风向的朋友——别让他错过这次飞跃。
#AI周报 #GPT55 #图像生成 #ClaudeDesign #开源大模型